
يبحث المطورون عن طرق فعالة لدمج نماذج اللغة المتقدمة في تطبيقاتهم. يبرز INTELLECT-3 كخيار مقنع بفضل أساسه مفتوح المصدر وأدائه القوي في مهام التفكير. يتميز هذا النموذج، الذي طورته Prime Intellect، ببنية Mixture-of-Experts (MoE) التي تبلغ 106 مليار معلمة، مما يتيح كفاءة عالية في التعامل مع الحسابات المعقدة.
فهم INTELLECT-3: القوة الرائدة مفتوحة المصدر
تطلق Prime Intellect نموذج INTELLECT-3 كنموذج مفتوح المصدر بالكامل، مما يمكّن الباحثين والمطورين من تخصيص وتوسيع قدراته دون حواجز احتكارية. تعزز هذه الشفافية الابتكار في مجالات مثل التعلم المعزز (RL) وأنظمة الذكاء الاصطناعي العاملة. يمكنك الوصول إلى الحزمة الكاملة، بما في ذلك أوزان النموذج، وأطر التدريب، ومجموعات البيانات، وبيئات التعلم المعزز، وأدوات التقييم، مباشرة من مستودعات Prime Intellect.

في جوهره، يستخدم INTELLECT-3 بنية MoE بـ 106 مليار معلمة، مبنية على النموذج الأساسي GLM-4.5-Air. تقوم تصميمات MoE بتوجيه المدخلات إلى شبكات فرعية "خبيرة" متخصصة، مما يحسن استخدام الحوسبة ويسرع الاستدلال. على سبيل المثال، أثناء المعالجة، يقوم النموذج بتنشيط مجموعة فرعية فقط من المعلمات ذات الصلة بالاستعلام، مما يقلل من زمن الوصول مع الحفاظ على الدقة. يثبت هذا الإعداد فعاليته بشكل خاص للمهام التي تتطلب خبرة انتقائية، مثل الاشتقاقات الرياضية أو توليد التعليمات البرمجية.
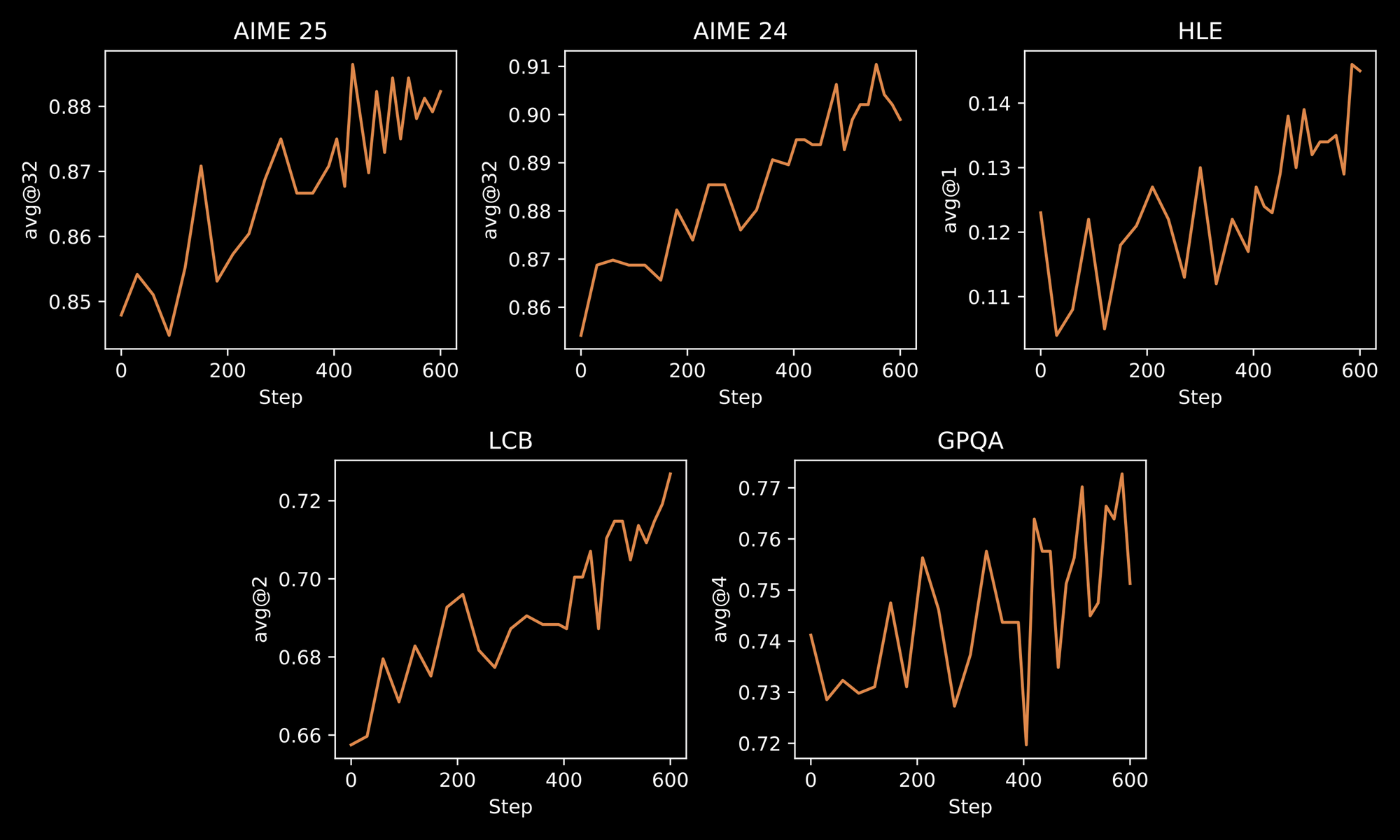
يؤكد مسار التدريب على قوة INTELLECT-3. يطبق المهندسون منهجية من مرحلتين: الضبط الدقيق الأولي الخاضع للإشراف (SFT) على مجموعات بيانات منسقة، متبوعًا بالتعلم المعزز (RL) على نطاق واسع باستخدام إطار عمل prime-rl المخصص. يعمل prime-rl كنظام تعلم معزز غير متزامن خارج السياسة، والذي يتعامل مع المحاكاة المتوازية الهائلة بكفاءة. تستفيد من هذا من خلال تحسين سلوكيات النموذج في البيئات الديناميكية، مثل حل المشكلات التكراري أو التخطيط متعدد الخطوات.
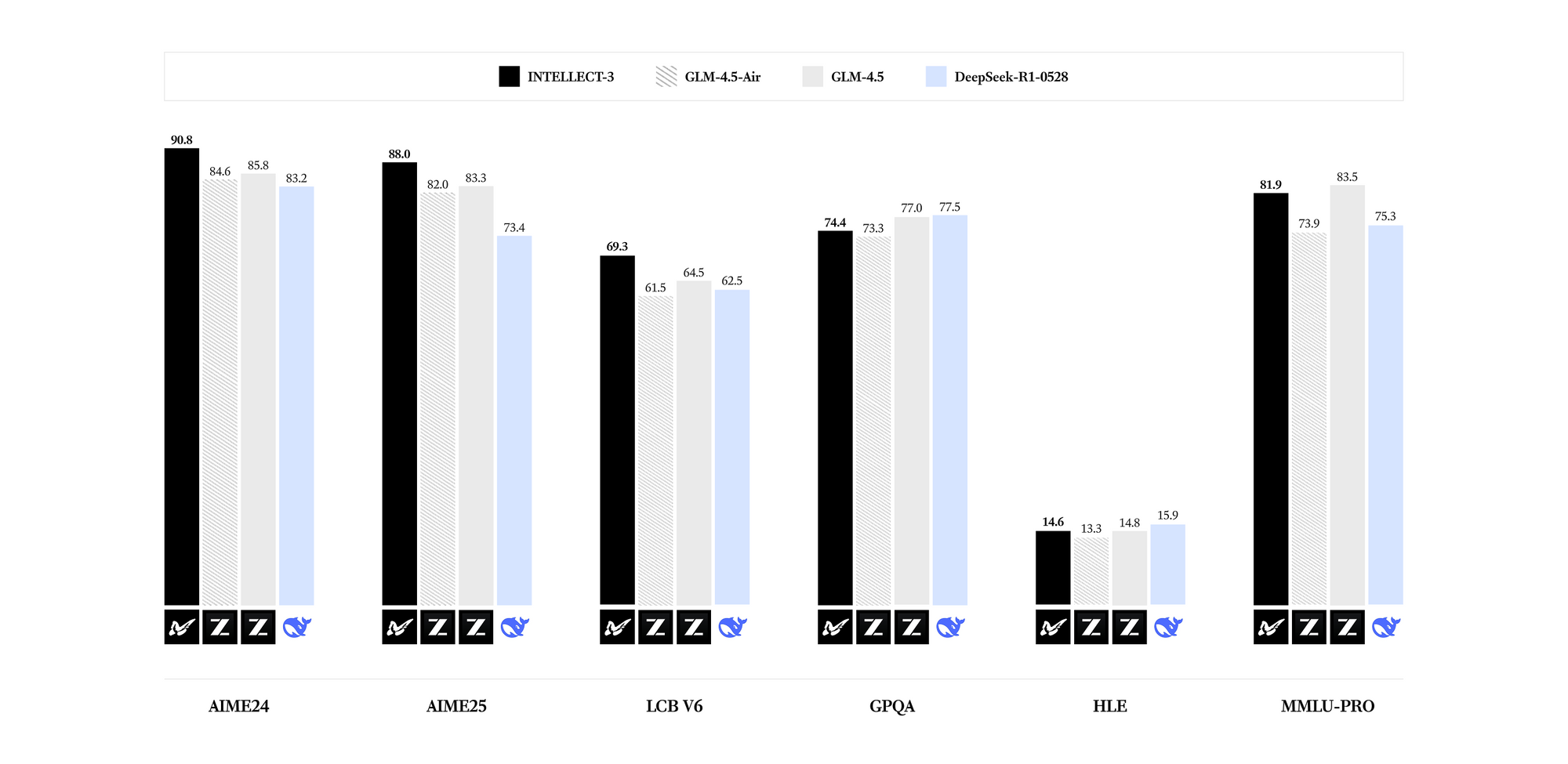
يتفوق INTELLECT-3 في المجالات المتخصصة. تكشف المعايير عن نتائج رائدة لعدد معاملاته عبر الرياضيات (على سبيل المثال، تتجاوز درجات GSM8K 95%)، والترميز (تتجاوز معدلات اجتياز HumanEval 85%)، والعلوم (دقة GPQA تزيد عن 60%)، والاستدلال (درجات MMLU تقترب من 80%). مقارنة بالنماذج الأكثر كثافة مثل Llama 3.1 70B، يحقق INTELLECT-3 كفاءة فائقة - استدلال أسرع مرتين على أجهزة مكافئة - بسبب أنماط التنشيط المتفرقة. وبالتالي، يمكنك نشره في البيئات ذات الموارد المحدودة دون التضحية بجودة المخرجات.
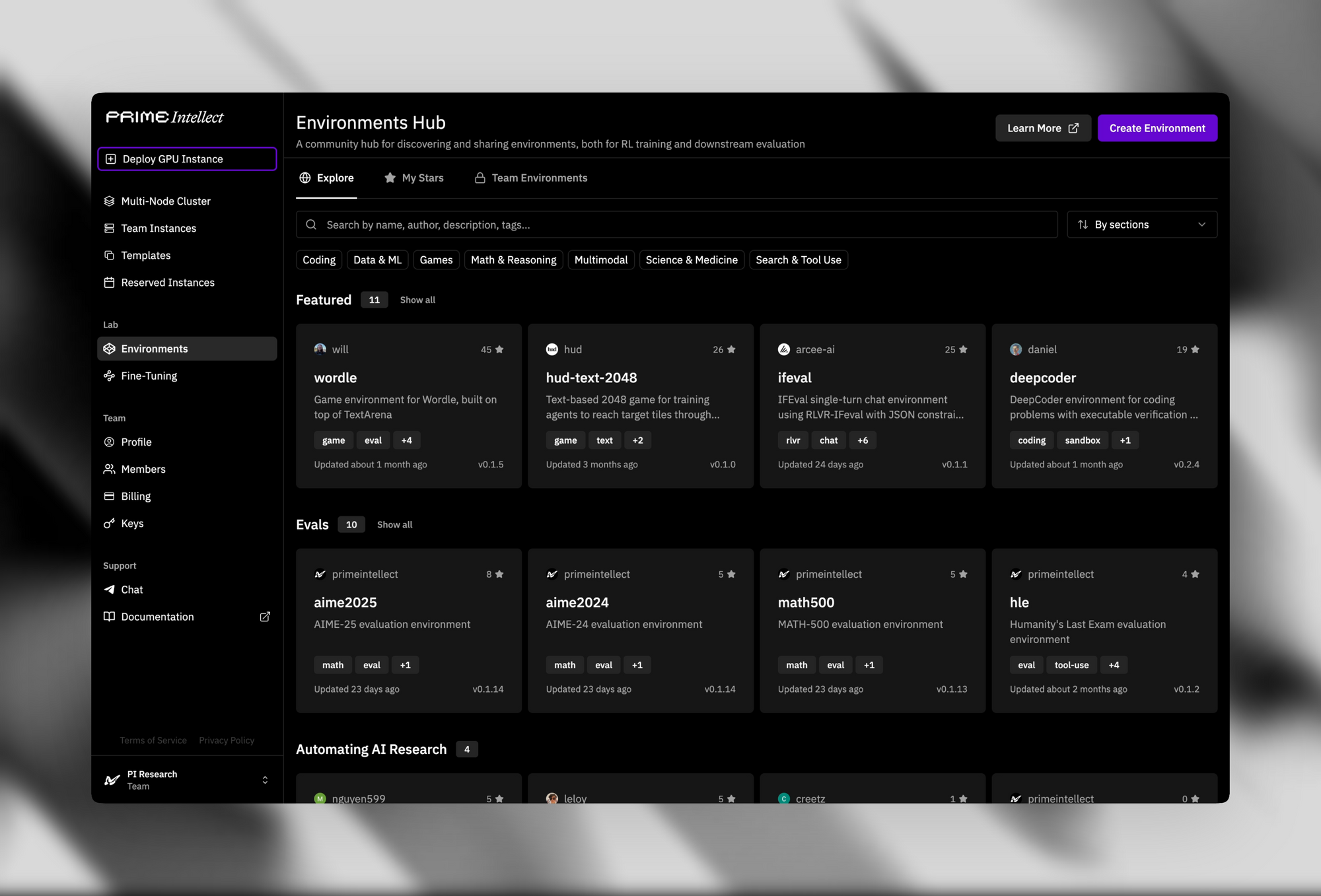
تعزز البنية التحتية الداعمة جاذبيته كمصدر مفتوح. يوفر مركز Verifiers & Environments Hub أكثر من 500 بيئة تعلم معزز (RL)، من الألغاز البسيطة إلى أدوات إثبات النظريات المتقدمة.
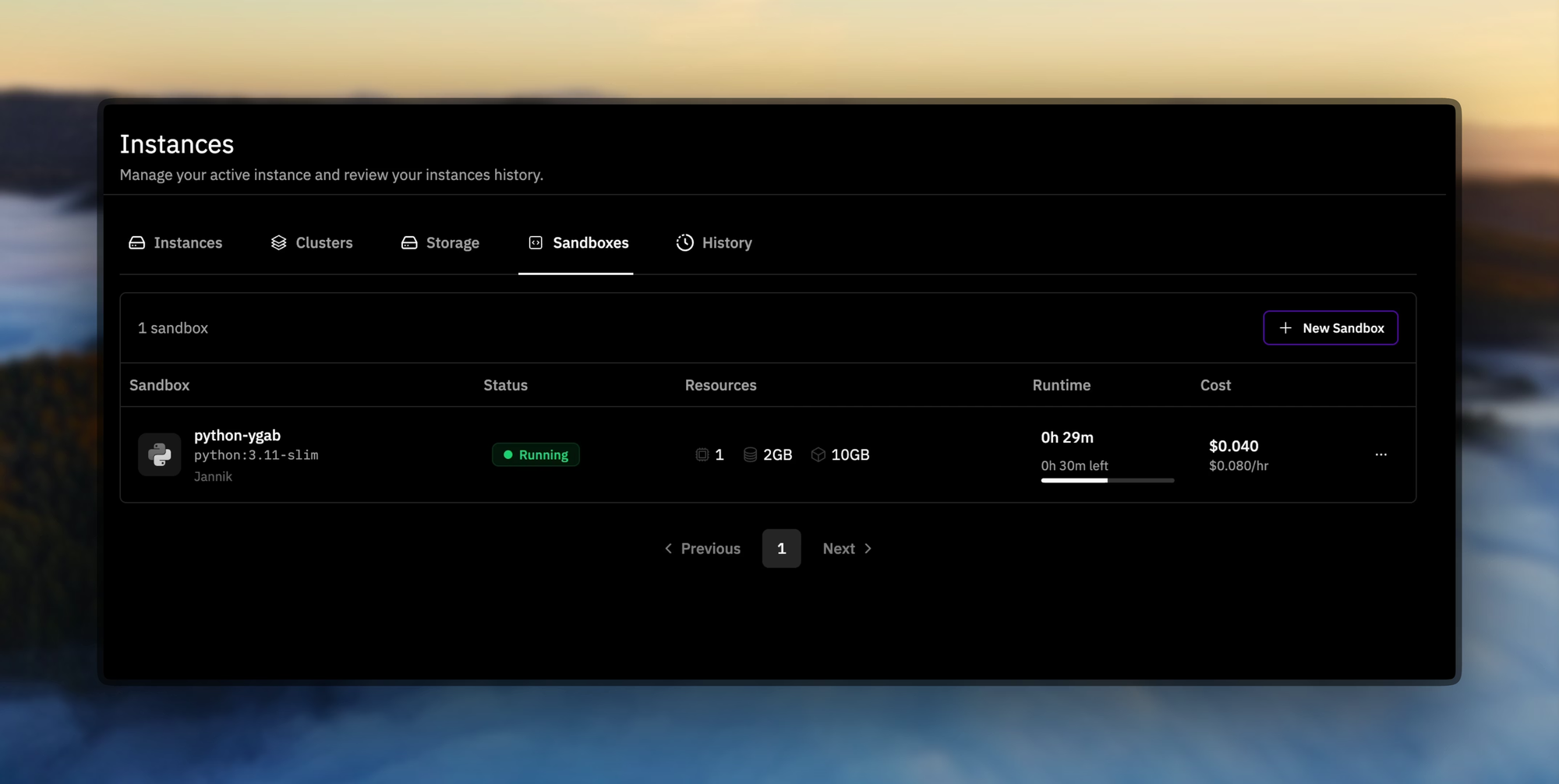
توفر صناديق رمل Prime (Prime Sandboxes) تنفيذًا آمنًا وعالي الإنتاجية للتعليمات البرمجية، مما يعزل إجراءات الوكيل أثناء التدريب أو الاستدلال. يستفيد المطورون من هذه الأدوات لضبط INTELLECT-3 للتطبيقات المخصصة، مثل الوكلاء المستقلين في خطوط أنابيب تطوير البرمجيات.
عمليًا، يمكنك تنزيل أوزان النموذج عبر Hugging Face أو GitHub الخاص بـ Prime Intellect. يتطلب التثبيت تبعيات قياسية مثل PyTorch ومكتبة Transformers. يبدو السكريبت الأساسي لتحميل النموذج كالتالي:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
يقوم هذا الرمز بتهيئة النموذج على الأجهزة التي تدعم وحدات معالجة الرسومات (GPU). ومع ذلك، للاستخدام على نطاق الإنتاج، تنتقل إلى واجهات برمجة التطبيقات المستضافة، حيث يتطلب الاستضافة الذاتية قدرة حوسبة كبيرة (على سبيل المثال، وحدات A100 GPU متعددة). وبالتالي، يضع الوصول مفتوح المصدر الأساس، لكن دمج واجهة برمجة التطبيقات يوسع نطاق عمليات النشر الخاصة بك بفعالية.
انتقالًا من التجارب المحلية، تستكشف الآن كيفية الوصول إلى INTELLECT-3 من خلال الخدمات المُدارة. يضمن هذا التحول الموثوقية ويتعامل مع تعقيدات الاستدلال الموزع.
الوصول إلى واجهة برمجة تطبيقات INTELLECT-3: الإعداد والمصادقة
الخيار 1 – نقطة نهاية Prime Intellect الأصلية (موصى بها لتحقيق أقصى أداء وأقل زمن انتقال)
تبدأ الوصول إلى واجهة برمجة التطبيقات بالحصول على بيانات الاعتماد من منصة Prime Intellect. قم بزيارة لوحة تحكم Prime Intellect على app.primeintellect.ai وأنشئ حسابًا إذا لزم الأمر.
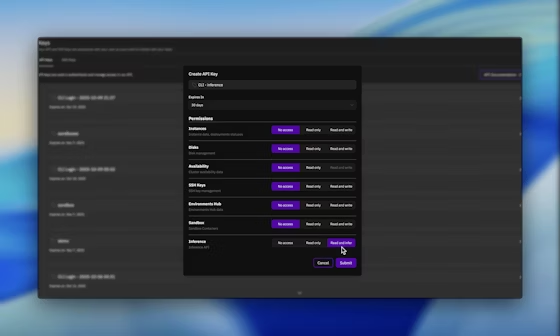
بمجرد تسجيل الدخول، انتقل إلى قسم مفاتيح API وقم بإنشاء مفتاح جديد مع تمكين أذونات الاستدلال (Inference). يصادق هذا المفتاح على جميع الطلبات اللاحقة، مما يضمن وصولاً آمنًا إلى INTELLECT-3.
بعد ذلك، قم بتهيئة بيئتك. اضبط مفتاح API كمتغير بيئة للتكامل السلس:
export PRIME_API_KEY="your-api-key-here"
لسير العمل القائم على الفريق، قم بتضمين ترويسة X-Prime-Team-ID في الطلبات. يوجه هذا المعرف الاستخدام إلى مجموعة الفوترة الصحيحة، مما يمنع رسوم الحسابات المتعددة. يمكنك استرداد معرف الفريق من لوحة التحكم ضمن إعدادات الحساب.
تعتمد واجهة برمجة التطبيقات واجهة متوافقة مع OpenAI، مما يبسط الاعتماد إذا كنت تستخدم بالفعل مكتبات مثل openai-python. حدد عنوان URL الأساسي كـ https://api.pinference.ai/api/v1. تقوم نقطة النهاية هذه بتوكيل الطلبات إلى مزودي الاستدلال المحسنين، بما في ذلك Parasail و Nebius، الذين يستضيفون مثيلات INTELLECT-3. ونتيجة لذلك، تحقق استجابات منخفضة زمن الانتقال دون إدارة المجموعات الأساسية.
للتحقق من الوصول، استعلم عن نقطة نهاية النماذج. يسرد هذا النماذج المتاحة، مؤكدًا وجود INTELLECT-3 (عادةً تحت اسم مثل prime-intellect/intellect-3). استخدم أداة CLI لإجراء فحوصات سريعة:
prime inference models
بدلاً من ذلك، أرسل طلب GET عبر curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
تعيد الاستجابة مصفوفة JSON من كائنات النموذج، كل منها يوضح تفاصيل المعلمات مثل id، max_tokens، و context_window. يدعم INTELLECT-3 سياق 128 ألف رمز مميز، والذي يستوعب سلاسل التفكير طويلة الأمد.
تمتد المصادقة لتشمل تحديد المعدل والحصص. تفرض Prime Intellect حدودًا للدقيقة واليوم بناءً على خطتك، والتي تكون مرئية في لوحة التحكم. يمكنك مراقبة الاستخدام عبر علامة تبويب الفوترة، والتي تسجل الرموز المعالجة ومكالمات واجهة برمجة التطبيقات التي تم إجراؤها. إذا كانت الحدود تقيد سير عملك، فقم بالترقية بسلاسة عبر المنصة.
علاوة على ذلك، قم بالاندماج مع Apidog للاختبار المعزز. استورد مخطط OpenAI إلى Apidog، ثم قم بمحاكاة الطلبات إلى نقاط نهاية INTELLECT-3. تحدد هذه الممارسة المشكلات مبكرًا، مثل حمولات JSON المشوهة. يكفي المستوى المجاني من Apidog للإعدادات الأولية، لربط التطوير المحلي بواجهات برمجة التطبيقات الإنتاجية.
مع وجود المصادقة، يمكنك المضي قدمًا في صياغة الطلبات. يوضح القسم التالي التنسيقات الدقيقة للحصول على استجابات مثالية من INTELLECT-3.
الخيار 2 – OpenRouter (وصول فوري ورصيد موحد)
بالإضافة إلى الاستضافة الذاتية أو استخدام منصة الاستدلال الأصلية لـ Prime Intellect، يتوفر INTELLECT-3 رسميًا أيضًا على OpenRouter. يمنحك هذا بوابة بديلة بفوترة موحدة، وتوجيه تلقائي للعودة الاحتياطية، ووصول فوري — لا يلزم حساب Prime Intellect منفصل إذا كنت تستخدم OpenRouter بالفعل.
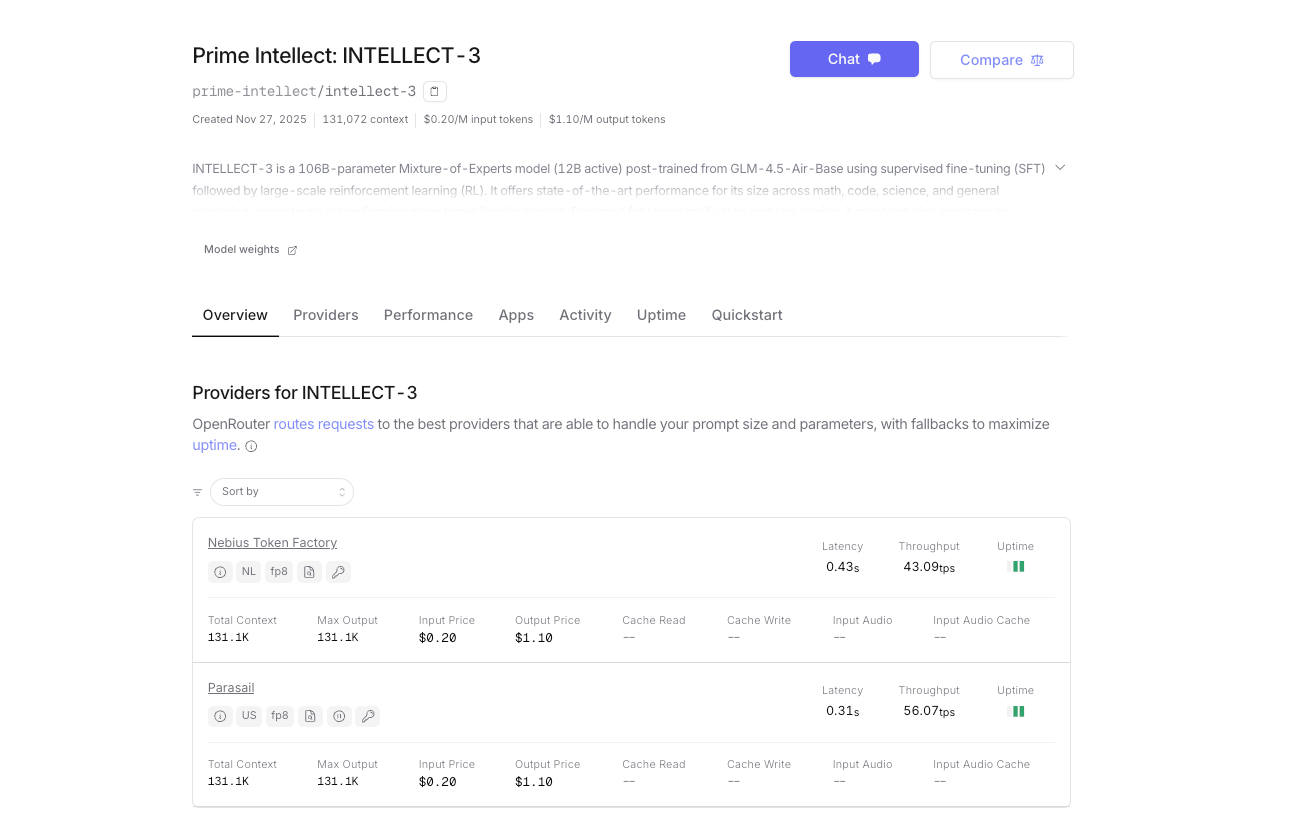
- عنوان URL الأساسي: https://openrouter.ai/api/v1
- اسم النموذج: prime-intellect/intellect-3
- المصادقة: مفتاح OpenRouter API الخاص بك (OPENROUTER_API_KEY)
- توجيه المزود التلقائي (يتم تقديمه حاليًا بواسطة مجموعات Prime Intellect)
- الدفع حسب الاستخدام باستخدام أرصدة OpenRouter؛ تكلفة أعلى قليلاً لكل رمز مميز بسبب رسوم المنصة
تدعم كلتا نقطتي النهاية مخططات طلب/استجابة متطابقة، والبث المباشر، واستدعاء الأدوات، ووضع JSON.
تقديم الطلبات إلى واجهة برمجة تطبيقات INTELLECT-3: التنسيقات والأمثلة
تبدأ التفاعلات عبر نقطة نهاية /chat/completions، والتي تتعامل مع المحادثات والمطالبات الموجهة نحو المهام. قم بإنشاء الطلبات ككائنات JSON مع حقول model، messages، temperature، و max_tokens. تحاكي مصفوفة messages سجلات الدردشة، باستخدام أدوار مثل "system" و "user" و "assistant".
لنفترض مثالاً أساسيًا لتوليد التعليمات البرمجية. تقوم بالإرسال:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
ينتج هذا الرمز تطبيق فيبوناتشي متكرر مع التخزين المؤقت (memoization)، مستفيدًا من براعة INTELLECT-3 في الترميز. يتحكم المعامل temperature في الإبداع — القيم المنخفضة (مثل 0.2) تفضل المخرجات الحتمية للاستعلامات الواقعية، بينما تشجع القيم الأعلى (حتى 1.0) مسارات التفكير المتنوعة.
للتفكير الرياضي، تقوم ببناء المطالبات لتسلسل الأفكار. يبرز تدريب INTELLECT-3 للتعلم المعزز هنا، حيث يحاكي التحقق خطوة بخطوة. مثال:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
يستجيب النموذج بإثبات دقيق، مستشهدًا بالمسلمات والنظريات. تقوم بتحليل المخرج عبر response.choices[0].message.content، الذي يصل كسلسلة نصية. للبيانات المنظمة، قم بتمكين وضع JSON بإضافة "response_format": {"type": "json_object"} إلى الطلب، مما يضمن استجابات قابلة للتحليل.
الاستخدام المتقدم يتضمن استدعاء الأدوات، حيث يدمج INTELLECT-3 وظائف خارجية. حدد الأدوات في الطلب:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
إذا استدعى النموذج الأداة، فإنه يعيد الوسائط في response.choices[0].message.tool_calls. تقوم بتنفيذ الوظيفة خارجيًا وتغذية النتائج مرة أخرى في رسالة متابعة. يبني هذا النمط سير عمل الوكلاء، مستفيدًا من سلوكيات INTELLECT-3 المدربة بيئيًا.
يشكل التعامل مع الأخطاء جزءًا حيويًا. تشمل المشكلات الشائعة 401 (مفتاح غير صالح)، 429 (حد المعدل)، و 400 (طلب خاطئ التنسيق). نفّذ عمليات إعادة المحاولة مع التراجع الأسي:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
تتضمن الاستجابات بيانات تعريف مثل usage (prompt_tokens, completion_tokens, total_tokens)، والتي تسجلها للتحسين. يعالج INTELLECT-3 ما يصل إلى 4096 رمزًا مميزًا لكل إكمال، موازنًا بين العمق والسرعة.
تعزز استجابات البث المباشر التطبيقات في الوقت الفعلي. أضف stream=True إلى استدعاء الإنشاء؛ يعطي العميل أجزاء كأحداث مرسلة من الخادم. قم بتحليلها تكراريًا:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
تناسب هذه التقنية برامج الدردشة أو مساعدي الأكواد المباشرة، حيث يتوقع المستخدمون ملاحظات تدريجية.
بعد إتقان صياغة الطلبات، يمكنك تقييم الأداء. يقدم الجزء التالي أدوات قياس الأداء المصممة خصيصًا لـ INTELLECT-3.
تحسين وتقييم استخدام واجهة برمجة تطبيقات INTELLECT-3
يمكنك تحسين استدعاءات واجهة برمجة التطبيقات عن طريق ضبط المعلمات تجريبيًا. ابدأ بتجميع رسائل متعددة في طلب واحد لتحقيق مكاسب في الإنتاجية — كفاءة تصل إلى 10 أضعاف في مجموعات التقييم. تدعم واجهة سطر الأوامر (CLI) الخاصة بـ Prime Intellect هذا:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
يقوم هذا الأمر بتشغيل 100 عينة من GSM8K، ويجمع مقاييس الدقة وزمن الانتقال. تقوم بتحليل النتائج لضبط top_p أو frequency_penalty، مما يقلل التكرار في التوليدات الطويلة.
يمتد التقييم إلى بيئات مخصصة من مركز المدققين (Verifiers Hub). قم بتحميل بيئة التعلم المعزز (RL) واستعلم عن INTELLECT-3 كسياسة:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
تقيس المكافآت التحسينات، وتوجه الضبط الدقيق إذا كنت تستضيف محليًا. بالنسبة لمستخدمي واجهة برمجة التطبيقات فقط، سجل التفاعلات في قاعدة بيانات متجهات واحسب المقاييس النهائية مثل معدل نجاح المهمة.
تعد اعتبارات الأمان مهمة أيضًا. قم بتنقية مدخلات المستخدم لمنع حقن المطالبات، واستخدم مطالبات النظام لفرض الحدود. تقلل خلفية INTELLECT-3 في التعلم المعزز (RL) من الهلوسات، ولكن عليك التحقق من المخرجات مقابل المدققين للتطبيقات عالية المخاطر.
يتضمن التوسع المراقبة عبر لوحة التحكم. قم بتعيين تنبيهات لعتبات الرموز المميزة، وتكامل مع أدوات المراقبة مثل Prometheus، والتي تعرضها Prime Intellect للمجموعات. وبالتالي، تحافظ على الموثوقية مع تزايد الاستخدام.
الآن بعد أن تعاملت مع التحسين، فكر في التكاليف. تضمن شفافية التسعير تكاملاً مستدامًا.
تسعير واجهة برمجة تطبيقات INTELLECT-3: نموذج شفاف قائم على الرمز المميز
تنظم Prime Intellect التسعير بناءً على استهلاك الرموز المميزة، وتفرض رسومًا منفصلة على المدخلات والمخرجات. تدفع لكل 1,000 رمز مميز، وتختلف الأسعار حسب النموذج والمزود. بالنسبة لـ INTELLECT-3، توقع أرقامًا تنافسية — حوالي 0.50 دولار لكل مليون رمز مميز للمدخلات و 1.50 دولار لكل مليون للمخرجات — على الرغم من أن القيم الدقيقة تظهر في استجابة نقطة نهاية النماذج.
| المزود | المدخلات ($$ /مليون رمز) | المخرجات ($$ /مليون رمز) | ملاحظات |
|---|---|---|---|
| Prime Intellect Direct | ~$0.45–$0.60 | ~$1.30–$1.80 | أقل تكلفة، خصومات على الكميات |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | تتضمن رسوم منصة OpenRouter |
تتقلب الأسعار الدقيقة؛ تحقق دائمًا من أحدث القيم في لوحة التحكم الخاصة بك أو عبر نقطة نهاية النماذج.
أيهما يجب أن تختار؟
- اختر Prime Intellect مباشرةً إذا كنت تريد أقصى سرعة، أقل تكلفة، أو تخطط لاستخدام بكميات كبيرة.
- اختر OpenRouter إذا كنت تفضل مفتاح API واحدًا عبر أكثر من 50 نموذجًا، أو تحتاج إلى بدء تشغيل فوري، أو تريد توجيهًا احتياطيًا مدمجًا.
يقدم كلا الخيارين نفس أداء INTELLECT-3. اختر الخيار الذي يناسب سير عملك — تستخدم العديد من الفرق كلاهما في وقت واحد للتكرار.
ينطبق بقية هذا الدليل (تنسيقات الطلبات، البث المباشر، استدعاء الأدوات، التحسين، إلخ) بالتساوي سواء قمت بالاتصال بـ Prime Intellect مباشرة أو عبر OpenRouter.
تابع مع تفاصيل التنفيذ التقني الكاملة أدناه، وابدأ البناء باستخدام INTELLECT-3 اليوم — عبر أي بوابة تعمل بشكل أفضل لك.
عمليات التكامل المتقدمة مع واجهة برمجة تطبيقات INTELLECT-3
يمكنك توسيع INTELLECT-3 ليشمل بيئات مثل LangChain أو LlamaIndex للتنسيق. في LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
يربط هذا واجهة برمجة التطبيقات بخطوط أنابيب التوليد المعزز بالاسترجاع (RAG)، مما يعزز الدقة بالمعرفة الخارجية.
بالنسبة للخدمات المصغرة، قم بالنشر عبر أغلِفة FastAPI التي تعمل كوكيل لـ INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
اكشف عن نقطة النهاية هذه بشكل آمن، مع تحديد معدل الطلبات باستخدام Redis. تعمل هذه الإعدادات على تشغيل أدوات SaaS، من مولدات المحتوى إلى مساعدي البحث.
تتطلب الحالات الخاصة اهتمامًا. تعامل مع تجاوزات الرموز المميزة عن طريق اقتطاع المدخلات ديناميكيًا، والرجوع إلى نماذج أصغر إذا كانت INTELLECT-3 في قائمة الانتظار. تقدم منتديات المجتمع على موقع Prime Intellect موضوعات استكشاف الأخطاء وإصلاحها.
الخاتمة: نشر واجهة برمجة تطبيقات INTELLECT-3 بثقة
أنت الآن تمتلك مجموعة أدوات شاملة لاستخدام واجهة برمجة تطبيقات INTELLECT-3. من جذورها مفتوحة المصدر إلى التعامل الدقيق مع الطلبات وإدارة التكاليف، يجهزك هذا الدليل لعمليات النشر في العالم الحقيقي. جرب Apidog لتحسين سير عملك، وراقب الوثائق المتطورة للحصول على التحديثات.
نفذ هذه التقنيات تدريجيًا — ابدأ بالدردشات البسيطة، ثم قم بالتوسع إلى الوكلاء. تضع كفاءة INTELLECT-3 وانفتاحه كخيار مفضل لمشاريع الذكاء الاصطناعي التقنية. ابدأ بالترميز اليوم، وشاهد التأثير على تطبيقاتك.