Ever wanted to automate multi-step, intelligent research—just like ChatGPT or GPT-4—using only open-source tools? This guide will show API and backend engineers how to build an iterative, reasoning-driven Deep Research system using jina-ai/node-DeepResearch, breaking down its architecture and practical setup, and highlighting how you can extend or integrate it with platforms like Apidog.
What is Deep Research and Why Does It Matter?
Traditional AI question-answering models often provide quick, surface-level responses. In contrast, Deep Research systems emulate a human researcher:
- Searching, reading, and reasoning in steps
- Looping through multiple actions until a clear, well-supported answer is found—or resource limits are reached
OpenAI’s proprietary models use such iterative pipelines. With open-source solutions like Jina AI’s DeepResearch, you can build similar workflows—crucial for API engineers who need reliable, reference-backed answers for complex and ambiguous queries.
Quick Start: Installation and Setup
Before diving into the codebase, here’s how to set up DeepResearch locally:
-
Set Your API Keys
- Gemini (for language modeling):
export GEMINI_API_KEY=... - Jina Reader:
export JINA_API_KEY=jina_...(get it from jina.ai/reader) - Brave (optional, for search):
export BRAVE_API_KEY=...(defaults to DuckDuckGo if omitted)
- Gemini (for language modeling):
-
Clone and Install
git clone https://github.com/jina-ai/node-DeepResearch.git cd node-DeepResearch npm install -
Run Example Queries
- Simple:
npm run dev "what is the capital of France?" - Multi-step:
npm run dev "what is the latest news from Jina AI?" - Ambiguous:
npm run dev "who is bigger? cohere, jina ai, voyage?"
- Simple:
Alongside the CLI, a web server is included for HTTP-based queries and real-time streaming—ideal for integrating with API platforms like Apidog for collaborative workflows.
System Architecture: Core Components and Workflow
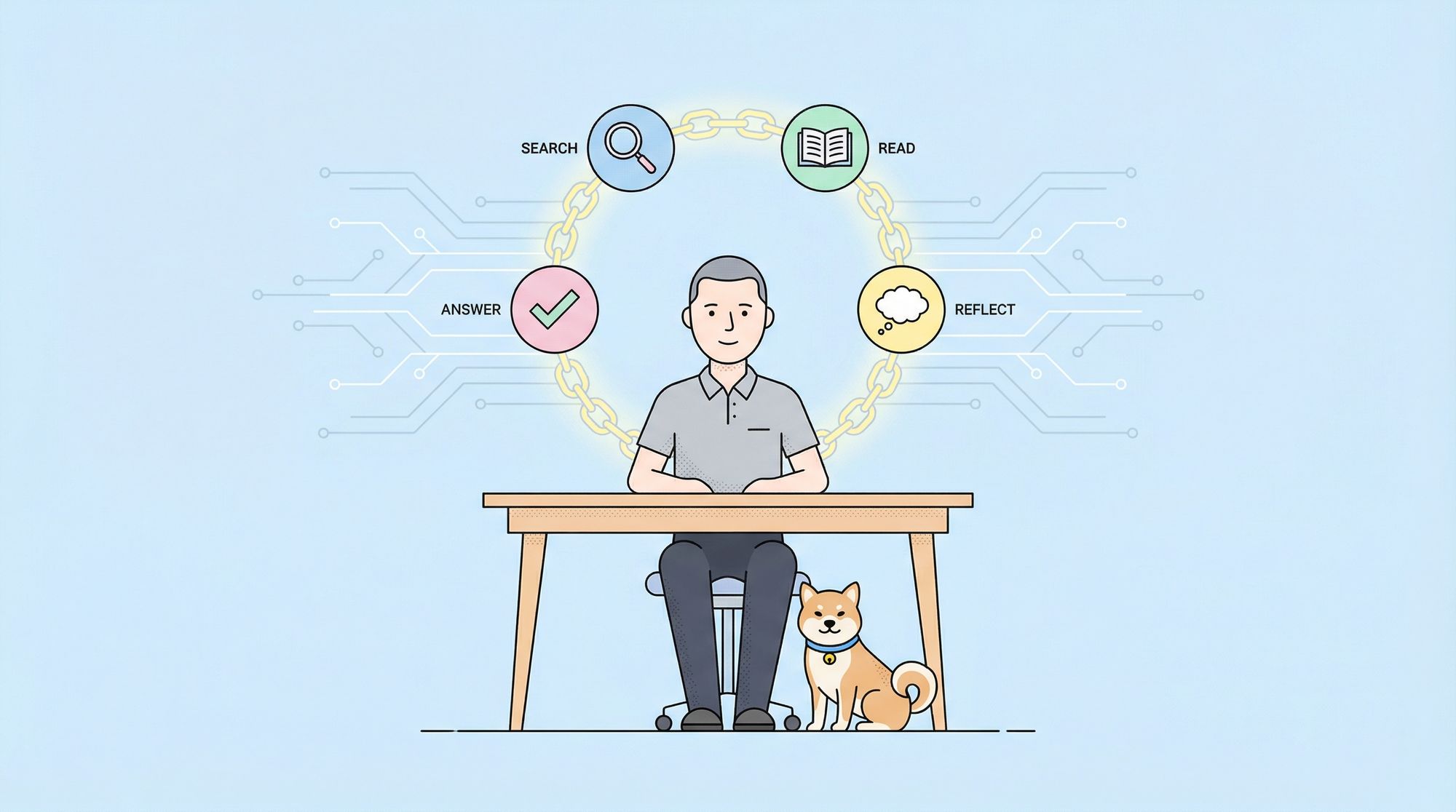
1. The Agent: Orchestrating Search, Read, Reflect, and Answer
At the heart of DeepResearch is the agent.ts file, which implements a loop that mimics expert research:
-
Action Selection: Each cycle, the agent decides whether to:
- Search (formulate new queries)
- Visit (read URLs)
- Reflect (generate clarifying sub-questions)
- Answer (if confident)
-
Prompt Engineering: The agent crafts detailed prompts for the language model, including:
- The original question and current context
- Knowledge gathered so far
- Failed attempts and suggested improvements
- Allowed next actions (with “Beast Mode” for aggressive answering when stuck)
-
JSON Schema Enforcement: Output is validated against strict schemas to ensure machine-readability—a best practice for robust API design.
-
Token and Action Tracking: The agent monitors computational budget (tokens used) and maintains transparency on decision steps, which helps with debugging and resource control.
-
Example Loop (Pseudocode):
while (!answerFound && tokensUsed < tokenBudget) { sleep(); prompt = buildPrompt(context, knowledge, attempts); response = callLanguageModel(prompt); action = parseAction(response); updateTrackers(action); if (action === "answer" && isDefinitive(answer)) break; } -
Context Logging: Every prompt and decision is archived for traceability—a practical feature for regulated industries or API QA teams.
2. Configuration: Easy Environment Management
config.ts centralizes all environment variables and model settings:
- API keys via
dotenv - Search provider selection (Brave or DuckDuckGo)
- Model parameters (e.g., temperature, token limits)
- Step delay to avoid API rate limits
Such modular configuration supports quick adaptation—whether scaling up, switching providers, or integrating with Apidog’s API testing and monitoring workflows.
3. Web Server API: Real-Time and Asynchronous Research
server.ts uses Express to expose endpoints:
- POST
/api/v1/query: Start a new research task - GET
/api/v1/stream/:requestId: Receive live SSE progress updates (ideal for building dashboards or real-time monitoring) - GET
/api/v1/task/:requestId: Retrieve completed results
Progress events include:
{
"type": "progress",
"trackers": {
"tokenUsage": 74950,
"actionState": { "action": "search", ... },
"step": 7
}
}
This makes DeepResearch easily embeddable into API-focused platforms like Apidog, creating transparent, collaborative research workflows.
4. Search & Read Utilities
test-duck.ts: A minimal script for testing API calls—demonstrates how custom integrations or health checks can be coded.readUrl,duckSearch,braveSearch: Modular tools for fetching and parsing external data, ready for extension or replacement based on your team’s needs.
5. Typed Data Structures
types.ts enforces strong typing for all agent actions, responses, and schemas—crucial for teams prioritizing reliability in API-centric environments.
How DeepResearch Iterative Reasoning Works
- Initialization: Start with a “gap”—the unanswered query
- Prompt Generation: Build a context-rich, step-by-step prompt for the language model
- Action Selection: Choose between search, visit, reflect, or answer
- Update Trackers: Log token usage, step results, and archive state
- Evaluation: If the answer is not definitive, loop again
- Beast Mode: When stuck, force a final best-effort answer using all gathered data
This mirrors the way skilled API developers approach difficult research—breaking down ambiguity, tracing sources, and iterating until confident.
Real-Time Feedback for Developers and Teams
DeepResearch’s streaming API provides detailed, real-time insights for every step:
- Current action and rationale (“thoughts”)
- Token usage and breakdown
- URLs visited, search queries used, sub-questions asked
- Failures and attempted improvements
This transparency is invaluable for:
- Debugging complex research workflows
- Tracking resource consumption
- Training or auditing API agents
Tip: With Apidog, you can visualize, monitor, and share these research steps as part of your API documentation or QA process.
Extending DeepResearch: Customization Ideas
- Plug in New Search Providers: Integrate specialized APIs for vertical search (e.g., scientific, legal)
- Enhance Reading Modules: Swap in NLP models to parse new content types or languages
- Advanced Evaluation: Add sentiment analysis, fact-checking, or custom scoring logic
- User Interface: Build rich web or mobile frontends, or embed within Apidog for collaborative research sessions
- Scalability: Containerize and orchestrate with Kubernetes for production-grade deployments
Security, Performance, and API Best Practices
- Secure API Key Storage: Use environment variables or vaults—never hardcode credentials
- Rate Limiting: The built-in sleep can be supplemented with API gateway controls
- Input/Output Validation: Rely on strict schemas and validate all HTTP requests
- Robust Error Handling: Defensive code prevents crashes due to external API failures
- Resource Monitoring: Track tokens and action steps for cost and performance optimization
Platforms like Apidog can help automate many of these best practices—enforcing validation, monitoring API health, and sharing research flows with your team.
Conclusion: Bring OpenAI-Style Deep Research to Your Stack
Jina AI’s DeepResearch shows that you don’t need proprietary models to build powerful, iterative research agents. By combining open-source search, generative AI, and transparent reasoning loops, you can automate complex research—ideal for developers, QA engineers, and API teams who need trustworthy, reference-based answers.
Key takeaways:
- DeepResearch is modular, transparent, and extensible for any research workflow
- Real-time feedback and strict typing make it ideal for collaborative, API-driven environments
- Easy integration with platforms like Apidog enables better documentation, monitoring, and sharing of research processes
Ready to level up your automated research? Clone the repo, follow the setup above, and start experimenting—or connect DeepResearch with Apidog to bring deep, iterative reasoning into your API lifecycle.


