
Les développeurs s'appuient de plus en plus sur des modèles d'IA avancés pour améliorer l'efficacité du codage, automatiser les flux de travail complexes et créer des applications intelligentes. Claude Opus 4.5 d'Anthropic s'impose comme une solution de premier plan dans ce domaine, offrant des performances supérieures en ingénierie logicielle, pour les tâches agentiques et le raisonnement en plusieurs étapes. Ce modèle établit de nouvelles références en matière de codage et d'utilisation informatique en conditions réelles, le rendant essentiel pour les équipes techniques travaillant sur des projets de niveau production.
Ce guide vous apporte les connaissances techniques nécessaires pour exploiter efficacement Claude Opus 4.5. Nous abordons la configuration, les mécanismes fondamentaux de l'API, les configurations avancées et les stratégies d'optimisation. En suivant ces étapes, vous positionnez vos applications pour tirer parti de la fenêtre contextuelle de 200 000 jetons du modèle, de l'utilisation améliorée des outils et de la gestion efficace des jetons. Par conséquent, vous obtenez des cycles de développement plus rapides et des fonctionnalités basées sur l'IA plus fiables.
Qu'est-ce que Claude Opus 4.5 ?
Les ingénieurs d'Anthropic ont conçu Claude Opus 4.5 comme leur modèle phare, en privilégiant la profondeur du raisonnement, la précision du codage et l'autonomie agentique. Cette itération s'appuie sur les versions précédentes en intégrant des avancées en matière de traitement de la vision, de précision mathématique et de résolution d'ambiguïtés. Par exemple, le modèle excelle dans la gestion des compromis dans des scénarios complexes, tels que la modification d'itinéraires de vol dans des simulations d'entreprise ou le débogage de vastes bases de code sans directives explicites.
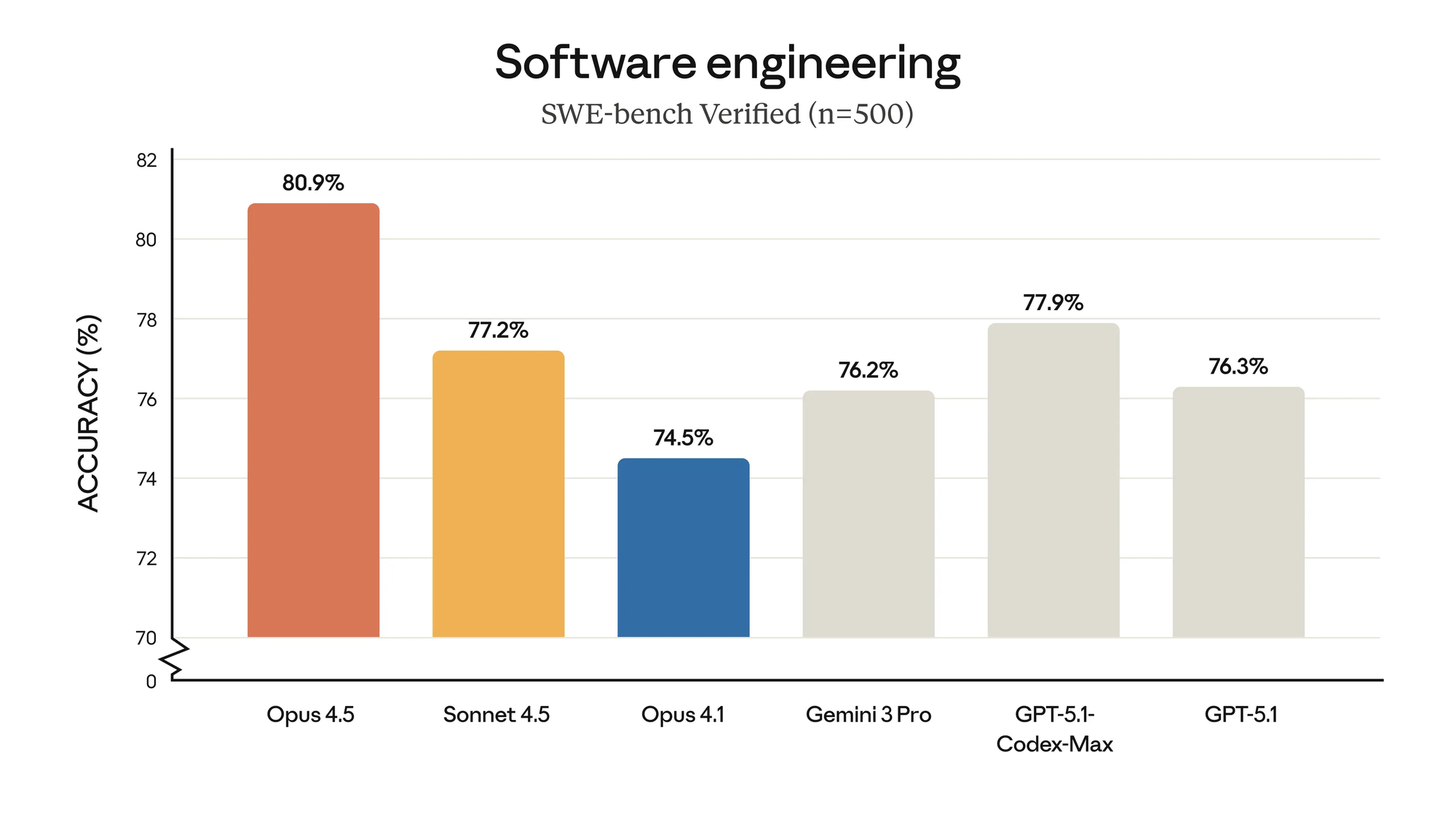
Les capacités clés incluent des résultats de pointe sur SWE-bench Verified, où il surpasse ses prédécesseurs de jusqu'à 4,3 points de pourcentage tout en utilisant 48 % moins de jetons de sortie à effort maximal.
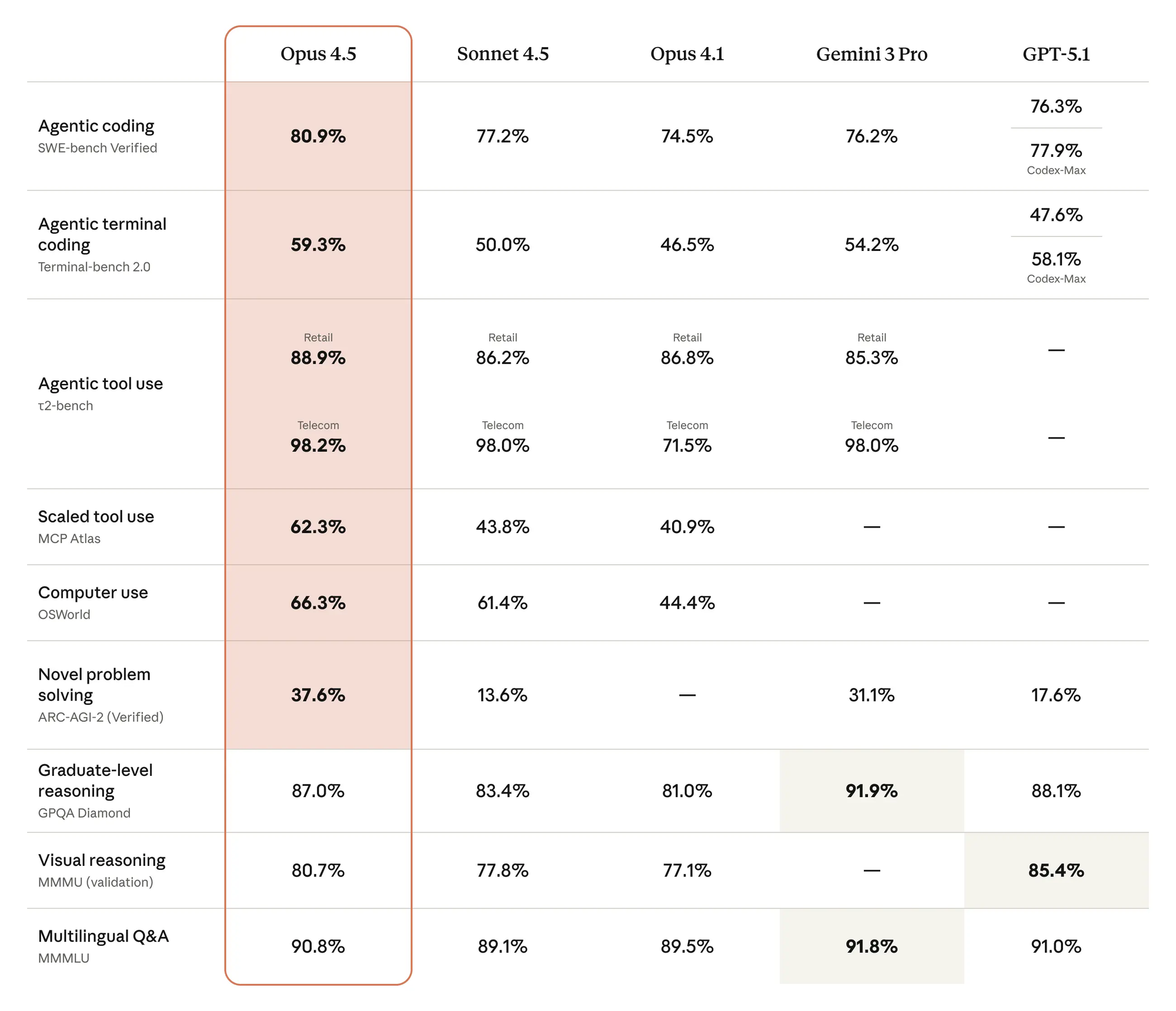
Les développeurs accèdent à ces atouts via l'API Claude, qui prend en charge une fenêtre contextuelle de 200 000 jetons, idéale pour l'analyse de longs documents ou les revues de code multifichiers. De plus, le modèle s'intègre parfaitement aux plateformes cloud comme Amazon Bedrock, Google Vertex AI et Microsoft Foundry, permettant des déploiements évolutifs.
La tarification reflète son positionnement premium : 5 $ par million de jetons d'entrée et 25 $ par million de jetons de sortie, avec des économies grâce à la mise en cache des invites (jusqu'à 90 %) et au traitement par lots (50 %). Cependant, ces coûts soulignent la nécessité de modèles d'utilisation précis, que nous aborderons plus loin. En substance, Claude Opus 4.5 permet aux développeurs de construire des agents qui gèrent des projets de bout en bout, de la planification initiale à l'exécution, avec une supervision humaine minimale.
Configuration de votre environnement de développement
Vous commencez par préparer un environnement robuste pour interagir avec l'API Claude. Tout d'abord, obtenez une clé API depuis la Console Anthropic à l'adresse console.anthropic.com. Inscrivez-vous ou connectez-vous, naviguez vers la section "Clés API" et générez une nouvelle clé. Stockez-la en toute sécurité—utilisez des variables d'environnement comme export ANTHROPIC_API_KEY='votre-clé-ici' dans votre terminal ou des fichiers .env à la racine de votre projet.
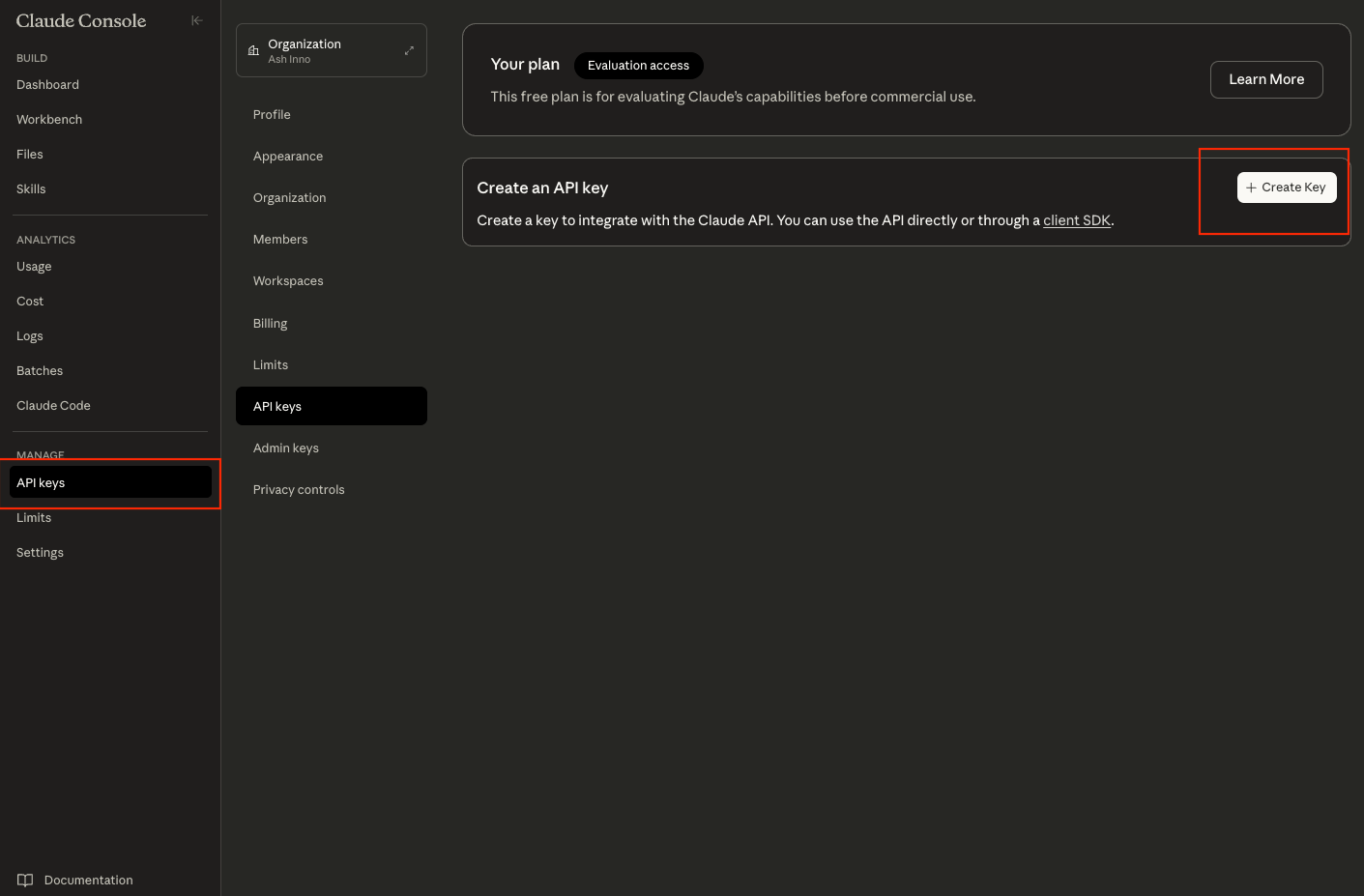
Ensuite, installez le SDK officiel d'Anthropic, qui abstrait les complexités HTTP et gère les nouvelles tentatives. Pour Python, exécutez pip install anthropic. Cette bibliothèque prend en charge les appels synchrones et asynchrones, essentiels pour les applications à haut débit. De même, les développeurs Node.js exécutent npm install @anthropic-ai/sdk. Vérifiez l'installation en important le module : en Python, import anthropic; client = anthropic.Anthropic(api_key=os.getenv('ANTHROPIC_API_KEY')).
Pour les tests, intégrez Apidog dès le début. Cet outil génère des commandes curl et des collections Postman à partir de vos expériences SDK, assurant la cohérence entre les équipes. Importez votre clé API dans les variables d'environnement d'Apidog et créez une nouvelle requête vers le point de terminaison /v1/messages. Une telle préparation prévient les pièges courants comme les erreurs d'authentification, vous permettant de vous concentrer sur l'ingénierie des invites.
Une fois configuré, confirmez la connectivité avec un simple contrôle de santé. Envoyez une requête de base pour valider votre clé et votre réseau. Cette étape confirme que votre environnement gère les limites de débit de l'API—initialement 50 requêtes par minute pour les modèles Opus, évolutives avec les niveaux d'utilisation.
Authentification et bases de l'API
Anthropic applique l'authentification via des jetons Bearer, un mécanisme standard inspiré d'OAuth2. Incluez votre clé API dans l'en-tête Authorization sous la forme Bearer ${ANTHROPIC_API_KEY} pour chaque requête. L'URL de base est https://api.anthropic.com/v1, avec le point de terminaison principal /messages pour les complétions de chat.
Les requêtes suivent une structure de charge utile JSON. Définissez un champ model spécifiant claude-opus-4-5-20251101, l'identifiant exact de cette version. Ajoutez un tableau messages contenant des paires rôle-contenu : les invites système définissent des directives comportementales, tandis que les messages utilisateur déclenchent des réponses. Par exemple :
{
"model": "claude-opus-4-5-20251101",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
]
}
Le SDK simplifie cela : en Python, client.messages.create(model="claude-opus-4-5-20251101", max_tokens=1024, messages=[{"role": "user", "content": "Votre invite ici"}]). Les réponses renvoient un tableau content avec des deltas de texte pour le streaming, ou des blocs complets pour le mode batch.
Les limites de débit s'appliquent par organisation : Opus 4.5 est plafonné à 10 000 jetons par minute initialement, avec des rafales allant jusqu'à 50 000. Surveillez via les en-têtes de réponse comme x-ratelimit-remaining. En cas de dépassement, implémentez un backoff exponentiel dans votre code— le SDK gère cela nativement avec retry_on=anthropic.RetryStatus.SERVER_ERROR.
Les meilleures pratiques de sécurité incluent la rotation trimestrielle des clés et leur restriction à des plages d'adresses IP spécifiques dans la console. Ainsi, vous maintenez la conformité dans les environnements d'entreprise tout en adaptant les appels API.
Effectuer votre première requête API
Exécutez votre première requête pour comprendre le rythme de l'API. Commencez par une requête simple qui teste les capacités de raisonnement du modèle. En Python :
import anthropic
import os
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=500,
messages=[
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n=20."}
]
)
print(response.content[0].text)
Ce code invoque le modèle, qui génère un code efficace utilisant la mémoïsation—mettant en valeur son aptitude au codage. La réponse arrive en moins de 2 secondes avec l'effort par défaut, avec environ 150 jetons de sortie pour des résultats concis.
Pour le streaming, ajoutez stream=True à l'appel. Cela produit des deltas incrémentiels, idéaux pour les interfaces utilisateur en temps réel. Analysez-les via une boucle de générateur :
stream = client.messages.stream(
model="claude-opus-4-5-20251101",
max_tokens=500,
messages=[{"role": "user", "content": "Your streaming prompt"}]
)
for text in stream:
print(text.content[0].text, end="", flush=True)
Apidog complète cela en visualisant les flux dans son visualiseur de réponses, mettant en évidence la consommation de jetons. Expérimentez ici pour affiner les invites avant la production.
Gérez les erreurs de manière proactive. Un statut 429 indique une limitation ; interceptez-le avec des blocs try-except. De même, les 400 signalent un JSON malformé—validez les charges utiles à l'aide du vérificateur de schéma d'Apidog. Grâce à ces bases, vous construisez une fondation pour des intégrations plus complexes.
Fonctionnalités avancées : Contrôle de l'effort et gestion du contexte
Claude Opus 4.5 introduit le paramètre effort, un élément clé pour équilibrer vitesse et profondeur. Définissez-le sur "low", "medium" ou "high" dans les requêtes : "low" privilégie les réponses rapides (latence inférieure à la seconde), tandis que "high" alloue un temps de calcul prolongé pour des sorties nuancées, augmentant les benchmarks comme SWE-bench de 15 points.
Intégrez-le ainsi :
response = client.messages.create(
model="claude-opus-4-5-20251101",
effort="high",
max_tokens=2000,
messages=[{"role": "user", "content": "Analyze tradeoffs in microservices vs. monoliths for a fintech app."}]
)
À effort élevé, le modèle utilise des brouillons intercalés et un budget de réflexion de 64K, produisant des tableaux détaillés d'avantages/inconvénients. Cependant, cela augmente les coûts—un effort moyen suffit souvent pour 80 % des tâches, égalant l'efficacité de Sonnet 4.5 avec 76 % moins de jetons.
La gestion du contexte suit le même principe. La fenêtre de 200 000 permet d'accueillir des référentiels entiers ; utilisez le SDK de compaction côté client pour résumer les échanges précédents. Installez via pip install anthropic-compaction, puis :
from anthropic.compaction import compact_context
compacted = compact_context(previous_messages)
# Append to new messages array
Cette fonctionnalité brille dans les boucles agentiques, où les agents conservent une mémoire entre les sessions. Pour les systèmes multi-agents, définissez des sous-agents via des appels d'outils, permettant à Opus 4.5 d'orchestrer des équipes—par exemple, une pour la recherche, une autre pour la validation.
En passant aux outils, Opus 4.5 prend en charge des définitions avancées. Déclarez des schémas JSON pour des fonctions comme les requêtes de base de données :
{
"name": "get_user_data",
"description": "Fetch user profile",
"input_schema": {"type": "object", "properties": {"user_id": {"type": "string"}}}
}
Le modèle invoque les outils de manière autonome, analysant les arguments et injectant les résultats dans les suivis. Cela permet des flux de travail hybrides, tels que des agents enchaînés via API pour des analyses de cybersécurité.
Intégration d'outils et construction d'agents
L'utilisation d'outils élève Claude Opus 4.5 à des sommets agentiques. Définissez les outils dans le tableau tools des requêtes. Le modèle décide de l'invocation en fonction du contexte, générant des appels formatés en XML pour plus de précision.
Exemple : Intégrer un outil d'API météo.
tools = [
{
"name": "get_weather",
"description": "Retrieve current weather for a city",
"input_schema": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
]
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=1000,
tools=tools,
messages=[{"role": "user", "content": "Plan a trip to Paris; check weather."}]
)
Si le modèle appelle l'outil, extrayez de response.stop_reason == "tool_use", exécutez-le extérieurement et ajoutez la sortie comme message de résultat d'outil. Bouclez jusqu'à la complétion pour une exécution complète de l'agent.
Pour l'utilisation informatique, activez les fonctionnalités bêta via les en-têtes. Cela permet l'inspection et l'automatisation de l'écran, avec l'outil Zoom pour l'analyse au niveau du pixel—crucial pour le débogage de l'interface utilisateur.
Apidog simplifie les tests d'outils : simulez des points de terminaison dans son simulateur, puis exportez vers le code SDK. Cette approche itérative améliore la fiabilité des agents, réduisant les appels hallucinés.

Dans les configurations multi-agents, utilisez des outils de mémoire pour la persistance de l'état. Stockez les faits clés dans un outil memory, interrogé par les sous-agents. Par conséquent, les systèmes gèrent des tâches complexes comme les audits logiciels, où un agent planifie, et d'autres exécutent.
Gestion des erreurs et meilleures pratiques
Les applications robustes anticipent les échecs. Implémentez une gestion complète des erreurs pour les particularités de l'API. Pour les erreurs 4xx, enregistrez le error.type (par exemple, "invalid_request") et réessayez avec des charges utiles corrigées. Utilisez la bibliothèque tenacity pour les décorateurs :
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def safe_api_call(prompt):
return client.messages.create(model="claude-opus-4-5-20251101", messages=[{"role": "user", "content": prompt}])
Surveillez l'utilisation des jetons via usage dans les réponses—entrée, sortie et succès du cache. Définissez des budgets dynamiquement : si la sortie dépasse 80 % de max_tokens, tronquez et résumez.
Les meilleures pratiques incluent l'ingénierie des invites avec des balises XML pour la structure : <thinking>Reason step-by-step</thinking><output>Final answer</output>. Cela guide le modèle, surtout à faible effort. De plus, activez la sécurité via des invites system imposant des directives éthiques.
Pour la production, regroupez les requêtes pour réduire les coûts : mettez en file d'attente les requêtes non urgentes et traitez-les par centaines. Mettez en cache les invites fréquentes pour 90 % d'économies. Auditez régulièrement les sorties pour l'alignement—Opus 4.5 résiste aux injections, mais validez les données sensibles.
Optimisation des performances et des coûts
L'optimisation assure une utilisation durable. Profilez les requêtes avec les analyses d'Apidog : suivez la latence, la dépense en jetons et les taux de succès. Identifiez les goulots d'étranglement, comme les invites verbeuses, et condensez-les en utilisant la compaction.
Tirez parti de la mise en cache des invites : étiquetez les préfixes réutilisables avec cache_control: {"type": "ephemeral"}. Lors des correspondances, ne payez que 25 % pour les entrées. Pour les agents, maintenez le cache persistant entre les appels pour conserver le contexte à moindre coût.
Mettez à l'échelle avec des modèles asynchrones. En Node.js :
const { Anthropic } = require('@anthropic-ai/sdk');
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
async function parallelRequests(prompts) {
const promises = prompts.map(p =>
anthropic.messages.create({ model: 'claude-opus-4-5-20251101', messages: [{role: 'user', content: p}] })
);
return Promise.all(promises);
}
Cela gère efficacement les bifurcations d'agents concurrentes. À effort élevé, plafonnez le budget de réflexion à 32K pour le contrôle des coûts sans sacrifier la qualité.
Comparez votre configuration aux références : Opus 4.5 atteint 72,5 % sur SWE-bench, alors testez des évaluations personnalisées. Ajustez l'effort par tâche—faible pour l'idéation, élevé pour la vérification.
Conclusion
Vous possédez désormais les outils pour intégrer efficacement l'API Claude Opus 4.5 à votre pile technologique. De la configuration initiale à l'orchestration des agents, ce guide vous montre la voie pour exploiter ses atouts en matière de codage et de raisonnement. N'oubliez pas que de petits ajustements—comme la mise en cache ou le réglage de l'effort—apportent des gains substantiels en termes de performances et d'économie.
Expérimentez de manière itérative, en utilisant Apidog pour valider chaque couche. Au fur et à mesure que vous construisez, surveillez les mises à jour d'Anthropic pour les améliorations. En fin de compte, Claude Opus 4.5 transforme le développement d'un labeur manuel en une intelligence orchestrée. Commencez à implémenter dès aujourd'hui et regardez vos projets évoluer avec précision.