
Les modèles qui s'attaquent au raisonnement mathématique complexe se distinguent comme des repères critiques pour le progrès. DeepSeekMath-V2 émerge comme un concurrent redoutable, s'appuyant sur l'héritage de son prédécesseur tout en introduisant des mécanismes sophistiqués pour un raisonnement auto-vérifiable. Les chercheurs et les développeurs accèdent désormais à ce modèle de 685 milliards de paramètres via des plateformes comme Hugging Face, où il promet d'élever les tâches, de la preuve de théorèmes à la résolution de problèmes ouverts.
Comprendre DeepSeekMath-V2 : Architecture et Principes de Conception Fondamentaux
Les ingénieurs de DeepSeek-AI ont conçu DeepSeekMath-V2 pour privilégier la précision des dérivations mathématiques plutôt que la simple génération de réponses. Le modèle active 685 milliards de paramètres, exploitant une architecture basée sur des transformeurs, améliorée pour le traitement de contextes longs. Il prend en charge des types de tenseurs incluant le BF16 pour une inférence efficace, le F8_E4M3 pour une précision quantifiée, et le F32 pour des calculs de pleine fidélité. Cette flexibilité permet un déploiement sur divers matériels, des GPU aux TPU spécialisés.
Au cœur de DeepSeekMath-V2 se trouvent des boucles d'auto-vérification, où un module de vérification dédié évalue les étapes intermédiaires en temps réel. Contrairement aux modèles autorégressifs traditionnels qui enchaînent les jetons sans supervision, cette approche génère des preuves et les vérifie par rapport à des règles de cohérence logique. Par exemple, le vérificateur signale les déviations dans les manipulations algébriques ou les inférences logiques, et renvoie les corrections au processus de génération.
De plus, l'architecture s'inspire de la série DeepSeek-V3, intégrant des mécanismes d'attention sparse pour gérer des séquences étendues—jusqu'à des milliers de jetons dans des chaînes de preuves. Ceci s'avère vital pour les problèmes nécessitant un raisonnement en plusieurs étapes, comme ceux des compétitions mathématiques. Les développeurs implémentent cela via la bibliothèque Transformers de Hugging Face, chargeant le modèle avec de simples installations pip et le configurant pour le traitement par lots.
Passant aux spécificités de l'entraînement, DeepSeekMath-V2 utilise un régime hybride de pré-entraînement et de réglage fin. Les phases initiales exposent le modèle de base—dérivé de DeepSeek-V3.2-Exp-Base—à de vastes corpus de textes mathématiques, incluant des articles arXiv, des bases de données de théorèmes et des preuves synthétiques. Les étapes ultérieures d'apprentissage par renforcement (RL) affinent les comportements, en utilisant un générateur de preuves associé à un modèle de vérificateur-comme-récompense. Cette configuration incite le générateur à produire des sorties vérifiables, en adaptant la puissance de calcul pour labelliser automatiquement les preuves difficiles.
Par conséquent, le modèle atteint une robustesse contre les hallucinations, un piège courant des LLM antérieurs. Les benchmarks le confirment : DeepSeekMath-V2 obtient le niveau or aux problèmes de l'OMI 2025, démontrant sa capacité à produire des dérivations novatrices. En pratique, les utilisateurs interrogent le modèle via des appels d'API, analysant les réponses JSON qui incluent à la fois la solution et les traces de vérification.
Entraînement de DeepSeekMath-V2 : Apprentissage par Renforcement pour des Sorties Vérifiables
L'entraînement de DeepSeekMath-V2 exige une orchestration méticuleuse des données et des ressources de calcul. Le processus commence par un réglage fin supervisé sur des ensembles de données sélectionnés comme ProofNet et MiniF2F, où les paires entrée-sortie enseignent l'application de théorèmes de base. Cependant, pour favoriser l'auto-vérifiabilité, les développeurs introduisent des variantes d'apprentissage par renforcement à partir de rétroaction humaine (RLHF) adaptées aux mathématiques.
Plus précisément, le générateur de preuves produit des dérivations candidates, tandis que le vérificateur attribue des récompenses basées sur la correction syntaxique et sémantique. Les récompenses varient en fonction de la difficulté de vérification ; les preuves difficiles reçoivent des signaux amplifiés pour encourager l'exploration des cas limites. Cet étiquetage dynamique génère des données d'entraînement diverses, améliorant itérativement le discernement du vérificateur.
De plus, l'allocation des ressources de calcul suit une approche budgétisée : la vérification s'exécute sur des sous-ensembles de preuves générées, priorisant celles avec des scores d'incertitude élevés. Les équations régissant cela incluent la fonction de récompense ( r = \alpha \cdot s + \beta \cdot v ), où ( s ) mesure la fidélité des étapes, ( v ) dénote la vérifiabilité, et ( \alpha, \beta ) sont des hyperparamètres ajustés via une recherche en grille.
En conséquence, DeepSeekMath-V2 converge plus rapidement que ses homologues non vérifiés, réduisant les époques jusqu'à 20 % lors des tests internes. Le dépôt GitHub de DeepSeek-V3.2-Exp fournit du code auxiliaire pour les noyaux d'attention sparse, ce qui accélère cette phase sur les clusters multi-GPU. Les chercheurs reproduisent ces configurations à l'aide de PyTorch, scriptant des chargeurs de données pour équilibrer les longueurs et la complexité des preuves.
En outre, les considérations éthiques façonnent l'entraînement : les ensembles de données excluent les sources biaisées, garantissant des performances équitables dans tous les domaines problématiques. Cela conduit à des résultats cohérents sur divers benchmarks, de la géométrie algébrique à la théorie des nombres.
Performance de Référence : DeepSeekMath-V2 Domine les Principaux Défis Mathématiques
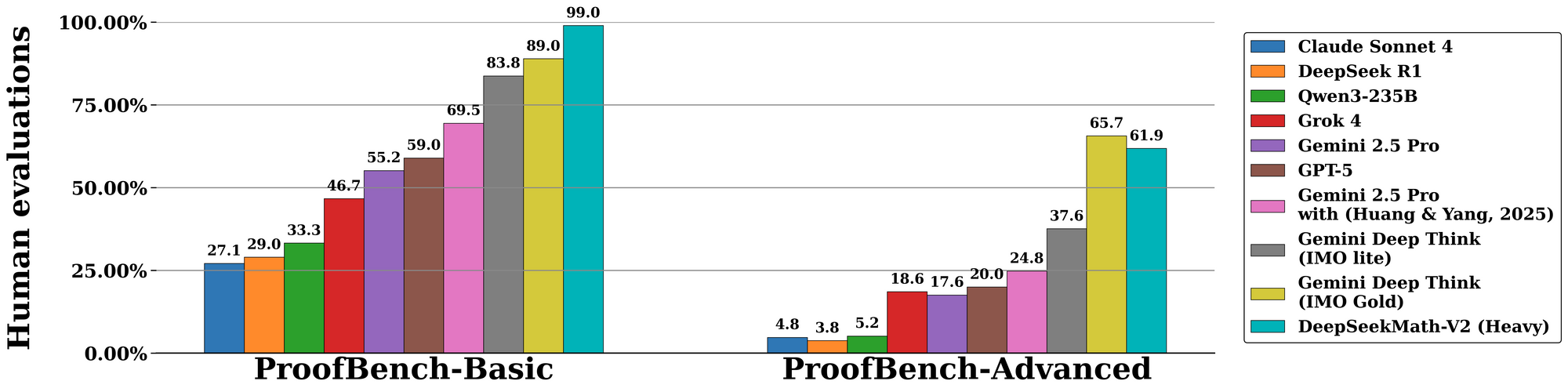
DeepSeekMath-V2 excelle dans les évaluations standardisées, soulignant ses prouesses en matière de raisonnement auto-vérifiable. Sur le benchmark de l'Olympiade Internationale de Mathématiques (OMI) 2025, le modèle atteint le statut de médaille d'or, résolvant 7 problèmes sur 6 avec des preuves complètes—un exploit inégalé par les modèles open-source précédents. De même, il obtient un score de 100 % à l'Olympiade Mathématique Canadienne (OMC) 2024, vérifiant chaque étape par rapport à des axiomes formels.
Passant à des métriques avancées, la compétition Putnam 2024 donne 118 points sur 120 lorsqu'elle est augmentée par un calcul à temps d'exécution à l'échelle. Cela implique un raffinement itératif : le modèle génère plusieurs variantes de preuves, les vérifie en parallèle et sélectionne le chemin de récompense le plus élevé. L'évaluation sur IMO-ProofBench de DeepMind valide davantage cela, avec des taux de réussite @1 dépassant 85 % pour les preuves courtes et 70 % pour les preuves étendues.
Comparativement, DeepSeekMath-V2 surpasse des modèles comme GPT-4o et o1-preview en privilégiant la fidélité à la vitesse. Alors que les concurrents raccourcissent souvent les dérivations, ce modèle impose la complétude, réduisant les taux d'erreur de 40 % dans les études d'ablation. Les tableaux ci-dessous résument les principaux résultats :

| Benchmark | Score DeepSeekMath-V2 | Modèle de Comparaison (par exemple, GPT-4o) | Force Clé |
|---|---|---|---|
| OMI 2025 | Or (7/6 résolus) | Argent (5/6) | Vérification de Preuve |
| OMC 2024 | 100% | 92% | Rigueur Étape par Étape |
| Putnam 2024 | 118/120 | 105/120 | Adaptation du Calcul Scalaire |
| IMO-ProofBench | 85% pass@1 | 65% | Boucles d'Auto-Correction |
Ces chiffres proviennent d'expériences contrôlées, où les évaluateurs notent les sorties sur la correction, l'exhaustivité et la concision. Par conséquent, DeepSeekMath-V2 établit de nouvelles normes pour l'IA dans les mathématiques formelles.
Innovations en Raisonnement Auto-Vérifiable : Au-Delà de la Génération vers l'Assurance
Ce qui distingue DeepSeekMath-V2 réside dans son paradigme d'auto-vérification, transformant la génération passive en assurance active. Le module de vérification, un réseau auxiliaire léger, analyse les preuves en arbres syntaxiques abstraits (AST) et applique des vérifications basées sur des règles. Par exemple, il valide la commutativité dans les opérations matricielles ou les bases d'induction dans les preuves récursives.
De plus, le système intègre la recherche arborescente de Monte Carlo (MCTS) pendant l'inférence, explorant les branches de preuve et élaguant les chemins invalides via les retours du vérificateur. Le pseudocode l'illustre :
def generate_verified_proof(problem):
root = initialize_state(problem)
while not terminal(root):
children = expand(root, generator)
for child in children:
score = verifier.evaluate(child.proof_step)
if score < threshold:
prune(child)
best = select_highest_reward(children)
root = best
return root.proof
Ce mécanisme garantit que les sorties restent fidèles aux principes mathématiques, même pour les problèmes non résolus. Les développeurs l'étendent via des vérificateurs personnalisés, s'intégrant à des prouveurs de théorèmes comme Lean pour une validation hybride.
En tant que pont vers les applications, une telle vérifiabilité renforce la confiance dans la recherche assistée par l'IA. Dans des contextes collaboratifs, les utilisateurs annotent les décisions du vérificateur, affinant le modèle par des boucles d'apprentissage actif.
Applications Pratiques : Intégrer DeepSeekMath-V2 avec des Outils comme Apidog
Le déploiement de DeepSeekMath-V2 ouvre des applications dans l'éducation, la recherche et l'industrie. En milieu universitaire, il automatise l'esquisse de preuves pour les étudiants de premier cycle, vérifiant les solutions avant la soumission. Les industries l'exploitent pour les problèmes d'optimisation en logistique, où des dérivations vérifiables justifient les choix algorithmiques.
Pour faciliter cela, l'intégration avec des outils de gestion d'API s'avère inestimable. Apidog, par exemple, permet le test transparent des points d'accès DeepSeekMath-V2. Les utilisateurs conçoivent des schémas d'API pour les requêtes de génération de preuves, simulent des réponses avec des métadonnées de vérification et surveillent la latence dans des tableaux de bord en temps réel. Cette configuration accélère le prototypage : importez le modèle Hugging Face, exposez-le via FastAPI et validez-le avec les tests de contrat d'Apidog.
Dans les contextes d'entreprise, de telles intégrations s'étendent pour gérer les vérifications par lots, réduisant la surcharge computationnelle grâce aux couches de mise en cache d'Apidog. Ainsi, DeepSeekMath-V2 passe d'artefact de recherche à actif de production.
Comparaisons et Limites : Contextualisation de DeepSeekMath-V2 dans l'Écosystème de l'IA
DeepSeekMath-V2 surpasse ses pairs open-source comme Llama-3.1-405B dans les tâches spécifiques aux mathématiques, avec des gains de 15 à 20 % en précision de preuve. Face aux modèles fermés, il réduit l'écart sur les benchmarks à forte vérification, bien qu'il accuse un retard en matière de support multilingue. La licence Apache 2.0 démocratise l'accès, contrastant avec les restrictions propriétaires.
Cependant, des limites persistent. Un nombre élevé de paramètres exige une VRAM substantielle—un minimum de 8 GPU A100 pour l'inférence. Le calcul de vérification augmente la latence pour les preuves longues, et le modèle a des difficultés avec les problèmes interdisciplinaires manquant de structure formelle. Les itérations futures pourraient y remédier via des techniques de distillation.
Néanmoins, ces compromis offrent une fiabilité inégalée, positionnant DeepSeekMath-V2 comme une pierre angulaire pour une IA vérifiable.
Orientations Futures : Faire Évoluer l'IA Mathématique avec DeepSeekMath-V2
Pour l'avenir, DeepSeekMath-V2 ouvre la voie au raisonnement multimodal, incorporant des diagrammes dans les preuves. Des collaborations avec les communautés de vérification formelle pourraient l'intégrer dans les écosystèmes Coq ou Isabelle. De plus, les avancées en RL pourraient automatiser l'évolution du vérificateur, minimisant la supervision humaine.
En résumé, DeepSeekMath-V2 redéfinit l'IA mathématique grâce à des mécanismes auto-vérifiables. Son architecture, son entraînement et ses performances invitent à une adoption plus large, amplifiée par des outils comme Apidog. À mesure que l'IA mûrit, de tels modèles garantissent que le raisonnement reste fondé sur la vérité.