
La famille Qwen 3 domine le paysage des LLM open-source en 2026. Les ingénieurs déploient ces modèles partout, des agents d'entreprise essentiels aux assistants mobiles. Avant de commencer à envoyer des requêtes à Alibaba Cloud ou à auto-héberger, optimisez votre flux de travail avec Apidog.
Aperçu de Qwen 3 : Innovations architecturales stimulant les performances en 2026
L'équipe Qwen d'Alibaba a lancé la série Qwen 3 le 29 avril 2026, marquant une avancée capitale dans les grands modèles linguistiques (LLM) open-source. Les développeurs saluent sa licence Apache 2.0, qui permet un réglage fin et un déploiement commercial sans restriction. À la base, Qwen 3 utilise une architecture basée sur Transformer avec des améliorations des embeddings positionnels et des mécanismes d'attention, prenant en charge nativement des longueurs de contexte allant jusqu'à 128K tokens — et extensible à 131K via YaRN.

De plus, la série intègre des conceptions de Mixture-of-Experts (MoE) dans certaines variantes, n'activant qu'une fraction des paramètres pendant l'inférence. Cette approche réduit la charge computationnelle tout en maintenant une haute fidélité dans les sorties. Par exemple, les ingénieurs signalent un débit jusqu'à 10 fois plus rapide sur les tâches à long contexte par rapport aux prédécesseurs denses comme Qwen2.5-72B. En conséquence, les variantes de Qwen 3 s'adaptent efficacement à divers matériels, des appareils périphériques aux clusters cloud.
Qwen 3 excelle également dans la prise en charge multilingue, gérant plus de 119 langues avec une interprétation nuancée des instructions. Les benchmarks confirment son avantage dans les domaines STEM, où il traite des données synthétiques de mathématiques et de code raffinées à partir de 36 billions de tokens. Par conséquent, les applications dans les entreprises mondiales bénéficient de la réduction des erreurs de traduction et de l'amélioration du raisonnement interlingue. Pour être plus précis, le mode de raisonnement hybride — activé via des drapeaux de tokenizer — permet aux modèles d'engager une logique étape par étape pour les mathématiques ou le codage, ou de passer par défaut au mode "non-pensée" pour le dialogue. Cette dualité permet aux développeurs d'optimiser par cas d'utilisation.
Fonctionnalités clés unifiant les variantes de Qwen 3
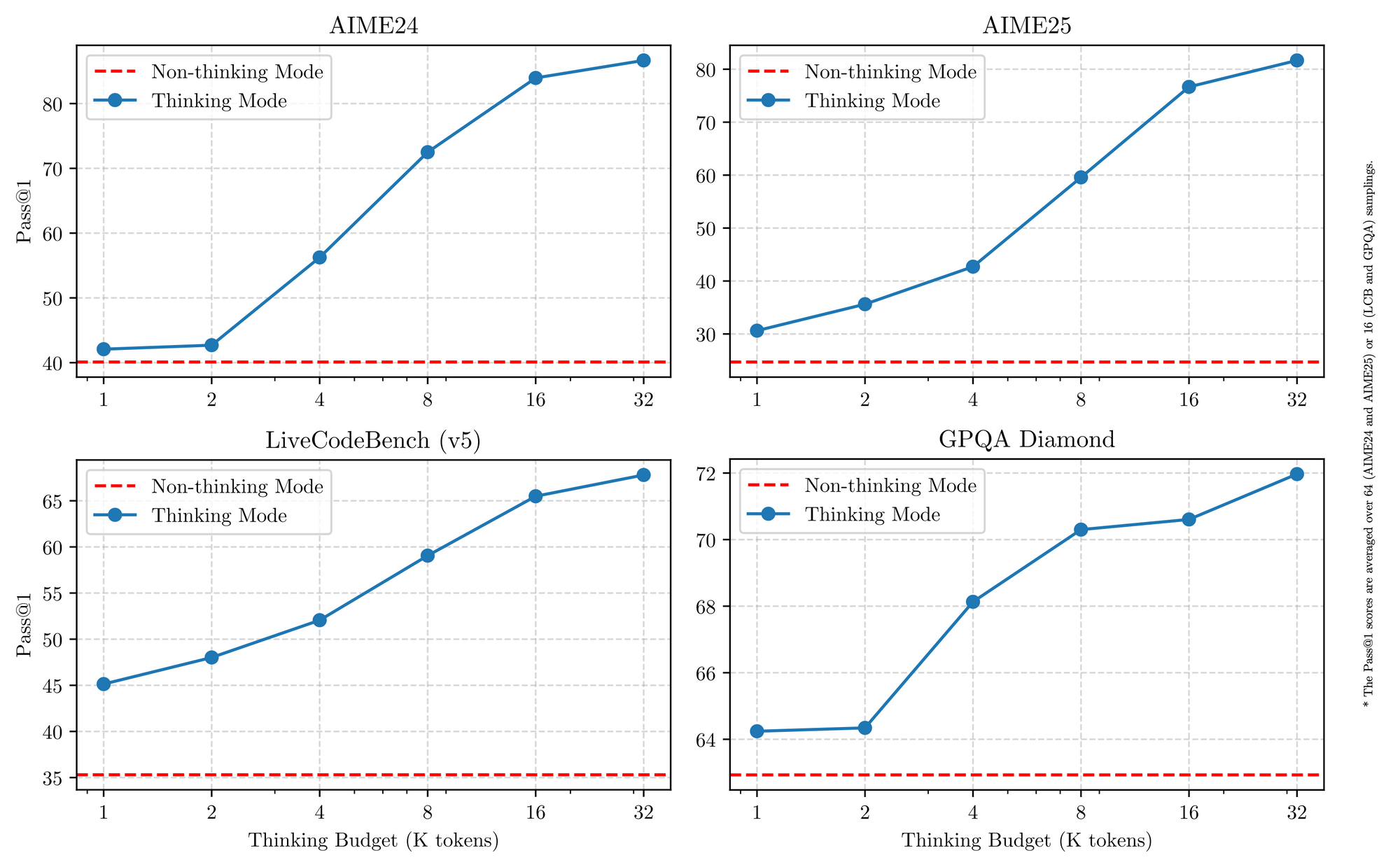
Tous les modèles Qwen 3 partagent des caractéristiques fondamentales qui augmentent leur utilité en 2026. Premièrement, ils prennent en charge un fonctionnement à double mode : le mode de pensée (thinking mode) active les processus de chaîne de pensée pour des benchmarks comme AIME25, tandis que le mode sans pensée (non-thinking mode) privilégie la vitesse pour les applications de chat. Les ingénieurs basculent entre ces modes avec de simples paramètres, atteignant jusqu'à 92,3 % de précision sur des problèmes mathématiques complexes sans sacrifier la latence.
Deuxièmement, les fonctionnalités d'agent (agentic features) permettent un appel d'outils transparent, surpassant les modèles open-source concurrents dans des tâches comme la navigation web ou l'exécution de code. Par exemple, les variantes de Qwen 3 obtiennent un score de 69,6 sur Tau2-Bench Verified, rivalisant avec les modèles propriétaires. De plus, la maîtrise multilingue couvre les dialectes du mandarin au swahili, avec un score de 73,0 sur les benchmarks MultiIF.
Troisièmement, l'efficacité provient des variantes quantifiées (par exemple, Q4_K_M) et des frameworks comme vLLM ou SGLang, qui délivrent 25 tokens/seconde sur les GPU grand public. Cependant, les modèles plus grands exigent plus de 16 Go de VRAM, ce qui incite aux déploiements cloud. Les tarifs restent compétitifs, avec des tokens d'entrée à 0,20 $ – 1,20 $ par million via Alibaba Cloud.
De plus, Qwen 3 met l'accent sur la sécurité grâce à une modération intégrée, réduisant les hallucinations de 15 % par rapport à Qwen2.5. Les développeurs tirent parti de cela pour des applications de qualité production, des moteurs de recommandation e-commerce aux analyseurs juridiques. À mesure que nous passons aux variantes individuelles, ces forces partagées fournissent une base de comparaison cohérente.
Les 5 meilleures variantes du modèle Qwen 3 en 2026
Basé sur les benchmarks de 2026 de LMSYS Arena, LiveCodeBench et SWE-Bench, nous classons les cinq meilleures variantes de Qwen 3. Les critères de sélection incluent les scores de raisonnement, la vitesse d'inférence, l'efficacité des paramètres et l'accessibilité de l'API. Chacune excelle dans des scénarios distincts, mais toutes font progresser les frontières de l'open-source.
1. Qwen3-235B-A22B – Le Monstre MoE Phare Absolu
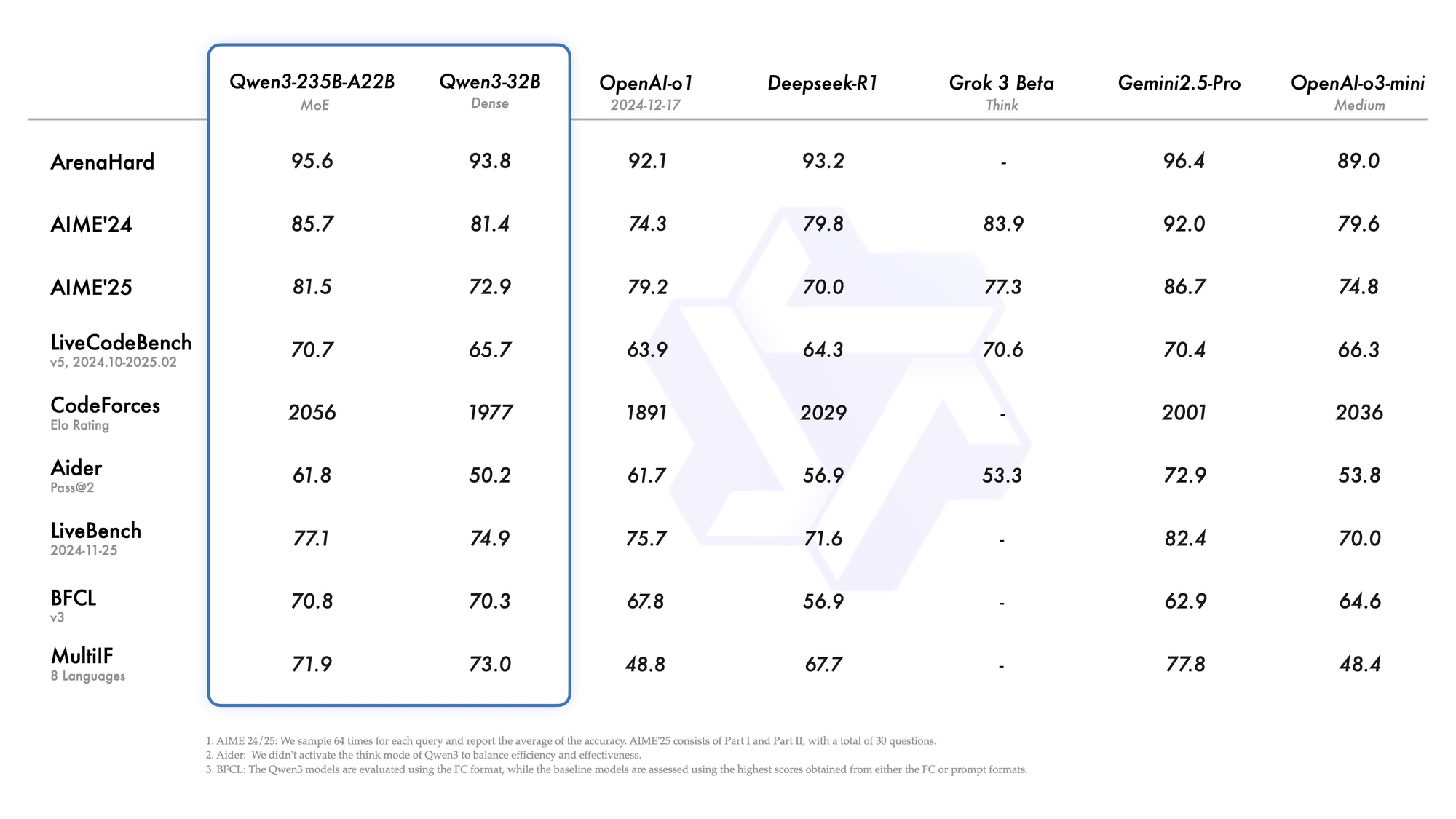
Qwen3-235B-A22B attire l'attention en tant que variante MoE de premier plan, avec 235 milliards de paramètres totaux et 22 milliards actifs par token. Lancé en juillet 2026 sous le nom de Qwen3-235B-A22B-Instruct-2507, il active huit experts via un routage top-k, réduisant la consommation de calcul de 90 % par rapport aux équivalents denses. Les benchmarks le placent au coude à coude avec Gemini 2.5 Pro : 95,6 sur ArenaHard, 77,1 sur LiveBench et un leadership dans CodeForces Elo (menant de 5 %).
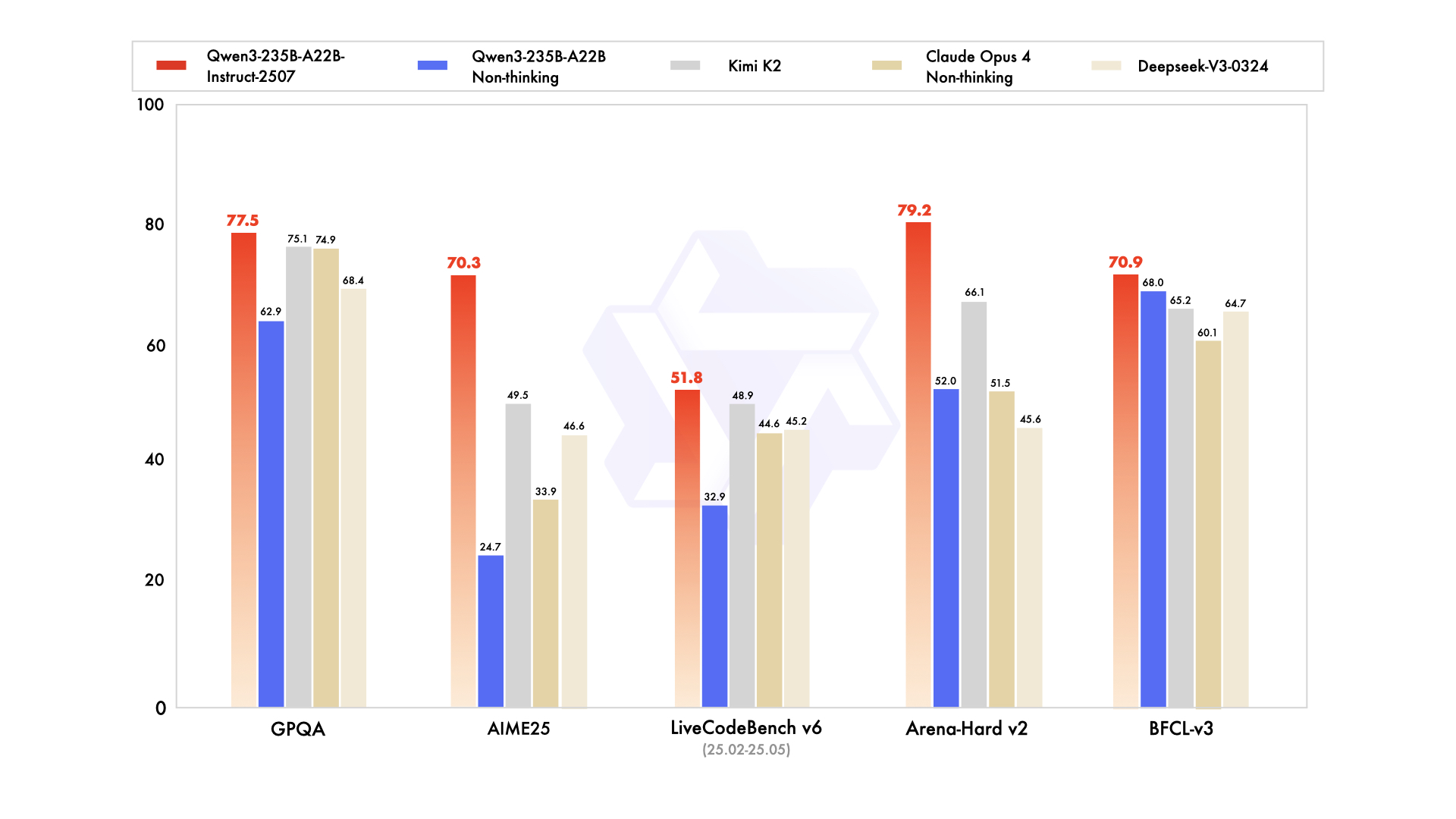
En codage, il atteint 74,8 sur LiveCodeBench v6, générant du TypeScript fonctionnel avec un minimum d'itérations. Pour les mathématiques, le mode de pensée (thinking mode) produit 92,3 sur AIME25, résolvant des intégrales multi-étapes par déduction explicite. Les tâches multilingues affichent 73,0 sur MultiIF, traitant les requêtes arabes sans faute.
Le déploiement privilégie les API cloud, où il gère des contextes de 256K. Cependant, les exécutions locales nécessitent 8 GPU H100. Les ingénieurs l'intègrent pour des workflows basés sur des agents, comme le débogage à l'échelle d'un dépôt. Globalement, cette variante établit la norme 2026 en matière de profondeur, bien que son échelle convienne aux équipes à gros budget.
Points forts
- Égale ou dépasse Gemini 2.5 Pro et Claude 3.7 Sonnet sur presque tous les classements 2026 (95,6 ArenaHard, 92,3 AIME25 en mode pensée, 74,8 LiveCodeBench v6).
- Excelle dans les workflows d'agents multi-tours, l'appel d'outils complexes et la compréhension de code au niveau du dépôt.
- Gère un contexte de 256K à 1M avec YaRN sans perte de qualité.
- Le mode pensée offre un raisonnement vérifiable de type "chaîne de pensée" qui rivalise avec les modèles de pointe propriétaires.
Points faibles
- Extrêmement coûteux et lent en local — nécessite 8×H100 ou équivalent pour une latence raisonnable.
- Le prix de l'API est le plus élevé de la famille (1,20 $ – 6,00 $/M tokens de sortie au pic de contexte).
- Surdimensionné pour 95 % des charges de travail de production ; la plupart des équipes ne saturent jamais sa capacité.
Quand l'utiliser
- Agents autonomes de niveau entreprise qui doivent résoudre des problèmes mathématiques de niveau doctorat, déboguer des bases de code entières ou effectuer des analyses de contrats juridiques avec une hallucination quasi nulle.
- Laboratoires de recherche à gros budget qui repoussent les limites de l'état de l'art sur de nouveaux benchmarks.
- Backends de raisonnement internes où le coût par token est secondaire par rapport à l'intelligence maximale.
2. Qwen3-30B-A3B – Le Champion MoE Idéal
Qwen3-30B-A3B apparaît comme la solution de référence pour les configurations aux ressources limitées, avec 30,5 milliards de paramètres totaux et 3,3 milliards actifs. Sa structure MoE — 48 couches, 128 experts (huit routés) — reflète celle du fleuron mais avec une empreinte 10 fois moindre. Mis à jour en juillet 2026, il surpasse QwQ-32B par un facteur 10 en efficacité active, obtenant 91,0 sur ArenaHard et 69,6 sur SWE-Bench Verified.
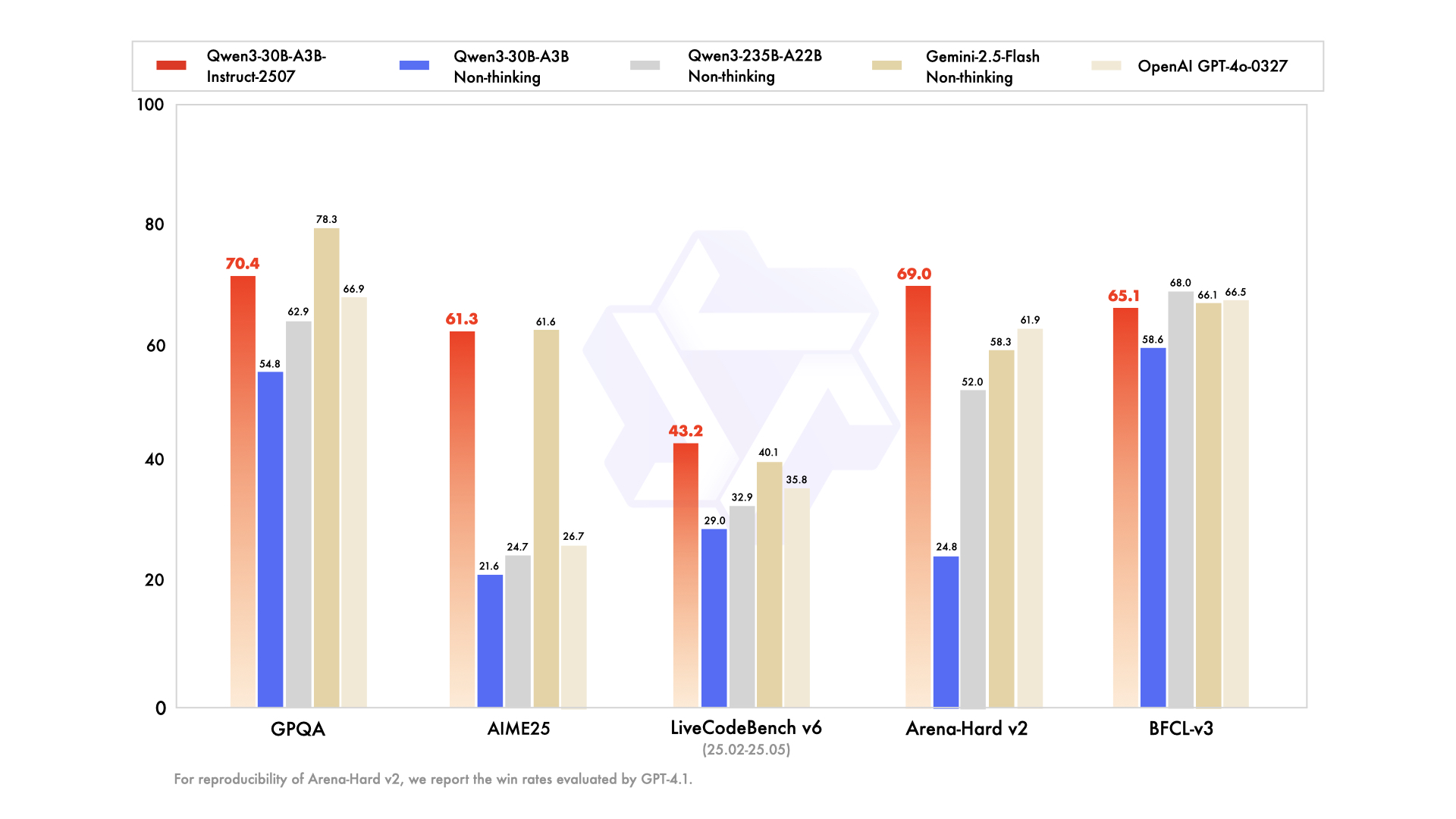
Les évaluations de codage soulignent ses prouesses : 32,4 % de réussite@5 sur les nouvelles PR GitHub, égalant GPT-5-High. Les benchmarks mathématiques montrent 81,6 sur AIME25 en mode pensée, rivalisant avec ses homologues plus grands. Avec un contexte de 131K via YaRN, il traite de longs documents sans troncature.
Points forts
- Paramètres actifs 10 fois moins chers que le 235B tout en conservant environ 90 à 95 % de la qualité de raisonnement du fleuron (91,0 ArenaHard, 81,6 AIME25).
- Fonctionne confortablement sur une seule A100 de 80 Go ou deux cartes de 40 Go avec vLLM + FlashAttention.
- Meilleur rapport prix-performance parmi tous les modèles MoE ouverts de 2026.
- Surpasse tous les modèles denses de 72B à 110B en codage et en mathématiques.
Points faibles
- Nécessite toujours environ 24 à 30 Go de VRAM en FP8/INT4 ; non compatible avec les ordinateurs portables.
- Légèrement moins de fluidité en écriture créative que les modèles denses purs de taille similaire.
- La latence du mode pensée augmente de 2 à 3 fois par rapport au mode sans pensée.
Quand l'utiliser
- Agents de codage de production, revues de PR automatisées ou copilotes DevOps internes.
- Pipelines de recherche à haut débit nécessitant un raisonnement mathématique ou scientifique de pointe avec un budget raisonnable.
- Toute équipe ayant précédemment utilisé Llama-405B ou Mixtral-123B mais souhaitant un meilleur raisonnement à moindre coût.
3. Qwen3-32B – Le Roi Polyvalent Dense
Le Qwen3-32B dense offre 32 milliards de paramètres entièrement actifs, privilégiant le débit brut à la parcimonie. Entraîné sur 36T tokens, il égale Qwen2.5-72B en performances de base mais excelle dans l'alignement post-entraînement. Les benchmarks révèlent 89,5 sur ArenaHard et 73,0 sur MultiIF, avec une forte capacité d'écriture créative (par exemple, les récits de jeux de rôle obtenant 85 % de préférence humaine).
En codage, il mène BFCL à 68,2, générant des interfaces utilisateur par glisser-déposer à partir de prompts. Les mathématiques donnent 70,3 sur AIME25, bien qu'il soit à la traîne par rapport aux MoE en matière de "chaîne de pensée". Son contexte de 128K convient aux bases de connaissances, et le mode sans pensée (non-thinking mode) augmente la vitesse de dialogue à 20 tokens/seconde.
Points forts
- Suivi d'instructions et production créative exceptionnels — souvent préféré aux modèles MoE plus grands lors d'évaluations humaines aveugles pour l'écriture et les jeux de rôle.
- Facile à affiner avec LoRA/QLoRA sur du matériel grand public (16–24 Go de VRAM).
- Inférence la plus rapide parmi les modèles qui surpassent toujours GPT-4o sur de nombreuses tâches (89,5 ArenaHard).
- Très fortes performances multilingues sur plus de 119 langues.
Points faibles
- Accuse un retard d'environ 8 à 12 points par rapport aux modèles MoE similaires sur les benchmarks mathématiques et de codage les plus difficiles lorsque le mode pensée est activé.
- Pas d'astuces d'efficacité des paramètres — chaque token coûte le calcul complet de 32B.
Quand l'utiliser
- Plateformes de génération de contenu, assistants d'écriture de romans, outils de rédaction marketing.
- Projets nécessitant un réglage fin intensif (chatbots spécifiques à un domaine, transfert de style).
- Équipes qui veulent une qualité quasi-phare mais doivent rester en dessous de 24 Go de VRAM.
4. Qwen3-14B – La Puissance Mobile et Edge
Qwen3-14B privilégie la portabilité avec 14,8 milliards de paramètres, prenant en charge des contextes de 128K sur du matériel de milieu de gamme. Il rivalise avec Qwen2.5-32B en efficacité, obtenant 85,5 sur ArenaHard et échangeant des coups avec Qwen3-30B-A3B en mathématiques/codage (à moins de 5 % de marge). Quantifié en Q4_0, il fonctionne à 24,5 tokens/seconde sur des mobiles comme le RedMagic 8S Pro.
Les tâches d'agent (agentic tasks) affichent 65,1 sur Tau2-Bench, permettant l'utilisation d'outils dans des applications à faible latence. Le support multilingue brille, avec 70 % de précision sur l'inférence dialectale. Pour les appareils périphériques (edge devices), il traite 32K contextes hors ligne, idéal pour l'analyse IoT.
Les ingénieurs apprécient son empreinte pour l'apprentissage fédéré, où la confidentialité l'emporte sur l'échelle. Ainsi, il convient aux assistants IA mobiles ou aux systèmes embarqués.
Points forts
- Fonctionne à 24–30 tokens/sec sur les téléphones modernes (Snapdragon 8 Gen 4, Dimensity 9400) lorsqu'il est quantifié en Q4_K_M.
- Dépasse toujours Qwen2.5-32B et Llama-3.1-70B sur la plupart des benchmarks de raisonnement.
- Excellent pour le RAG embarqué (on-device RAG) avec un contexte de 32K à 128K.
- Coût API le plus bas dans la tranche de performances de premier ordre.
Points faibles
- Commence à rencontrer des difficultés avec les tâches d'agent multi-étapes qui nécessitent plus de 5 appels d'outils.
- Qualité d'écriture créative nettement inférieure à celle des modèles 32B+.
- Moins pérenne à mesure que les benchmarks continuent d'augmenter.
Quand l'utiliser
- Assistants embarqués (applications Android/iOS, wearables).
- Déploiements sensibles à la confidentialité (santé, finance) où les données ne peuvent pas quitter l'appareil.
- Systèmes embarqués en temps réel (robots, voitures, passerelles IoT).
5. Qwen3-8B – Le Cheval de Bataille Léger Ultime pour le Prototypage
Pour compléter le top cinq, Qwen3-8B offre 8 milliards de paramètres pour une itération rapide, surpassant Qwen2.5-14B sur 15 benchmarks. Il atteint 81,5 sur AIME25 (mode sans pensée) et 60,2 sur LiveCodeBench, suffisant pour des revues de code de base. Avec un contexte natif de 32K, il se déploie sur les ordinateurs portables via Ollama, atteignant 25 tokens/seconde.
Cette variante convient aux débutants testant le chat multilingue ou des agents simples. Son mode de pensée (thinking mode) améliore les puzzles logiques, obtenant un score de 75 % sur les tâches de déduction. En conséquence, il accélère les preuves de concept avant de passer à des modèles plus grands.
Points forts
- Fonctionne à plus de 25 tokens/sec même sur des ordinateurs portables avec 8 à 12 Go de VRAM (MacBook M3 Pro, RTX 4070 mobile).
- Suivi d'instructions étonnamment compétent — surpasse Gemma-2-27B et Phi-4-14B sur la plupart des classements 2026.
- Parfait pour l'expérimentation locale avec Ollama ou LM Studio.
- Tarification API la plus économique de la famille.
Points faibles
- Plafond de raisonnement évident sur les problèmes de mathématiques de niveau supérieur et les problèmes de codage avancés.
- Plus sujet aux hallucinations dans les tâches intensives en connaissances.
- Contexte limité (32K natif, 128K avec YaRN mais plus lent).
Quand l'utiliser
- Prototypage rapide et construction de MVP.
- Outils éducatifs, assistants personnels ou projets de loisirs.
- Couche de routage frontend dans les systèmes hybrides (utiliser 8B pour le triage, escalader vers 30B/235B si nécessaire).
Tarification des API et considérations de déploiement pour les modèles Qwen 3
L'accès à Qwen 3 via des API démocratise l'IA avancée, avec Alibaba Cloud en tête à des tarifs compétitifs. La tarification est basée sur les tokens : pour Qwen3-235B-A22B, l'entrée coûte 0,20 $ – 1,20 $/million (gamme 0–252K), la sortie 1,00 $ – 6,00 $/million. Qwen3-30B-A3B reflète cela à 80 % du taux, tandis qu'un modèle dense comme Qwen3-32B descend à 0,15 $ d'entrée / 0,75 $ de sortie.
Des fournisseurs tiers comme Together AI proposent Qwen3-32B à 0,80 $/1M tokens totaux, avec des remises sur volume. Les "cache hits" réduisent les factures : implicites à 20 %, explicites à 10 %. Comparé à GPT-5 (3–15 $/1M), Qwen 3 est 70 % moins cher, permettant une mise à l'échelle rentable.
Conseils de déploiement : Utilisez vLLM pour le traitement par lots, SGLang pour la compatibilité OpenAI. Apidog améliore cela en simulant les points de terminaison Qwen, en testant les charges utiles et en générant des documents — essentiels pour les pipelines CI/CD. Les exécutions locales via Ollama conviennent au prototypage, mais les API excellent pour la production.
Les fonctionnalités de sécurité comme la limitation de débit et la modération ajoutent de la valeur, sans frais supplémentaires. Par conséquent, les équipes soucieuses de leur budget sélectionnent en fonction du volume de tokens : petites variantes pour le développement, fleurons pour l'inférence.
Tableau de décision – Choisissez votre modèle Qwen 3 en 2026
| Rang | Modèle | Paramètres (Total/Actif) | Résumé des points forts | Principaux points faibles | Idéal pour | Coût API approx. (Entrée/Sortie par 1M tokens) | VRAM minimale (quantifiée) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Raisonnement maximal, agentique, maths, code | Extrêmement cher et lourd | Recherche de pointe, agents d'entreprise, précision zéro tolérance | 0,20 $ – 1,20 $ / 1,00 $ – 6,00 $ | 64 Go+ (cloud) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Meilleur rapport qualité-prix, raisonnement solide | Nécessite toujours un GPU serveur | Agents de codage de production, backends math/science, inférence à grand volume | 0,16 $ – 0,96 $ / 0,80 $ – 4,80 $ | 24–30 Go |
| 3 | Qwen3-32B | 32B Dense | Écriture créative, réglage fin facile, vitesse | Reste derrière MoE sur les tâches les plus difficiles | Plateformes de contenu, réglage fin de domaine, chatbots multilingues | 0,15 $ / 0,75 $ | 16–20 Go |
| 4 | Qwen3-14B | 14.8B Dense | Compatible edge/mobile, excellent RAG embarqué | Capacité d'agent multi-étapes limitée | IA embarquée, applications critiques pour la confidentialité, systèmes embarqués | 0,12 $ / 0,60 $ | 8–12 Go |
| 5 | Qwen3-8B | 8B Dense | Vitesse ordinateur portable/téléphone, le moins cher | Plafond évident sur les tâches complexes | Prototypage, assistants personnels, couche de routage dans les systèmes hybrides | 0,10 $ / 0,50 $ | 4–8 Go |
Recommandation finale pour 2026
La plupart des équipes en 2026 devraient opter par défaut pour Qwen3-30B-A3B — il offre plus de 90 % de la puissance du fleuron pour une fraction du coût et des exigences matérielles. Ne passez au 235B-A22B que si vous avez réellement besoin des 5 à 10 % supplémentaires de qualité de raisonnement et que vous disposez du budget. Descendez au 32B dense pour les charges de travail créatives ou de réglage fin intensif, et utilisez le 14B/8B lorsque la latence, la confidentialité ou les contraintes de l'appareil sont prédominantes.
Quelle que soit la variante que vous choisissez, Apidog vous fera gagner des heures de débogage d'API. Téléchargez-le gratuitement dès aujourd'hui et commencez à développer avec Qwen 3 en toute confiance.