
يسعى المطورون والباحثون باستمرار لإيجاد طرق لربط البيانات المرئية بالمعالجة النصية في الذكاء الاصطناعي. تتصدى DeepSeek-AI لهذا التحدي من خلال DeepSeek-OCR، وهو نموذج يركز على الضغط البصري للسياقات. تم إصدار هذه الأداة في 20 أكتوبر 2025، وهي تفحص مُشفّرات الرؤية من منظور يركز على نماذج اللغة الكبيرة (LLM) وتدفع حدود ضغط المعلومات المرئية إلى سياقات نصية. يدمج المهندسون مثل هذه النماذج للتعامل بكفاءة مع المهام المعقدة مثل تحويل المستندات ووصف الصور.
يشير الضغط البصري للسياقات إلى العملية التي تقوم فيها مُشفّرات الرؤية بتكثيف بيانات الصورة إلى تمثيلات نصية مدمجة يمكن لنماذج اللغة الكبيرة (LLMs) معالجتها بفعالية. تستخرج أنظمة التعرف الضوئي على الحروف (OCR) التقليدية النص ولكنها غالبًا ما تتجاهل الفروق الدقيقة السياقية، مثل التخطيطات أو العلاقات المكانية. يتغلب DeepSeek-OCR على هذه القيود من خلال التركيز على الضغط الذي يحافظ على التفاصيل الأساسية. يدعم النموذج أوضاع دقة متعددة، مما يتيح المرونة في التعامل مع أحجام الصور المختلفة. علاوة على ذلك، فإنه يدمج قدرات التحديد المكاني للإشارة الدقيقة إلى المواقع داخل الصور.
صمم باحثون في DeepSeek-AI هذا النموذج للتحقيق في كيفية مساهمة مُشفّرات الرؤية في كفاءة نماذج اللغة الكبيرة (LLM). من خلال ضغط المدخلات المرئية إلى عدد أقل من الرموز، يقلل النظام من الحمل الحسابي مع الحفاظ على الدقة. يثبت هذا النهج فائدته بشكل خاص في السيناريوهات التي تتطلب فيها الصور عالية الدقة موارد كبيرة. على سبيل المثال، تتطلب معالجة صورة بحجم 1280×1280 عادةً ذاكرة واسعة، لكن وضع DeepSeek-OCR الكبير يتعامل معها باستخدام 400 رمز بصري فقط.
يعمل مستودع GitHub الخاص بالمشروع كمصدر أساسي للنموذج ووثائقه. يمكن للمستخدمين الوصول إلى أوزان النموذج عبر Hugging Face، مما يسهل التكامل السهل في خطوط العمل الحالية. مع تطور الذكاء الاصطناعي، تسلط نماذج مثل DeepSeek-OCR الضوء على أهمية ضغط البيانات الفعال. يمثل الانتقال من استخراج النص الأساسي إلى المعالجة الواعية بالسياق تقدمًا كبيرًا. ونتيجة لذلك، يحقق المطورون نتائج أفضل في المهام التي تتراوح من أتمتة المستندات إلى الإجابة على الأسئلة المرئية.
أساسيات الضغط البصري للسياقات
يبرز الضغط البصري للسياقات كتقنية حاسمة في الذكاء الاصطناعي الحديث. تلتقط أنظمة الرؤية الصور، لكن نماذج اللغة الكبيرة (LLMs) تتطلب مدخلات نصية. لذلك، تقوم المُشفّرات بضغط بيانات البكسل إلى رموز تنقل المعنى دون فقدان المعلومات الأساسية. يجسد DeepSeek-OCR ذلك من خلال التركيز على تصميم يركز على نماذج اللغة الكبيرة (LLM). على عكس الطرق التقليدية التي تعطي الأولوية للدقة على مستوى البكسل، يعمل هذا النموذج على تحسين كفاءة الرموز.
يتضمن الضغط النشط عدة خطوات. أولاً، يحلل المُشفّر الصورة بدقتها الأصلية. ثم يحدد العناصر النصية والتخطيطات والأشكال. بعد ذلك، يولد تمثيلات مضغوطة. تضمن هذه العملية أن نماذج اللغة الكبيرة (LLMs) تفسر السياقات المرئية بدقة. على سبيل المثال، في المستند، يميز النموذج العناوين عن نص المتن ويحافظ على الهياكل الهرمية.
علاوة على ذلك، يقلل الضغط من زمن الاستجابة في التطبيقات في الوقت الفعلي. تعالج الأنظمة عددًا أقل من الرموز، مما يؤدي إلى أوقات استدلال أسرع. يجمع وضع الدقة الديناميكي في DeepSeek-OCR، المسمى "Gundam"، بين أجزاء صور متعددة للتحليل الشامل. يتكيف هذا الوضع مع كثافات المحتوى المتغيرة، مثل النص الكثيف أو الرسوم البيانية المتفرقة.

تشمل التحديات التقنية في الضغط الموازنة بين الاحتفاظ بالتفاصيل وتقليل الرموز. يؤدي الضغط المفرط إلى خطر فقدان الفروق الدقيقة، بينما يزيد الضغط الناقص التكاليف. يعالج DeepSeek-OCR هذا من خلال أوضاع قابلة للتطوير: صغير جدًا (512×512، 64 رمزًا)، صغير (640×640، 100 رمز)، أساسي (1024×1024، 256 رمزًا)، وكبير (1280×1280، 400 رمز). يناسب كل وضع حالات استخدام محددة، من المعاينات السريعة إلى الاستخراجات التفصيلية.
علاوة على ذلك، يدمج النموذج علامات تحديد الموقع (grounding tags) للوعي المكاني. يحدد المستخدمون مراجع مثل "<|ref|>xxxx<|/ref|>" لتحديد موقع العناصر بدقة. تعزز هذه الميزة التطبيقات في الواقع المعزز أو المستندات التفاعلية. ونتيجة لذلك، لا يقتصر DeepSeek-OCR على ضغط البيانات فحسب، بل يثريها أيضًا بالبيانات الوصفية السياقية.
بالمقارنة مع تقنيات التعرف الضوئي على الحروف (OCR) السابقة، مثل Tesseract، يستفيد DeepSeek-OCR من التعلم العميق لتحقيق دقة فائقة. تعتمد الأنظمة التقليدية على أنماط قائمة على القواعد، بينما يستخدم هذا النموذج شبكات عصبية مدربة على مجموعات بيانات متنوعة. وبالتالي، فإنه يتعامل مع النصوص المكتوبة بخط اليد، والصور المشوهة، والمحتوى متعدد اللغات بفعالية أكبر.
بالانتقال إلى التطبيقات العملية، يتيح فهم هذه الأساسيات للمطورين تقدير ابتكارات النموذج. يتعمق القسم التالي في الميزات المحددة التي تجعل DeepSeek-OCR متميزًا.
الميزات الرئيسية لـ DeepSeek-OCR
يقدم DeepSeek-OCR مجموعة قوية من الميزات التي تلبي احتياجات التعرف الضوئي على الحروف (OCR) المتقدمة. يدعم النموذج أوضاع الدقة الأصلية، مما يسمح للمستخدمين باختيار المقياس المناسب لمهامهم. على سبيل المثال، يعالج الوضع الصغير جدًا صورًا بحجم 512×512 باستخدام 64 رمزًا بصريًا فقط، وهو مثالي للبيئات ذات الموارد المنخفضة.
بالإضافة إلى ذلك، يجمع وضع "Gundam" الديناميكي بين مقاطع بحجم n×640×640 مع نظرة عامة بحجم 1024×1024. يتيح هذا النهج التعامل مع المستندات عالية الدقة للغاية دون إرباك النظام. يستفيد المستخدمون من هذه المرونة عند التعامل مع الكتب الممسوحة ضوئيًا أو المخططات المعمارية.
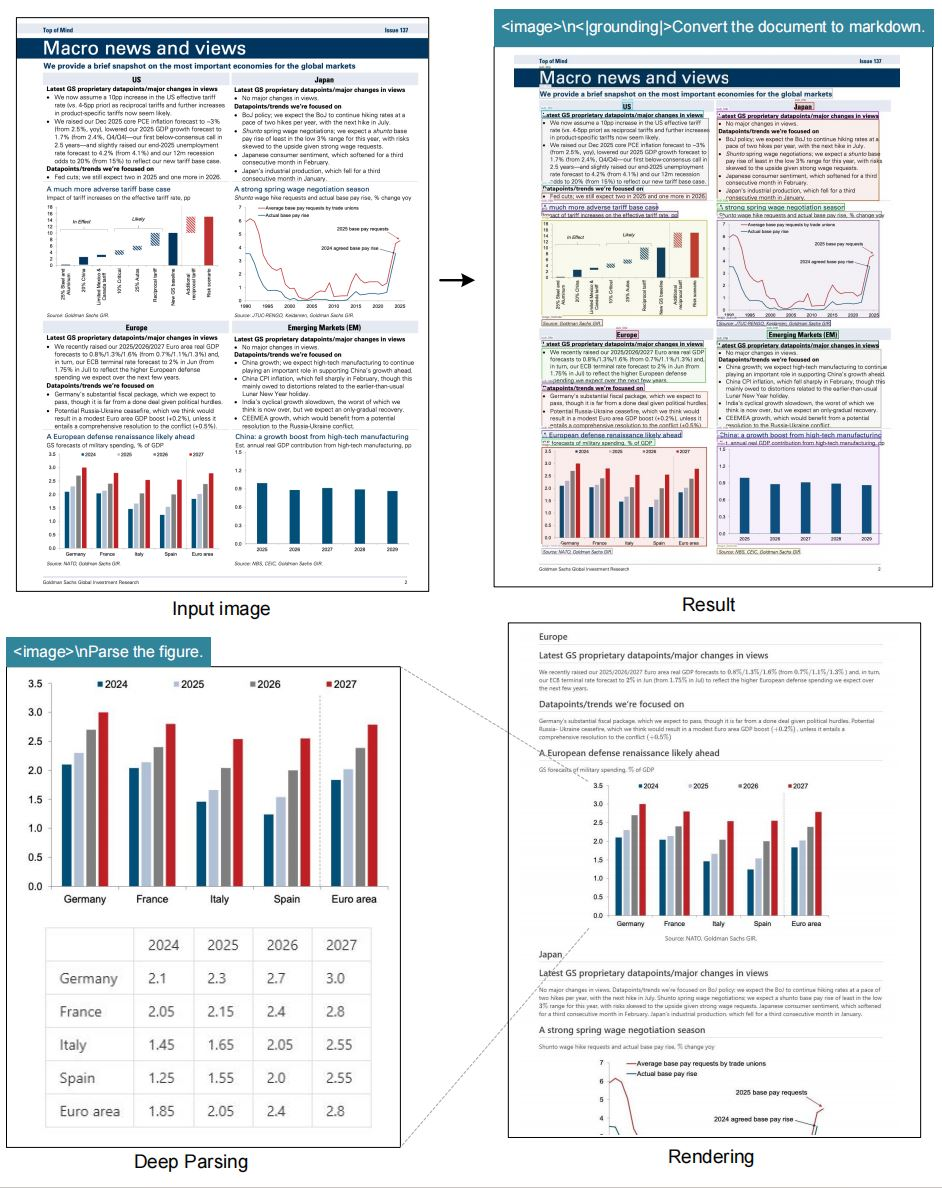
يتفوق النموذج في مهام التعرف الضوئي على الحروف (OCR)، حيث يحول الصور إلى نص بدقة عالية. كما يقوم بتحويل المستندات إلى تنسيق Markdown، مع الحفاظ على الهياكل مثل الجداول والقوائم. علاوة على ذلك، فإنه يحلل الأشكال، ويستخرج الأوصاف ونقاط البيانات من الرسوم البيانية أو المخططات.
يشكل الوصف العام للصور ميزة أساسية أخرى. يولد النموذج تعليقات توضيحية مفصلة، مفيدة لأدوات الوصول أو فهرسة المحتوى. تضيف الإشارة إلى المواقع قيمة من خلال السماح بالاستعلامات حول عناصر محددة داخل الصور.
يتكامل DeepSeek-OCR بسلاسة مع أطر عمل مثل vLLM و Transformers. يسرع هذا التوافق الاستدلال، حيث تصل معالجة ملفات PDF إلى حوالي 2500 رمز في الثانية على وحدات معالجة الرسوميات (GPUs) عالية الأداء مثل A100-40G.
توجه اعتبارات الأمان والكفاءة مجموعة الميزات. يتجنب النموذج التبعيات غير الضرورية، ويركز على المكتبات الأساسية. ونتيجة لذلك، تظل عمليات النشر خفيفة الوزن وقابلة للتطوير.
تضع هذه الميزات DeepSeek-OCR كأداة متعددة الاستخدامات لممارسي الذكاء الاصطناعي. للمضي قدمًا، يشرح قسم البنية كيفية تضافر هذه الإمكانيات.
بنية DeepSeek-OCR: تفصيل تقني
يقوم مهندسو DeepSeek-AI بتصميم بنية DeepSeek-OCR حول مُشفّر رؤية يركز على نماذج اللغة الكبيرة (LLM). يضغط النظام المدخلات المرئية إلى رموز نصية تهضمها نماذج اللغة الكبيرة بكفاءة. في جوهره، يستخدم المُشفّر طبقات التفافية لاستخراج الميزات من الصور.
تبدأ العملية بالمعالجة المسبقة للصور. يغير النموذج حجم المدخلات إلى الدقة المختارة ويطبق التطبيع. ثم، يقسم محول الرؤية الصورة إلى رقع، ويقوم بترميز كل منها إلى تضمينات.
تخضع هذه التضمينات للضغط من خلال آليات الانتباه. يلتقط الانتباه متعدد الرؤوس التبعيات بين العناصر المرئية، مثل محاذاة النص أو حدود الأشكال. تعمل تسوية الطبقات والشبكات العصبية الأمامية على تحسين التمثيلات.

يتم التكامل مع نموذج اللغة الكبيرة (LLM) عبر ربط الرموز. يتم إلحاق رموز الرؤية المضغوطة بموجهات النص، مما يتيح المعالجة الموحدة. يقلل هذا التصميم من طول السياق، مما يقلل من استخدام الذاكرة.
للتحديد المكاني، تقوم الرموز الخاصة مثل <|grounding|> بتنشيط الوحدات المكانية. تقوم هذه الوحدات بربط الاستعلامات بإحداثيات الصورة، باستخدام مربعات الإحاطة أو خرائط الحرارة.
يتضمن التدريب الضبط الدقيق على مجموعات بيانات تحتوي على صور ونصوص مقترنة. تعمل دوال الخسارة على تحسين كل من نسبة الضغط ودقة إعادة البناء. يتعلم النموذج إعطاء الأولوية للميزات البارزة، والتخلص من البكسلات الزائدة عن الحاجة.
من حيث المعلمات، يوازن DeepSeek-OCR بين الحجم والأداء. بينما تظل الأعداد المحددة غير معلنة، يشير مستودع Hugging Face إلى تحجيم فعال عبر الأوضاع.
تشمل التحديات في البنية التعامل مع الدقة المتغيرة. يعالج الوضع الديناميكي هذا عن طريق ربط التضمينات من تمريرات متعددة. وبالتالي، يحافظ النظام على الاتساق عبر المقاييس.

تمكن هذه البنية DeepSeek-OCR من التفوق على النماذج التقليدية في مهام الضغط. يرشد القسم التالي المستخدمين خلال التثبيت، مما يضمن قدرتهم على تكرار الإعداد.
دليل تثبيت DeepSeek-OCR
يتطلب إعداد DeepSeek-OCR بيئة متوافقة. يبدأ المستخدمون بالتأكد من توفر CUDA 11.8 و Torch 2.6.0. تبدأ العملية باستنساخ المستودع من GitHub.
نفذ الأمر: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. انتقل إلى مجلد DeepSeek-OCR.
بعد ذلك، أنشئ بيئة Conda: conda create -n deepseek-ocr python=3.12.9 -y. قم بتنشيطها باستخدام conda activate deepseek-ocr.
ثبت Torch والحزم ذات الصلة: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
قم بتنزيل ملف vLLM-0.8.5 wheel من الإصدار المحدد. ثبته: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
ثم، ثبت المتطلبات: pip install -r requirements.txt. أخيرًا، أضف flash-attention: pip install flash-attn==2.7.3 --no-build-isolation.
لاحظ أن دمج vLLM و Transformers قد يؤدي إلى ظهور أخطاء، لكن المستخدمين يتجاهلونها وفقًا للوثائق.
يهيئ هذا الإعداد النظام للاستدلال. مع جاهزية البيئة، ينتقل المستخدمون إلى أمثلة الاستخدام.
مقاييس الأداء وتقييمات المعايير
يحقق DeepSeek-OCR سرعات مبهرة. على وحدة معالجة رسوميات (GPU) من نوع A100-40G، تصل معالجة ملفات PDF المتزامنة إلى 2500 رمز في الثانية. يسلط هذا المقياس الضوء على ملاءمته للمهام واسعة النطاق.
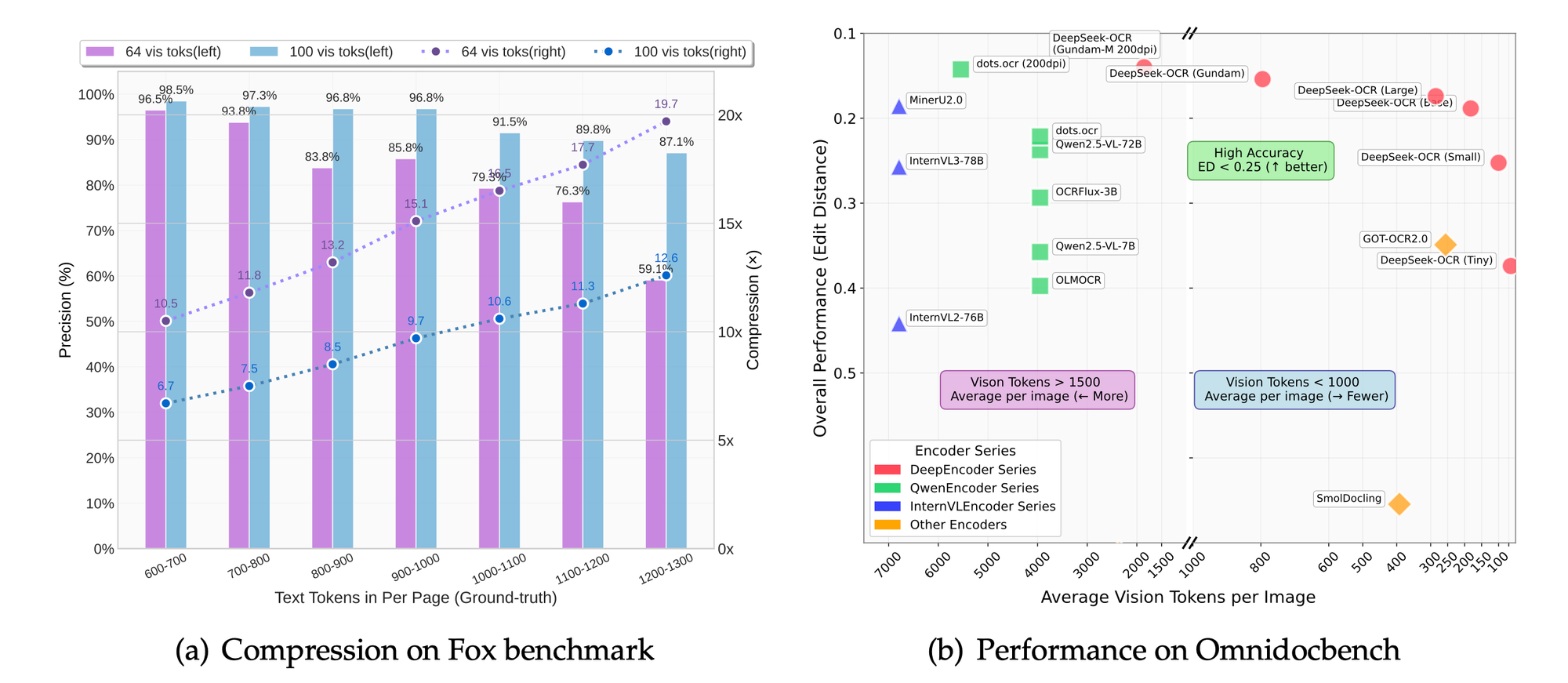
تقوم معايير مثل Fox و OmniDocBench بتقييم الدقة. يتفوق النموذج في دقة التعرف الضوئي على الحروف (OCR)، والحفاظ على التخطيط، وتحليل الأشكال. تظهر المقارنات نسب ضغط فائقة مقارنة بالأسس.
في أوضاع الدقة، تؤدي الإعدادات الأعلى إلى احتفاظ أفضل بالتفاصيل على حساب الرموز. يوازن الوضع الأساسي بين السرعة والجودة لمعظم التطبيقات.
تؤكد دراسات الاستئصال، المستنبطة من تركيز المشروع، فوائد النهج الذي يركز على نماذج اللغة الكبيرة (LLM). يؤدي تقليل الرموز بنسبة 50% إلى الحفاظ على دقة 95% في استخراج النص.
تتحقق هذه المقاييس من تصميم DeepSeek-OCR. تستفيد التطبيقات من هذا الأداء لتحقيق تأثير في العالم الحقيقي.
مقارنات مع نماذج OCR أخرى
يتفوق DeepSeek-OCR على PaddleOCR في كفاءة الضغط. بينما يركز PaddleOCR على السرعة، يشدد DeepSeek على تقليل الرموز لنماذج اللغة الكبيرة (LLMs).
يقدم GOT-OCR2.0 تحليلًا مشابهًا ولكنه يفتقر إلى الأوضاع الديناميكية. يتعامل Gundam الخاص بـ DeepSeek مع المستندات الأكبر بشكل أفضل.
يتفوق MinerU في التنقيب ولكنه لا يتفوق في التحديد المكاني. يوفر DeepSeek إشارة دقيقة إلى المواقع.
يلهم Vary التصميم، ومع ذلك يطور DeepSeek تكامل نماذج اللغة الكبيرة (LLM).
بشكل عام، يتصدر DeepSeek-OCR في الضغط البصري للسياقات. تبني التطورات المستقبلية على هذه نقاط القوة.
الخاتمة
يُحدث DeepSeek-OCR ثورة في التفاعلات المرئية-النصية من خلال الضغط البصري للسياقات. تحدد ميزاته وبنيته وأدائه معايير جديدة. يستفيد المطورون من هذا النموذج لحلول مبتكرة، مدعومين بأدوات مثل Apidog.