
يبحث المطورون باستمرار عن طرق فعالة لدمج نماذج الذكاء الاصطناعي المتقدمة في التطبيقات. يوفر Gemini 3 Flash API خيارًا قويًا يوازن بين الذكاء العالي والسرعة وفعالية التكلفة.
تواصل Google تطوير عروضها من الذكاء الاصطناعي التوليدي. بالإضافة إلى ذلك، يبرز نموذج Gemini 3 Flash في التشكيلة الحالية. يصل المهندسون إليه من خلال Gemini API، مما يتيح النماذج الأولية السريعة والنشر في بيئة الإنتاج.
الحصول على مفتاح Gemini API الخاص بك
تبدأ بالحصول على مفتاح API. أولاً، انتقل إلى Google AI Studio على aistudio.google.com. سجّل الدخول باستخدام حساب Google الخاص بك إذا لزم الأمر. بعد ذلك، حدد نموذج معاينة Gemini 3 Flash من الخيارات المتاحة. ثم، انقر فوق خيار إنشاء مفتاح API.
توفر Google هذا المفتاح على الفور. علاوة على ذلك، قم بتخزينه بشكل آمن—تعامل معه كبيانات اعتماد حساسة. تستخدمه في ترويسة x-goog-api-key لجميع الطلبات. بدلاً من ذلك، عيّنه كمتغير بيئة لسهولة الاستخدام في البرامج النصية.
بدون مفتاح صالح، تفشل الطلبات فورًا مع أخطاء المصادقة. لذلك، تحقق من وظيفة المفتاح مبكرًا عن طريق الاختبار في واجهة Google AI Studio التفاعلية.
فهم قدرات Gemini 3 Flash
يقدم Gemini 3 Flash ذكاءً بمستوى احترافي بسرعات فائقة. على وجه التحديد، يظل معرف النموذج هو gemini-3-flash-preview خلال مرحلة المعاينة. وهو يدعم نافذة سياق إدخال ضخمة تبلغ 1,048,576 رمزًا وحد إخراج 65,536 رمزًا.
علاوة على ذلك، يتعامل بفعالية مع المدخلات متعددة الوسائط. يمكنك تزويده بالنصوص والصور ومقاطع الفيديو والصوت وملفات PDF. تتكون المخرجات بشكل أساسي من نصوص، مع خيارات لـ JSON منظم عبر فرض المخطط.
تشمل الميزات الرئيسية التحكم المدمج في الاستدلال. يقوم المطورون بتعديل عمق التفكير باستخدام المعامل thinking_level: (minimal) أدنى، (low) منخفض، (medium) متوسط، أو (high) عالٍ (افتراضي). يعمل المستوى العالي على زيادة جودة الاستدلال، بينما تعطي المستويات الأدنى الأولوية لزمن الوصول للحالات ذات الإنتاجية العالية.
بالإضافة إلى ذلك، يمكن التحكم في دقة الوسائط لمهام الرؤية. تتراوح الخيارات من (low) منخفضة إلى (ultra_high) فائقة الارتفاع، مما يؤثر على استهلاك الرموز لكل إطار أو صورة. اختر ما يناسبك—عالية للصور التفصيلية، ومتوسطة للمستندات.
يدمج النموذج أدوات مثل ربط نتائج بحث Google، وتنفيذ التعليمات البرمجية، واستدعاء الوظائف. ومع ذلك، فإنه يستبعد توليد الصور وبعض أدوات الروبوتات المتقدمة.
تسعير Gemini 3 Flash API
تعد إدارة التكاليف مهمة في عمليات دمج واجهة برمجة التطبيقات. يعمل Gemini 3 Flash بنموذج الدفع حسب الاستخدام. تكلف رموز الإدخال 0.50 دولار لكل مليون، بينما تكلف رموز الإخراج (بما في ذلك رموز التفكير) 3 دولارات لكل مليون.
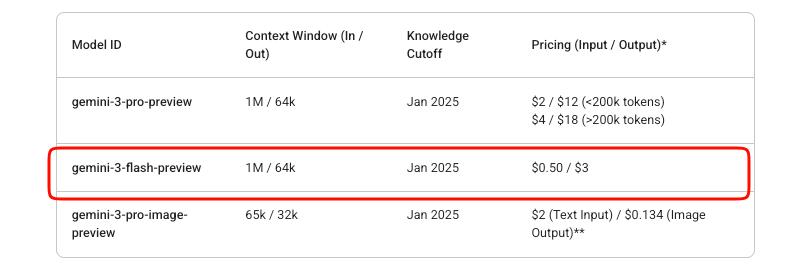
تقدم Google تجربة مجانية في AI Studio. ومع ذلك، فإن استخدام API في الإنتاج يتكبد رسومًا بمجرد تمكين الفواتير. لا يوجد مستوى مجاني يتجاوز تجارب Studio لهذا النموذج التجريبي.
يساعد التخزين المؤقت للسياق ومعالجة الدُفعات في تحسين التكاليف بشكل أكبر. يقلل التخزين المؤقت من معالجة الرموز المتكررة للسياقات المتكررة. تناسب Batch API الوظائف غير المتزامنة ذات الحجم الكبير.
راقب الاستخدام عبر لوحات معلومات الفواتير في Google Cloud. غالبًا ما تنبع الارتفاعات المفاجئة من إعدادات media_resolution العالية أو الاستدلال المكثف.
إجراء طلب API الأول الخاص بك
تبدأ بتوليد نص بسيط. نقطة النهاية هي https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
قم بإنشاء طلب POST. قم بتضمين مفتاح API الخاص بك في الرؤوس. يحتوي الجسم على محتويات كصفيف من كائنات الأجزاء المتعلقة بالدور.
هذا مثال أساسي لـ cURL:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
تعيد الاستجابة المرشحات مع الأجزاء النصية. بالإضافة إلى ذلك، تعامل مع بيانات التعريف الخاصة بالاستخدام لعدد الرموز.
بالنسبة للاستجابات المتدفقة، استخدم نقطة النهاية :streamGenerateContent. ينتج هذا نتائج جزئية بشكل تدريجي، مما يحسن زمن الاستجابة المتصور في التطبيقات.
الدمج مع حزم SDK الرسمية
تحافظ Google على حزم SDK التي تبسط التفاعلات. قم بتثبيت حزمة Python عبر pip install google-generativeai.
تهيئة العميل:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
تدير حزمة SDK توقيعات التفكير تلقائيًا للمحادثات متعددة الأدوار واستخدام الأدوات. وبالتالي، يُفضل استخدام حزم SDK على HTTP الخام لرمز الإنتاج.
يستفيد مستخدمو Node.js من راحة مماثلة عبر @google/generative-ai.
التعامل مع المدخلات متعددة الوسائط
يتفوق Gemini 3 Flash في معالجة الوسائط المتعددة. قم بتحميل الملفات أو توفير معرفات URI للبيانات المضمنة.
في بايثون:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
اضبط media_resolution في إعدادات التوليد لكفاءة الرموز:
generation_config = {
"media_resolution": "media_resolution_high"
}
تتبع مقاطع الفيديو وملفات PDF أنماطًا مماثلة. علاوة على ذلك، اجمع وسائط متعددة في طلب واحد لمهام التحليل المعقدة.
ميزات متقدمة: مستويات التفكير والأدوات
تحكم في الاستدلال بشكل صريح. عيّن thinking_level إلى "low" للحصول على استجابات سريعة:
"generationConfig": {
"thinking_level": "low"
}
يمكّن التفكير عالي المستوى معالجة أعمق لسلسلة الأفكار داخليًا.
تمكين أدوات مثل استدعاء الوظائف. حدد الوظائف في الطلب؛ يقوم النموذج بإرجاع الاستدعاءات عند الاقتضاء.
تفرض المخرجات المنظمة مخططات JSON:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
اجمع هذه الميزات لسير العمل الوكالي. على سبيل المثال، استند في الاستجابات إلى البحث في الوقت الفعلي.
الاختبار وتصحيح الأخطاء باستخدام Apidog
يضمن الاختبار الفعال تكاملات موثوقة. يظهر Apidog كأداة قوية لهذا الغرض. فهو يجمع بين تصميم API وتصحيح الأخطاء والمحاكاة والاختبار الآلي في منصة واحدة.
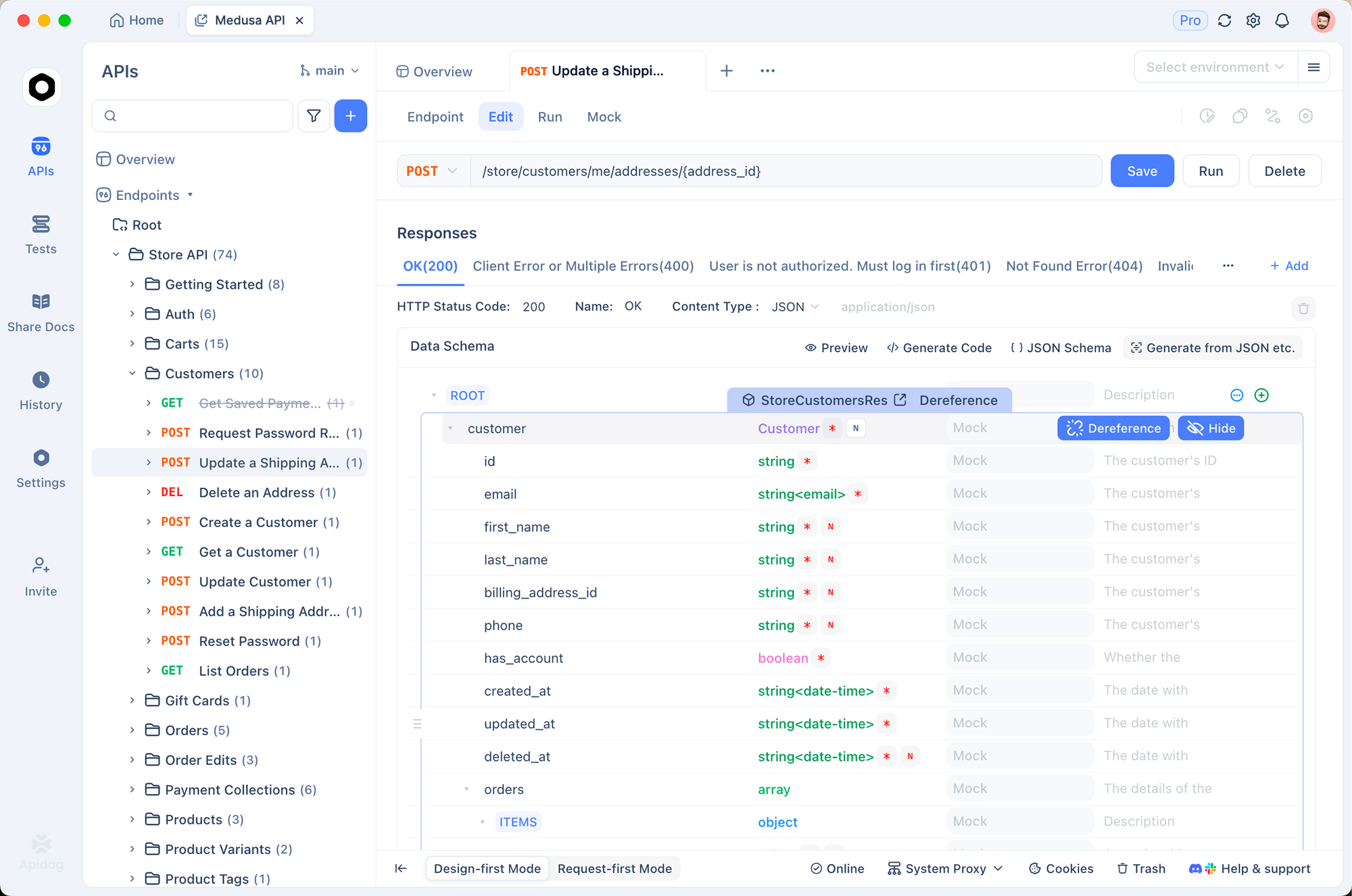
أولاً، استورد نقطة نهاية Gemini إلى Apidog. أنشئ طلبًا جديدًا يشير إلى طريقة generateContent. قم بتخزين مفتاح API الخاص بك كمتغير بيئة—يدعم Apidog بيئات متعددة للتطوير والتحضير والإنتاج.
أرسل الطلبات بصريًا. يعرض Apidog الاستجابات بوضوح، ويسلط الضوء على استخدام الرموز والأخطاء. بالإضافة إلى ذلك، قم بإعداد تأكيدات للتحقق من صحة هياكل الاستجابة تلقائيًا.
للمحادثات متعددة الأدوار، حافظ على سجل المحادثة عبر الطلبات باستخدام البرمجة النصية أو المتغيرات في Apidog. يحاكي هذا جلسات المستخدم الحقيقية بكفاءة.
ينشئ Apidog أيضًا خوادم وهمية. قم بمحاكاة استجابات Gemini أثناء تطوير الواجهة الأمامية دون استهلاك الحصص.
علاوة على ذلك، قم بأتمتة مجموعات الاختبار. حدد سيناريوهات تغطي مستويات تفكير مختلفة، ومدخلات متعددة الوسائط، وحالات الأخطاء. قم بتشغيلها في خطوط أنابيب CI/CD.
يجد العديد من المطورين أن Apidog يقلل وقت تصحيح الأخطاء بشكل كبير مقارنة بـ cURL الخام أو العملاء الأساسيين. تتعامل واجهته البديهية مع هياكل JSON المعقدة بسهولة.
أفضل الممارسات للاستخدام في بيئة الإنتاج
طبق منطق إعادة المحاولة مع التراجع الأسي. تنطبق حدود المعدل، خاصة في مرحلة المعاينة.
خزّن السياقات مؤقتًا حيثما أمكن لتقليل الرموز. استخدم توقيعات التفكير بدقة في الطلبات الخام لتجنب أخطاء التحقق.
راقب التكاليف بشكل استباقي. سجل عدد رموز الإدخال/الإخراج لكل طلب.
حافظ على درجة الحرارة عند الافتراضي 1.0—الانحرافات تقلل من أداء الاستدلال.
أخيرًا، ابقَ على اطلاع عبر الوثائق الرسمية. تتطور نماذج المعاينة؛ خطط للتغييرات الجذرية المحتملة.
الخاتمة
أنت الآن تمتلك المعرفة لدمج Gemini 3 Flash بفعالية. ابدأ بالطلبات البسيطة، ثم توسع إلى تطبيقات متعددة الوسائط ومعززة بالأدوات. استفد من أدوات مثل Apidog لتبسيط سير عمل التطوير.
يمكّن Gemini 3 Flash المطورين من إنشاء أنظمة ذكية وسريعة الاستجابة بتكلفة معقولة. جرب بحرية في AI Studio، ثم انتقل إلى API للنشر.