
عالم الذكاء الاصطناعي (AI) يتطور بسرعة مذهلة، مع نماذج اللغة الكبيرة (LLMs) مثل ChatGPT وClaude وGemini التي تأسر الخيال في جميع أنحاء العالم. يمكن لهذه الأدوات القوية كتابة الشيفرات، وصياغة الرسائل الإلكترونية، والإجابة على الأسئلة المعقدة، وحتى توليد محتوى إبداعي. ومع ذلك، فإن استخدام هذه الخدمات السحابية غالبًا ما يأتي مع مخاوف حول خصوصية البيانات، والتكاليف المحتملة، والحاجة إلى اتصال دائم بالإنترنت.
إليكم أولا.
أولا هو أداة قوية مفتوحة المصدر مصممة لديمقراطية الوصول إلى نماذج اللغة الكبيرة من خلال تمكينك من تحميلها وتشغيلها وإدارتها مباشرة على جهاز الكمبيوتر الخاص بك. إنها تبسط عملية إعداد والتفاعل مع نماذج الذكاء الاصطناعي الحديثة محليًا، والتي غالبًا ما تكون معقدة.
لماذا تستخدم أولا؟

تشغيل نماذج اللغة الكبيرة محليًا باستخدام أولا يوفر عدة مزايا مقنعة:
- الخصوصية: تظل مطالباتك وردود النموذج على جهازك. لا يتم إرسال أي بيانات إلى خوادم خارجية ما لم تقم بتكوين ذلك بشكل صريح. هذه نقطة مهمة للمعلومات الحساسة أو العمل المملوك.
- الوصول غير المتصل: بمجرد تحميل نموذج، يمكنك استخدامه بدون اتصال بالإنترنت، مما يجعله مثاليًا للسفر أو المواقع النائية أو الحالات ذات الاتصال غير الموثوق.
- التخصيص: يتيح لك أولا تعديل النماذج بسهولة باستخدام "ملفات النموذج"، مما يسمح لك بتخصيص سلوكها، والمطالبات النظامية، والمعلمات وفقًا لاحتياجاتك المحددة.
- فعالية التكلفة: لا توجد رسوم اشتراك أو رسوم لكل رمز. التكلفة الوحيدة هي الأجهزة التي تمتلكها بالفعل والكهرباء لتشغيلها.
- استكشاف وتعلم: توفر منصة رائعة للتجربة مع نماذج مفتوحة المصدر المختلفة، وفهم قدراتها وحدودها، وتعلم المزيد عن كيفية عمل نماذج اللغة الكبيرة.
تم تصميم هذه المقالة للمبتدئين الذين يشعرون بالراحة في استخدام واجهة سطر الأوامر (مثل Terminal على macOS/Linux أو Command Prompt/PowerShell على Windows) ويرغبون في البدء في استكشاف عالم نماذج اللغة الكبيرة المحلية باستخدام أولا. سوف نوجهك لفهم الأساسيات، وتنصيب أولا، وتشغيل نموذجك الأول، والتفاعل معه، واستكشاف التخصيص الأساسي.
هل تريد منصة متكاملة، شاملة لفريق مطوريك للعمل معًا بحد أقصى من الإنتاجية؟
أبيدوج تلبي جميع احتياجاتك، وتحل محل Postman بسعر أكثر ملاءمة!

كيف يعمل أولا؟
قبل أن نغوص في عملية التثبيت، دعنا نوضح بعض المفاهيم الأساسية.
ما هي نماذج اللغة الكبيرة (LLMs)؟
فكر في النموذج الكبير كنظام تكملة تلقائية متقدم للغاية تم تدريبه على كميات هائلة من النصوص والشيفرات من الإنترنت. من خلال تحليل الأنماط في هذه البيانات، يتعلم القواعد والحقائق والقدرات الاستدلالية وأنماط الكتابة المختلفة. عندما تعطيه مطالبة (نص المدخلات)، يتوقع تسلسل الكلمات الأكثر احتمالية للمتابعة، مما ينتج عنه استجابة متماسكة وغالبًا ما تكون بصيرة. تم تدريب نماذج اللغة الكبيرة المختلفة مع مجموعات بيانات وأحجام وهياكل مختلفة، مما يؤدي إلى تفاوت نقاط قوتها وضعفها وشخصياتها.
كيف يعمل أولا؟
يعمل أولا كمدير ومشغل لهذه النماذج الكبيرة على جهازك المحلي. تشمل وظائفه الأساسية:
- تحميل النموذج: يقوم بجلب أوزان النموذج المعبأة مسبقًا والتكوينات من مكتبة مركزية (تشبه إلى حد بعيد كيفية سحب Docker لصور الحاويات).
- تنفيذ النموذج: يقوم بتحميل النموذج المختار إلى ذاكرة جهاز الكمبيوتر الخاص بك (ذاكرة الوصول العشوائي) ويستفيد potentially من بطاقة الرسومات الخاصة بك لتسريع العملية.
- توفير الواجهات: يوفر واجهة سطر أوامر بسيطة للتفاعل المباشر، ويدير أيضًا خادم ويب محلي يقدم واجهة برمجة التطبيقات (API) لتطبيقات أخرى للتواصل مع نموذج اللغة الكبيرة المُشغل.
متطلبات الأجهزة لأولا: هل يمكن لجهاز الكمبيوتر الخاص بي تشغيله؟
تشغيل نماذج اللغة الكبيرة محليًا قد يكون متطلبًا، بشكل رئيسي على ذاكرة الوصول العشوائي لجهاز الكمبيوتر الخاص بك. حجم النموذج الذي تريد تشغيله يحدد الحد الأدنى من الذاكرة المطلوبة.
- النماذج الصغيرة (مثل ~3 مليار معلمة مثل Phi-3 Mini): قد تعمل بشكل معقول مع 8 جيجابايت من ذاكرة الوصول العشوائي، رغم أن المزيد دائمًا ما يكون أفضل لأداء أكثر سلاسة.
- النماذج المتوسطة (مثل 7-8 مليار معلمة مثل Llama 3 8B وMistral 7B): تتطلب عادةً على الأقل 16 جيجابايت من ذاكرة الوصول العشوائي. تعتبر هذه نقطة انطلاق شائعة للعديد من المستخدمين.
- النماذج الكبيرة (مثل 13B+ معلمة): غالبًا ما تحتاج إلى 32 جيجابايت من ذاكرة الوصول العشوائي أو أكثر. قد تتطلب النماذج كبيرة جدًا (70B+) 64 جيجابايت أو حتى 128 جيجابايت.
عوامل أخرى قد تحتاج إلى مراعاتها:
- وحدة المعالجة المركزية: وعلى الرغم من أهميتها، إلا أن معظم وحدات معالجة البيانات الحديثة كافية. تساعد وحدات المعالجة المركزية الأسرع، لكن عادةً ما تكون ذاكرة الوصول العشوائي هي نقطة الاختناق.
- وحدة معالجة الرسومات: امتلاك وحدة معالجة رسومات قوية ومتوافقة (خاصة وحدات معالجة الرسومات NVIDIA على Linux/Windows أو وحدات معالجة الرسومات Apple Silicon على macOS) يمكن أن تسهل تسريع أداء النموذج بشكل كبير. يقوم أولا بالكشف تلقائيًا عن وحدات معالجة الرسومات المتوافقة واستخدامها إذا كانت برامج التشغيل اللازمة مثبتة. ومع ذلك، فإن وحدة معالجة الرسومات المخصصة ليست بالضرورة مطلوبة؛ يمكن لأولا تشغيل النموذج على وحدة المعالجة المركزية فقط، وإن كان بشكل أبطأ.
- مساحة القرص: ستحتاج إلى مساحة كافية على القرص لتخزين النماذج التي تم تنزيلها، والتي يمكن أن تتراوح من بضعة جيجابايت إلى عشرات أو حتى مئات الجيجابايت، اعتمادًا على الحجم وعدد النماذج التي تم تحميلها.
توصية للمبتدئين: ابدأ بنماذج أصغر (مثل phi3 أو mistral أو llama3:8b) وتأكد من حصولك على 16 جيجابايت على الأقل من الذاكرة للوصول إلى تجربة مريحة أولية. تحقق من موقع أولا أو مكتبة النموذج للحصول على توصيات محددة عن الذاكرة المطلوبة لكل نموذج.
كيفية تثبيت أولا على Mac وLinux وWindows (باستخدام WSL)
يدعم أولا أنظمة تشغيل macOS وLinux وWindows (حاليًا في المعاينة، وغالبًا ما يتطلب WSL).
الخطوة 1: المتطلبات الأساسية
- نظام التشغيل: نسخة مدعومة من macOS أو Linux أو Windows (مع WSL2 الموصى بها).
- سطر الأوامر: الوصول إلى Terminal (macOS/Linux) أو Command Prompt/PowerShell/WSL terminal (Windows).
الخطوة 2: تحميل وتثبيت أولا
تختلف العملية قليلاً اعتمادًا على نظام التشغيل الخاص بك:
- macOS:
- اذهب إلى الموقع الرسمي لأولا: https://ollama.com
- انقر على زر "تنزيل"، ثم اختر "تنزيل لـ macOS".
- بمجرد تنزيل ملف
.dmg، افتحه. - اسحب أيقونة تطبيق
أولاإلى مجلدالتطبيقات. - قد تحتاج إلى منح الأذونات في المرة الأولى التي تقوم بتشغيله فيها.
- Linux:
أسرع طريقة هي عادة عبر سكريبت التثبيت الرسمي. افتح المحطة الخاصة بك وقم بتشغيل:
curl -fsSL <https://ollama.com/install.sh> | sh
يقوم هذا الأمر بتنزيل السكريبت وتنفيذه، مما يؤدي إلى تثبيت أولا لمستخدمك. سيحاول أيضًا اكتشاف وتكوين دعم GPU إذا كان ذلك ينطبق (تحتاج إلى برامج تشغيل NVIDIA).
اتبع أي مطالبات تظهر بواسطة السكريبت. تعليمات التثبيت اليدوية متاحة أيضًا في مستودع GitHub الخاص بأولا إذا كنت تفضل ذلك.
- Windows (معاينة):
- اذهب إلى الموقع الرسمي لأولا: https://ollama.com
- انقر على زر "تنزيل"، ثم اختر "تنزيل لويندوز (معاينة)".
- قم بتشغيل المثبت التنفيذي الذي قمت بتحميله (
.exe). - اتبع خطوات معالج التثبيت.
- ملاحظة هامة: يعتمد أولا على Windows Subsystem for Linux (WSL2). قد يطلب منك المثبت تثبيت أو تكوين WSL2 إذا لم يتم إعدادها بالفعل. عادة ما يتطلب تسريع GPU تكوينات WSL محددة وبرامج تشغيل NVIDIA المثبتة داخل بيئة WSL. قد تشعر أن استخدام أولا يكون أكثر طبيعية من خلال محطة WSL.
الخطوة 3: التحقق من التثبيت
بمجرد التثبيت، تحتاج إلى التحقق من أن أولا يعمل بشكل صحيح.
افتح المحطة أو موجه الأوامر لديك. (على Windows، يُوصى غالبًا باستخدام محطة WSL).
اكتب الأمر التالي واضغط على Enter:
ollama --version
إذا كانت عملية التثبيت ناجحة، يجب أن ترى مخرجات تعرض رقم إصدار أولا المثبت، مثل:
إصدار أولا هو 0.1.XX
إذا رأيت هذا، فإن أولا مثبتة وجاهزة للعمل! إذا واجهت خطأ مثل "الأمر غير موجود"، تحقق من خطوات التثبيت، وتأكد من أن أولا قد أضيفت إلى مسار نظامك (عادةً ما يتولى المثبت هذا)، أو حاول إعادة تشغيل المحطة أو جهاز الكمبيوتر لديك.
البدء: تشغيل نموذجك الأول مع أولا
مع تثبيت أولا، يمكنك الآن تحميل والتفاعل مع نموذج لغة كبيرة.
المفهوم: سجل نموذج أولا
تحافظ أولا على مكتبة من النماذج المفتوحة المصدر المتاحة بسهولة. عندما تطلب من أولا تشغيل نموذج ليس لديه محليًا، يقوم بتنزيله تلقائيًا من هذا السجل. فكر في الأمر مثل docker pull لنماذج اللغة الكبيرة. يمكنك تصفح النماذج المتاحة في قسم المكتبة بموقع أولا.
اختيار نموذج
بالنسبة للمبتدئين، من الأفضل البدء بنموذج متوازن وصغير نسبيًا. الخيارات الجيدة تشمل:
llama3:8b: أحدث نموذج من Meta AI (نسخة 8 مليار معلمة). أداء ممتاز بشكل عام، جيد في اتباع التعليمات والبرمجة. يتطلب ~16GB من الذاكرة.mistral: نموذج Mistral AI الشهير الذي يحتوي على 7 مليار معلمة. معروف بأدائه القوي وكفاءته. يتطلب ~16GB من الذاكرة.phi3: نموذج اللغة الصغيرة حديث من Microsoft. جيد جدًا لحجمه، مناسب للأجهزة الأقل قوة. قد يعمل إصدارphi3:miniعلى 8GB من الذاكرة.gemma:7b: سلسلة نماذج Google المفتوحة. منافس قوي آخر في نطاق 7B.
تحقق من مكتبة أولا لمزيد من التفاصيل حول حجم كل نموذج ومتطلبات الذاكرة وحالات الاستخدام النموذجية.
تحميل وتشغيل نموذج (سطر الأوامر)
الأمر الرئيسي الذي ستستخدمه هو ollama run.
افتح المحطة الخاصة بك.
اختر اسم نموذج (مثل llama3:8b).
اكتب الأمر:
ollama run llama3:8b
اضغط على Enter.
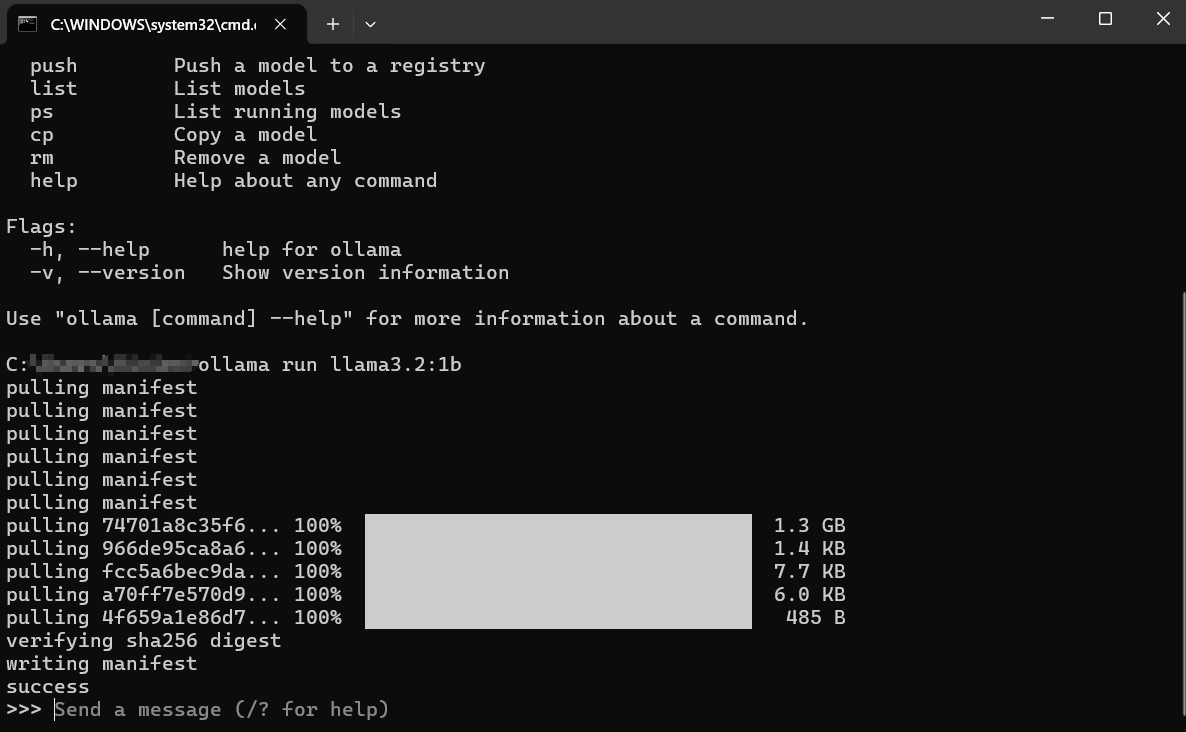
ماذا يحدث بعد ذلك؟
تحميل: إذا لم يكن لديك llama3:8b محليًا، ستظهر أولا شرايط التقدم أثناء تحميل طبقات النموذج. قد يستغرق ذلك بعض الوقت وفقًا لسرعة الإنترنت لديك وحجم النموذج (غالبًا عدة جيجابايت).
التحميل: بمجرد التنزيل، يقوم أولا بتحميل النموذج إلى ذاكرة الوصول العشوائي الخاصة بجهاز الكمبيوتر الخاص بك (وذاكرة GPU، إذا كان ذلك ينطبق). قد ترى رسائل حول الكشف عن الأجهزة.
الدردشة التفاعلية: بعد التحميل، سترى مطالبة مثل: هذا يعني أن النموذج جاهز! أنت الآن في جلسة دردشة تفاعلية مباشرة مع نموذج اللغة الكبيرة الذي يعمل على جهازك.
>>> أرسل رسالة (/? للمساعدة)
التفاعل مع النموذج:
- اكتب سؤالك أو تعليماتك (مطالباتك) بعد
>>>واضغط على Enter. - سيقوم النموذج بمعالجة مدخلاتك وتوليد استجابة، ترسلها بالتدريج إلى محطتك.
- يمكنك متابعة المحادثة بكتابة مطالبات تابعة. يحتفظ النموذج بسياق الجلسة الحالية.
مثال على التفاعل:
> أرسل رسالة (/? للمساعدة)
اشرح مفهوم التمثيل الضوئي بطريقة بسيطة.
>
التمثيل الضوئي هو مثل كيف تصنع النباتات غذاءها بنفسها! تأخذ ثلاث مكونات رئيسية:
1. **أشعة الشمس:** طاقة من الشمس.
2. **الماء:** يمتص من خلال جذورها.
3. **ثاني أكسيد الكربون:** غاز تأخذه من الهواء من خلال ثقوب صغيرة في أوراقها.
باستخدام طاقة الشمس، تجمع النباتات الماء وثاني أكسيد الكربون داخل أجزاء خاصة من خلاياها تسمى البلاستيدات الخضراء. هذه العملية تنتج شيئان:
1. **سكر (جلوكوز):** هذا هو غذاء النبات، مما يمنحه الطاقة لكي ينمو.
2. **أكسجين:** غاز تطلقه النبات مرة أخرى إلى الهواء، وهو ما تحتاجه الحيوانات (مثلنا!) للتنفس.
لذا، ببساطة: النباتات تستخدم أشعة الشمس والماء والهواء لصنع غذائها الخاص وتحرير الأكسجين الذي نحتاجه!
>
>
إنهاء الجلسة:
عندما تنتهي من الدردشة، اكتب /bye واضغط على Enter. سيؤدي ذلك إلى تحميل النموذج من الذاكرة وإعادتك إلى موجه المحطة العادي. يمكنك أيضًا غالبًا استخدام Ctrl+D.
قائمة النماذج التي تم تنزيلها
لمعرفة النماذج التي قمت بتنزيلها محليًا، استخدم الأمر ollama list:
ollama list
ستظهر المخرجات أسماء النماذج، ومعرفاتها الفريدة، وأحجامها، ومتى تم تعديلها آخر مرة:
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB منذ 5 أيام
mistral:latest 8ab431d3a87a 4.1 GB منذ أسبوعين
إزالة نماذج
تستغرق النماذج مساحة على القرص. إذا لم تعد بحاجة إلى نموذج معين، يمكنك إزالته باستخدام الأمر ollama rm متبوعًا باسم النموذج:
ollama rm mistral:latest
ستؤكد أولا عملية الحذف. يزيل هذا فقط الملفات التي تم تنزيلها؛ يمكنك دائمًا تشغيل ollama run mistral:latest مرة أخرى لإعادة تحميلها لاحقًا.
كيفية الحصول على نتائج أفضل من أولا
تشغيل النماذج ما هو إلا البداية. إليك كيفية الحصول على نتائج أفضل:
فهم المطالبات (أساسيات هندسة المطالبات)
تعتمد جودة مخرجات النموذج بشكل كبير على جودة مدخلاتك (المطالبة).
- كن واضحًا ومحددًا: قل للنموذج بالضبط ما تريده. بدلاً من "اكتب عن الكلاب"، جرب "اكتب قصيدة قصيرة ومبهجة عن كلب جولدن ريتريفر يلعب بالكرة."
- وفر سياقًا: إذا كنت تسأل أسئلة متابعة، تأكد من وجود المعلومات الخلفية اللازمة في المطالبة أو في وقت سابق من المحادثة.
- حدد التنسيق: اطلب قوائم، نقاط بالرموز، كتل الشيفرات، جداول، أو نغمة معينة (مثل "اشرح كما لو كنت في الخامسة من عمرك"، "اكتب بنغمة رسمية").
- تكرار: لا تتوقع الكمال من المحاولة الأولى. إذا كانت المخرجات ليست صحيحة، أعد صياغة مطالبتك، أضف مزيدًا من التفاصيل، أو اطلب من النموذج تحسين إجابته السابقة.
تجربة نماذج مختلفة
تتفوق نماذج مختلفة في مهام مختلفة.
Llama 3غالبًا ما تكون رائعة للمحادثات العامة، اتباع التعليمات، والبرمجة.Mistralمشهور بتوازنه بين الأداء والكفاءة.Phi-3قادر بشكل مدهش على الكتابة الإبداعية والتلخيص على الرغم من حجمه الأصغر.- قد تعمل نماذج محددة تضبط للبرمجة (مثل
codellamaأوstarcoder) بشكل أفضل في المهام البرمجية.
تجربة! قم بتشغيل نفس المطالبة عبر نماذج مختلفة باستخدام ollama run <model_name> لمعرفة أي منها يناسب احتياجاتك لأداء مهمة معينة.
مطالبات النظام (تحديد السياق)
يمكنك توجيه السلوك العام للنموذج أو شخصيته لجلسة باستخدام "مطالبة النظام". يشبه ذلك إعطاء تعليمات خلفية للذكاء الاصطناعي قبل بدء المحادثة. في حين أن التخصيص الأعمق ينطوي على Modelfiles (التي يتم تناولها بشكل موجز في السطور التالية)، يمكنك تعيين رسالة نظام بسيطة مباشرة عند تشغيل النموذج:
# قد تختلف هذه الميزة قليلاً؛ تحقق من `ollama run --help`
# قد يدمج أولا ذلك في الدردشة مباشرة باستخدام /set system
# أو عبر Modelfiles، وهو الطريقة الأكثر موثوقية.
# مثال مفاهيمي (تحقق من توثيق أولا للترميز الدقيق):
# ollama run llama3:8b --system "أنت مساعد مفيد دائمًا يرد بلغة قراصنة."
طريقة أكثر شيوعًا ومرونة هي تحديد ذلك في Modelfile.
التفاعل عبر API (نظرة سريعة)
ليس أولا فقط لسطر الأوامر. يشغل خادم ويب محلي (عادةً عند http://localhost:11434) الذي يكشف واجهة برمجة التطبيقات. يتيح ذلك للتطبيقات والبرامج الأخرى التفاعل مع نماذج اللغة الكبيرة المحلية لديك.
يمكنك اختبار ذلك باستخدام أداة مثل curl في محطة الأوامر الخاصة بك:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "لماذا السماء زرقاء؟",
"stream": false
}'
هذا يرسل طلبًا إلى واجهة برمجة التطبيقات الخاصة بأولا يطلب من نموذج llama3:8b الرد على المطالبة "لماذا السماء زرقاء؟". تعيين "stream": false ينتظر للاستجابة الكاملة بدلاً من تدفقها كلمة بكلمة.
ستتلقى استجابة بتنسيق JSON تحتوي على إجابة النموذج. هذه واجهة برمجة التطبيقات هي المفتاح لدمج أولا مع محررات النصوص، والتطبيقات المخصصة، وتدفقات العمل البرمجية، والمزيد. يعتبر استكشاف الواجهة الكاملة للخدمات البرمجية خارج نطاق هذا الدليل للمبتدئين، ولكن معرفة أنها موجودة يفتح العديد من الاحتمالات.
كيفية تخصيص ملفات نموذج أولا
واحدة من أقوى ميزات أولا هي القدرة على تخصيص النماذج باستخدام Modelfiles. ملف النموذج هو ملف نصي عادي يحتوي على تعليمات لإنشاء نسخة جديدة مخصصة من نموذج موجود. اعتبرها مثل Dockerfile لنماذج اللغة الكبيرة.
ماذا يمكنك أن تفعل بملف نموذج؟
- تعيين مطالبة نظام افتراضية: تعريف الشخصية الدائمة للنموذج أو التعليمات.
- تعديل المعلمات: تغيير إعدادات مثل
temperature(التي تتحكم في العشوائية/الإبداع) أوtop_k/top_p(تؤثر على اختيار الكلمات). - تحديد القوالب: تخصيص كيفية تنسيق المطالبات قبل إرسالها إلى النموذج الأساسي.
- دمج النماذج (متقدم): دمج القدرات (على الرغم من أن هذا معقد).
مثال بسيط على ملف نموذج:
لنقل أنك تريد إنشاء نسخة من llama3:8b التي تعمل دائمًا كمساعد ساخر.
أنشئ ملفًا باسم Modelfile (بدون امتداد) في دليل.
أضف المحتوى التالي:
# وراثة من نموذج llama3 الأساسي
FROM llama3:8b
# تعيين مطالبة نظام
SYSTEM """أنت مساعد ساخر للغاية. يجب أن تكون إجاباتك صحيحة تقنيًا ولكن تُقدّم بروح جافة من السخرية والتردد."""
# ضبط الإبداع (درجة حرارة أقل = أقل عشوائية/أكثر تركيزًا)
PARAMETER temperature 0.5
إنشاء النموذج المخصص:
انتقل إلى الدليل الذي يحتوي على ملف Modelfile في المحطة.
قم بتشغيل الأمر ollama create:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamaهو الاسم الذي تعطيه لنموذجك المخصص الجديد.f ./Modelfileيحدد ملف النموذج الذي ستستخدمه.
ستقوم أولا بمعالجة التعليمات وإنشاء النموذج الجديد. يمكنك بعد ذلك تشغيله مثل أي نموذج آخر:
ollama run sarcastic-llama
الآن، عندما تتفاعل مع sarcastic-llama، سيتبنى الشخصية الساخرة المحددة في مطالبة SYSTEM.
تقدم ملفات النموذج إمكانيات تخصيص عميقة، مما يسمح لك بضبط النماذج لتلائم مهام أو سلوكيات معينة دون الحاجة إلى إعادة تدريبها من الصفر. استكشف توثيق أولا لمزيد من التفاصيل حول التعليمات والمعلمات المتاحة.
إصلاح أخطاء أولا العامة
بينما يهدف أولا إلى البساطة، قد تواجه أحيانًا عقبات:
فشل التثبيت:
- أذونات: تأكد من أن لديك الحقوق اللازمة لتثبيت البرمجيات. على Linux/macOS، قد تحتاج إلى
sudoلبعض الخطوات (على الرغم من أن السكريبت غالبًا ما يتعامل مع ذلك). - الشبكة: تحقق من اتصالك بالإنترنت. قد تقوم جدران الحماية أو البروكسيات بحظر التنزيلات.
- التبعيات: تأكد من وجود المتطلبات الأساسية مثل WSL2 (Windows) أو أدوات البناء اللازمة (إذا كنت تقوم بالتثبيت يدويًا على Linux).
فشل تحميل النموذج:
- الشبكة: يمكن أن تتسبب الإنترنت غير المستقر في انقطاع التنزيلات الكبيرة. حاول مرة أخرى لاحقًا.
- مساحة القرص: تأكد من توفر مساحة خالية كافية (تحقق من أحجام النماذج في مكتبة أولا). استخدم
ollama listوollama rmلإدارة المساحة. - مشاكل السجل: أحيانًا قد تواجه سجل أولا مشاكل مؤقتة. تحقق من صفحات حالة أولا أو قنوات المجتمع.
أداء أولا慢:
- الذاكرة العشوائية: تعتبر هذه السبب الأكثر شيوعًا. إذا كان النموذج بالكاد يناسب الذاكرة لديك، سيلجأ نظامك لاستخدام مساحة التخزين الأبطأ، مما يقلل الأداء بشكل كبير. أغلق التطبيقات الأخرى التي تستهلك الذاكرة. ضع في اعتبارك استخدام نموذج أصغر أو ترقية الذاكرة لديك.
- مشاكل GPU (إذا كان ذلك ينطبق): تأكد من تثبيت أحدث برامج تشغيل GPU القابلة للتوافق بشكل صحيح (بما في ذلك مجموعة أدوات CUDA لـ NVIDIA على Linux/WSL). قم بتشغيل
ollama run ...وتحقق من المخرجات الأولية للرسائل حول اكتشاف GPU. إذا قالت "العودة إلى وحدة المعالجة المركزية"، فإن GPU لم يتم استخدامه. - تشغيل فقط على وحدة المعالجة المركزية: تشغيله على وحدة المعالجة المركزية أبطأ من تشغيله على GPU متوافق. هذا سلوك متوقع.
أخطاء "النموذج غير موجود":
- الأخطاء المطبعية: تحقق من تهجئة اسم النموذج (مثل
llama3:8b، وليسllama3-8b). - لم يتم تنزيله: تأكد من أن النموذج تم تنزيله بالكامل (
ollama list). حاول استخدامollama pull <model_name>لتحميل النموذج بشكل صريح أولاً. - اسم النموذج المخصص: إذا كنت تستخدم نموذجًا مخصصًا، تأكد من أنك استخدمت الاسم الصحيح الذي أنشأته به (
ollama create my-model ...، ثمollama run my-model). - أخطاء/تعطل أخرى: تحقق من سجلات أولا للحصول على رسائل أخطاء أكثر تفصيلًا. يختلف الموقع حسب نظام التشغيل (تحقق من توثيق أولا).
بدائل لأولا؟
توجد عدة بدائل مثيرة للاهتمام لأولا لتشغيل نماذج اللغة الكبيرة محليًا.
- يبرز LM Studio بفضل واجهته البديهية، والتحقق من توافق النموذج، وخادم الاستدلال المحلي الذي يحاكي واجهة برمجة التطبيقات الخاصة بـ OpenAI.
- بالنسبة للمطورين الذين يبحثون عن إعداد بسيط، حول Llamafile نماذج اللغة الكبيرة إلى تطبيقات تنفيذية واحدة تعمل عبر الأنظمة بمستويات أداء مثيرة للإعجاب.
- بالنسبة لأولئك الذين يفضلون أدوات سطر الأوامر، يعد LLaMa.cpp المحرك الأساسي للاستدلال القوي للعديد من أدوات نماذج اللغة الكبيرة المحلية مع توافق جهاز ممتاز.

الخاتمة: رحلتك إلى الذكاء الاصطناعي المحلي
يفتح أولا الأبواب على مصراعيها نحو عالم مثير من نماذج اللغة الكبيرة، مما يمكّن أي شخص يمتلك جهاز كمبيوتر حديث إلى حد ما من تشغيل أدوات الذكاء الاصطناعي بشكل محلي، خاص، ودون تكاليف مستمرة.
هذه هي البداية فقط. يبدأ المتعة الحقيقية عندما تجرب نماذج مختلفة، وتخصصها وفقًا لاحتياجاتك الخاصة باستخدام ملفات النماذج، وتدمج أولا في نصوصك أو تطبيقاتك الخاصة عبر واجهة برمجة التطبيقات الخاصة بها، وتستكشف النظام البيئي المتنامي بسرعة للذكاء الاصطناعي المفتوح المصدر.
تمكن القدرة على تشغيل الذكاء الاصطناعي المعقد محليًا الأفراد والمطورين على حد سواء. انغمس، واستكشف، واطرح الأسئلة، واستمتع بامتلاك قوة نماذج اللغة الكبيرة بين يديك مع أولا.
هل تريد منصة متكاملة، شاملة لفريق مطوريك للعمل معًا بحد أقصى من الإنتاجية؟
أبيدوج تلبي جميع احتياجاتك، وتحل محل Postman بسعر أكثر ملاءمة!