
Recientemente, la potente IA de Meta, Llama 3.2 , se ha lanzado como un modelo de lenguaje revolucionario, que ofrece capacidades impresionantes tanto para el procesamiento de texto como de imágenes. Para los desarrolladores y entusiastas de la IA que desean aprovechar el poder de este modelo avanzado en sus máquinas locales, herramientas como LM Studio destacan. Esta guía completa te guiará a través del proceso de ejecutar Llama 3.2 localmente utilizando estas potentes plataformas, lo que te permitirá aprovechar la tecnología de IA de vanguardia sin depender de los servicios en la nube.
Qué hay de nuevo con Llama 3.2: Lo último en innovación en IA
Antes de sumergirnos en el proceso de instalación, exploremos brevemente qué hace que Llama 3.2 sea especial:
- Capacidades multimodales: Llama 3.2 puede procesar tanto texto como imágenes, lo que abre nuevas posibilidades para las aplicaciones de IA.
- Eficiencia mejorada: Diseñado para un mejor rendimiento con una latencia reducida, lo que lo hace ideal para la implementación local.
- Tamaños de modelo variados: Disponible en varios tamaños, desde modelos ligeros de 1B y 3B adecuados para dispositivos periféricos hasta versiones potentes de 11B y 90B para tareas más complejas.
- Contexto extendido: Admite una longitud de contexto de 128K, lo que permite una comprensión y generación de contenido más completas.
Ejecutar Llama 3.2 con LM Studio localmente
LM Studio ofrece un enfoque más fácil de usar con una interfaz gráfica. Aquí te mostramos cómo ejecutar Llama 3.2 localmente usando LM Studio:
Paso 1: Descargar e instalar LM Studio
- Visita el sitio web de LM Studio.
- Descarga la versión compatible con tu sistema operativo.
- Sigue las instrucciones de instalación proporcionadas.

Paso 2: Iniciar LM Studio
Una vez instalado, abre LM Studio. Serás recibido con una interfaz intuitiva.
Paso 3: Buscar y descargar Llama 3.2
- Utiliza la función de búsqueda en LM Studio para encontrar Llama 3.2.
- Selecciona la versión apropiada de Llama 3.2 para tus necesidades (por ejemplo, 3B para aplicaciones ligeras o 11B para tareas más complejas).
- Haz clic en el botón de descarga para iniciar el proceso de descarga.
Paso 4: Configurar el modelo
Después de la descarga, puedes configurar varios parámetros:
- Ajusta la longitud del contexto si es necesario (Llama 3.2 admite hasta 128K).
- Establece los valores de temperatura y muestreo top-p para controlar la aleatoriedad de la salida.
- Experimenta con otras configuraciones para ajustar el comportamiento del modelo.
Paso 5: Comienza a interactuar con Llama 3.2
Con el modelo configurado, ahora puedes:
- Utiliza la interfaz de chat para tener conversaciones con Llama 3.2.
- Prueba diferentes indicaciones para explorar las capacidades del modelo.
- Utiliza la función Playground para experimentar con indicaciones y configuraciones más avanzadas.

Paso 6: Configurar un servidor local (opcional)
Para los desarrolladores, LM Studio te permite configurar un servidor local:
- Ve a la pestaña Servidor en LM Studio.
- Configura los ajustes del servidor (puerto, puntos finales de la API, etc.).
- Inicia el servidor para usar Llama 3.2 a través de llamadas API en tus aplicaciones.
Mejores prácticas para ejecutar Llama 3.2 localmente
Para aprovechar al máximo tu configuración local de Llama 3.2, considera estas mejores prácticas:
- Consideraciones de hardware: Asegúrate de que tu máquina cumpla con los requisitos mínimos. Una GPU dedicada puede mejorar significativamente el rendimiento, especialmente para tamaños de modelo más grandes.
- Ingeniería de prompts: Crea prompts claros y específicos para obtener los mejores resultados de Llama 3.2. Experimenta con diferentes frases para optimizar la calidad de la salida.
- Actualizaciones periódicas: Mantén actualizada tanto la herramienta elegida (LM Studio) como el modelo Llama 3.2 para obtener el mejor rendimiento y las últimas funciones.
- Experimenta con parámetros: No dudes en ajustar la configuración para encontrar el equilibrio adecuado para tu caso de uso. Los valores más bajos generalmente producen salidas más enfocadas y deterministas, mientras que los valores más altos introducen más creatividad y variabilidad.
- Uso ético: Utiliza siempre los modelos de IA de manera responsable y sé consciente de los posibles sesgos en las salidas. Considera implementar salvaguardias o filtros adicionales si se implementan en entornos de producción.
- Privacidad de datos: Ejecutar Llama 3.2 localmente mejora la privacidad de los datos. Ten en cuenta los datos que ingresas y cómo utilizas las salidas del modelo, especialmente cuando manejas información confidencial.
- Gestión de recursos: Supervisa los recursos de tu sistema al ejecutar Llama 3.2, especialmente durante períodos prolongados o con tamaños de modelo más grandes. Considera usar administradores de tareas o herramientas de supervisión de recursos para garantizar un rendimiento óptimo.
Solucionar problemas comunes
Al ejecutar Llama 3.2 localmente, es posible que encuentres algunos desafíos. Aquí hay soluciones a problemas comunes:
- Rendimiento lento:
- Asegúrate de tener suficiente RAM y potencia de CPU/GPU.
- Intenta usar un tamaño de modelo más pequeño si está disponible (por ejemplo, 3B en lugar de 11B).
- Cierra las aplicaciones en segundo plano innecesarias para liberar recursos del sistema.
2. Errores de falta de memoria:
- Reduce la longitud del contexto en la configuración del modelo.
- Utiliza una variante de modelo más pequeña si está disponible.
- Actualiza la RAM de tu sistema si es posible.
3. Problemas de instalación:
- Comprueba si tu sistema cumple con los requisitos mínimos para LM Studio.
- Asegúrate de tener la última versión de la herramienta que estás utilizando.
- Intenta ejecutar la instalación con privilegios de administrador.
4. Fallos en la descarga del modelo:
- Comprueba la estabilidad de tu conexión a Internet.
- Desactiva temporalmente los firewalls o las VPN que puedan estar interfiriendo con la descarga.
- Intenta descargar durante las horas de menor actividad para obtener un mejor ancho de banda.
5. Salidas inesperadas:
- Revisa y refina tus prompts para mayor claridad y especificidad.
- Ajusta la temperatura y otros parámetros para controlar la aleatoriedad de la salida.
- Asegúrate de estar utilizando la versión y configuración correctas del modelo.
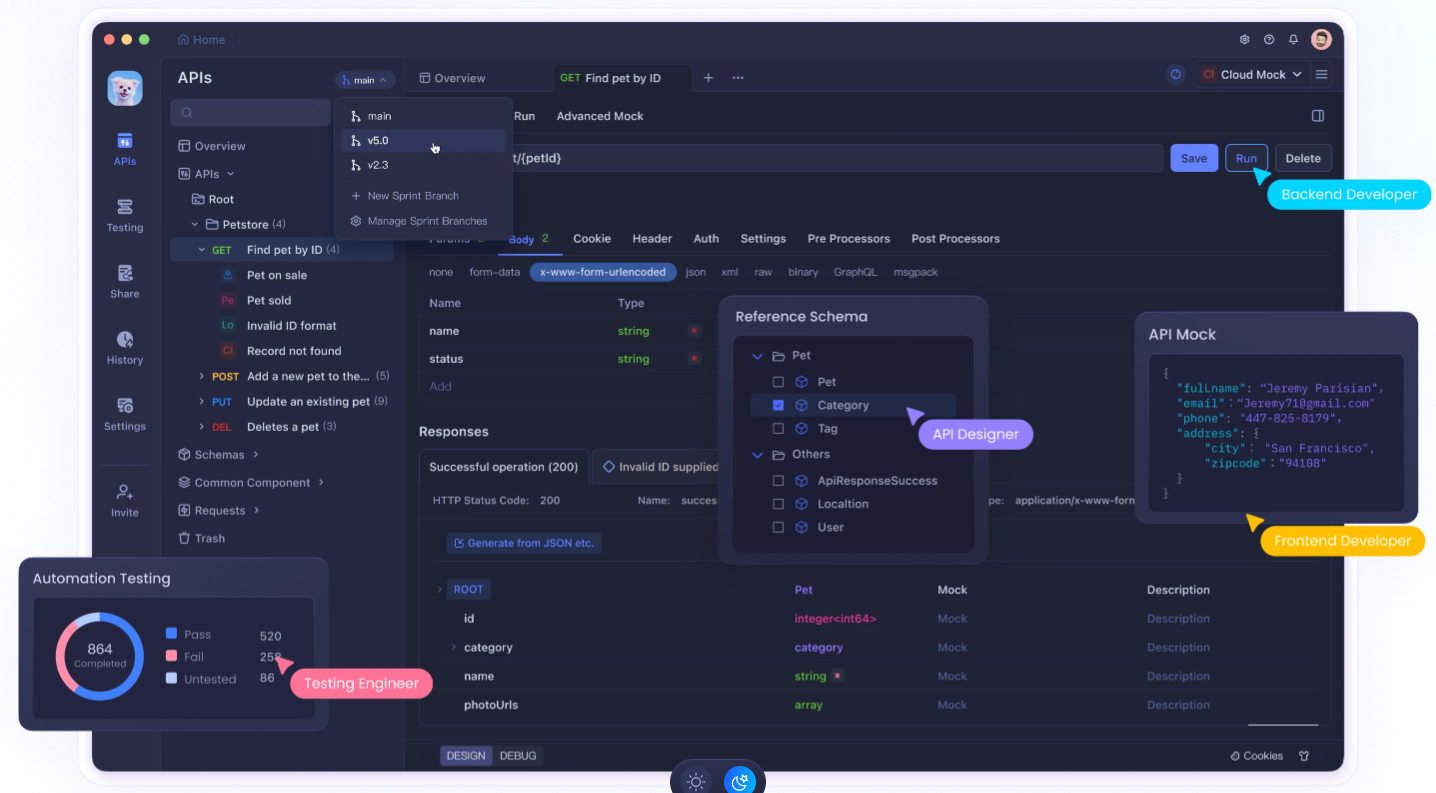
Usar Apidog para mejorar el desarrollo de tu API
Ejecutar Llama 3.2 localmente es potente, integrarlo en tus aplicaciones a menudo requiere un desarrollo y pruebas de API robustos. Aquí es donde Apidog entra en juego. Apidog es una plataforma integral de desarrollo de API que puede mejorar significativamente tu flujo de trabajo cuando trabajas con LLM locales como Llama 3.2.
Características clave de Apidog para la integración local de LLM:
- Diseño y documentación de API: Diseña y documenta fácilmente las API para tus integraciones de Llama 3.2, asegurando una comunicación clara entre tu modelo local y otras partes de tu aplicación.
- Pruebas automatizadas: Crea y ejecuta pruebas automatizadas para tus puntos finales de la API de Llama 3.2, asegurando la fiabilidad y la coherencia en las respuestas de tu modelo.
- Servidores simulados: Utiliza la funcionalidad de servidor simulado de Apidog para simular las respuestas de Llama 3.2 durante el desarrollo, lo que te permite avanzar incluso cuando no tienes acceso inmediato a tu configuración local.
- Gestión del entorno: Gestiona diferentes entornos (por ejemplo, Llama 3.2 local, API de producción) dentro de Apidog, lo que facilita el cambio entre configuraciones durante el desarrollo y las pruebas.
- Herramientas de colaboración: Comparte tus diseños de API de Llama 3.2 y los resultados de las pruebas con los miembros del equipo, fomentando una mejor colaboración en proyectos impulsados por IA.
- Supervisión del rendimiento: Supervisa el rendimiento de tus puntos finales de la API de Llama 3.2, lo que te ayuda a optimizar los tiempos de respuesta y el uso de recursos.
- Pruebas de seguridad: Implementa pruebas de seguridad para tus integraciones de la API de Llama 3.2, asegurando que la implementación de tu modelo local no introduzca vulnerabilidades.
Comenzando con Apidog para el desarrollo de Llama 3.2:
- Regístrate para obtener una cuenta de Apidog.
- Crea un nuevo proyecto para tu integración de la API de Llama 3.2.
- Diseña tus puntos finales de la API que interactuarán con tu instancia local de Llama 3.2.
- Configura entornos para gestionar diferentes configuraciones (por ejemplo, configuraciones de LM Studio).
- Crea pruebas automatizadas para asegurar que tus integraciones de Llama 3.2 estén funcionando correctamente.
- Utiliza la función de servidor simulado para simular las respuestas de Llama 3.2 durante las primeras etapas de desarrollo.
- Colabora con tu equipo compartiendo diseños de API y resultados de pruebas.
Al aprovechar Apidog junto con tu configuración local de Llama 3.2, puedes crear aplicaciones impulsadas por IA más robustas, bien documentadas y probadas a fondo.
Conclusión: Abrazando el poder de la IA local
Ejecutar Llama 3.2 localmente representa un paso significativo hacia la democratización de la tecnología de IA. Ya sea que elijas la interfaz fácil de usar de LM Studio u otra, ahora tienes las herramientas para aprovechar el poder de los modelos de lenguaje avanzados en tu propia máquina.
Recuerda que la implementación local de modelos de lenguaje grandes como Llama 3.2 es solo el comienzo. Para sobresalir verdaderamente en el desarrollo de IA, considera integrar herramientas como Apidog en tu flujo de trabajo. Esta potente plataforma puede ayudarte a diseñar, probar y documentar las API que interactúan con tu instancia local de Llama 3.2, agilizando tu proceso de desarrollo y asegurando la fiabilidad de tus aplicaciones impulsadas por IA.
A medida que te embarcas en tu viaje con Llama 3.2, sigue experimentando, mantente curioso y siempre esfuérzate por usar la IA de manera responsable. El futuro de la IA no está solo en la nube, está aquí mismo en tu máquina local, esperando ser explorado y aprovechado para aplicaciones innovadoras. Con las herramientas y prácticas adecuadas, puedes desbloquear todo el potencial de la IA local y crear soluciones innovadoras que superen los límites de lo que es posible en la tecnología.


