
Les ingénieurs et les développeurs recherchent constamment des modèles efficaces qui offrent des performances élevées sans exigences excessives en matière de ressources. GLM-4.7-Flash apparaît comme une option convaincante dans ce paysage. Ce modèle Mixture-of-Experts (MoE) 30B-A3B, développé par Zhipu AI (Z.ai), se distingue par son équilibre entre puissance et efficacité. Il excelle dans les benchmarks de codage, les tâches de raisonnement et l'intégration d'outils, ce qui le rend adapté aux scénarios de déploiement local.
L'exécution de GLM-4.7-Flash en local permet aux utilisateurs de préserver la confidentialité des données, de réduire la latence et de personnaliser les intégrations. Des outils comme Ollama, LM Studio et Hugging Face simplifient ce processus.
Au fur et à mesure que vous parcourrez ce guide, vous acquerrez des connaissances pratiques sur l'installation et l'utilisation. Tout d'abord, considérez les exigences fondamentales du système.
Qu'est-ce que GLM-4.7-Flash et pourquoi l'utiliser localement ?
GLM-4.7-Flash représente une avancée dans les modèles de langage open-source. Construit sur l'architecture glm4_moe_lite, il utilise des types de tenseurs BF16 et F32 sous licence MIT. L'article sur le modèle, "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models", détaille sa formation pour l'utilisation d'outils et le raisonnement, s'appuyant sur arXiv:2508.06471.
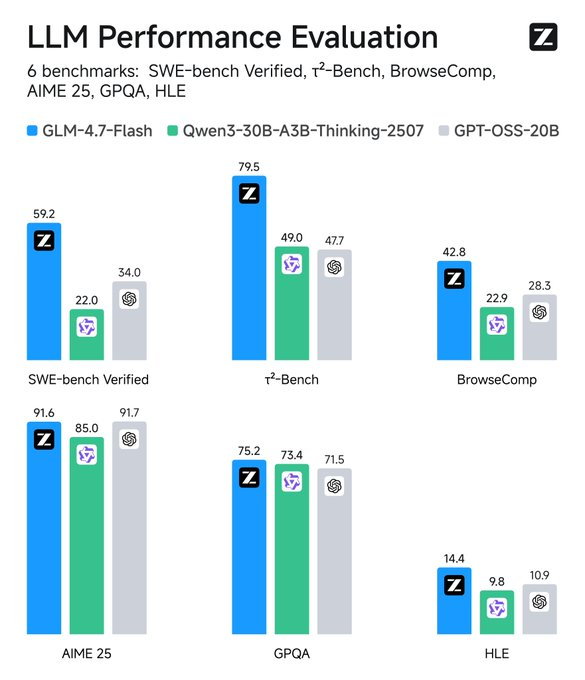
Les fonctionnalités clés incluent la prise en charge de l'anglais et du chinois, la génération de texte et les tâches conversationnelles. Il gère les entrées multimodales sous forme de texte mais se concentre sur les sorties purement textuelles. Des limitations découlent de son échelle – bien qu'efficace, il pourrait ne pas égaler les modèles plus grands dans des domaines de niche sans un ajustement fin. Les détails des données d'entraînement restent confidentiels, mais les évaluations confirment son avantage dans les scénarios de codage et d'agentique.
Les utilisateurs optent pour des exécutions locales afin d'éviter les coûts d'API. Z.ai propose un niveau gratuit pour GLM-4.7-Flash via leur plateforme, mais le déploiement local élimine la dépendance aux services externes. Cette approche convient aux développeurs qui créent des applications personnalisées, aux chercheurs qui testent des hypothèses ou aux entreprises qui privilégient la sécurité. Par exemple, vous contrôlez les niveaux de quantification pour s'adapter aux contraintes matérielles, garantissant ainsi des performances optimales.
Exigences système pour exécuter GLM-4.7-Flash localement
Le matériel joue un rôle crucial dans l'inférence du modèle. GLM-4.7-Flash exige au moins 16 Go de mémoire système pour les opérations de base, comme spécifié dans les directives de LM Studio. Cependant, l'accélération GPU améliore considérablement la vitesse.
Pour les variantes Ollama :
- q4_K_M : 19 Go de VRAM
- q8_0 : 32 Go de VRAM
- bf16 : 60 Go de VRAM
Hugging Face recommande torch.bfloat16 pour l'efficacité, nécessitant des GPU NVIDIA compatibles (architectures Ampere ou ultérieures). L'inférence CPU-only fonctionne mais ralentit considérablement pour les contextes larges.
Les prérequis logiciels incluent Python 3.8+, pip et Git. Les frameworks comme Transformers nécessitent des installations supplémentaires. Assurez-vous que votre OS prend en charge CUDA pour l'utilisation du GPU – Ubuntu 20.04 ou Windows avec WSL2 fonctionne bien.
Si les ressources sont insuffisantes, la quantification réduit l'empreinte mémoire. Des outils comme llama.cpp ou Unsloth proposent des versions 4 bits ou 2 bits, réduisant les exigences à 15-20 Go de VRAM. Cette flexibilité permet le déploiement sur du matériel grand public comme le RTX 4090.
Une fois les exigences satisfaites, explorez les méthodes d'installation. Commencez par Ollama pour sa simplicité.
Comment installer et utiliser GLM-4.7-Flash avec Ollama
Ollama offre une plateforme accessible pour exécuter de grands modèles localement. Il gère automatiquement la quantification et la mise à disposition de l'API.
Tout d'abord, installez Ollama. Téléchargez l'exécutable pour votre OS et exécutez-le.

Vérifiez l'installation avec ollama --version, en vous assurant que la version est 0.14.3 ou ultérieure, car GLM-4.7-Flash le requiert.

Ensuite, téléchargez le modèle : exécutez ollama pull glm-4.7-flash.

Choisissez des variantes comme glm-4.7-flash:q4_K_M pour une utilisation moindre de la mémoire. La commande télécharge environ 19 Go pour la version q4.
Exécutez le modèle de manière interactive : tapez ollama run glm-4.7-flash. Saisissez des invites comme "Générer du code Python pour une suite de Fibonacci." Le modèle répond avec des sorties raisonnées, tirant parti de ses forces en matière de codage.
Pour un accès programmatique, utilisez l'API. Envoyez une requête curl :
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Ceci renvoie un JSON avec la réponse. En Python, intégrez avec la bibliothèque ollama :
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript suit de la même manière avec le package npm ollama.
Personnalisez les configurations en modifiant Modelfile. Réglez la température à 0.7 pour des sorties déterministes dans les tâches de codage. Le mode le plus récent d'Ollama récupère les publications récentes si nécessaire, mais concentrez-vous ici sur l'inférence locale.
Cette méthode convient aux configurations rapides. Cependant, pour une interface graphique, tournez-vous vers LM Studio.
Configuration de GLM-4.7-Flash dans LM Studio
LM Studio offre une interface utilisateur graphique conviviale pour la gestion des modèles. Téléchargez-le et installez-le.
Recherchez "zai-org/glm-4.7-flash" dans le hub de modèles. Sélectionnez une version quantifiée — MLX-4bit, 6bit ou 8bit — à partir des dépôts Hugging Face liés. Le téléchargement se termine dans l'application.
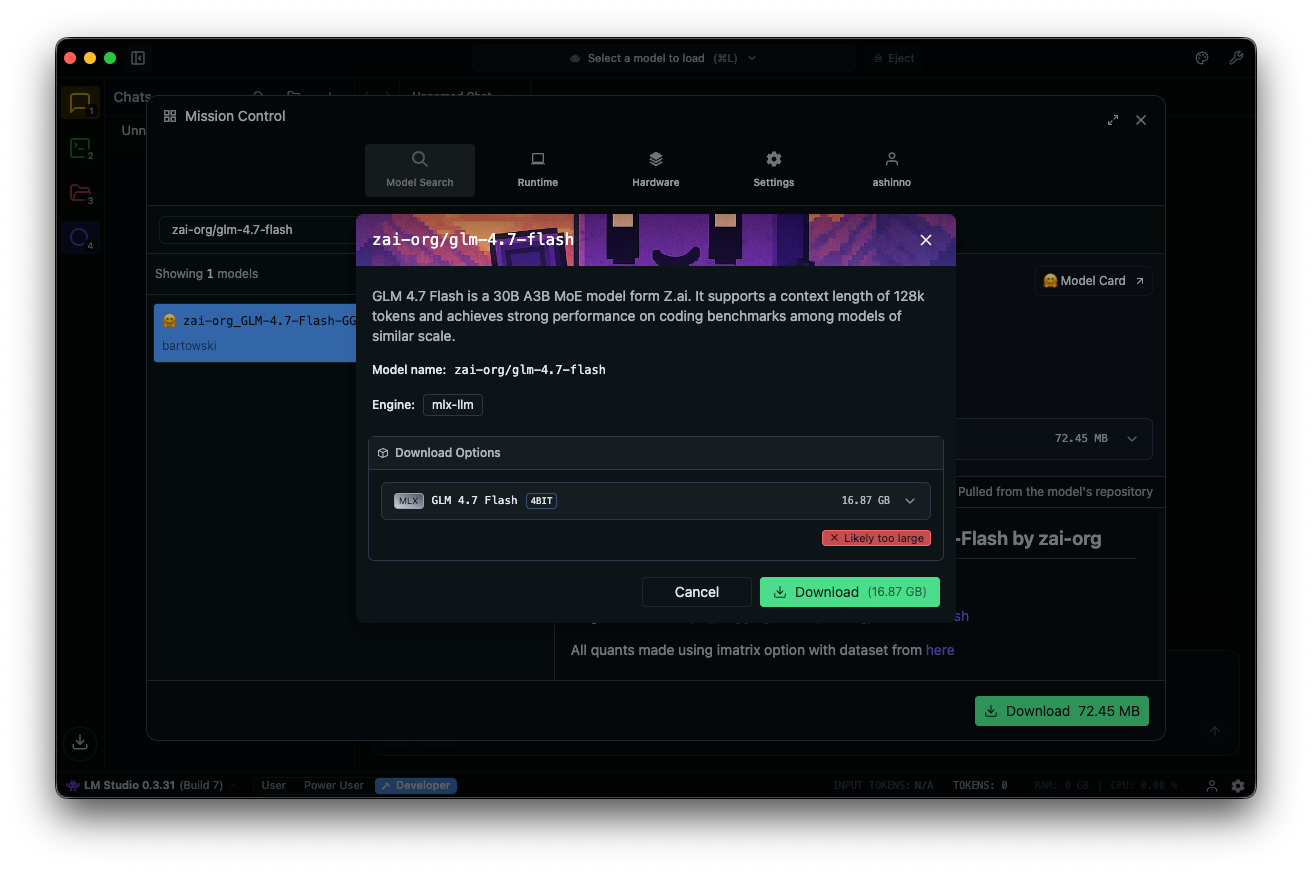
Chargez le modèle : accédez à l'interface de chat, sélectionnez GLM-4.7-Flash et ajustez les paramètres. Activez la "réflexion" (par défaut : true) pour un raisonnement étape par étape. Réglez la température à 1, top_k à 50, top_p à 0.95 et désactivez la pénalité de répétition.
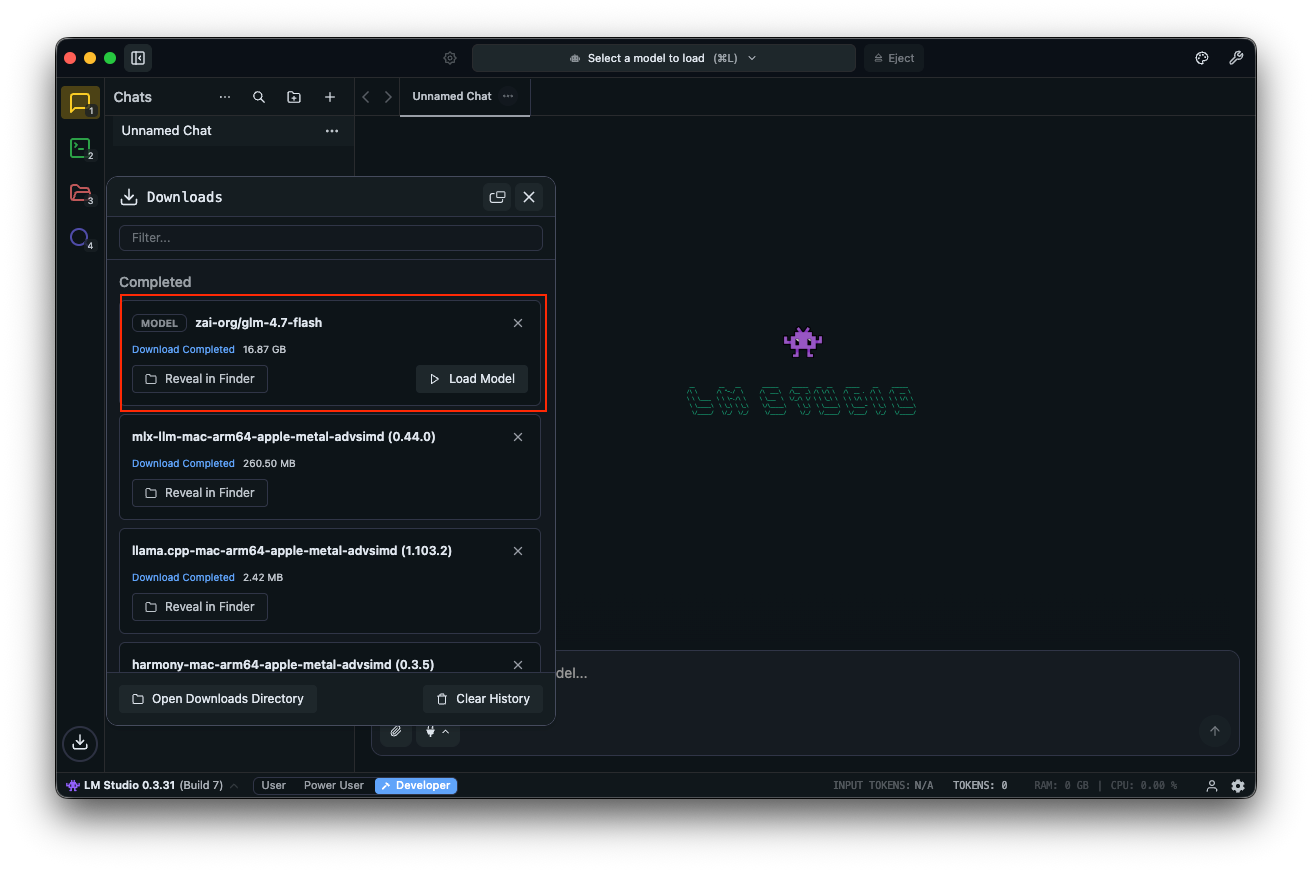
Testez avec des invites : "Concevez une API REST pour l'authentification des utilisateurs." LM Studio affiche les sorties avec les vitesses de jeton, ce qui aide à l'optimisation des performances.
Des champs personnalisés comme clear_thinking (par défaut : false) gèrent l'historique. Pour les modèles MoE, surveillez les experts actifs — A3B signifie trois actifs par passe avant, optimisant l'efficacité.
LM Studio prend en charge les liens profonds pour un accès direct au modèle. En cas de problèmes, vérifiez la mémoire système — un minimum de 16 Go évite les plantages.
Cet outil excelle pour l'expérimentation. Pour un script avancé, intégrez-le à Hugging Face.
Utilisation de GLM-4.7-Flash avec Hugging Face Transformers
Hugging Face fournit des bibliothèques robustes pour un contrôle précis. Installez Transformers à partir de la branche principale :
pip install git+https://github.com/huggingface/transformers.git
Chargez le modèle :
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Préparez les entrées :
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Générez :
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Cette configuration prend en charge la quantification via bitsandbytes pour une VRAM réduite. Ajoutez load_in_4bit=True lors du chargement du modèle.
Pour le service, utilisez vLLM ou SGLang. Installez vLLM :
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Exécutez un serveur :
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Accédez via des points de terminaison compatibles OpenAI. SGLang nécessite une installation à partir des sources et suit des étapes similaires.
Ces frameworks permettent des déploiements de qualité production. Voyons maintenant les tests d'API avec Apidog.
Intégration d'Apidog pour les tests d'API avec GLM-4.7-Flash local
Une fois que vous servez GLM-4.7-Flash via Ollama ou vLLM, testez les points de terminaison efficacement. Apidog, une plateforme API tout-en-un, facilite cela.
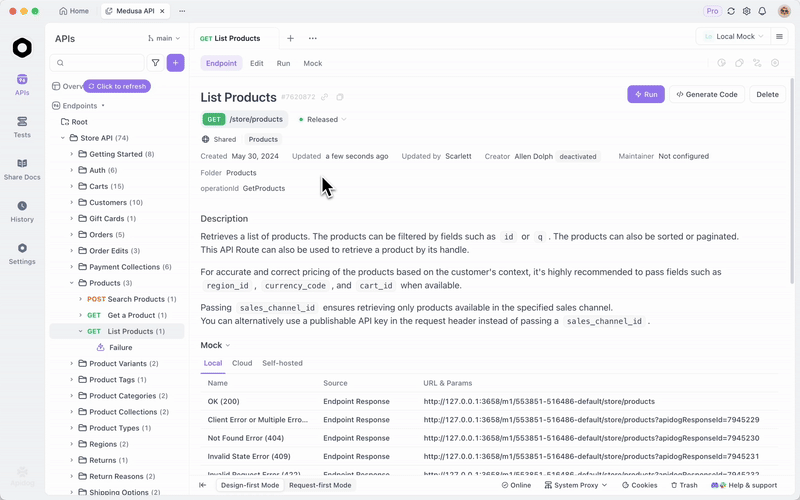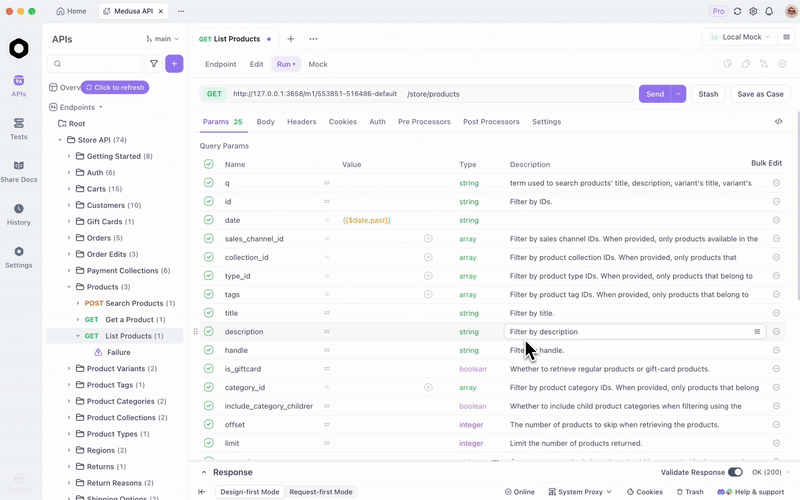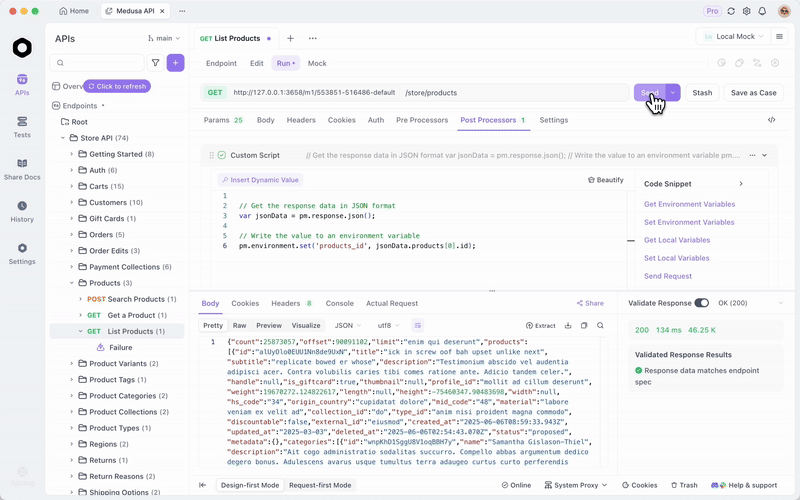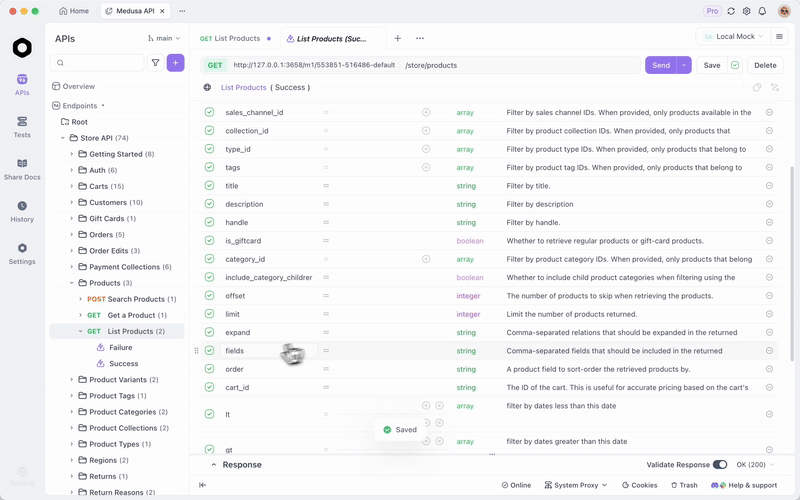
Téléchargez Apidog gratuitement. Il prend en charge les fonctionnalités d'IA en configurant votre modèle local comme fournisseur — utilisez les clés API si applicables, ou les points de terminaison directs.
Le serveur MCP d'Apidog s'intègre aux IDE comme Cursor, en utilisant les spécifications d'API pour la génération de code. Cela renvoie aux capacités de codage de GLM-4.7-Flash — testez directement les sorties agentiques.
Par exemple, interrogez votre serveur local et validez les réponses. Cela garantit la fiabilité des applications.
En s'appuyant sur les bases, passez à l'optimisation.
Conseils avancés pour optimiser les performances de GLM-4.7-Flash
Ajustez finement les paramètres pour les tâches. Réglez la température à 0.7 pour le codage, 1.0 pour l'écriture créative. Utilisez top_p 0.95 pour équilibrer la diversité.
Quantifiez davantage avec les formats GGUF via llama.cpp. Compilez llama.cpp avec CUDA, puis convertissez :
./llama-gguf-split --model GLM-4.7-Flash.gguf
Exécutez avec --jinja pour la prise en charge des modèles.
Gérez les contextes longs : Divisez les entrées si elles dépassent 128K. Activez la "réflexion" pour les requêtes complexes.
Surveillez les métriques : Des outils comme TensorBoard suivent la latence. Comparez avec les références — GLM-4.7-Flash surpasse ses pairs sur SWE-bench de 37.2 points.
Intégrez des outils : Ajoutez l'appel de fonction dans les invites pour un comportement agentique.
Sécurité : Exécutez dans des environnements isolés pour éviter les fuites de données.
Ces stratégies maximisent l'utilité. Réfléchissez ensuite aux applications.
Dépannage des problèmes courants
Des erreurs de mémoire insuffisante ? Réduisez la taille du lot ou quantifiez à un niveau inférieur.
Inférence lente ? Mettez à niveau le GPU ou utilisez des frameworks plus rapides comme vLLM.
Problèmes de compatibilité ? Mettez à jour Transformers vers la branche principale.
Si Ollama échoue, vérifiez la disponibilité du port 11434.
LM Studio plante ? Vérifiez l'intégrité du modèle.
Abordez ces problèmes de manière proactive.
Conclusion : Optimisez votre flux de travail avec GLM-4.7-Flash
L'exécution de GLM-4.7-Flash localement débloque de puissantes capacités d'IA. De la facilité d'Ollama à la flexibilité de Hugging Face, les options abondent. Intégrez Apidog pour une gestion d'API transparente — téléchargez-le gratuitement pour améliorer votre configuration.
À mesure que la technologie évolue, des modèles comme celui-ci comblent le fossé entre performance et accessibilité. Mettez en œuvre ces étapes, et vous réaliserez des déploiements d'IA efficaces et privés. De petits ajustements dans les paramètres ou les outils apportent des améliorations significatives, transformant les tâches routinières en processus rationalisés.