
مقدمة في إطار عمل واجهة برمجة التطبيقات Evals من OpenAI
تمثل واجهة برمجة التطبيقات Evals من OpenAI، التي تم تقديمها في 9 أبريل 2025، تقدمًا كبيرًا في التقييم المنهجي لنماذج اللغة الكبيرة (LLMs). بينما كانت قدرات التقييم متاحة من خلال لوحة القيادة الخاصة بـ OpenAI لبعض الوقت، فإن واجهة برمجة التطبيقات Evals تمكّن الآن المطورين من تعريف الاختبارات برمجيًا، وأتمتة تشغيلات التقييم، والتكرار بسرعة على العروض ونماذج التنفيذ داخل سير العمل الخاص بهم. تدعم هذه الواجهة القوية التقييم المنهجي لمخرجات النماذج، مما يسهل اتخاذ قرارات مدعومة بالأدلة عند اختيار النماذج أو تحسين استراتيجيات هندسة العروض.
يوفر هذا البرنامج التعليمي دليلًا فنيًا شاملًا لتنفيذ واستخدام واجهة برمجة التطبيقات Evals من OpenAI. سنستكشف الهندسة المعمارية الأساسية، أنماط التنفيذ، والتقنيات المتقدمة لإنشاء أنظمة تقييم قوية يمكن أن تقيس أداء تطبيقات LLM الخاصة بك بشكل موضوعي.
واجهة برمجة التطبيقات Evals من OpenAI: كيف تعمل؟
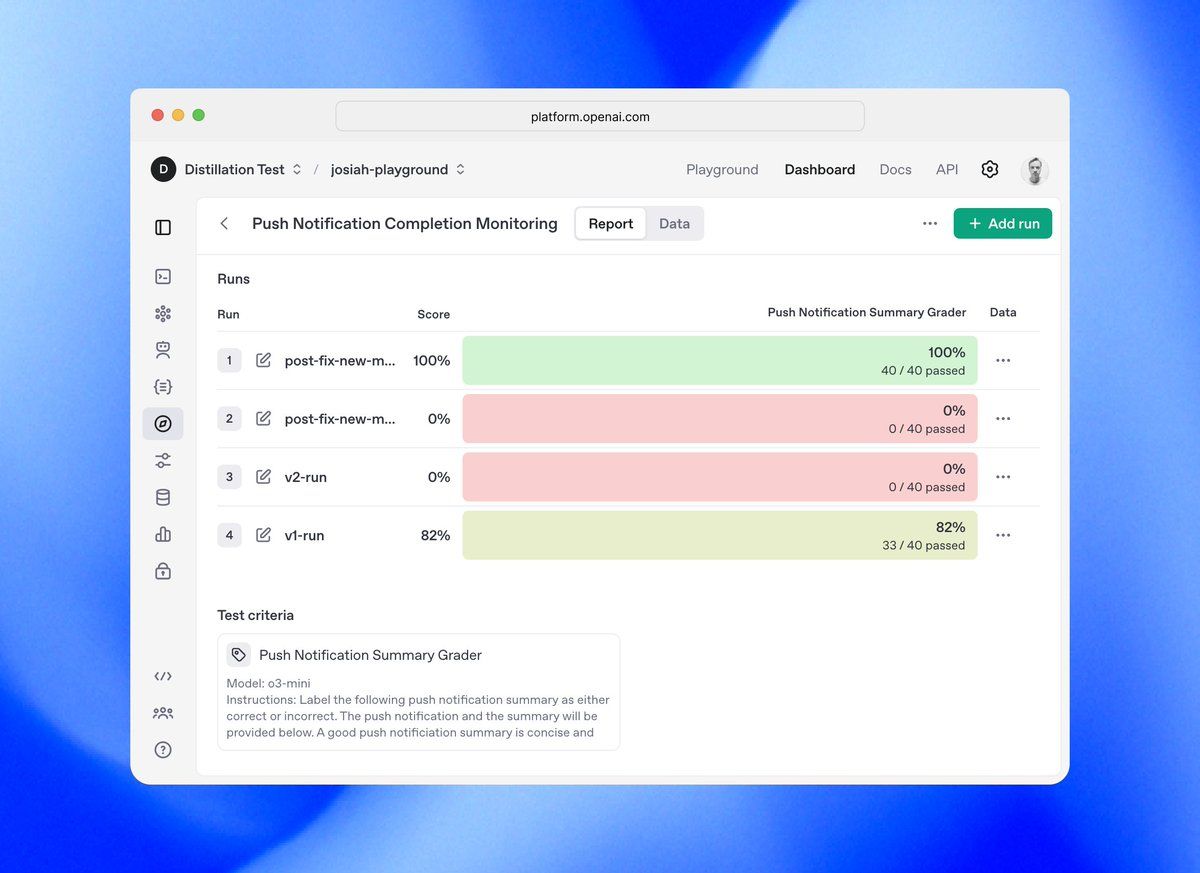
تتبع واجهة برمجة التطبيقات Evals من OpenAI هيكلًا هرميًا مبنيًا حول نوعين أساسيين من التجريد:
- تكوين التقييم - الحاوية لمواصفات التقييم التي تتضمن:
- تعريف مخطط مصدر البيانات
- تكوين معايير الاختبار
- بيانات وصفية للتنظيم والاسترجاع
2. عمليات التقييم - تنفيذات التقييم الفردية التي تتضمن:
- مرجع إلى تكوين تقييم الأب
- عينات بيانات محددة للتقييم
- استجابات النماذج ونتائج التقييم
تمكن هذه الفجوة بين الاهتمامات من إعادة الاستخدام عبر سيناريوهات اختبار متعددة مع الحفاظ على اتساق معايير التقييم.
نموذج كائن واجهة برمجة التطبيقات Evals
تتبع الكائنات الأساسية ضمن واجهة برمجة التطبيقات Evals هذه العلاقة:
- data_source_config (تعريف المخطط)
- testing_criteria (طرق التقييم)
- metadata (الوصف، العلامات، إلخ)
- Run 1 (ضد بيانات محددة)
- Run 2 (تنفيذ بديل)
- ...
- Run N (مقارنة الإصدارات)
إعداد بيئتك لواجهة برمجة التطبيقات Evals من OpenAI
عند تنفيذ واجهة برمجة التطبيقات Evals من OpenAI، يمكن أن تؤثر اختياراتك من أدوات الاختبار والتطوير بشكل كبير على إنتاجيتك وجودة النتائج.

تتميز Apidog بأنها المنصة الرائدة لواجهات برمجة التطبيقات التي تتفوق على الحلول التقليدية مثل Postman في عدة جوانب رئيسية، مما يجعلها الرفيق المثالي للعمل مع واجهة برمجة التطبيقات Evals المعقدة من الناحية الفنية.
قبل تنفيذ التقييمات، ستحتاج إلى تكوين بيئة تطويرك بشكل صحيح:
import openai
import os
import pydantic
import json
from typing import Dict, List, Any, Optional
# Configure API access with appropriate permissions
os.environ["OPENAI_API_KEY"] = os.environ.get("OPENAI_API_KEY", "your-api-key")
# For production environments, consider using a more secure method
# such as environment variables loaded from a .env file
توفر مكتبة العميل Python الخاصة بـ OpenAI الواجهة للتفاعل مع واجهة برمجة التطبيقات Evals. تأكد من أنك تستخدم أحدث إصدار يتضمن دعم واجهة برمجة التطبيقات Evals:
pip install --upgrade openai>=1.20.0 # الإصدار الذي يتضمن دعم واجهة برمجة التطبيقات Evals
إنشاء تقييمك الأول باستخدام واجهة برمجة التطبيقات Evals من OpenAI
دعنا ننفذ سير عمل تقييم كامل باستخدام واجهة برمجة التطبيقات Evals من OpenAI. سننشئ نظام تقييم لمهمة تلخيص النصوص، موضحين العملية الكاملة من تصميم التقييم إلى تحليل النتائج.
تحديد نماذج البيانات لواجهة برمجة التطبيقات Evals من OpenAI
أولاً، نحتاج إلى تحديد هيكل بيانات الاختبار لدينا باستخدام نماذج Pydantic:
class ArticleSummaryData(pydantic.BaseModel):
"""هيكل البيانات لتقييم تلخيص المقالات."""
article: str
reference_summary: Optional[str] = None # مرجع اختياري للمقارنة
class Config:
frozen = True # يضمن عدم التغيير من أجل تقييم متسق
يحدد هذا النموذج المخطط لبيانات التقييم الخاصة بنا، والتي ستستخدمها واجهة برمجة التطبيقات Evals للتحقق من صحة المدخلات وتوفير متغيرات القالب لمعايير الاختبار الخاصة بنا.
تنفيذ الوظيفة المستهدفة لاختبار واجهة برمجة التطبيقات Evals
بعد ذلك، سنقوم بتنفيذ الوظيفة التي تولد المخرجات التي نريد تقييمها:
def generate_article_summary(article_text: str) -> Dict[str, Any]:
"""
توليد ملخص مختصر لمقال باستخدام نماذج OpenAI.
Args:
article_text: محتوى المقال للتلخيص
Returns:
كائن استجابة الاكتمال مع الملخص
"""
summarization_prompt = """
قم بتلخيص المقال التالي بطريقة مختصرة ومعلوماتية.
التقط النقاط الرئيسية مع الحفاظ على الدقة والسياق.
اجعل الملخص عبارة عن 1-2 فقرة.
مقال:
{{article}}
"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": summarization_prompt.replace("{{article}}", article_text)},
],
temperature=0.3, # درجة حرارة أقل من أجل ملخصات أكثر اتساقًا
max_tokens=300
)
return response.model_dump() # تحويل إلى قاموس قابل للتسلسل
تكوين مصدر البيانات لواجهة برمجة التطبيقات Evals من OpenAI
تتطلب واجهة برمجة التطبيقات Evals تكوين مصدر بيانات محدد يوضح مخطط بيانات التقييم الخاصة بك:
data_source_config = {
"type": "custom",
"item_schema": ArticleSummaryData.model_json_schema(),
"include_sample_schema": True, # يتضمن مخطط مخرجات النموذج تلقائيًا
}
print("مخطط مصدر البيانات:")
print(json.dumps(data_source_config, indent=2))
يخبر هذا التكوين واجهة برمجة التطبيقات Evals عن الحقول التي يجب توقعها في بيانات التقييم الخاصة بك وكيفية معالجتها.
تنفيذ معايير الاختبار باستخدام واجهة برمجة التطبيقات Evals من OpenAI
الآن سنحدد كيف ينبغي على واجهة برمجة التطبيقات Evals تقييم مخرجات النموذج. سننشئ تقييمًا شاملاً مع عدة معايير:
# 1. تقييم الدقة باستخدام حكم قائم على النموذج
accuracy_grader = {
"name": "تقييم دقة الملخص",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
أنت مقيم خبير تقيم دقة ملخصات المقالات.
قم بتقييم ما إذا كان الملخص يمثل بدقة النقاط الرئيسية من المقال الأصلي.
صنف الملخص كواحد من:
- "دقيق": يحتوي على جميع المعلومات الرئيسية، ولا توجد أخطاء واقعية
- "دقيق جزئيًا": يحتوي على معظم المعلومات الرئيسية، مع وجود أخطاء أو سهو بسيط
- "غير دقيق": أخطاء كبيرة، وأهمية المعلومات المفقودة، أو تشويه
قدم تفسيرًا تفصيليًا لتقييمك.
"""
},
{
"role": "user",
"content": """
المقال الأصلي:
{{item.article}}
الملخص المراد تقييمه:
{{sample.choices[0].message.content}}
التقييم:
"""
}
],
"passing_labels": ["دقيق", "دقيق جزئيًا"],
"labels": ["دقيق", "دقيق جزئيًا", "غير دقيق"],
}
# 2. تقييم الإيجاز
conciseness_grader = {
"name": "تقييم إيجاز الملخص",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
أنت مقيم خبير تقيم إيجاز ملخصات المقالات.
قم بتقييم ما إذا كان الملخص يعبر عن المعلومات بكفاءة دون تفاصيل غير ضرورية.
صنف الملخص كواحد من:
- "موجز": الطول المثالي، لا توجد معلومات غير ضرورية
- "مقبول": مطوّل قليلاً ولكنه مناسب بشكل عام
- "مبالغ فيه": طويل بشكل مفرط أو يحتوي على تفاصيل غير ضرورية
قدم تفسيرًا تفصيليًا لتقييمك.
"""
},
{
"role": "user",
"content": """
الملخص الذي يجب تقييمه:
{{sample.choices[0].message.content}}
التقييم:
"""
}
],
"passing_labels": ["موجز", "مقبول"],
"labels": ["موجز", "مقبول", "مبالغ فيه"],
}
# 3. إذا كانت ملخصات المراجع متاحة، أضف مقارنة مرجعية
reference_comparison_grader = {
"name": "تقييم مقارنة المرجعية",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
قارن الملخص الذي تم إنتاجه مع ملخص المرجعية.
قم بتقييم مدى جودة التقاط الملخص الناتج لنفس المعلومات الرئيسية الواردة في المرجعية.
صنف المقارنة كواحدة من:
- "ممتاز": معادل أو أفضل من المرجعية
- "جيد": يلتقط معظم المعلومات المهمة من المرجعية
- "غير كاف": يفتقر إلى معلومات مهمة موجودة في المرجعية
قدم تفسيرًا تفصيليًا لتقييمك.
"""
},
{
"role": "user",
"content": """
ملخص المرجعية:
{{item.reference_summary}}
الملخص الناتج:
{{sample.choices[0].message.content}}
التقييم:
"""
}
],
"passing_labels": ["ممتاز", "جيد"],
"labels": ["ممتاز", "جيد", "غير كاف"],
"condition": "item.reference_summary != null" # ينطبق فقط عندما تكون المرجعية موجودة
}
إنشاء تكوين التقييم باستخدام واجهة برمجة التطبيقات Evals من OpenAI
مع تعريف مخطط بياناتنا ومعايير الاختبار، يمكننا الآن إنشاء تكوين التقييم:
eval_create_result = openai.evals.create(
name="تقييم جودة تلخيص المقالات",
metadata={
"description": "تقييم شامل لجودة تلخيص المقالات عبر عدة أبعاد",
"version": "1.0",
"created_by": "منظمتك",
"tags": ["تلخيص", "جودة المحتوى", "دقة"]
},
data_source_config=data_source_config,
testing_criteria=[
accuracy_grader,
conciseness_grader,
reference_comparison_grader
],
)
eval_id = eval_create_result.id
print(f"تم إنشاء التقييم بالرقم: {eval_id}")
print(f"عرض في لوحة التحكم: {eval_create_result.dashboard_url}")
تنفيذ عمليات التقييم باستخدام واجهة برمجة التطبيقات Evals من OpenAI
تحضير بيانات التقييم
الآن سنقوم بتحضير بيانات اختبار لتقييمنا:
test_articles = [
{
"article": """
أعلنت وكالة الفضاء الأوروبية (ESA) اليوم عن نشر ناجح لقمرها الصناعي الجديد لمراقبة الأرض، Sentinel-6.
ستراقب هذه القمر الصناعي مستويات البحر بدقة غير مسبوقة، مما يوفر بيانات حاسمة حول تأثيرات تغير المناخ.
يتميز Sentinel-6 بتقنية قياس الارتفاع بالرادار المتقدمة القادرة على قياس تغيرات مستوى البحر بدقة تصل إلى المليمتر.
يتوقع العلماء أن تحسن هذه البيانات نماذج المناخ واستراتيجيات التخطيط الساحلي بشكل كبير.
تم إطلاق القمر الصناعي من قاعدة فاندنبرغ الجوية في كاليفورنيا، وهو جزء من برنامج كوبرنيكوس، وهو تعاون
بين ESA وNASA وNOAA وشركاء دوليين آخرين.
""",
"reference_summary": """
قامت ESA بنشر قمر Sentinel-6 لمراقبة الأرض بنجاح، والذي تم تصميمه لمراقبة مستويات البحر
بدقة تصل إلى المليمتر باستخدام تقنية قياس الارتفاع بالرادار المتقدمة. ستوفر هذه المهمة، التي هي جزء من برنامج كوبرنيكوس الدولي،
بيانات حاسمة لأبحاث تغير المناخ والتخطيط الساحلي.
"""
},
# ستتم إضافة مقالات اختبار إضافية هنا
]
# معالجة بيانات الاختبار الخاصة بنا للتقييم
run_data = []
for item in test_articles:
# توليد الملخص باستخدام وظيفتنا
article_data = ArticleSummaryData(**item)
result = generate_article_summary(article_data.article)
# إعداد إدخال بيانات التشغيل
run_data.append({
"item": article_data.model_dump(),
"sample": result
})
إنشاء وتنفيذ عملية تقييم
مع تحضير بياناتنا، يمكننا إنشاء عملية تقييم:
eval_run_result = openai.evals.runs.create(
eval_id=eval_id,
name="تشغيل تلخيص الأساس",
metadata={
"model": "gpt-4o",
"temperature": 0.3,
"max_tokens": 300
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": run_data,
}
},
)
print(f"تم إنشاء عملية التقييم: {eval_run_result.id}")
print(f"عرض النتائج التفصيلية: {eval_run_result.report_url}")
استرجاع وتحليل نتائج التقييم من واجهة برمجة التطبيقات Evals
بمجرد الانتهاء من عملية تقييم، يمكنك استرجاع النتائج التفصيلية:
def analyze_run_results(run_id: str) -> Dict[str, Any]:
"""
استرجاع وتحليل النتائج من عملية تقييم.
Args:
run_id: الرقم التعريفي لعملية التقييم
Returns:
قاموس يحتوي على النتائج المحللة
"""
# استرجاع تفاصيل العملية
run_details = openai.evals.runs.retrieve(run_id)
# استخراج النتائج
results = {}
# حساب معدل النجاح العام
if run_details.results and "pass_rate" in run_details.results:
results["overall_pass_rate"] = run_details.results["pass_rate"]
# استخراج المقاييس المحددة للمعايير
if run_details.criteria_results:
results["criteria_performance"] = {}
for criterion, data in run_details.criteria_results.items():
results["criteria_performance"][criterion] = {
"pass_rate": data.get("pass_rate", 0),
"sample_count": data.get("total_count", 0)
}
# استخراج الأخطاء لمزيد من التحليل
if run_details.raw_results:
results["failure_analysis"] = [
{
"item": item.get("item", {}),
"result": item.get("result", {}),
"criteria_results": item.get("criteria_results", {})
}
for item in run_details.raw_results
if not item.get("passed", True)
]
return results
# تحليل عمليتنا
results_analysis = analyze_run_results(eval_run_result.id)
print(json.dumps(results_analysis, indent=2))
تقنيات متقدمة لواجهة برمجة التطبيقات Evals من OpenAI
تنفيذ اختبار A/B باستخدام واجهة برمجة التطبيقات Evals
تتفوق واجهة برمجة التطبيقات Evals في مقارنة تنفيذات مختلفة. إليك كيفية إعداد اختبار A/B بين تكوينين مختلفين للنموذج:
def generate_summary_alternative_model(article_text: str) -> Dict[str, Any]:
"""تنفيذ بديل باستخدام تكوين نموذج مختلف."""
response = openai.chat.completions.create(
model="gpt-4o-mini", # استخدام نموذج مختلف
messages=[
{"role": "system", "content": "تلخيص هذه المقالة بطريقة مختصرة."},
{"role": "user", "content": article_text},
],
temperature=0.7, # درجة حرارة أعلى للمقارنة
max_tokens=250
)
return response.model_dump()
# معالجة بيانات الاختبار الخاصة بنا باستخدام النموذج البديل
alternative_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_alternative_model(article_data.article)
alternative_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# إنشاء عملية تقييم بديلة
alternative_eval_run = openai.evals.runs.create(
eval_id=eval_id,
name="تشغيل النموذج البديل",
metadata={
"model": "gpt-4o-mini",
"temperature": 0.7,
"max_tokens": 250
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": alternative_run_data,
}
},
)
# مقارنة النتائج برمجيًا
def compare_evaluation_runs(run_id_1: str, run_id_2: str) -> Dict[str, Any]:
"""
مقارنة النتائج من عمليتي تقييم.
Args:
run_id_1: الرقم التعريفي لأول عملية تقييم
run_id_2: الرقم التعريفي لثاني عملية تقييم
Returns:
قاموس يحتوي على التحليل المقارن
"""
run_1_results = analyze_run_results(run_id_1)
run_2_results = analyze_run_results(run_id_2)
comparison = {
"overall_comparison": {
"run_1_pass_rate": run_1_results.get("overall_pass_rate", 0),
"run_2_pass_rate": run_2_results.get("overall_pass_rate", 0),
"difference": run_1_results.get("overall_pass_rate", 0) - run_2_results.get("overall_pass_rate", 0)
},
"criteria_comparison": {}
}
# مقارنة كل معيار
all_criteria = set(run_1_results.get("criteria_performance", {}).keys()) | set(run_2_results.get("criteria_performance", {}).keys())
for criterion in all_criteria:
run_1_criterion = run_1_results.get("criteria_performance", {}).get(criterion, {})
run_2_criterion = run_2_results.get("criteria_performance", {}).get(criterion, {})
comparison["criteria_comparison"][criterion] = {
"run_1_pass_rate": run_1_criterion.get("pass_rate", 0),
"run_2_pass_rate": run_2_criterion.get("pass_rate", 0),
"difference": run_1_criterion.get("pass_rate", 0) - run_2_criterion.get("pass_rate", 0)
}
return comparison
# مقارنة عمليتي التقييم لدينا
comparison_results = compare_evaluation_runs(eval_run_result.id, alternative_eval_run.id)
print(json.dumps(comparison_results, indent=2))
كشف الانحدارات باستخدام واجهة برمجة التطبيقات Evals من OpenAI
أحد التطبيقات الأكثر قيمة لواجهة برمجة التطبيقات Evals هو كشف الانحدارات عند تحديث العروض:
def create_regression_detection_pipeline(eval_id: str, baseline_run_id: str) -> None:
"""
إنشاء خط أنابيب لكشف الانحدارات يقارن عرض جديد
مقابل تشغيل أساسي.
Args:
eval_id: الرقم التعريفي لتكوين التقييم
baseline_run_id: الرقم التعريفي للتشغيل الأساسي للمقارنة
"""
def test_prompt_for_regression(new_prompt: str, threshold: float = 0.95) -> Dict[str, Any]:
"""
اختبار ما إذا كان العرض الجديد يتسبب في الانحدار بالمقارنة مع الأساس.
Args:
new_prompt: العرض الجديد للاختبار
threshold: النسبة المقبولة الأدنى للأداء (جديد/أساسي)
Returns:
قاموس يحتوي على تحليل الانحدار
"""
# تعريف الوظيفة باستخدام العرض الجديد
def generate_summary_new_prompt(article_text: str) -> Dict[str, Any]:
response = openai.chat.completions.create(
model="gpt-4o", # نفس النموذج مثل الأساس
messages=[
{"role": "system", "content": new_prompt},
{"role": "user", "content": article_text},
],
temperature=0.3,
max_tokens=300
)
return response.model_dump()
# معالجة بيانات الاختبار مع العرض الجديد
new_prompt_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_new_prompt(article_data.article)
new_prompt_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# إنشاء عملية تقييم للعرض الجديد
new_prompt_run = openai.evals.runs.create(
eval_id=eval_id,
name=f"اختبار الانحدار-{int(time.time())}",
metadata={
"prompt": new_prompt,
"test_type": "regression"
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": new_prompt_run_data,
}
},
)
# انتظار اكتمال التقييم (في الإنتاج، قد ترغب في تنفيذ معالجة غير متزامنة)
# هذه هي تنفيذ مبسط
time.sleep(10) # الانتظار لاكتمال التقييم
# المقارنة مع الأساس
comparison = compare_evaluation_runs(baseline_run_id, new_prompt_run.id)
# تحديد ما إذا كان هناك انحدار
baseline_pass_rate = comparison["overall_comparison"]["run_1_pass_rate"]
new_pass_rate = comparison["overall_comparison"]["run_2_pass_rate"]
regression_detected = (new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0) < threshold
return {
"regression_detected": regression_detected,
"baseline_pass_rate": baseline_pass_rate,
"new_pass_rate": new_pass_rate,
"performance_ratio": new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0,
"threshold": threshold,
"detailed_comparison": comparison,
"report_url": new_prompt_run.report_url
}
return test_prompt_for_regression
# إنشاء خط أنابيب لكشف الانحدارات
regression_detector = create_regression_detection_pipeline(eval_id, eval_run_result.id)
# اختبار عرض إشكالي محتمل
problematic_prompt = """
قم بتلخيص هذه المقالة بشكل مفرط، وتأكد من تضمين كل نقطة صغيرة.
يجب أن يكون الملخص شاملاً ولا يترك أي شيء.
"""
regression_analysis = regression_detector(problematic_prompt)
print(json.dumps(regression_analysis, indent=2))
العمل مع المقاييس المخصصة في واجهة برمجة التطبيقات Evals من OpenAI
لأغراض التقييم المتخصصة، يمكنك تنفيذ مقاييس مخصصة:
# مثال على تقييم الدرجة الرقمية المخصصة
numeric_score_grader = {
"name": "تقييم جودة الملخص",
"type": "score_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
أنت مقيم خبير تقيم جودة تلخيص المقالات.
قيم الجودة العامة للملخص على مقياس من 1.0 إلى 10.0 حيث:
- 1.0-3.9: جودة ضعيفة، مشاكل كبيرة
- 4.0-6.9: جودة مقبولة مع مجال للتحسين
- 7.0-8.9: جودة جيدة، تلبي التوقعات
- 9.0-10.0: جودة ممتازة، تتجاوز التوقعات
قدم درجة رقمية محددة وتبريرًا مفصلًا.
"""
},
{
"role": "user",
"content": """
المقال الأصلي:
{{item.article}}
الملخص المراد تقييمه:
{{sample.choices[0].message.content}}
الدرجة (1.0-10.0):
"""
}
],
"passing_threshold": 7.0, # الحد الأدنى للدرجة للنجاح
"min_score": 1.0,
"max_score": 10.0
}
# إضافة هذا إلى معايير الاختبار الخاصة بك عند إنشاء تقييم
دمج واجهة برمجة التطبيقات Evals من OpenAI في سير عمل التطوير
دمج CI/CD مع واجهة برمجة التطبيقات Evals
يضمن دمج واجهة برمجة التطبيقات Evals في خط أنابيب CI/CD جودة متسقة:
def ci_cd_evaluation_workflow(
prompt_file_path: str,
baseline_eval_id: str,
baseline_run_id: str,
threshold: float = 0.95
) -> bool:
"""
دمج CI/CD لتقييم عبارات النموذج قبل النشر.
Args:
prompt_file_path: مسار ملف العرض الذي يتم تحديثه
baseline_eval_id: الرقم التعريفي لتكوين التقييم الأساسي
baseline_run_id: الرقم التعريفي للتشغيل الأساسي للمقارنة
threshold: النسبة المقبولة الأدنى للأداء
Returns:
Boolean indicating whether the new prompt passed evaluation
"""
# تحميل العرض الجديد من نظام التحكم في الإصدارات
with open(prompt_file_path, 'r') as f:
new_prompt = f.read()
# إنشاء كاشف الانحدار باستخدام الأساس
regression_detector = create_regression_detection_pipeline(baseline_eval_id, baseline_run_id)
# اختبار العرض الجديد
regression_analysis = regression_detector(new_prompt)
# تحديد ما إذا كان العرض آمنًا للنشر
is_approved = not regression_analysis["regression_detected"]
# تسجيل نتائج التقييم
print(f"نتائج التقييم لـ {prompt_file_path}")
print(f"معدل نجاح الأساس: {regression_analysis['baseline_pass_rate']:.2f}")
print(f"معدل نجاح العرض الجديد: {regression_analysis['new_pass_rate']:.2f}")
print(f"نسبة الأداء: {regression_analysis['performance_ratio']:.2f}")
print(f"قرار النشر: {'موافق' if is_approved else 'مرفوض'}")
print(f"تقرير مفصل: {regression_analysis['report_url']}")
return is_approved
المراقبة المجدولة باستخدام واجهة برمجة التطبيقات Evals من OpenAI
يساعد التقييم المنتظم على اكتشاف انحراف النموذج أو التدهور:
def schedule_periodic_evaluation(
eval_id: str,
baseline_run_id: str,
interval_hours: int = 24
) -> None:
"""
جدولة تقييمات دورية لمراقبة تغيرات الأداء.
Args:
eval_id: الرقم التعريفي لتكوين التقييم
baseline_run_id: الرقم التعريفي للتشغيل الأساسي للمقارنة
interval_hours: تكرار التقييمات بالساعات
"""
# في نظام الإنتاج، ستستخدم مجدول مهام مثل Airflow،
# Celery، أو حلول محلية السحاب. هذه هي مثال مبسط.
def perform_periodic_evaluation():
while True:
try:
# تشغيل التكوين الإنتاجي الحالي أمام التقييم
print(f"تشغيل التقييم المجدول في {datetime.now()}")
# تنفيذ منطق التقييم الخاص بك هنا، مشابه للاختبار الانحداري
# النوم حتى التشغيل المجدول التالي
time.sleep(interval_hours * 60 * 60)
except Exception as e:
print(f"خطأ في التقييم المجدول: {e}")
# تنفيذ معالجة الأخطاء والتنبيه
# في تنفيذ حقيقي، ستدير هذه الخيط بشكل صحيح
# أو تستخدم نظام جدولة مخصص
import threading
evaluation_thread = threading.Thread(target=perform_periodic_evaluation)
evaluation_thread.daemon = True
evaluation_thread.start()
أنماط الاستخدام المتقدمة لواجهة برمجة التطبيقات Evals من OpenAI
خطوط أنابيب التقييم متعددة المراحل
للاستخدامات المعقدة، قم بتنفيذ خطوط أنابيب تقييم متعددة المراحل:
def create_multi_stage_evaluation_pipeline(
article_data: List[Dict[str, str]]
) -> Dict[str, Any]:
"""
إنشاء خط أنابيب تقييم متعدد المراحل لتوليد المحتوى.
Args:
article_data: قائمة بالعناصر للتقييم
Returns:
قاموس يحتوي على نتائج التقييم من كل مرحلة
"""
# المرحلة 1: تقييم توليد المحتوى
generation_eval_id = create_content_generation_eval()
generation_run_id = run_content_generation_eval(generation_eval_id, article_data)
# المرحلة 2: تقييم الدقة الواقعية
accuracy_eval_id = create_factual_accuracy_eval()
accuracy_run_id = run_factual_accuracy_eval(accuracy_eval_id, article_data)
# المرحلة 3: تقييم النغمة والأسلوب
tone_eval_id = create_tone_style_eval()
tone_run_id = run_tone_style_eval(tone_eval_id, article_data)
# تجميع النتائج من جميع المراحل
results = {
"generation": analyze_run_results(generation_run_id),
"accuracy": analyze_run_results(accuracy_run_id),
"tone": analyze_run_results(tone_run_id)
}
# حساب الدرجة المركبة
composite_score = (
results["generation"].get("overall_pass_rate", 0) * 0.4 +
results["accuracy"].get("overall_pass_rate", 0) * 0.4 +
results["tone"].get("overall_pass_rate", 0) * 0.2
)
results["composite_score"] = composite_score
return results
الخاتمة: إتقان واجهة برمجة التطبيقات Evals من OpenAI
تمثل واجهة البرمجة Evals من OpenAI تقدمًا كبيرًا في التقييم المنهجي لنماذج LLM، حيث تقدم للمطورين أدوات قوية لتقييم أداء النموذج بشكل موضوعي واتخاذ قرارات مدفوعة بالبيانات.
مع تزايد تكامل LLMs في التطبيقات الحرجة، تزداد أهمية التقييم المنهجي بشكل متناسب. توفر واجهة برمجة التطبيقات Evals من OpenAI البنية التحتية اللازمة لتنفيذ هذه الممارسات التقييمية على نطاق واسع، مما يضمن أن تظل أنظمة AI الخاصة بك قوية وموثوقة ومتوافقة مع توقعاتك بمرور الوقت.
لكن لماذا يتوقف الأمر هنا؟ من خلال دمج Apidog في سير عمل واجهة برمجة التطبيقات Evals من OpenAI، ستحصل على مزايا كبيرة:
- اختبار مبسط: تقلل قوالب الطلبات الخاصة بـ Apidog وقدرات الاختبار الآلي من الوقت اللازم لتطوير خطوط أنابيب التقييم
- تحسين الوثائق: يضمن إنشاء الوثائق التلقائية لواجهة برمجة التطبيقات أن تتم توثيق معايير التقييم وتنفيذاتها جيدًا
- تعاون الفريق: تسهل المساحات المشتركة الحفاظ على معايير تقييم متسقة عبر فرق التطوير
- دمج CI/CD: تمكّن قدرات سطر الأوامر من التكامل مع خطوط CI/CD الحالية للاختبار التلقائي
- تحليل بصري: تساعد أدوات التصوير المدمجة في تفسير نتائج التقييم المعقدة بسرعة
