
xAI a lancé Grok 4.1 et les ingénieurs qui travaillent avec des modèles de langage de grande taille remarquent immédiatement la différence. De plus, cette mise à jour privilégie la convivialité dans le monde réel plutôt que la simple course aux benchmarks. En conséquence, les conversations sont plus précises, les réponses ont une personnalité cohérente et les erreurs factuelles diminuent considérablement.
Les chercheurs de xAI ont construit Grok 4.1 sur la même infrastructure d'apprentissage par renforcement qui alimentait Grok 4. Cependant, ils ont introduit de nouvelles techniques de modélisation de récompense qui méritent un examen approfondi.
Architecture et variantes de déploiement
xAI propose Grok 4.1 dans deux configurations distinctes. Premièrement, la variante non-réfléchie (nom de code interne : tensor) génère des réponses directement sans jetons de raisonnement intermédiaires. Ce mode privilégie la latence et atteint les temps d'inférence les plus rapides de la famille. Deuxièmement, la variante réfléchie (nom de code : quasarflux) expose des étapes explicites de chaîne de pensée avant la sortie finale. Par conséquent, les tâches analytiques complexes bénéficient de traces de raisonnement visibles.
Les deux variantes partagent la même architecture pré-entraînée. De plus, les alignements post-entraînement diffèrent subtilement : le mode réfléchi reçoit des signaux de renforcement supplémentaires qui encouragent la décomposition étape par étape, tandis que le mode non-réfléchi optimise les réponses concises et immédiates.
L'accès reste simple. Les utilisateurs sélectionnent explicitement « Grok 4.1 » dans le sélecteur de modèle sur grok.com, x.com ou les applications mobiles.
Alternativement, le mode Auto utilise désormais Grok 4.1 par défaut pour la plupart du trafic, suite au déploiement progressif qui a débuté le 1er novembre 2025.

Percées dans l'optimisation des préférences
L'innovation majeure réside dans la modélisation des récompenses. Le RLHF traditionnel repose sur les préférences humaines recueillies à grande échelle. En revanche, xAI déploie désormais des modèles de raisonnement agentiques de pointe comme juges autonomes. Ces juges évaluent des milliers de variantes de réponses selon des dimensions telles que la cohérence stylistique, la perceptivité émotionnelle, la base factuelle et la stabilité de la personnalité.
Ce système en boucle fermée itère beaucoup plus rapidement que les flux de travail impliquant des humains. De plus, il s'adapte à des critères nuancés que les humains ont du mal à classer de manière cohérente. Les premières expériences internes ont montré que les modèles de récompense agentiques corrèlent mieux avec la satisfaction des utilisateurs finaux que les récompenses scalaires précédentes.
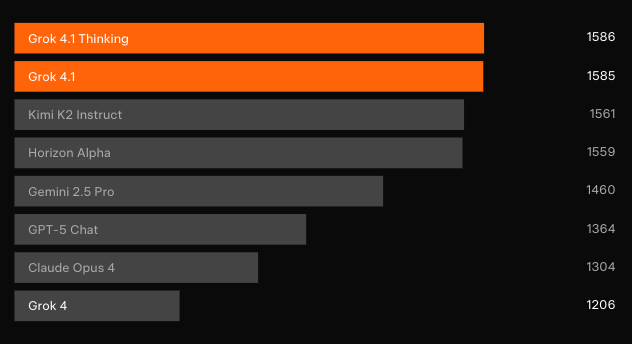
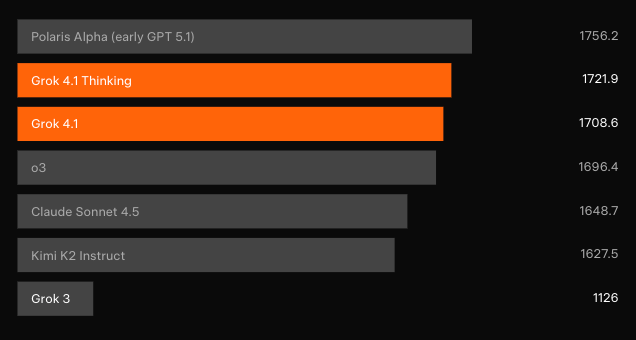
Domination des benchmarks : LMArena et au-delà
Des tests aveugles indépendants confirment les gains. Sur l'Arène de texte de LMArena — le classement participatif le plus représentatif — Grok 4.1 Réfléchi revendique la 1ère position avec 1483 Elo. Cette marge se situe à 31 points d'avance sur le meilleur concurrent non-xAI. Pendant ce temps, Grok 4.1 non-réfléchi se classe 2ème avec 1465 Elo, surpassant la configuration de raisonnement complète de tous les autres modèles.

Des tests de préférence par paires comparés au modèle de production précédent montrent que les utilisateurs sélectionnent les réponses de Grok 4.1 64,78 % du temps. De plus, des évaluations spécialisées révèlent des avancées ciblées.
Intelligence émotionnelle (EQ-Bench v3)
Grok 4.1 atteint le score le plus élevé enregistré sur EQ-Bench3, qui évalue 45 scénarios de jeu de rôle multi-tours pour l'empathie, la perspicacité et la nuance interpersonnelle. Les réponses détectent désormais des signaux émotionnels subtils que les modèles précédents ignoraient. Par exemple, lorsqu'un utilisateur écrit « Mon chat me manque tellement que ça fait mal », Grok 4.1 offre une reconnaissance nuancée, une validation douce et un soutien ouvert sans tomber dans des platitudes génériques.
Écriture créative v3
Le modèle établit également un nouveau record sur Écriture créative v3, où les juges évaluent la continuation itérative d'histoires à travers 32 invites. Les sorties présentent des images plus riches, une cohérence narrative plus forte et une voix plus authentique. Une invite de démonstration demandant à Grok de simuler son propre « éveil » a produit un monologue de style post-X viral qui mélangeait humour, émerveillement existentiel et références aux mèmes de manière transparente.
Atténuation des hallucinations
Des mesures quantitatives montrent que Grok 4.1 hallucine trois fois moins souvent lors de requêtes de recherche d'informations que son prédécesseur. Les ingénieurs y sont parvenus grâce à un post-entraînement ciblé sur le trafic de production stratifié et des ensembles de données classiques comme FActScore (500 questions biographiques). De plus, le mode non-réfléchi déclenche désormais proactivement des outils de recherche web lorsque la confiance tombe en dessous des seuils internes, ancrant davantage les réponses dans des sources vérifiables.

Évaluation de la sécurité et de la responsabilité
La fiche technique officielle du modèle offre une transparence sans précédent sur les résultats des tests de red-team.
Les filtres d'entrée bloquent les requêtes restreintes en biologie et chimie avec des taux de faux négatifs aussi bas que 0,00–0,03 % pour les requêtes directes. Les attaques par injection de prompt augmentent ce chiffre modestement (0,12–0,20 %), indiquant un travail continu sur la robustesse face aux adversaires.
Les taux de refus sur les invites de chat violentes atteignent 93 à 95 % même sans filtres, et le succès des tentatives de jailbreak tombe à près de zéro dans la configuration non-réfléchie. Les scénarios agentiques (AgentHarm, AgentDojo) restent la catégorie la plus difficile, mais les taux de réponse absolus restent inférieurs à 0,14 %.
Les évaluations des capacités à double usage — menées délibérément sans mesures de protection — révèlent une forte récupération des connaissances en biologie (WMDP-Bio 87 %) et en chimie, mais le raisonnement procédural en plusieurs étapes est en deçà des références d'experts humains pour les tâches nécessitant l'interprétation de figures ou des protocoles de clonage. Ce schéma est conforme aux limitations actuelles des modèles de pointe dans l'ensemble de l'industrie.
Implications pour les consommateurs d'API et les développeurs
L'API xAI sert déjà les points de terminaison de Grok 4.1 sous les noms de modèles standard. Les profils de latence s'améliorent sensiblement : le mode non-réfléchi affiche une moyenne de moins de 400 ms pour le temps jusqu'au premier jeton sur des invites typiques, tandis que le mode réfléchi ajoute une profondeur de raisonnement contrôlable via des paramètres optionnels.
C'est là que Apidog excelle. Importez la spécification OpenAPI 3.1 officielle (disponible publiquement), puis générez instantanément des SDK clients dans plus de 20 langages. Configurez des serveurs de maquette qui reproduisent le schéma de réponse exact de Grok 4.1 — y compris les nouveaux flux de jetons de réflexion — afin que vos tests backend ne soient jamais bloqués par les crédits d'API en direct. Lorsque xAI déploie des changements majeurs (rare, mais possible), le visualiseur de différences d'Apidog met immédiatement en évidence les dérives de schéma.
De vraies équipes utilisent déjà Apidog pour maintenir une disponibilité de 100 % pendant les mises à niveau des modèles. Un client du Fortune 500 a signalé une réduction de 68 % des bogues d'intégration après être passé de Postman.
Comparaison avec les modèles de pointe contemporains
Les données directes de comparaison sont rares quelques heures après le lancement, mais les classements Elo de LMArena fournissent le signal le plus clair. Grok 4.1 Réfléchi surpasse toutes les configurations publiées par OpenAI, Anthropic, Google et Meta avec des marges qui exigent généralement des sauts architecturaux complets.
Les compromis vitesse-qualité favorisent Grok 4.1 non-réfléchi pour le chat grand public, tandis que le mode réfléchi rivalise directement avec les offres riches en raisonnement comme o3-pro ou Claude 4 Opus — l'emportant souvent sur la cohérence subjective et le maintien de la personnalité.
Conclusion
Grok 4.1 ne se contente pas d'incrémenter des métriques ; il réoriente la frontière vers des modèles avec lesquels les gens aiment réellement converser pendant des heures. Les utilisateurs techniques bénéficient d'un point de terminaison plus rapide et plus fiable. Les créatifs découvrent un collaborateur qui comprend le ton et l'émotion à des niveaux auparavant inaccessibles. Et les chercheurs en sécurité reçoivent la fiche technique de modèle la plus détaillée publiée à ce jour.
Téléchargez Apidog aujourd'hui — entièrement gratuitement — et commencez à construire avec Grok 4.1 avant que vos concurrents n'aient fini de lire l'annonce. La différence entre observer le progrès des frontières et livrer des produits basés dessus se résume souvent aux décisions d'outillage prises aujourd'hui.