
مقدمة
مع استمرار نمو حجم البيانات، تصبح واحدة من الطرق الشائعة في تدريب نماذج التعلم الآلي هي التدريب على دفعات. تنطوي هذه الطريقة على تقسيم مجموعة البيانات إلى مجموعات فرعية أصغر أو "دفعات"، يتم إدخالها إلى النموذج واحدة تلو الأخرى.
في هذه المقالة، سنستكشف ثلاث تقنيات مختلفة لتقسيم مجموعات البيانات إلى دفعات:
- إنشاء موتر كبير
- تحميل بيانات جزئية باستخدام HDF5
- استخدام مولدات بايثون
لتوضيح ذلك، سنفترض أن النموذج هو كاشف يعتمد على الصوت، لكن الطرق المناقشة قابلة للتطبيق على نطاق واسع. على الرغم من أن هذا المثال محدد، فإن الخطوات الأساسية - التقسيم، المعالجة المسبقة، والتكرار على البيانات - ذات صلة عالمية. يمكن استخدام هذه التقنيات مع مصادر بيانات متنوعة، مثل ملفات الصور، الجداول من استعلام SQL، أو استجابة HTTP. التركيز هنا هو على العملية نفسها.
سنقوم بتقييم كل طريقة من خلال النظر في العوامل التالية:
- جودة الكود
- استخدام الذاكرة
- كفاءة الوقت
قبل أن نبدأ، إذا كنت تقوم باختبار API وتحتاج إلى بديل مناسب لـ Postman (الذي أصبح أكثر تكلفة ويقدم ميزات أقل)، فإن APIDog هو خيارك المثالي!

APIDog هي منصة تعاونية مصممة لإدارة واختبار API، مشابهة لـ Postman، ولكن مع ميزات إضافية تجعل التعامل مع التواريخ أسهل. إليك كيف يمكن أن يساعد:
ما هي الدفعة في سياق مجموعات البيانات
الدفعة هي عمومًا زوج من المدخلات والمخرجات (X[i]، y[i])، تمثل مجموعة فرعية من البيانات. بالنسبة لكاشفنا المعتمد على الصوت، يتلقى النموذج تسلسل صوتي مُعالج كمدخلات ويخرج احتمال حدوث حدث معين. في هذه الحالة، تتكون الدفعة من:
- X[t] - مصفوفة تمثل المسار الصوتي المُعالج المؤخذ على مدار فترة زمنية
- y[t] - تسمية ثنائية تشير إلى حدوث الحدث.
هنا، تشير t إلى فترة الزمن (الشكل 1).
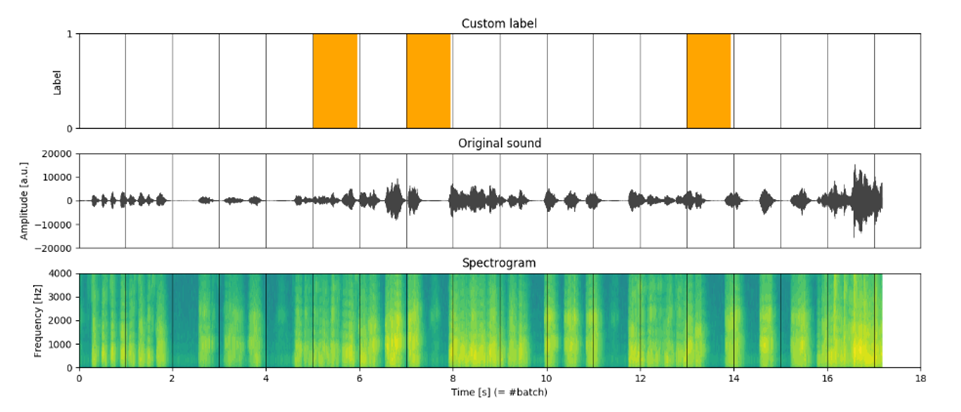
مقارنة الطرق المختلفة لتقسيم مجموعات البيانات
النهج #1 - استخدام موتر كبير
يتلقى النموذج المدخلات على شكل موتر ثنائي الأبعاد. لاستيعاب معالجة الدفعات، يمكننا زيادة رتبة الموتر، باستخدام البعد الثالث لتمثيل حجم الدفعة. الخطوات في هذه العملية هي كما يلي:
- تحميل بيانات المدخلات (X).
- تحميل الملصقات المقابلة (y).
- تقسيم X و y إلى دفعات أصغر.
- استخراج الميزات لكل دفعة (مثل الطيف الصوتي).
- دمج الدفعات المعالجة من X[t] و y[t].
ومع ذلك، لماذا قد لا تكون هذه الطريقة مثالية؟ دعونا نستكشف مثالاً للتطبيق لفهم الأمر بشكل أفضل.
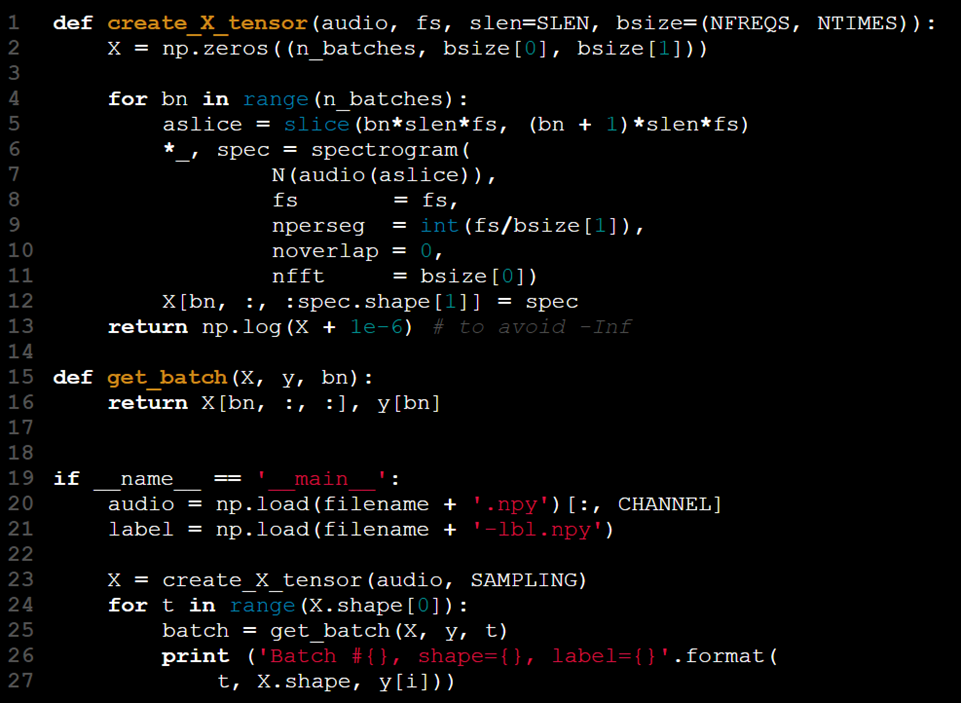
يمكن تلخيص هذا النهج على أنه "تحميل كل شيء دفعة واحدة والتعامل مع العواقب لاحقًا."
المزايا والعيوب لنهج "الموتر الكبير"
بينما قد يبدو التعامل مع X كمجموعة بيانات ذاتية الاكتفاء مفيدًا، هناك عدة عيوب لهذه الطريقة:
1. قيود الذاكرة: تحميل مجموعة البيانات بالكامل في RAM يمكن أن يسبب مشاكل، خاصة إذا كانت الذاكرة المتاحة غير كافية لاستيعاب كل البيانات.
2. صلابة بعد الدفعة: يتم استخدام البعد الأول لـ X لتمثيل حجم الدفعة، لكن هذه مجرد قاعدة. إذا قرر شخص ما تغيير هذا الترتيب (مثل استخدام البعد الأخير للدفعات)، سيتطلب الأمر تعديلات على الكود.
3. تتبع الدفعات: على الرغم من أن X.shape[0] يعطي العدد الدقيق للدفعات، لا يزال عليك استخدام متغير مساعد (مثل t) لتتبع الدفعة الحالية، مما يزيد من تعقيد الكود.
4. وظيفة زائدة: يتطلب هذا التصميم وجود وظيفة get_batch، التي تخدم فقط لتقطيع ودمج X و y للدفعات، مما يجعل الكود غير ضروري ومعقد.
النهج #2 - تحميل الدفعات باستخدام HDF5
إحدى الطرق لمعالجة مشكلة تحميل كل البيانات في RAM هي تحميل أجزاء فقط من البيانات حسب الحاجة. إذا كانت البيانات مخزنة في ملف، فمن المنطقي تحميل والعمل على أقسام صغيرة بدلاً من مجموعة البيانات الكاملة.
في حالة ملفات CSV، استخدام الوسائط skiprows و nrows في وظيفة read_csv الخاصة بـ Pandas يسمح لك بتحميل أجزاء محددة من الملف.
ولكن هل تلتقط هذه الطريقة حقًا جميع السيناريوهات؟ لنفترض أننا نريد التعامل مع بعض البيانات الكبيرة والمعقدة جدًا، أي ملفات الصوت، قد لا يكون من الملائم التعامل معها باستخدام skiprows أو nrow باستخدام وظيفة read_csv من pandas. لهذا السبب هنالك طريقة أخرى: التنسيق الهرمي لتخزين البيانات (HDF5).
يدعم هذا التنسيق تخزين مصفوفات متعددة ويوفر وسيلة مريحة للوصول إليها ومعالجتها بشكل مماثل لمصفوفات NumPy.
على سبيل المثال، يمكنك العمل مع مجموعات البيانات المسماة "audio" و "label" المخزنة في ملف HDF5. مكتبة بايثون h5py هي أداة مفيدة لإدارة هذا التنسيق.
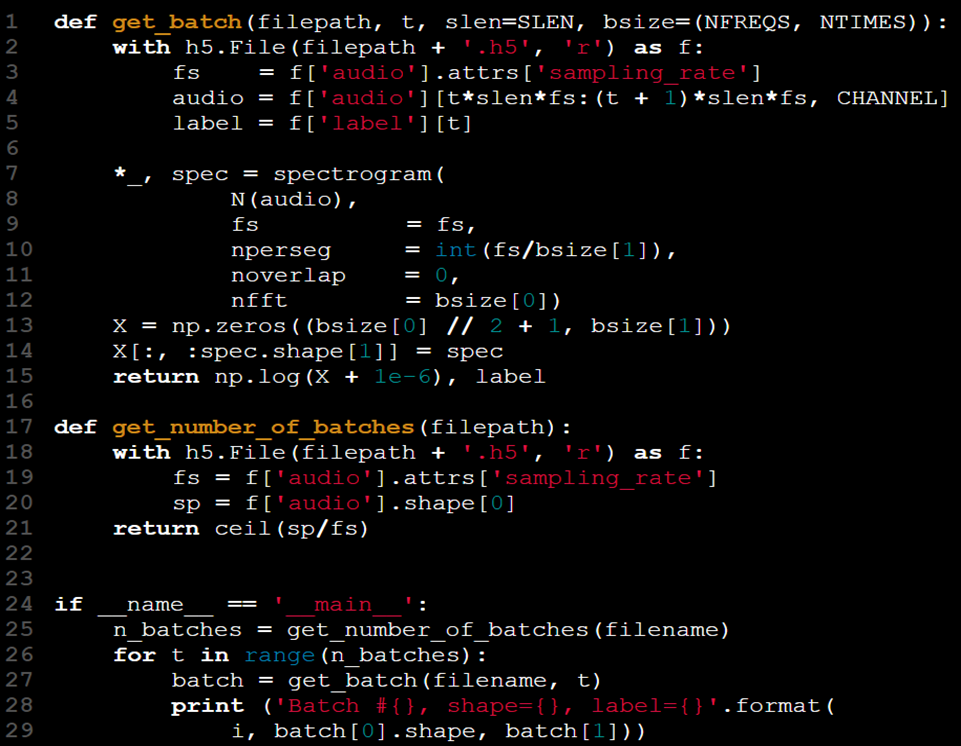
الآن بعد أن أصبحت بياناتنا أكثر قابلية للإدارة، فقد حسنّا أيضًا جودتها العامة:
- تم استبدال الوظيفة السابقة get_batch بإصدار أكثر عملية يحسب ويسترد البيانات بكفاءة.
- لم يعد هناك حاجة لتعديل موتر X بشكل مصطنع.
- من خلال تغيير get_batch(X, y, t) إلى get_batch(filename, t)، قمنا بتجريد الوصول إلى البيانات وألغينا الحاجة للاحتفاظ بـ X و y في مساحة الاسم.
- أصبحت مجموعة البيانات الآن موحدة في ملف واحد، مما يجعل من غير الضروري الحصول على البيانات والعلامات من ملفات منفصلة.
- تم تضمين معدل العينة (fs) كجزء من ملف مجموعة البيانات من خلال سمات HDF5، مما يلغي الحاجة لتمريره كوسيط منفصل.
على الرغم من هذه التحسينات، لا تزال هناك تحديات:
- لا تتتبع الوظيفة الجديدة get_batch حالتها، لذا لا يزال علينا الاعتماد على استخدام حلقة للتحكم في t. لا توجد وسيلة مضمنة للوظيفة لمعرفة حجم الحلقة، مما يتطلب منا التحقق من حجم البيانات مسبقًا. وهذا يستلزم إنشاء وظيفة ثانية: get_number_of_batches.
- بينما تجعل هذه الإعدادات أفضل، فإنها لا تزال تفتقر إلى أناقة وظيفة get_batch التي تحافظ على الحالة بالكامل، مما قد يبسط العملية أكثر.
النهج #3 - استخدام المولدات
ما هي المولدات؟
المولدات هي وظائف تعيد كائنات المكرر. بدلاً من حساب جميع النتائج مقدمًا، توفر هذه المكررات البيانات قطعة واحدة في كل مرة، منتظرةً الطلب التالي للمتابعة. مما يجعلها خيارًا مثاليًا للتعامل مع مجموعات البيانات الكبيرة بكفاءة.
لنحدد نمطًا متكررًا:
نحتاج فقط إلى الوصول إلى أجزاء البيانات ومعالجتها وتقديمها بشكل متسلسل، بدلاً من تحميل كل شيء دفعة واحدة. تقدم بايثون حلاً لذلك على شكل مولدات.
يمكن تنفيذ المولدات بثلاث طرق:
استخدام تعبير مولد، مشابه لقائمة الفهم لكن باستخدام أقواس بدلاً من أقواس مربعة (مثل (i for i in iterable)).
إنشاء وظيفة مولد باستخدام yield بدلاً من return.
تعريف فئة مع iter_ مخصص (أو getitem_) و _next_ methods.
في هذا السيناريو، فإن الكلمة الرئيسية yield تناسب احتياجاتنا، مما يسمح لنا بمعالجة وإرجاع البيانات في قطع قابلة للإدارة.
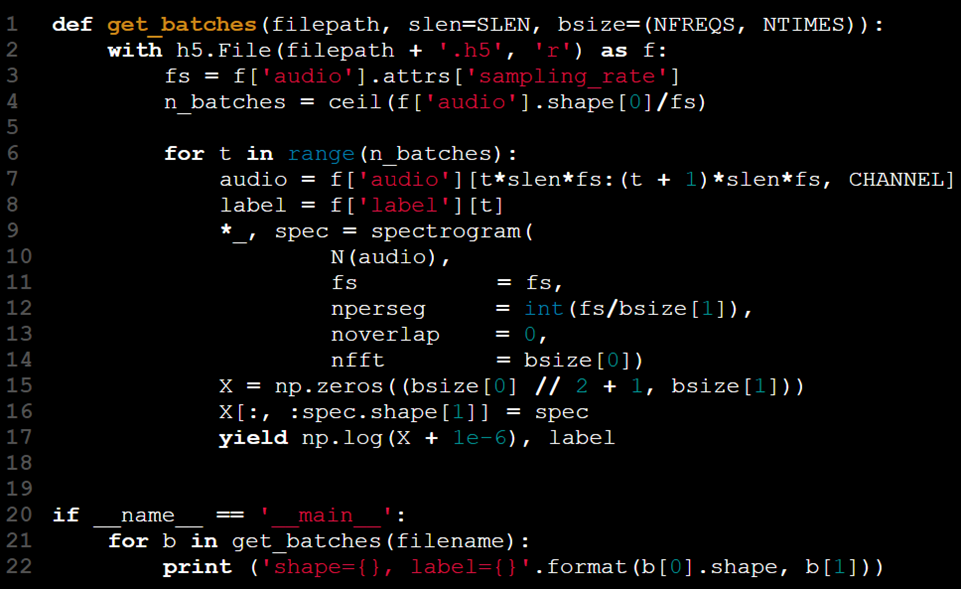
الآن، الحلقة محصورة داخل الوظيفة. من خلال استخدام عبارة yield، يتم إرجاع الزوج (X[t]، y[t]) فقط عندما يتم استدعاء get_batches مرات t - 1. وهذا يلغي الحاجة إلى إدارة حالة الحلقة عبر كود تدريب النموذج. تحتفظ الوظيفة بحالتها بين الاستدعاءات، مما يسمح للمستخدم بالتكرار عبر الدفعات ببساطة دون الحاجة إلى مؤشر دفعة يدوي.
يمكن مقارنة مكررات المولدات بالحاويات التي تفرغ تدريجيًا مع معالجة البيانات. نظرًا لأن الدفعات يتم استردادها مع كل تكرار، تستمر العملية حتى يتم استهلاك كل البيانات، مما يلغي الحاجة إلى الفهرسة الصريحة أو شروط التوقف.
الأداء: الوقت والذاكرة
بدأنا بالتركيز على جودة الكود، حيث تتوافق بشكل وثيق مع طريقة تطور الحل. ومع ذلك، من المهم أيضًا مراعاة قيود الموارد، خصوصًا عند التعامل مع مجموعات البيانات الكبيرة.
يوضح الشكل 2 الوقت المطلوب لتقديم الدفعات باستخدام الطرق الثلاث التي ناقشناها. كما هو ملاحظ، فإن الوقت اللازم لمعالجة ونقل البيانات يبقى تقريبًا نفسه عبر جميع الطرق. سواء قمنا بتحميل جميع البيانات دفعة واحدة ثم تقسيمها إلى دفعات، أو قمنا بمعالجتها بشكل تدريجي من البداية، فإن الوقت الإجمالي للحصول على النتيجة يكاد يكون متطابقًا. قد يرجع ذلك جزئيًا إلى استخدام SSDs، التي توفر وصولًا أسرع إلى البيانات. ومع ذلك، يبدو أن النهج المختار له تأثير ضئيل على الأداء الزمني العام.
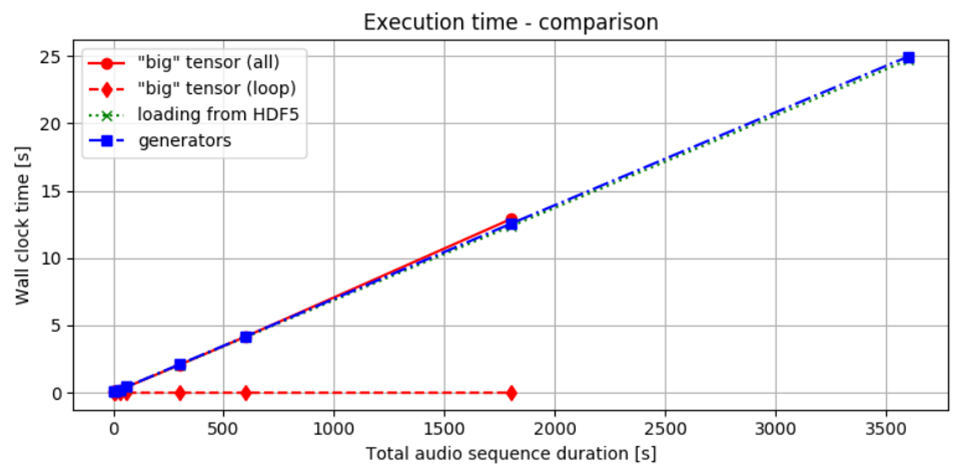
الشكل 2. مقارنة أداء الوقت: تشير الخط الأحمر المتصل إلى الوقت المستغرق لتحميل البيانات إلى الذاكرة وإجراء الحسابات. بينما تمثل الخطوط الحمراء المتقطعة الوقت المستغرق فقط في الدورة التي تعالج الشرائح، مع افتراض أنه تم حساب البيانات مسبقًا.
يوضح الخط الأخضر المتقطع توقيت تحميل الدفعات من ملف HDF5، بينما يظهر الخط الأزرق المتقطع الأداء باستخدام مولد. عند مقارنة الخطوط الحمراء، من الواضح أن الوصول إلى البيانات بمجرد تحميلها في RAM يتحمل تكلفة إضافية ضئيلة. عندما تكون البيانات محلية، فإن الفروقات بين الطرق المختلفة تكون قليلة نسبياً.
الشكل 3. مقارنة استخدام الذاكرة: يظهر النهج الأول استهلاك الذاكرة الأعلى، مما يؤدي إلى حدوث خطأ في الذاكرة عند التعامل مع عينة صوتية طويلة تصل إلى ساعة واحدة. على العكس، فإن طريقة التحميل المستندة إلى القطع تتحكم في تخصيص الذاكرة بناءً على حجم الدفعة، مما يضمن أن يبقى استخدام RAM ضمن الحدود الآمنة.
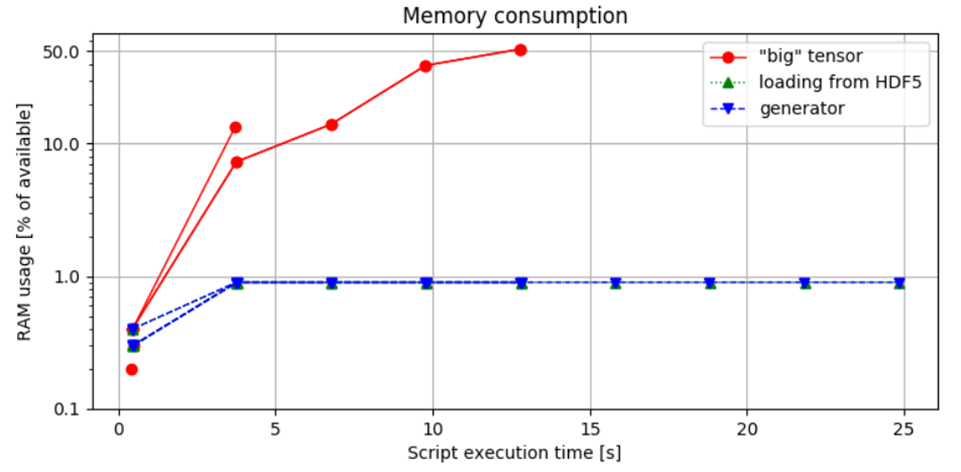
الشكل 3. مقارنة استهلاك الذاكرة: يوضح هذا الشكل النسبة المئوية من RAM المتاحة التي استخدمها برنامج بايثون، وتم قياسه عن طريق تشغيل البرنامج بالأمر:
python idea.py & top -b -n 10 > capture.log;cat capture.log | egrep python > analysis.log، ثم تحليله لاحقًا.
ملاحظات ورؤى:
تظهر المقارنة بين الطريقتين الثانية والثالثة أنه لا يوجد فرق كبير في استخدام الذاكرة، مما يدل على أن الخيار لتنفيذ مولد مكرر لا يؤثر على بصمة الذاكرة. تسلط هذه النتيجة الضوء على نقطة مهمة: بينما غالبًا ما يُوصى بالمولدات لكفاءتها في إدارة الوقت والذاكرة، فإنها لا تقلل بالضرورة من استهلاك الموارد.
العامل الرئيسي هو كفاءة الوصول إلى البيانات والقدرة على معالجة البيانات في قطع قابلة للإدارة.
يعتبر استخدام ملفات HDF5 ميزة حيث يسمح بالوصول السريع إلى البيانات والمرونة لتجنب تحميل كل البيانات دفعة واحدة. في حين أن دمج مولد يعزز من قرائية وجودة الكود.
يبدو أن الجمع بين استخدام HDF5 لتحميل البيانات الجزئية مع المولدات هو النهج الأكثر فعالية، كما يتضح من الطريقة الثالثة. يعمل هذا الجمع على تحسين إدارة الذاكرة ووضوح الكود.
كيفية تقسيم مجموعات البيانات في بايثون (أمثلة)
تذكر أنه في بايثون، يمكنك تقسيم مجموعة بيانات إلى دفعات باستخدام مجموعة متنوعة من الطرق، اعتمادًا على نوع البيانات والإطار الذي تعمل به. فيما يلي العديد من الطرق الشائعة:
- بايثون فقط: استخدم حلقة بسيطة أو مولد لتقسيم القوائم أو المصفوفات.
- NumPy: استخدم numpy.array_split لتقسيم المصفوفات.
- PyTorch: استخدم DataLoader لتجميع فعّال في الشبكات العصبية.
- TensorFlow: استخدم tf.data.Dataset لتجميع بيانات فعّال وخطوط بيانات.
- Pandas: استخدم قوائم الفهم أو الحلقات لتقسيم DataFrames.
1. استخدام وظيفة بايثون بسيطة
إذا كان لديك مجموعة بيانات على شكل قائمة أو مصفوفة NumPy، يمكنك استخدام وظيفة مخصصة لتقسيم البيانات إلى دفعات.
def split_into_batches(data, batch_size):
"""تقسيم البيانات إلى دفعات بحجم محدد."""
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
# مثال على الاستخدام
dataset = [i for i in range(100)] # مجموعة البيانات المثالية
batch_size = 10
batches = list(split_into_batches(dataset, batch_size))
# طباعة الدفعات
for batch in batches:
print(batch)2. استخدام numpy.array_split
إذا كانت مجموعة بياناتك على شكل مصفوفة NumPy، يمكنك استخدام وظيفة numpy.array_split() لتقسيم مجموعة البيانات إلى دفعات.
import numpy as np
# مجموعة البيانات المثالية
dataset = np.arange(100)
# تقسيم إلى دفعات
batch_size = 10
batches = np.array_split(dataset, len(dataset) // batch_size)
# طباعة الدفعات
for batch in batches:
print(batch)3. استخدام torch.utils.data.DataLoader (PyTorch)
إذا كنت تعمل مع PyTorch، يمكنك بسهولة تجميع مجموعة بياناتك باستخدام DataLoader، والذي يمكنه خلط وتجميع بياناتك.
import torch
from torch.utils.data import DataLoader, TensorDataset
# مجموعة البيانات المثالية
data = torch.arange(100)
labels = torch.arange(100) # لنفترض أن لديك تسميات كذلك
# إنشاء مجموعة بيانات Tensor
dataset = TensorDataset(data, labels)
# تقسيم إلى دفعات باستخدام DataLoader
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# طباعة الدفعات
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)مثال: قائمة بسيطة لتحقيق الفهرس
import math
import torch
import torch.nn as nn
X = torch.rand(1000,10, 4)
batch_size = 64
num_batches = math.ceil(X.size()[0]/batch_size)
X_list = [X[batch_size*y:batch_size*(y+1),:,:] for y in range(num_batches)]
print(X_list[0].size())4. استخدام tensorflow.data.Dataset (TensorFlow)
بالنسبة لـ TensorFlow، توفر واجهة برمجة التطبيقات tf.data.Dataset طريقة عالية الأداء لتجميع مجموعات البيانات.
import tensorflow as tf
# مجموعة البيانات المثالية
dataset = tf.data.Dataset.range(100)
# تقسيم إلى دفعات
batch_size = 10
batched_dataset = dataset.batch(batch_size)
# طباعة الدفعات
for batch in batched_dataset:
print(batch.numpy())5. استخدام pandas لتقسيم البيانات
إذا كانت مجموعة بياناتك عبارة عن DataFrame من pandas، يمكنك تقسيمها إلى دفعات من خلال تقسيمها.
import pandas as pd
# مجموعة البيانات المثالية
data = pd.DataFrame({'A': range(100), 'B': range(100)})
# تقسيم إلى دفعات
batch_size = 10
batches = [data[i:i+batch_size] for i in range(0, data.shape[0], batch_size)]
# طباعة الدفعات
for batch in batches:
print(batch)أفكار نهائية
في هذه المقالة، استكشافنا ثلاث طرق لتقسيم ومعالجة البيانات في دفعات، مقارنةً أدائها وجودة الكود العامة. لقد لاحظنا أنه في حين أن المولدات وحدها لا تعزز الكفاءة بالضرورة، فإنها تساهم في حل أكثر أناقة وقابلية للقراءة. في النهاية، تتأثر فعالية كل نهج بقيود الوقت والذاكرة.
أي نهج تجدونه الأكثر جاذبية؟
اختر الطريقة التي تناسب تنسيق بياناتك واحتياجات المعالجة بشكل أفضل.
حظا موفقا!
الأسئلة الشائعة حول تقسيم مجموعات البيانات في بايثون
كيف أقوم بتقسيم مجموعة بيانات إلى دفعات في بايثون؟
لتقسيم مجموعة بيانات إلى دفعات في بايثون، يمكنك استخدام مكتبات مثل NumPy أو PyTorch. إليك مثال بسيط باستخدام NumPy:
import numpy as np
def create_batches(data, batch_size):
return np.array_split(data, np.ceil(len(data) / batch_size))
# مثال على الاستخدام
data = np.arange(10) # مجموعة بيانات مثالية
batches = create_batches(data, 3)
print(batches)
تقسم هذه الوظيفة مجموعة البيانات إلى دفعات بالحجم المحدد.
كيف يجب أن أقسم مجموعة بياناتي؟
عند تقسيم مجموعة بيانات، ضع في اعتبارك الاستراتيجيات التالية:
- تقسيم عشوائي: خلط المجموعة وتقسيمها إلى مجموعات تدريب وتحقق واختبار.
- تقسيم متحسس: التأكد من أن كل مجموعة فرعية تحافظ على نفس توزيع الفئات المستهدفة كما هو الحال في مجموعة البيانات الأصلية.
- تقسيم زمني: بالنسبة لبيانات السلاسل الزمنية، قم بالتقسيم بناءً على الوقت للحفاظ على التسلسل.
الممارسة الشائعة هي استخدام مزيج من هذه الطرق لضمان تمثيل عينة في كل مجموعة فرعية.
كيف أقسم مجموعة بيانات 80 20؟
لتقسيم مجموعة بيانات إلى 80% للتدريب و20% للاختبار، يمكنك استخدام وظيفة train_test_split من وحدة sklearn.model_selection:
from sklearn.model_selection import train_test_split
data = ... # مجموعة بياناتك
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
سيقوم هذا الكود بتقسيم مجموعة البيانات عشوائيًا، مما يخصص 80% لـ train_data و20% لـ test_data.
كيف أختار حجم دفعة لمجموعة بيانات كبيرة؟
اختيار حجم دفعة لمجموعة بيانات كبيرة يتضمن عدة اعتبارات:
- قيود الذاكرة: تأكد من أن حجم الدفعة يناسب حدود ذاكرة GPU أو CPU الخاصة بك.
- استقرار التدريب: يمكن أن تؤدي أحجام الدفعات الصغيرة إلى تدريب أكثر استقرارًا ولكن قد تزيد من وقت التدريب.
- ديناميكيات التعلم: يمكن أن تسرع أحجام الدفعات الأكبر التدريب ولكن قد تؤدي إلى تعميم أضعف.
نهج شائع هو البدء بحجم دفعة يبلغ 32 أو 64 ثم ضبطه بناءً على الأداء وتوافر الموارد. التجربة هي المفتاح للعثور على الحجم الأمثل للدفعة في سيناريو محدد خاص بك.
قبل أن نختتم، إذا كنت تقوم باختبار API وتحتاج إلى بديل مناسب لـ Postman (الذي أصبح أكثر تكلفة ويقدم ميزات أقل)، فإن APIDog هو خيارك المثالي!
APIDog هي منصة تعاونية مصممة لإدارة واختبار API، مشابهة لـ Postman، ولكن مع ميزات إضافية تجعل التعامل مع التواريخ أسهل. إليك كيف يمكن أن يساعد: