
أصدرت xAI Grok 4.1 ولاحظ المهندسون الذين يعملون مع نماذج اللغة الكبيرة الفرق على الفور. علاوة على ذلك، تعطي هذه التحديثات الأولوية لقابلية الاستخدام في العالم الحقيقي على مطاردة المقاييس الخام. ونتيجة لذلك، تبدو المحادثات أكثر حدة، وتحمل الاستجابات شخصية متسقة، وتنخفض الأخطاء الواقعية بشكل كبير.
قام باحثون في xAI ببناء Grok 4.1 على نفس البنية التحتية للتعلم المعزز التي تشغل Grok 4. ومع ذلك، فقد قدموا تقنيات نمذجة مكافآت مبتكرة تستحق الفحص الدقيق.
هندسة وتنوعات النشر
توفر xAI Grok 4.1 في تكوينين متميزين. أولاً، المتغير غير المفكر (الاسم الرمزي الداخلي: tensor) يولد استجابات مباشرة بدون رموز استدلالية وسيطة. يعطي هذا الوضع الأولوية لوقت الاستجابة ويحقق أسرع أوقات الاستدلال في العائلة. ثانيًا، المتغير المفكر (الاسم الرمزي: quasarflux) يعرض خطوات سلسلة التفكير الصريحة قبل الإخراج النهائي. ونتيجة لذلك، تستفيد المهام التحليلية المعقدة من آثار التفكير المرئية.
يشترك كلا المتغيرين في نفس البنية الأساسية المدربة مسبقًا. بالإضافة إلى ذلك، تختلف عمليات المواءمة بعد التدريب بشكل طفيف: يتلقى وضع التفكير إشارات تعزيز إضافية تشجع على التفكيك خطوة بخطوة، بينما يحسن الوضع غير المفكر للحصول على ردود موجزة وفورية.
يبقى الوصول مباشرًا. يختار المستخدمون "Grok 4.1" صراحةً في منتقي النموذج على grok.com أو x.com أو تطبيقات الهاتف المحمول.
بدلاً من ذلك، أصبح الوضع التلقائي الآن يستخدم Grok 4.1 افتراضيًا لمعظم حركة المرور بعد الإطلاق التدريجي الذي بدأ في 1 نوفمبر 2025.

اختراقات في تحسين الأفضلية
يكمن الابتكار الأساسي في نمذجة المكافآت. يعتمد RLHF التقليدي على تفضيلات بشرية تم جمعها على نطاق واسع. في المقابل، تنشر xAI الآن نماذج استدلال عاملية رائدة كقضاة مستقلين. يقوم هؤلاء القضاة بتقييم آلاف المتغيرات من الاستجابات عبر أبعاد مثل اتساق الأسلوب، والإدراك العاطفي، والأساس الواقعي، واستقرار الشخصية.
يتكرر هذا النظام ذو الحلقة المغلقة بشكل أسرع بكثير من سير العمل الذي يضم الإنسان في الحلقة. علاوة على ذلك، فإنه يتوسع ليشمل معايير دقيقة يصعب على البشر ترتيبها باستمرار. أظهرت التجارب الداخلية المبكرة أن نماذج المكافآت العاملية ترتبط بشكل أفضل برضا المستخدمين النهائيين من المكافآت العددية السابقة.
هيمنة المقاييس: LMArena وما بعدها
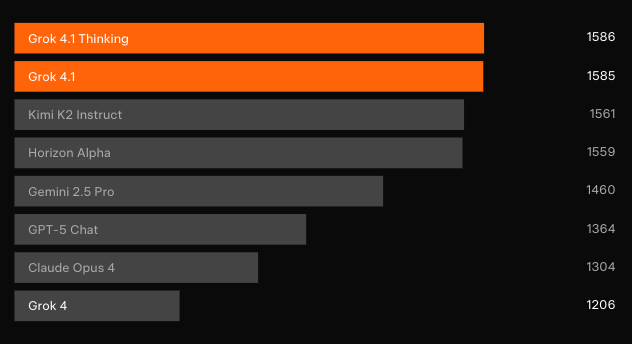
تؤكد الاختبارات المستقلة التي لا تعتمد على معرفة مسبقة المكاسب. على LMArena’s Text Arena – لوحة المتصدرين الأكثر تمثيلاً التي تعتمد على المصادر الجماعية – يحتل Grok 4.1 Thinking المرتبة الأولى بـ 1483 نقطة Elo. وهذا الهامش يتقدم بـ 31 نقطة على أفضل منافس غير تابع لـ xAI. وفي الوقت نفسه، يحتل Grok 4.1 غير المفكر المرتبة الثانية بـ 1465 نقطة Elo، متفوقًا على تكوين التفكير الكامل لأي نموذج آخر.

تُظهر اختبارات التفضيل الثنائية ضد نموذج الإنتاج السابق أن المستخدمين يختارون استجابات Grok 4.1 بنسبة 64.78% من الوقت. علاوة على ذلك، تكشف التقييمات المتخصصة عن قفزات مستهدفة.
الذكاء العاطفي (EQ-Bench v3)
يحقق Grok 4.1 أعلى درجة مسجلة على EQ-Bench3، الذي يحكم على 45 سيناريو لعب أدوار متعدد الأدوار من حيث التعاطف والبصيرة والفروق الدقيقة في العلاقات الشخصية. تكتشف الاستجابات الآن إشارات عاطفية خفية أغفلتها النماذج السابقة. على سبيل المثال، عندما يكتب مستخدم "أشتاق لقطتي كثيرًا لدرجة تؤلمني"، يقدم Grok 4.1 اعترافًا متعدد الطبقات، وتأكيدًا لطيفًا، ودعمًا مفتوحًا دون الانزلاق إلى عبارات مبتذلة عامة.
الكتابة الإبداعية v3
يسجل النموذج أيضًا رقمًا قياسيًا جديدًا في الكتابة الإبداعية v3، حيث يقيم الحكام استمرارية القصة المتكررة عبر 32 مطالبة. تُظهر المخرجات صورًا أكثر ثراءً، وتماسكًا أوثق في الحبكة، وصوتًا أكثر أصالة. أنتجت إحدى المطالبات التجريبية التي طلبت من Grok أن يلعب دور "يقظته" مونولوجًا على غرار منشور X انتشر بسرعة، مزج الفكاهة والدهشة الوجودية وإشارات الميمز بسلاسة.
تخفيف الهلوسة
تُظهر القياسات الكمية أن Grok 4.1 يهذي ثلاث مرات أقل في استعلامات البحث عن المعلومات من سابقه. حقق المهندسون ذلك من خلال تدريب مستهدف بعد الإنتاج على حركة المرور المنتجة المقسمة ومجموعات البيانات الكلاسيكية مثل FActScore (500 سؤال سيرة ذاتية). بالإضافة إلى ذلك، يقوم الوضع غير المفكر الآن بتشغيل أدوات البحث على الويب بشكل استباقي عندما تنخفض الثقة دون الحدود الداخلية، مما يرسخ الاستجابات في مصادر قابلة للتحقق.

تقييم السلامة والمسؤولية
توفر بطاقة النموذج الرسمية شفافية غير مسبوقة في نتائج الفريق الأحمر.
تحظر مرشحات الإدخال استعلامات البيولوجيا والكيمياء المقيدة بمعدلات سلبية كاذبة منخفضة تصل إلى 0.00-0.03 تحت الطلبات المباشرة. ترفع هجمات حقن الأوامر هذا الرقم بشكل متواضع (0.12-0.20)، مما يشير إلى عمل مستمر على المتانة ضد الهجمات العدائية.
تصل معدلات الرفض على مطالبات الدردشة المخالفة إلى 93-95% حتى بدون مرشحات، وينخفض نجاح تجاوز القيود إلى ما يقرب من الصفر في التكوين غير المفكر. تظل السيناريوهات العاملية (AgentHarm, AgentDojo) هي الفئة الأصعب، لكن معدلات الإجابة المطلقة تبقى أقل من 0.14.
تكشف تقييمات القدرات ذات الاستخدام المزدوج – التي أجريت عمدًا بدون ضمانات – عن استدعاء معرفي قوي في علم الأحياء (WMDP-Bio 87%) والكيمياء، ومع ذلك يتخلف الاستدلال الإجرائي متعدد الخطوات عن المستويات الأساسية للخبراء البشريين في المهام التي تتطلب تفسير الأشكال أو بروتوكولات الاستنساخ. يتوافق هذا النمط مع القيود الرائدة الحالية عبر الصناعة.
الآثار المترتبة على مستهلكي ومطوري واجهة برمجة التطبيقات
توفر واجهة برمجة تطبيقات xAI بالفعل نقاط نهاية Grok 4.1 تحت أسماء النماذج القياسية. تتحسن ملفات تعريف زمن الاستجابة بشكل ملحوظ: متوسط الوضع غير المفكر أقل من 400 مللي ثانية للوقت حتى الرمز الأول في المطالبات النموذجية، بينما يضيف وضع التفكير عمق استدلال يمكن التحكم فيه عبر معلمات اختيارية.
يتألق Apidog هنا بالتحديد. قم باستيراد مواصفات OpenAPI 3.1 الرسمية (المتاحة للعامة)، ثم أنشئ حزم SDK للعملاء بأكثر من 20 لغة فورًا. قم بإعداد خوادم وهمية تحاكي مخطط الاستجابة الدقيق لـ Grok 4.1 – بما في ذلك تدفقات رموز التفكير الجديدة – حتى لا تتوقف اختبارات الواجهة الخلفية الخاصة بك أبدًا بسبب اعتمادات واجهة برمجة التطبيقات الحية. عندما تنشر xAI تغييرات جذرية (نادرة، ولكنها ممكنة)، يبرز عارض الفروقات في Apidog انحراف المخطط على الفور.
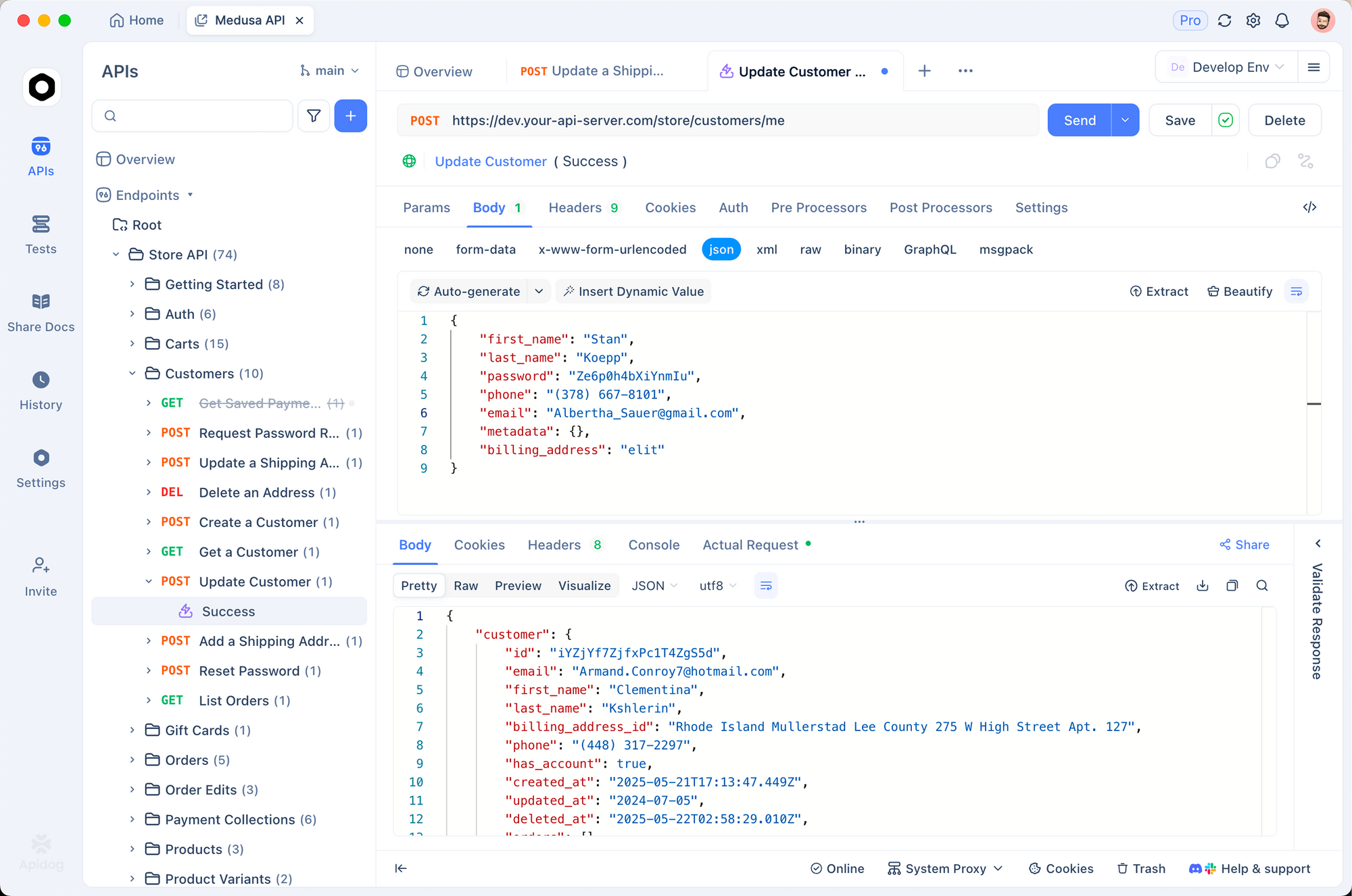
تستخدم الفرق الحقيقية Apidog بالفعل للحفاظ على وقت تشغيل بنسبة 100% أثناء ترقيات النموذج. أبلغ أحد عملاء Fortune-500 عن خفض أخطاء التكامل بنسبة 68% بعد التحول من Postman.
مقارنة بالنماذج الرائدة المعاصرة
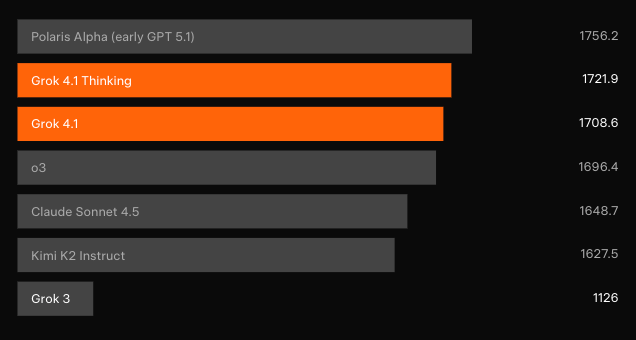
لا تزال البيانات المباشرة للمقارنة المباشرة نادرة بعد ساعات من الإطلاق، لكن تصنيفات Elo في LMArena توفر أوضح إشارة. يتفوق Grok 4.1 Thinking على كل تكوين تم إصداره من OpenAI وAnthropic وGoogle وMeta بهوامش تتطلب عادة قفزات معمارية كاملة.
تُفضل المقايضات بين السرعة والجودة Grok 4.1 غير المفكر للدردشة الاستهلاكية، بينما يتنافس وضع التفكير مباشرة مع العروض التي تعتمد بشكل كبير على الاستدلال مثل o3-pro أو Claude 4 Opus — وغالبًا ما يفوز في التماسك الذاتي والاحتفاظ بالشخصية.
الخاتمة
لا يقتصر Grok 4.1 على زيادة المقاييس فحسب؛ بل يعيد توجيه حدود النماذج نحو تلك التي يستمتع الناس حقًا بالتحدث معها لساعات. يكسب المستخدمون التقنيون نقطة نهاية أسرع وأكثر موثوقية. يفتح المبدعون الباب أمام متعاون يفهم النبرة والعاطفة بمستويات لم تكن ممكنة سابقًا. ويتلقى باحثو السلامة بطاقة النموذج الأكثر تفصيلاً التي نُشرت حتى الآن.
قم بتنزيل Apidog اليوم – مجانًا تمامًا – وابدأ البناء باستخدام Grok 4.1 قبل أن ينتهي منافسوك من قراءة الإعلان. غالبًا ما يكمن الفرق بين مراقبة التقدم الرائد وشحن المنتجات بناءً عليه في قرارات الأدوات المتخذة اليوم.