
Les développeurs recherchent constamment des outils puissants pour créer des applications intelligentes. OpenAI répond à ce besoin avec la sortie de GPT-OSS, une série de modèles linguistiques à poids ouverts qui offrent des capacités de raisonnement avancées. Ces modèles, y compris gpt-oss-120b et gpt-oss-20b, permettent la personnalisation et le déploiement dans divers environnements. Les utilisateurs y accèdent via des API fournies par des plateformes d'hébergement, permettant une intégration transparente dans les projets.
Pour commencer à travailler avec l'API GPT-OSS, les développeurs obtiennent l'accès via des fournisseurs tels qu'OpenRouter ou Together AI. Ces plateformes hébergent les modèles et exposent des points d'accès standard compatibles avec le format d'API d'OpenAI. Cette compatibilité simplifie la migration depuis les modèles propriétaires.
Qu'est-ce que GPT-OSS ? Caractéristiques et capacités clés
OpenAI conçoit GPT-OSS comme une famille de modèles à mélange d'experts (MoE). Cette architecture n'active qu'un sous-ensemble de paramètres par jeton, ce qui augmente l'efficacité. Par exemple, gpt-oss-120b dispose de 117 milliards de paramètres au total, mais n'active que 5,1 milliards par jeton. De même, gpt-oss-20b utilise 21 milliards de paramètres avec 3,6 milliards actifs.
Les modèles utilisent des structures basées sur des transformeurs avec des couches d'attention denses et clairsemées alternées. Ils intègrent des intégrations positionnelles rotatives (RoPE) pour gérer de longs contextes allant jusqu'à 128 000 jetons. Les développeurs en bénéficient dans les applications nécessitant des entrées étendues, telles que la synthèse de documents.
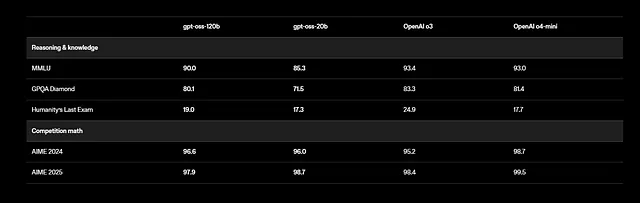
De plus, GPT-OSS prend en charge les tâches multilingues, bien que l'entraînement se concentre sur l'anglais avec un accent sur les données STEM et de codage. Les benchmarks montrent des résultats impressionnants : gpt-oss-120b obtient un score de 94,2 % sur MMLU (Massive Multitask Language Understanding) et de 96,6 % sur AIME (American Invitational Mathematics Examination). Il surpasse des modèles comme o4-mini pour les requêtes liées à la santé et les mathématiques de compétition.
Les développeurs utilisent les fonctionnalités d'appel d'outils, où le modèle invoque des fonctions externes comme la recherche web ou l'exécution de code. Cette capacité d'agent permet de construire des systèmes autonomes. Par exemple, le modèle enchaîne plusieurs appels d'outils dans une seule réponse pour résoudre des problèmes étape par étape.
De plus, les modèles adhèrent à la licence Apache 2.0, permettant la modification et le déploiement gratuits. OpenAI fournit les poids sur Hugging Face, quantifiés au format MXFP4 pour une utilisation réduite de la mémoire. Les utilisateurs peuvent les exécuter localement ou via des fournisseurs de cloud.
Cependant, des considérations de sécurité s'appliquent. OpenAI effectue des évaluations dans le cadre de son Cadre de Préparation, testant les risques tels que la désinformation. Les développeurs mettent en œuvre des mesures de protection, telles que le filtrage des sorties, pour atténuer les problèmes.
En substance, GPT-OSS combine puissance et accessibilité. Sa nature ouverte encourage les contributions de la communauté, ce qui conduit à des améliorations rapides. Ensuite, identifiez les fournisseurs qui offrent un accès API à ces modèles.
Choisir des fournisseurs pour l'accès à l'API GPT-OSS
Plusieurs plateformes hébergent des modèles GPT-OSS et fournissent des points d'accès API. Les développeurs choisissent en fonction de leurs besoins tels que la vitesse, le coût et l'évolutivité. OpenRouter, par exemple, propose gpt-oss-120b à des prix compétitifs et avec une intégration facile.
Together AI offre une autre option, en mettant l'accent sur les déploiements prêts pour l'entreprise. Il prend en charge le modèle via un point d'accès /v1/chat/completions, compatible avec les clients OpenAI. Les développeurs envoient des charges utiles JSON spécifiant les messages, max_tokens et la température.
De plus, Fireworks AI et Cerebras offrent une inférence à haute vitesse. Cerebras atteint jusqu'à 3 000 jetons par seconde, idéal pour les applications en temps réel. Les prix varient : OpenRouter facture environ 0,15 $ par million de jetons d'entrée, tandis que Together AI propose des tarifs similaires avec des remises sur volume.
Les développeurs envisagent également l'auto-hébergement pour la confidentialité. Des outils comme vLLM ou Ollama permettent d'exécuter GPT-OSS sur des serveurs locaux, exposant une API. Par exemple, vLLM sert le modèle avec des routes compatibles OpenAI, ne nécessitant qu'une seule commande pour démarrer.
Cependant, les fournisseurs de cloud simplifient la mise à l'échelle. AWS, Azure et Vercel intègrent GPT-OSS via des partenariats avec OpenAI. Ces options gèrent l'équilibrage de charge et la mise à l'échelle automatique.
De plus, évaluez la latence. gpt-oss-20b convient aux appareils périphériques avec des exigences moindres, tandis que gpt-oss-120b nécessite des GPU comme le NVIDIA H100. Les fournisseurs optimisent le matériel, garantissant des performances constantes.
En bref, le bon fournisseur s'aligne sur les objectifs du projet. Une fois choisi, passez à l'obtention des identifiants API.
Obtenir l'accès à l'API et configurer votre environnement
Les développeurs commencent par s'inscrire sur le site d'un fournisseur. Pour OpenRouter, visitez openrouter.ai, créez un compte et accédez à la section Clés. Générez une nouvelle clé API, nommez-la pour référence et copiez-la en toute sécurité.
Ensuite, installez les bibliothèques clientes. En Python, utilisez pip pour ajouter openai : pip install openai. Configurez le client avec l'URL de base et la clé. Par exemple :
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Cette configuration permet d'envoyer des requêtes aux modèles gpt-oss.
De plus, pour Together AI, utilisez leur SDK : pip install together. Initialisez avec :
import together
together.api_key = "your_together_api_key"
Testez la connexion en listant les modèles ou en envoyant une simple requête.
Cependant, vérifiez le matériel si vous auto-hébergez. Téléchargez les poids depuis Hugging Face : huggingface-cli download openai/gpt-oss-120b. Ensuite, utilisez vLLM pour servir : vllm serve openai/gpt-oss-120b.
De plus, définissez des variables d'environnement pour la sécurité. Stockez les clés dans des fichiers .env et chargez-les avec la bibliothèque dotenv.
En cas de problèmes, consultez la documentation du fournisseur pour les limites de débit ou les erreurs d'authentification. Cette préparation assure des interactions API fluides.
Effectuer votre premier appel API à GPT-OSS
Les développeurs créent des requêtes en utilisant le point d'accès des complétions de chat. Spécifiez le modèle, tel que "openai/gpt-oss-120b", dans la charge utile.
Pour un appel de base, préparez les messages sous forme de liste de dictionnaires. Chacun inclut le rôle (système, utilisateur, assistant) et le contenu.
Voici un exemple en Python :
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Ceci génère une réponse expliquant le concept techniquement.
De plus, ajustez les paramètres pour le contrôle. La température influence la créativité – des valeurs plus basses produisent des sorties déterministes. Top_p limite l'échantillonnage des jetons, tandis que presence_penalty décourage la répétition.
Ensuite, incorporez l'appel d'outils. Définissez les outils dans la requête :
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
Le modèle répond par un appel d'outil, que les développeurs exécutent et réinjectent.
Cependant, gérez les réponses avec soin. Analysez le JSON pour le contenu, la raison de fin et les statistiques d'utilisation comme le nombre de jetons.
De plus, pour la chaîne de pensée, invitez avec "Pensez étape par étape." Définissez l'effort de raisonnement dans les messages système : "reasoning_effort: medium".
Expérimentez avec gpt-oss-20b pour des tests plus rapides : Remplacez le nom du modèle dans les appels.
Dans les scénarios avancés, diffusez les réponses en utilisant stream=True pour une sortie en temps réel.
Ces étapes développent des compétences fondamentales. Maintenant, intégrez des outils de test comme Apidog.
Intégrer Apidog pour un test d'API GPT-OSS efficace
Les développeurs s'appuient sur Apidog pour tester et déboguer les interactions API. Cet outil fournit une interface conviviale pour envoyer des requêtes aux points d'accès gpt-oss.
Tout d'abord, installez Apidog depuis leur site web. Créez un nouveau projet et ajoutez un point d'accès API, tel que https://openrouter.ai/api/v1/chat/completions.
Ensuite, configurez les en-têtes : Ajoutez l'autorisation avec un jeton Bearer et le Content-Type comme application/json.
De plus, construisez le corps de la requête. Utilisez l'éditeur JSON d'Apidog pour saisir le modèle, les messages et les paramètres. Par exemple, testez un appel gpt-oss pour la génération de code.
Apidog visualise les réponses, mettant en évidence les erreurs ou les succès. Il prend en charge les variables d'environnement pour basculer les clés API entre les fournisseurs.
Cependant, utilisez les collections pour organiser les tests. Regroupez les requêtes GPT-OSS par tâche, comme le raisonnement ou l'utilisation d'outils, et exécutez-les par lots.
De plus, Apidog génère des extraits de code dans des langages comme Python ou cURL à partir de vos requêtes, accélérant le développement.
Pour la collaboration, partagez des projets avec les équipes. Cela garantit des tests cohérents des intégrations gpt-oss.
En pratique, utilisez Apidog pour surveiller l'utilisation des jetons et optimiser les invites, réduisant ainsi les coûts.
Dans l'ensemble, Apidog améliore la productivité lors de l'utilisation de l'API GPT-OSS.
Utilisation avancée : Affinage et déploiement
Les développeurs affinent GPT-OSS pour des domaines spécifiques. Utilisez la bibliothèque transformers de Hugging Face pour charger les poids et entraîner sur des ensembles de données personnalisés.
Par exemple, préparez les données au format JSONL avec des paires prompt-complétion. Exécutez les scripts d'affinage depuis le dépôt GitHub.
De plus, déployez les modèles affinés via vLLM pour le service d'API. Cela prend en charge les charges de production avec des fonctionnalités comme le traitement par lots dynamique.
Ensuite, explorez les extensions multimodales. Bien que centrées sur le texte, intégrez-les avec des modèles de vision pour des applications hybrides.
Cependant, surveillez le surapprentissage pendant l'affinage. Utilisez des ensembles de validation et l'arrêt anticipé.
De plus, mettez à l'échelle avec l'inférence distribuée sur des clusters. Des fournisseurs comme AWS proposent des options gérées.
Dans les configurations d'agents, enchaînez GPT-OSS avec des API externes pour des flux de travail comme la recherche automatisée.
Ces techniques étendent les capacités au-delà des appels de base.
Meilleures pratiques, limitations et dépannage
Les développeurs suivent les meilleures pratiques pour des résultats optimaux. Créez des invites claires, utilisez des exemples few-shot et itérez en fonction des sorties.
De plus, respectez les limites de débit – consultez les tableaux de bord des fournisseurs pour éviter la limitation.
Cependant, reconnaissez les limitations : GPT-OSS peut halluciner, alors validez les réponses critiques. Il manque de mises à jour de connaissances en temps réel.
De plus, sécurisez les clés API et enregistrez l'utilisation pour le contrôle des coûts.
Dépannage en examinant les codes d'erreur ; 401 indique une authentification invalide, 429 signifie que la limite de débit a été atteinte.
En résumé, respectez ces directives pour des performances fiables.
Conclusion : Renforcez vos projets avec l'API GPT-OSS
Les développeurs possèdent désormais les outils pour intégrer efficacement GPT-OSS. De la configuration aux fonctionnalités avancées, ce guide vous équipe pour réussir. Expérimentez, affinez et innovez avec gpt-oss et Apidog pour créer des solutions d'IA percutantes.