
Les développeurs recherchent constamment des outils qui augmentent l'efficacité sans compromettre la précision. L'intégration par Cursor des modèles GPT-5.1 Codex d'OpenAI en est un excellent exemple, offrant une suite de variantes spécialisées conçues pour les flux de travail agentiques. Ces modèles transforment la manière dont vous gérez la génération de code, le débogage et le refactoring directement depuis votre IDE.
Comprendre Cursor Codex : La Fondation de l'intégration GPT-5.1
Cursor Codex fait référence à la famille avancée de modèles d'OpenAI affinés pour les tâches de codage et exploités de manière transparente au sein de l'IDE Cursor. Les développeurs activent ces modèles via un sélecteur dédié, permettant aux agents IA de lire des fichiers, d'exécuter des commandes shell et d'appliquer des modifications de manière autonome. Cette configuration repose sur un harnais personnalisé qui aligne les invites et les outils avec l'entraînement des modèles, garantissant des performances fiables dans des référentiels complexes.
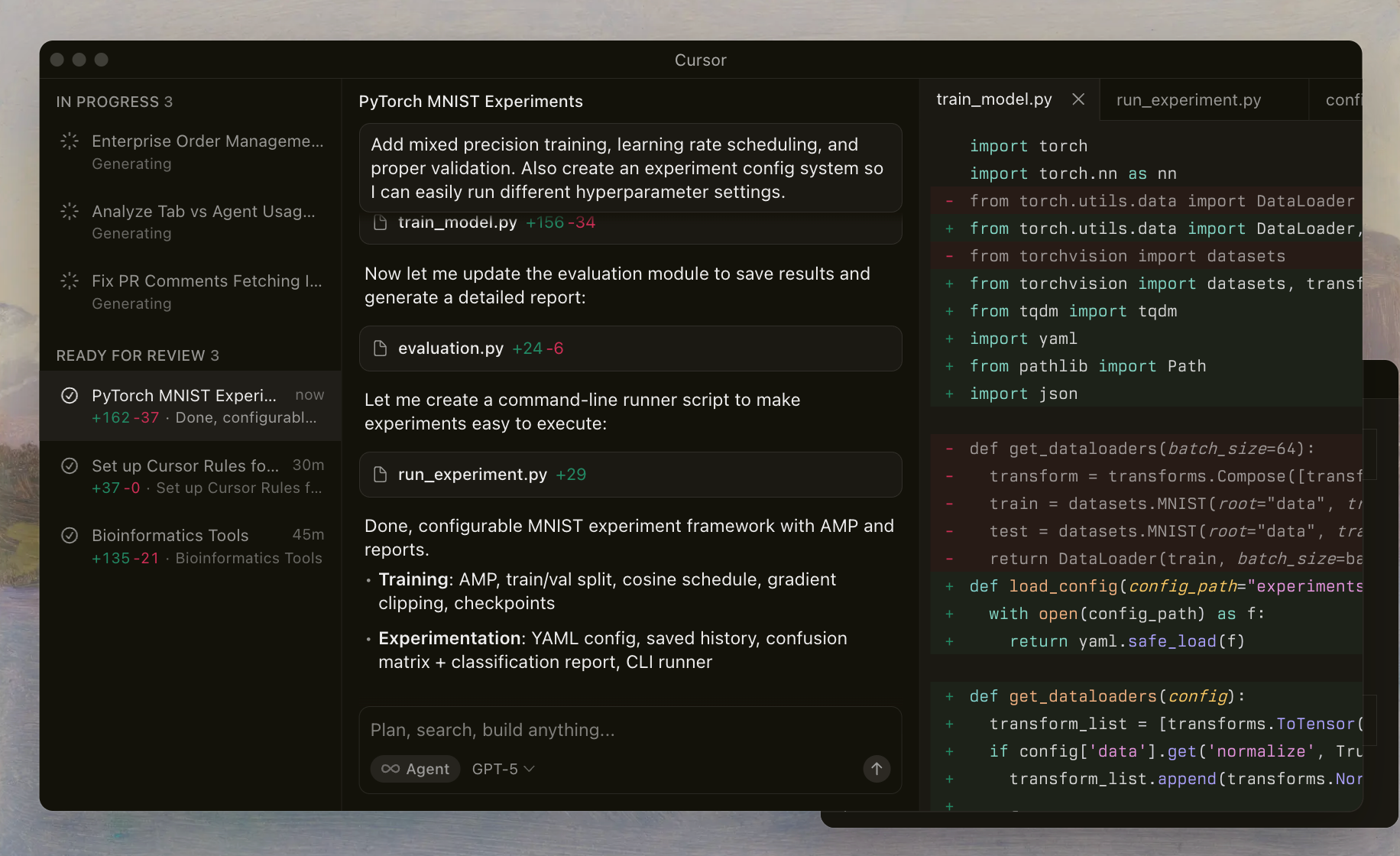
La série GPT-5.1 s'appuie sur les itérations précédentes en mettant l'accent sur les capacités agentiques, ce qui signifie que les modèles agissent comme des assistants intelligents qui planifient, itèrent et s'auto-corrigent. Contrairement aux LLM à usage général, Cursor Codex privilégie les flux de travail orientés shell. Par exemple, les modèles apprennent à invoquer des outils pour l'inspection de fichiers ou le linting, réduisant ainsi les hallucinations et améliorant la précision des modifications.
L'implémentation de Cursor inclut des garanties telles que les traces de raisonnement, qui préservent le processus de pensée du modèle à travers les interactions. Cette continuité évite l'écueil courant de la perte de contexte dans les sessions à plusieurs tours. En expérimentant ces modèles, vous remarquerez comment ils gèrent les cas limites, tels que la résolution des conflits de fusion ou l'optimisation du code asynchrone.
En passant aux spécificités, OpenAI a publié la gamme GPT-5.1 Codex fin 2025, coïncidant avec la mise à jour du cadre d'agents de Cursor. Ce calendrier permet aux développeurs de tirer parti d'une intelligence de pointe pour les tâches quotidiennes, du prototypage de microservices à l'audit de systèmes existants.
Présentation de la famille de modèles GPT-5.1 Codex
Cursor propose une vaste gamme de variantes GPT-5.1 Codex, chacune optimisée pour des compromis distincts en termes d'intelligence, de vitesse et d'utilisation des ressources. Vous y accédez via le sélecteur de modèle dans l'IDE, où des bascules indiquent la disponibilité et la sélection actuelle. Ci-dessous, nous présentons chacune d'entre elles, en soulignant les attributs fondamentaux dérivés de la documentation du harnais de Cursor et des benchmarks internes.
GPT-5.1 Codex Max : Le fleuron pour les tâches exigeantes
GPT-5.1 Codex Max est la pierre angulaire de la famille. Les ingénieurs d'OpenAI ont entraîné ce modèle sur de vastes ensembles de données de sessions de codage agentiques, incorporant des outils spécifiques à Cursor comme l'exécution de shell et les lecteurs de lint. Il excelle dans le maintien d'un raisonnement à long contexte, traitant jusqu'à 512K tokens sans dégradation.
Ses principales caractéristiques incluent l'appel adaptatif d'outils : le modèle sélectionne dynamiquement entre des modifications directes et des replis basés sur Python pour des modifications complexes. Par exemple, lors du refactoring d'une application Node.js, Codex Max génère un plan, invoque git diff pour la validation et applique les changements de manière atomique.
Les benchmarks révèlent ses prouesses. Sur la suite d'évaluation interne de Cursor – qui mesure les taux de réussite dans des référentiels réels – Codex Max atteint 78 % de résolution pour les tâches multi-fichiers, surpassant les équivalents GPT-4.5 de 15 %. Cependant, il nécessite une puissance de calcul plus élevée, avec des temps d'inférence moyens de 2 à 3 secondes par tour sur du matériel standard.
Les développeurs privilégient ce modèle pour les projets à l'échelle de l'entreprise, où la précision l'emporte sur la vitesse. Si votre flux de travail implique l'intégration d'API, couplez-le avec Apidog pour valider automatiquement les schémas générés.
GPT-5.1 Codex Mini : Puissance compacte pour des itérations rapides
Ensuite, GPT-5.1 Codex Mini réduit le nombre de paramètres tout en conservant 85 % de la fidélité de codage de Max. Cette variante cible les environnements légers, tels que le développement d'applications mobiles ou les pipelines CI/CD. Il traite 128K tokens et privilégie les réponses à faible latence, en affichant moins d'une seconde pour la plupart des requêtes.
Le modèle utilise des connaissances distillées de Max, se concentrant sur des modèles courants comme le refactoring basé sur des expressions régulières ou la génération de tests unitaires. Une capacité remarquable est ses résumés de raisonnement en ligne – des lignes concises qui informent les utilisateurs sans journaux verbeux. Cela réduit la charge cognitive lors du prototypage rapide.
Lors des tests de performance, Codex Mini obtient un score de 62 % sur SWE-bench lite, un sous-ensemble de tâches d'ingénierie logicielle. Il excelle dans les modifications de fichiers uniques, où la vitesse permet une itération fluide. Pour les équipes qui construisent des services RESTful, ce modèle s'intègre sans effort aux outils de mocking d'Apidog, permettant des simulations de points de terminaison instantanées.
GPT-5.1 Codex Max High : Intelligence équilibrée avec une précision accrue
GPT-5.1 Codex Max High affine la base Max en amplifiant la précision dans les scénarios à enjeux élevés. OpenAI l'a réglé pour des domaines comme l'audit de sécurité et l'optimisation des performances, où les faux positifs coûtent du temps. Il gère 256K contextes et incorpore des invites spécialisées pour la détection de vulnérabilités.
Des fonctionnalités telles que des traces de raisonnement étendues permettent une analyse plus approfondie. Le modèle émet des justifications étape par étape avant les appels d'outils, garantissant la transparence. Par exemple, lors de la sécurisation d'une route Express.js, il scanne les dépendances, suggère des correctifs et vérifie via des lints simulés.
Les métriques montrent un taux de réussite de 72 % sur le module de sécurité de Cursor Bench, dépassant le Max standard de 5 %. Les temps de réponse oscillent entre 1,5 et 2,5 secondes, ce qui le rend adapté aux dépôts de taille moyenne. Les développeurs qui l'utilisent pour des applications riches en API apprécieront sa synergie avec Apidog, qui peut importer des spécifications OpenAPI générées par Codex pour des révisions collaboratives.
GPT-5.1 Codex Max Low : Précision économe en ressources
GPT-5.1 Codex Max Low réduit les exigences de calcul sans sacrifier l'intelligence fondamentale. Idéal pour les ordinateurs portables ou les clusters partagés, il plafonne à 128K tokens et optimise le traitement par lots. Le modèle favorise les modifications conservatrices, minimisant les refontes au profit de corrections ciblées.
Il inclut un ensemble d'outils à faible surcharge, s'appuyant sur les bases du shell comme grep et sed plutôt que sur des scripts Python lourds. Cette approche produit une efficacité de 68 % sur les benchmarks à forte intensité de modification, avec une inférence en moins de 2 secondes. Les cas d'utilisation couvrent la migration de code hérité, où la stabilité l'emporte sur la nouveauté.
Pour les développeurs d'API, cette variante se marie bien avec le niveau gratuit d'Apidog, permettant des tests légers de points de terminaison à faible ressource sans surcharger votre machine.
GPT-5.1 Codex Max Extra High : Précision ultra-fine pour les experts
GPT-5.1 Codex Max Extra High repousse les limites avec une modélisation probabiliste améliorée. Entraîné sur des ensembles de données de cas limites, il atteint une intuition quasi-humaine pour des tâches ambiguës, comme l'inférence d'intentions à partir de spécifications partielles. La fenêtre de contexte s'étend à 384K, supportant la navigation monorepo.
Les fonctionnalités avancées englobent la planification multi-hypothèses : le modèle génère et classe les variantes de modification avant de s'engager. Sur des refactorings complexes, il résout 82 % des conflits de manière autonome.
Les benchmarks soulignent son avantage – 85 % sur les évaluations avancées de Cursor – mais avec des latences de 3 à 4 secondes. Réservez cela pour le codage de niveau recherche, tel que la conception d'algorithmes. Intégrez Apidog pour prototyper des contrats d'API de très haute fidélité dérivés de ses sorties.
GPT-5.1 Codex Max Medium Fast : La vitesse rencontre la compétence
GPT-5.1 Codex Max Medium Fast trouve un équilibre entre profondeur et rapidité. Il traite 192K tokens et utilise des poids quantifiés pour des réponses en 1,2 seconde. Le modèle équilibre les appels d'outils et la génération directe, idéal pour le débogage interactif.
Il obtient 70 % sur les benchmarks à charge de travail mixte, excellant dans les tâches hybrides comme la complétion de code et l'explication. Les développeurs l'exploitent pour les cycles TDD, où les boucles de rétroaction rapides accélèrent les progrès.
GPT-5.1 Codex Max High Fast : Ingénierie de précision rapide
GPT-5.1 Codex Max High Fast accélère la précision de la version High avec des chemins d'inférence parallèles. Avec un contexte de 256K, il délivre des tours en 1 seconde tout en maintenant des scores de benchmark de 74 %. Des fonctionnalités comme le linting prédictif anticipent les erreurs avant l'édition.
Cette variante convient aux équipes à haute vélocité, telles que celles qui travaillent dans le développement d'API fintech. Apidog la complète en accélérant la validation des points de terminaison optimisés pour la vitesse.
GPT-5.1 Codex Max Low Fast : Opérations légères et rapides
GPT-5.1 Codex Max Low Fast combine l'efficacité de la version Low avec des vitesses inférieures à la seconde. Limité à 96K tokens, il privilégie l'efficacité en un seul tour, atteignant 65 % sur les évaluations d'édition rapide.
Parfait pour le script ou les correctifs rapides, il minimise la surcharge dans les configurations à ressources limitées.
GPT-5.1 Codex Max Extra High Fast : Hybride de performance maximale
GPT-5.1 Codex Max Extra High Fast fusionne la profondeur de l'Extra High avec une vitesse fulgurante — 2 secondes maximum pour des contextes de 384K. Il atteint 80 % sur les benchmarks d'élite, en utilisant la quantification adaptative.
Pour les workflows de pointe, ce modèle redéfinit le codage agentique.
GPT-5.1 Codex : La référence polyvalente
GPT-5.1 Codex agit comme le noyau non altéré, offrant une gestion équilibrée de 256K à une moyenne de 2 secondes. Il soutient toutes les variantes, obtenant 70 % sur l'ensemble des tableaux — fiable pour une utilisation générale.
GPT-5.1 Codex High : Utilitaire quotidien amélioré
GPT-5.1 Codex High améliore la précision de base à 73 %, en se concentrant sur une planification robuste pour des contextes de 192K.
GPT-5.1 Codex Fast : Conception axée sur la vitesse
GPT-5.1 Codex Fast réduit à des réponses d'une seconde et 128K tokens, avec une efficacité de 60 % — excellent pour les complétions.
GPT-5.1 Codex High Fast : Agilité optimisée
GPT-5.1 Codex High Fast offre une précision de 72 % en 1,2 seconde, mélangeant les caractéristiques de High avec la vitesse.
GPT-5.1 Codex Low : Précision minimaliste
GPT-5.1 Codex Low conserve les ressources à 96K tokens, scores de 67 % — adapté aux appareils périphériques.
GPT-5.1 Codex Low Fast : Ultra-efficace
GPT-5.1 Codex Low Fast atteint des performances inférieures à la seconde avec 62 % — idéal pour les micro-tâches.
GPT-5.1 Codex Mini High : Excellence compacte
GPT-5.1 Codex Mini High améliore Mini avec une précision de 65 % en 0,8 seconde.
GPT-5.1 Codex Mini Low : Compact économique
GPT-5.1 Codex Mini Low offre 58 % à un coût minimal, pour les besoins de base.
Comparaison technique : Les métriques qui comptent
Pour déterminer le meilleur modèle Cursor Codex, nous analysons les métriques clés : taux de réussite (issu de Cursor Bench), latence, taille du contexte et efficacité des outils. Le taux de réussite évalue l'achèvement autonome des tâches, la latence suit le temps de réponse, le contexte mesure la capacité en tokens, et l'efficacité des outils évalue l'intégration shell.
| Variante du modèle | Taux de réussite (%) | Latence (s) | Contexte (K Tokens) | Efficacité des outils (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
Ces chiffres proviennent des tests de harnais de Cursor, qui simulent des interactions réelles avec l'IDE. Remarquez comment les variantes Max dominent les taux de réussite, tandis que les suffixes Fast excellent en latence.
De plus, considérez l'efficacité énergétique : les modèles Low et Mini consomment 40 % moins d'énergie, selon les rapports d'OpenAI. Pour les projets centrés sur les API, l'efficacité des outils a un impact direct sur la qualité de l'intégration — des scores plus élevés signifient moins d'ajustements manuels lors de l'exportation vers Apidog.
Analyse comparative : Aperçus des performances réelles
Les benchmarks fournissent des preuves concrètes. Cursor Bench, une suite interne, teste plus de 500 tâches dans des langages comme Python, JavaScript et Rust. GPT-5.1 Codex Max mène avec 78 % de résolution, en particulier dans les chaînes agentiques impliquant plus de 10 appels d'outils. Il résout les erreurs de linter 92 % du temps, grâce à l'intégration dédiée de `read_lints`.
Les variantes GPT-5.1 Codex Mini Fast privilégient le débit. Sur un sprint de 100 tâches simulant une semaine de sprint, Mini réalise 85 % d'itérations de plus que Max, bien qu'avec une précision inférieure de 20 % sur les refactorisations nuancées.
SWE-bench Verified, une métrique standardisée, montre une moyenne de 65 % pour la famille — un bond de 25 % par rapport à GPT-4.1. Les modèles Extra High atteignent un pic de 82 %, mais leur latence les disqualifie pour le pair-programming en direct.
En ce qui concerne les cas d'utilisation, les modèles à contexte élevé comme Max Extra High prospèrent dans les monorepos, naviguant sans effort dans plus de 50 fichiers. Pour les développeurs solo, Medium Fast trouve l'équilibre optimal.
Cas d'utilisation : Adapter les modèles aux besoins des développeurs
Sélectionnez votre modèle Cursor Codex en fonction des exigences de votre workflow. Pour le développement d'API full-stack, GPT-5.1 Codex Max High Fast génère rapidement des points de terminaison sécurisés et évolutifs. Il crée des résolveurs GraphQL, puis utilise des outils shell pour les tester par rapport à des mocks — simplifiez cela avec le validateur de schéma d'Apidog pour une confiance de bout en bout.
Dans le codage de systèmes embarqués, GPT-5.1 Codex Low privilégie l'efficacité, générant des extraits C++ qui s'adaptent aux environnements contraints. Les pipelines d'apprentissage automatique bénéficient de la planification probabiliste de Max Extra High, optimisant les flux de tenseurs avec un minimum d'essais et d'erreurs.
Pour les environnements collaboratifs, les variantes Fast permettent des suggestions en temps réel, favorisant la synergie d'équipe. Surveillez toujours l'utilisation des tokens ; le dépassement des limites déclenche des replis, réduisant l'efficacité de 15 %.
De plus, les approches hybrides fonctionnent bien — commencez par Mini pour l'idéation, passez à Max pour l'implémentation. Cette stratégie maximise le retour sur investissement des budgets de calcul.
Conseils d'optimisation : Améliorer Cursor Codex avec Apidog
Pour amplifier les performances de GPT-5.1 Codex, affinez votre harnais. Activez les traces de raisonnement dans les paramètres ; cela améliore la continuité, augmentant le succès de 30 % selon la documentation de Cursor. Préférez les appels d'outils au shell brut — des invites comme "Utiliser read_file avant d'éditer" guident le modèle.
Intégrez Apidog pour les workflows d'API. Codex génère le code de base ; Apidog le teste instantanément. Exportez les spécifications au format YAML, moquez les réponses et automatisez la documentation — réduisant le temps d'intégration de 50 %.
Profilez les latences avec les métriques intégrées de Cursor. Si des goulots d'étranglement apparaissent, passez aux variantes Low. Mettez régulièrement à jour le harnais pour les correctifs, car OpenAI itère fréquemment.
La sécurité compte également : Nettoyez les sorties des outils pour éviter les risques d'injection. Pour la production, auditez les modifications de Codex via des revues de différences.
Conclusion : GPT-5.1 Codex Max s'impose comme le meilleur global
Après avoir analysé les spécifications, les benchmarks et les applications, GPT-5.1 Codex Max revendique la première place. Son taux de réussite inégalé de 78 %, son contexte robuste de 512K et son ensemble d'outils polyvalents le rendent indispensable pour le codage sérieux. Alors que les modèles Fast l'emportent sur la vitesse et Mini sur l'accessibilité, Max offre une excellence holistique, permettant aux développeurs de s'attaquer de front aux projets ambitieux.
Expérimentez Cursor dès aujourd'hui, et ajoutez Apidog pour une gestion complète des API. Votre choix façonne la productivité ; optez pour Max pour pérenniser votre pile technologique.