In the realm of API development, ensuring data consistency and integrity is paramount, as APIs often return complex data structures, and managing these effectively is crucial for seamless client-server communication. One common challenge developers face is validating HashMaps within API responses. HashMaps, or associative arrays, are key-value pairs that often represent complex data structures. Validating these structures ensures that the data received or sent by an API meets expected standards, preventing errors and ensuring robust functionality. In this blog, we'll explore what HashMap is, how it works and how you can handle its validation in API responses using Apidog.
What is HashMap?
A HashMap is a data structure that stores key-value pairs. It is implemented using a hash table, which allows for fast retrieval, insertion, and deletion of elements. The HashMap uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
Key Characteristics:
- Key-Value Pair Storage: A HashMap stores data as key-value pairs, where each key is unique, and maps to a corresponding value.
- Hash Function: It uses a hash function to map keys to their corresponding values, which allows for rapid data retrieval.
- Buckets/Slots: Internally, it maintains an array of buckets. Each bucket can contain multiple entries in case of hash collisions (where different keys produce the same hash value).
- Fast Operations: The typical time complexity for operations like insert, delete, and search is O(1), making it highly efficient.
- Non-Synchronized: The default implementation of HashMap is not synchronized, which means it is not thread-safe and must be synchronized externally in a multi-threaded environment.
- Null Values: HashMap in Java allows for one null key and multiple null values.
How does a Hashmap work?
A HashMap is a fundamental data structure in programming that facilitates efficient storage and retrieval of key-value pairs. It works using a combination of a hash function and an array (bucket). Here’s how it works:
Hashing Function
- At the core of a HashMap is a hashing function. This function takes a key (such as a string or number) and converts it into an index within an array (often referred to as a bucket). The index is computed based on the key's value using a hash code algorithm.
Array of Buckets
- The HashMap maintains an array of buckets, where each bucket can store one or more key-value pairs. The index generated by the hashing function determines which bucket the key-value pair will be stored in.
Handling Collisions
- Hashing: Hashing functions may occasionally generate the same index for different keys, causing a collision. HashMaps employ techniques like chaining or open addressing to manage collisions:
- Chaining: Multiple key-value pairs with the same index are stored in a linked list or another data structure within the same bucket.
- Open Addressing: If a collision occurs, the HashMap searches for an alternative bucket using a probing sequence until an empty slot is found.
Insertion and Retrieval
- Insertion: When inserting a new key-value pair, the HashMap computes the hash code of the key to determine its bucket and stores the pair there. If a collision occurs, it resolves it using the chosen collision resolution strategy.
- Retrieval: To retrieve a value associated with a key, the HashMap computes the hash code of the key, determines its bucket, and retrieves the value stored at that location. If chaining is used, it iterates through the linked list or other structure within the bucket to find the correct key-value pair.
Removing Values
When you remove a key-value pair:
- The hash code for the key is generated.
- The index in the bucket array is calculated.
- The key is searched at that index, and if found, it is removed from the data structure (either from the list or tree).
Rehashing
When the HashMap becomes too full (e.g., the number of key-value pairs exceeds the load factor times the bucket array size), it needs to resize to maintain efficient performance. This involves:
- Creating a new, larger bucket array.
- Recalculating the index for each key-value pair and placing it in the new bucket array.
In essence, HashMap provides a flexible and efficient way to store and access data based on unique keys, leveraging hash codes and arrays to optimize operations while managing collisions to maintain performance and integrity.
Handling Hashmap Validation in API Responses using Apidog
Apidog allows you to customize response validations to handle Hashmap– "Additional Properties" not defined in your API documentation. Here's how you can set it up:
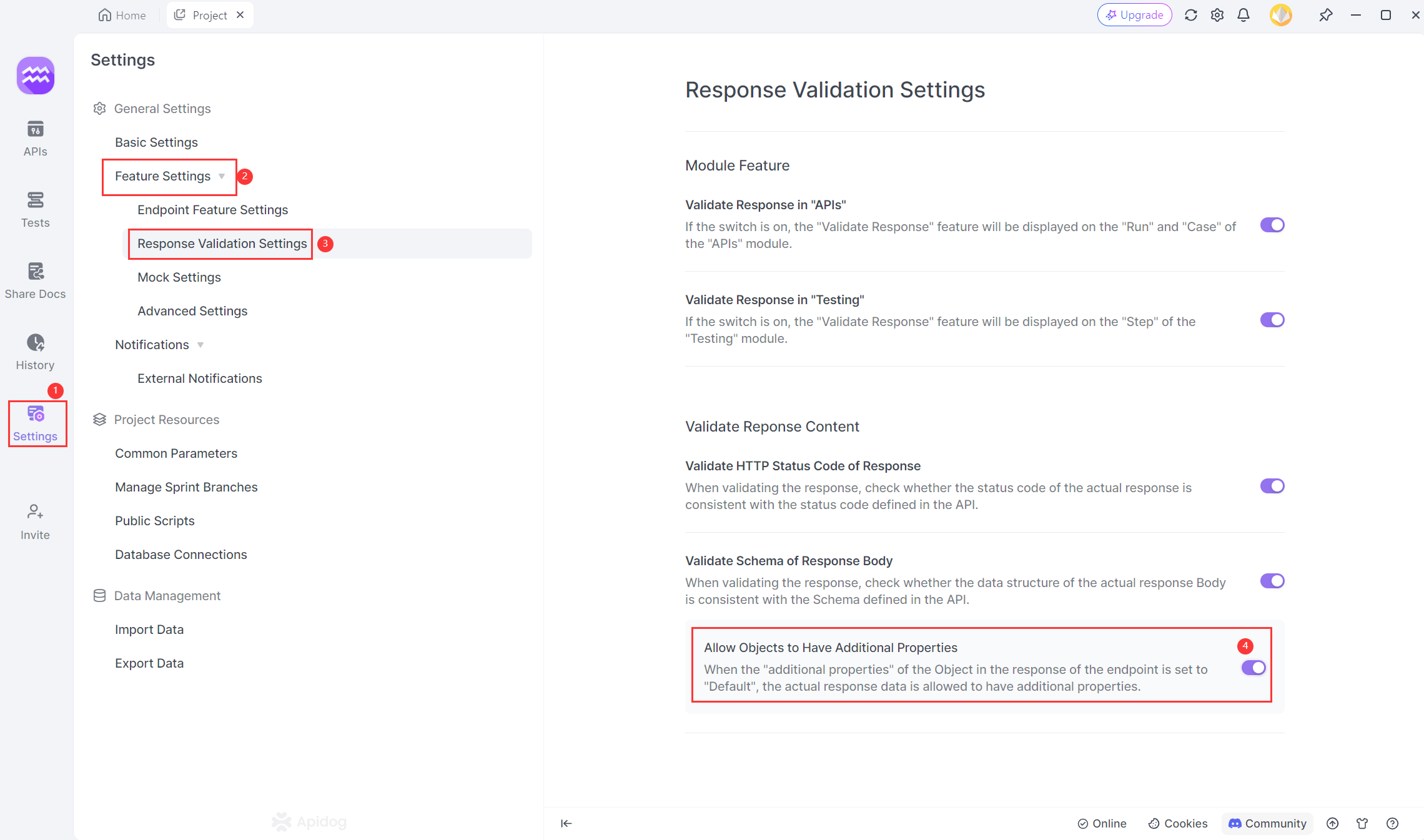
Method 1: Global Settings
You can enable or disable the option "Allow Objects to Have Additional Properties" in Settings -> Feature Settings -> Response Validation Settings. This global setting affects all interfaces within the project.
- Enabled (Default): Allows API response data to contain extra fields without triggering a validation error.
- Disabled: Ensures the returned data strictly matches the API document. Any extra fields will cause a verification error.
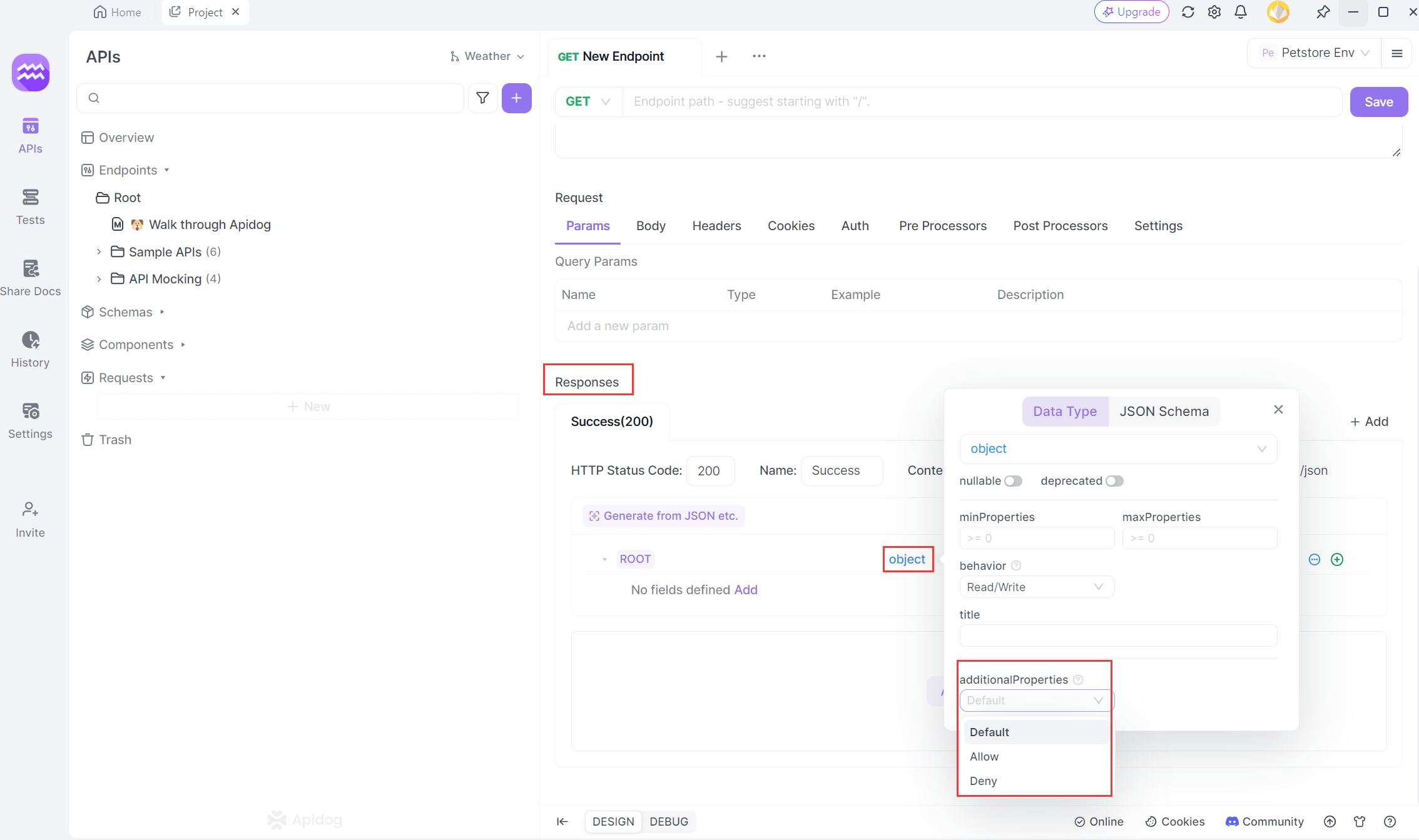
Method 2: Endpoint-level Settings
For more granular control, you can configure HashMap settings for individual endpoints. Navigate to the Response section in the API document and select Advanced Settings for the specific object. Here, you can set preferences for additional properties (HashMap).
There are three choices for configuring additional properties:
- Default(Not Configured): Adheres to the global setting.
- Allow: Permits API response data to include extra fields without causing a validation error.
- Deny: Ensures the returned data strictly conforms to the API documentation, triggering a validation error if any extra fields are present.
If choosing "Allow", you can further specify the type of the values in the map, enhancing flexibility in defining the expected structure of "additionalProperties".
Benefits of Apidog's HashMap Validation
Handling HashMap validation in API responses using Apidog provides numerous benefits that contribute to the efficiency, reliability, and maintainability of the API ecosystem. Here are some key advantages:
1. Data Consistency
Benefit: Ensures that all API responses adhere strictly to predefined structures.
How: By validating against schemas and predefined rules, Apidog helps maintain consistent data formats across all API responses, reducing the risk of data-related errors and discrepancies.
2. Improved Data Integrity
Benefit: Guarantees the accuracy and completeness of the data being transmitted.
How: Apidog's validation features check for missing or additional fields, incorrect data types, and other anomalies, ensuring that the data conforms to the expected format and content.
3. Enhanced Security
Benefit: Reduces security vulnerabilities caused by unexpected or malformed data.
How: By enforcing strict validation rules, Apidog prevents the injection of malicious data and helps mitigate common security threats like SQL injection and cross-site scripting (XSS).
4. Simplified Debugging
Benefit: Makes it easier to identify and correct validation errors.
How: Apidog provides detailed error messages, allowing developers to quickly pinpoint issues related to data consistency and validation, streamlining the debugging process.
5. Granular Control
Benefit: Allows tailored validation settings at both global and endpoint levels.
How: Developers can configure validation rules globally or customize them for individual endpoints, providing flexibility to accommodate specific business requirements and use cases.
6. Ease of Integration
Benefit: Simplifies the incorporation of validation processes into existing workflows.
How: Apidog integrates seamlessly with existing development and testing frameworks, making it easy to add validation steps to your API development lifecycle.
7. Automated Testing
Benefit: Enhances the reliability and repeatability of validation processes.
How: Automated tests can include HashMap validation as part of their routine checks, ensuring that any changes in the API do not violate predefined data integrity rules.
8. Comprehensive Documentation
Benefit: Keeps API documentation up to date and clear.
How: Apidog automatically updates documentation to reflect the latest validation rules and schema definitions, ensuring that API consumers have accurate and current information for integration.
9. Enhanced Client-Side Experience
Benefit: Provides a seamless and predictable experience for API consumers.
How: By ensuring that API responses are consistent and error-free, Apidog helps API clients reliably parse and use the data, improving overall satisfaction and reducing integration efforts.
10. Quick Adaptation to Changes
Benefit: Facilitates rapid adaptation to new requirements or data structures.
How: With Apidog, you can quickly update validation rules and schemas to reflect changes in business logic, ensuring that the API remains compliant with evolving requirements without significant downtime.
HashMap vs. Other Data Structures
1. HashMap vs. Hashtable:
HashMap is not synchronized, while Hashtable is synchronized. This makes HashMap faster but non-thread-safe, whereas Hashtable is thread-safe.
2. HashMap vs. TreeMap:
HashMap offers constant-time performance for basic operations, whereas TreeMap guarantees log(n) time cost for these operations because it is implemented as a Red-Black tree (a balanced binary search tree).
3. HashMap vs. ArrayList
HashMap stores key-value pairs, allowing for fast lookups using keys, while ArrayList is an ordered collection that uses indices for element retrieval.
4. Dictionary vs. HashMap
Both dictionaries in Python and HashMaps in Java serve similar purposes—they store key-value pairs. However:
- Dictionary: Found in Python, generally more flexible and easier to use.
- HashMap: Found in Java, offers tighter control over performance and memory usage.
5. HashSet vs. HashMap
- HashSet: Stores unique elements and does not allow duplicate values. It is backed by a HashMap.
- HashMap: Stores key-value pairs, where keys are unique but values can be duplicated.
Conclusion
Ensuring data consistency and integrity is crucial in API development, particularly when dealing with complex data structures like HashMaps. Proper validation of HashMap responses helps prevent errors, maintain robustness, and improve overall system reliability. By leveraging tools like Apidog, developers can customize and enforce strict validation rules, ensuring that API responses adhere closely to predefined specifications.
Frequently Asked Questions about Hashmap
1. Can HashMap Have Duplicate Keys?
No, a HashMap cannot have duplicate keys. Each key in a HashMap is unique, but the values can be duplicated. If you attempt to add a duplicate key, the existing value for that key will be overwritten.
2. How to Create a HashMap in Java?
Creating a HashMap in Java is straightforward. You use the HashMap class provided by the java.util package.
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
// Creating a HashMap
HashMap<Integer, String> map = new HashMap<>();
}
}3. How to Initialize a HashMap in Java?
Initialization usually involves adding some key-value pairs to the HashMap. Here's how you can do it:
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
// Initializing a HashMap
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "John");
map.put(2, "Jane");
map.put(3, "Doe");
}
}4. How to Print a HashMap in Java?
Printing a HashMap can be done using a loop or the toString method.
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "John");
map.put(2, "Jane");
// Using toString method
System.out.println(map);
// Using a loop
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}5. How to Use a HashMap in Java?
Using a HashMap involves adding, retrieving, and removing key-value pairs.
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "John");
map.put(2, "Jane");
// Retrieve value
String name = map.get(1); // Returns "John"
// Remove a key-value pair
map.remove(2); // Removes the key 2
}
}