
يعتمد المطورون في جميع أنحاء العالم على CodeX، مساعد البرمجة القوي المدعوم بالذكاء الاصطناعي من OpenAI، لتبسيط سير عملهم ومعالجة مهام البرمجة المعقدة. ومع ذلك، تكشف المناقشات الأخيرة على منصات مثل X عن قلق متزايد: يرى العديد من المستخدمين أن CodeX يقدم نتائج دون المستوى الأمثل مقارنة بأدائه الأولي. تواجه أخطاءً محبطة، واستجابات أبطأ، أو اقتراحات تعليمات برمجية غير مكتملة، وتتساءل عما إذا كانت الأداة قد تدهورت بالفعل. يستمر هذا التصور على الرغم من ادعاءات OpenAI بالتحسينات المستمرة والمقاييس التي تظهر نموًا في الاستخدام.
يبلغ المهندسون عن حالات يواجه فيها CodeX صعوبة في المهام المعقدة، مثل تطبيق التصحيحات أو التعامل مع المحادثات المطولة، مما يؤدي إلى افتراضات بالتدهور. ومع ذلك، يعالج فريق OpenAI هذه المشكلات بنشاط من خلال تحقيقات صارمة، مما يدل على التزام بالشفافية. على سبيل المثال، نشروا مؤخرًا تقريرًا مفصلاً يوضح النتائج المستخلصة من ملاحظات المستخدمين والتقييمات الداخلية.
زر
فهم CodeX: وظائفه الأساسية وتطوره
يمثل CodeX تقدمًا كبيرًا في البرمجة بمساعدة الذكاء الاصطناعي، بالاعتماد على أساس OpenAI في نماذج اللغة الكبيرة. يصمم المهندسون CodeX لتفسير أوامر اللغة الطبيعية وتوليد مقتطفات تعليمات برمجية، وتصحيح الأخطاء، وحتى إدارة مستودعات كاملة. على عكس إضافات بيئة التطوير المتكاملة (IDE) التقليدية، يتكامل CodeX بعمق مع واجهات سطر الأوامر والمحررات، مما يتيح تفاعلات سلسة.
أطلقت OpenAI أداة CodeX كتطور لنماذج سابقة مثل Codex، مع دمج تحسينات من بنية GPT-5. يركز هذا التكرار على المثابرة، مما يمكّن الذكاء الاصطناعي من إعادة محاولة المهام والتكيف مع ملاحظات المستخدمين داخل الجلسات. ونتيجة لذلك، يستخدم المطورون CodeX لتطبيقات متنوعة، من كتابة البرامج النصية البسيطة إلى عمليات دمج الأنظمة المعقدة.
ومع ذلك، مع تزايد الاعتماد، يدفع المستخدمون حدود CodeX. على سبيل المثال، قد تتضمن المهام الأولية وظائف أساسية، لكن المستخدمين المتقدمين يحاولون إجراء تعديلات على ملفات متعددة أو تنسيق واجهات برمجة التطبيقات. يكشف هذا التحول عن قيود، مما يثير تساؤلات حول اتساق الأداء.
علاوة على ذلك، يستخدم CodeX أدوات مثل apply_patch لتعديل الملفات و compaction لإدارة السياق. تعمل هذه الميزات على تحسين قابلية الاستخدام ولكنها تقدم متغيرات تؤثر على النتائج. عندما تقوم بإدخال أمر، يعالجه CodeX من خلال واجهة برمجة تطبيقات الاستجابات، التي تقوم ببث الرموز وتحليل النتائج. أي تباين في هذا المسار يمكن أن يظهر كتدهور ملحوظ في الأداء.
تقارير المستخدمين: علامات قد تشير إلى ضعف أداء CodeX
يشارك المستخدمون تجاربهم بنشاط على المنصات الاجتماعية، مسلطين الضوء على الحالات التي يفشل فيها CodeX في تلبية التوقعات. على سبيل المثال، أشار أحد المطورين على X إلى أن CodeX يتفوق في المهام الأولية ولكنه يواجه صعوبة مع التعقيد المتزايد، مما يؤدي إلى افتراضات بتدهور النموذج.
على وجه التحديد، تتضمن التقارير أن CodeX يولد فروقًا غير صحيحة أثناء تطبيقات التصحيح، مما يؤدي إلى حذف الملفات وإعادة إنشائها. يعطل هذا السلوك سير العمل، خاصة في الجلسات المتقطعة. تتضمن شكوى شائعة أخرى مشكلة زمن الاستجابة؛ فالمهام التي كانت تكتمل بسرعة تمتد الآن بسبب إعادة المحاولات مع مهل زمنية طويلة.
علاوة على ذلك، يلاحظ المستخدمون تبديل اللغة في منتصف الاستجابة، مثل التحول من الإنجليزية إلى الكورية، وهو ما يُعزى إلى أخطاء في أخذ العينات المقيدة. تؤثر هذه الشذوذات على أقل من 0.25% من الجلسات ولكنها تزيد من الإحباط عند مواجهتها.
بالإضافة إلى ذلك، تتلقى ميزة الضغط (compaction)—وهي ميزة تلخص المحادثات لإدارة السياق—انتقادات. مع طول الجلسات، يؤدي الضغط المتعدد إلى تدهور الدقة، مما دفع OpenAI إلى إضافة تحذيرات: ابدأ محادثات جديدة للتفاعلات المستهدفة.
علاوة على ذلك، تساهم اختلافات الأجهزة؛ فالتكوينات القديمة تؤدي إلى انخفاض طفيف في الأداء، مما يؤثر على الاحتفاظ. يبلغ المطورون المشتركون في الخطط المميزة عن عدم اتساق، على الرغم من أن المقاييس تظهر نموًا عامًا.
بالانتقال من هذه التقارير، يوفر تحليل الأدلة الكمية وضوحًا حول ما إذا كانت هذه المشكلات تشير إلى تدهور حقيقي أو استخدام متطور.
تحليل الأدلة: المقاييس، الملاحظات، وأنماط الاستخدام
تجمع OpenAI بيانات واسعة النطاق حول أداء CodeX، بما في ذلك التقييمات عبر إصدارات CLI والأجهزة. تؤكد التقييمات التحسينات، مثل انخفاض بنسبة 10% في استخدام الرموز بعد تحديثات CLI 0.45، دون تراجعات في المهام الأساسية.
ومع ذلك، تكشف ملاحظات المستخدمين عبر أمر /feedback عن اتجاهات. يقوم المهندسون بفرز أكثر من 100 مشكلة يوميًا، وربطها بأجهزة أو ميزات محددة. تربط النماذج التنبؤية الاحتفاظ بعوامل مثل نظام التشغيل ونوع الخطة، وتحدد الأجهزة كسبب ثانوي.
بالإضافة إلى ذلك، يظهر تحليل الجلسات زيادة في استخدام الضغط بمرور الوقت، وهو ما يرتبط بانخفاض الأداء. تحدد التقييمات هذا: تنخفض الدقة مع الضغط المتكرر.
علاوة على ذلك، لا يُظهر دمج البحث عبر الويب (--search) وتغييرات الأوامر على مدار شهرين أي تأثير سلبي. ومع ذلك، تضيف أوجه القصور في ذاكرة التخزين المؤقت للمصادقة 50 مللي ثانية من زمن الاستجابة لكل طلب، مما يزيد من تصورات المستخدمين.
بالإضافة إلى ذلك، يتطور الاستخدام؛ يستخدم المزيد من المطورين أدوات MCP، مما يزيد من تعقيد الإعداد. توصي OpenAI بتكوينات بسيطة للحصول على أفضل النتائج.
وبالتالي، تشير الأدلة إلى أن التصورات تنبع من دفع CodeX نحو مهام أصعب بدلاً من تدهور جوهري. وكما لخص أحد مستخدمي X، "CodeX جيد جدًا لدرجة أن الناس استمروا في محاولة استخدامه لمهام أصعب ولم يؤدِ تلك المهام بشكل جيد، ثم افترض الناس أن النموذج أصبح أسوأ."
يمهد هذا التحليل الطريق لاستجابة OpenAI التحقيقية، والتي تعالج هذه النقاط مباشرة.
استجابة OpenAI: التحقيق الشفاف في أداء CodeX
تلتزم OpenAI بالشفافية، واعدة بالتحقيق في تقارير التدهور بجدية. أعلن تيبو، عضو فريق Codex، عن التحقيق على X، موضحًا خطة لترقية آليات الملاحظات، وتوحيد الاستخدام الداخلي، وتشغيل تقييمات إضافية.
نفذ المهندسون بسرعة، وأصدروا CLI 0.50 مع ميزة /feedback المحسّنة، وربطوا المشكلات بالمجموعات والأجهزة. أزالوا أكثر من 60 علامة ميزة، مما بسّط المكدس.
علاوة على ذلك، قام فريق متخصص بوضع فرضيات واختبار المشكلات يوميًا. كشف هذا النهج عن حلول، من إخراج الأجهزة القديمة من الخدمة إلى تحسين الضغط.
بالإضافة إلى ذلك، شاركت OpenAI تقريرًا شاملاً بعنوان "أشباح في آلة Codex"، يوضح بالتفصيل النتائج دون تراجعات كبيرة ولكنه يقر بالعوامل المجمعة.
علاوة على ذلك، قاموا بإعادة تعيين حدود المعدل واسترداد الرصيد بسبب خطأ في الفوترة، مما يدل على إجراءات تتمحور حول المستخدم.
بالانتقال إلى التفاصيل، تلقي النتائج الرئيسية للتقرير الضوء على الفروق الدقيقة التقنية وراء مخاوف المستخدمين.
النتائج الرئيسية من تقرير تدهور CodeX الخاص بـ OpenAI
يخلص التقرير إلى عدم وجود مشكلة كبيرة واحدة؛ بدلاً من ذلك، تتراكم التحولات في السلوك والمشكلات الثانوية. بالنسبة للأجهزة، حددت التقييمات والنماذج الوحدات القديمة، مما أدى إلى إزالتها وتحسينات موازنة الحمل.
فيما يتعلق بالضغط، يؤدي التكرار الأعلى بمرور الوقت إلى تدهور الجلسات. حسّنت OpenAI التطبيقات لتجنب الملخصات المتكررة وأضافت إرشادات للمستخدمين.
بالنسبة لـ apply_patch، تؤدي الإخفاقات النادرة إلى عمليات حذف محفوفة بالمخاطر؛ تعمل التخفيفات على الحد من هذه التسلسلات، مع التخطيط لتحسينات النموذج.
لا تشهد مهل الوقت تراجعات واسعة النطاق—يتحسن زمن الاستجابة—لكن عمليات إعادة المحاولة غير الفعالة تستمر. تستهدف الاستثمارات معالجة أفضل للعمليات الطويلة.
يتسبب خطأ في أخذ العينات المقيدة في ظهور رموز خارج التوزيع، وسيتم إصلاحه قريبًا.
تكشف عمليات تدقيق واجهة برمجة تطبيقات الاستجابات عن تغييرات طفيفة في الترميز دون تأثير على الأداء.
تؤكد التحقيقات الأخرى، مثل التقييمات على إصدارات CLI والأوامر، الاستقرار.
علاوة على ذلك، توصي الإعدادات المتطورة التي تحتوي على المزيد من الأدوات بالبساطة.
تؤكد هذه النتائج تجارب المستخدمين بينما تثبت عدم وجود تدهور عام.
التحسينات المنفذة والتوجهات المستقبلية لـ CodeX
تتصرف OpenAI بناءً على النتائج، وتطرح إصلاحات مثل تحذيرات الضغط وتصحيحات أخذ العينات. تعمل عمليات تنقية الأجهزة وتقليل زمن الاستجابة على تعزيز الموثوقية.
علاوة على ذلك، يشكلون فريقًا دائمًا لمراقبة الأداء في العالم الحقيقي، ويقومون بتوظيف المواهب للتحسينات المستمرة.
بالإضافة إلى ذلك، يزداد تواصل الملاحظات، مما يضمن إدخالًا مستمرًا.
يتضمن العمل المستقبلي تحسينات في استمرارية النموذج وقابلية تكييف الأدوات.
وبالتالي، يتطور CodeX، ويعالج التصورات من خلال تحسينات مدفوعة بالبيانات.
ومع ذلك، بينما ينتظر المطورون هذه التحسينات، يبحثون عن مكملات مثل Apidog.
الأدوات التكميلية: كيف يعزز Apidog سير عمل CodeX
عندما يتعامل CodeX مع مهام واجهة برمجة التطبيقات، تنشأ تناقضات، خاصة في عمليات التكامل. يسد Apidog، وهو نظام أساسي قوي لواجهة برمجة التطبيقات، هذه الفجوة.
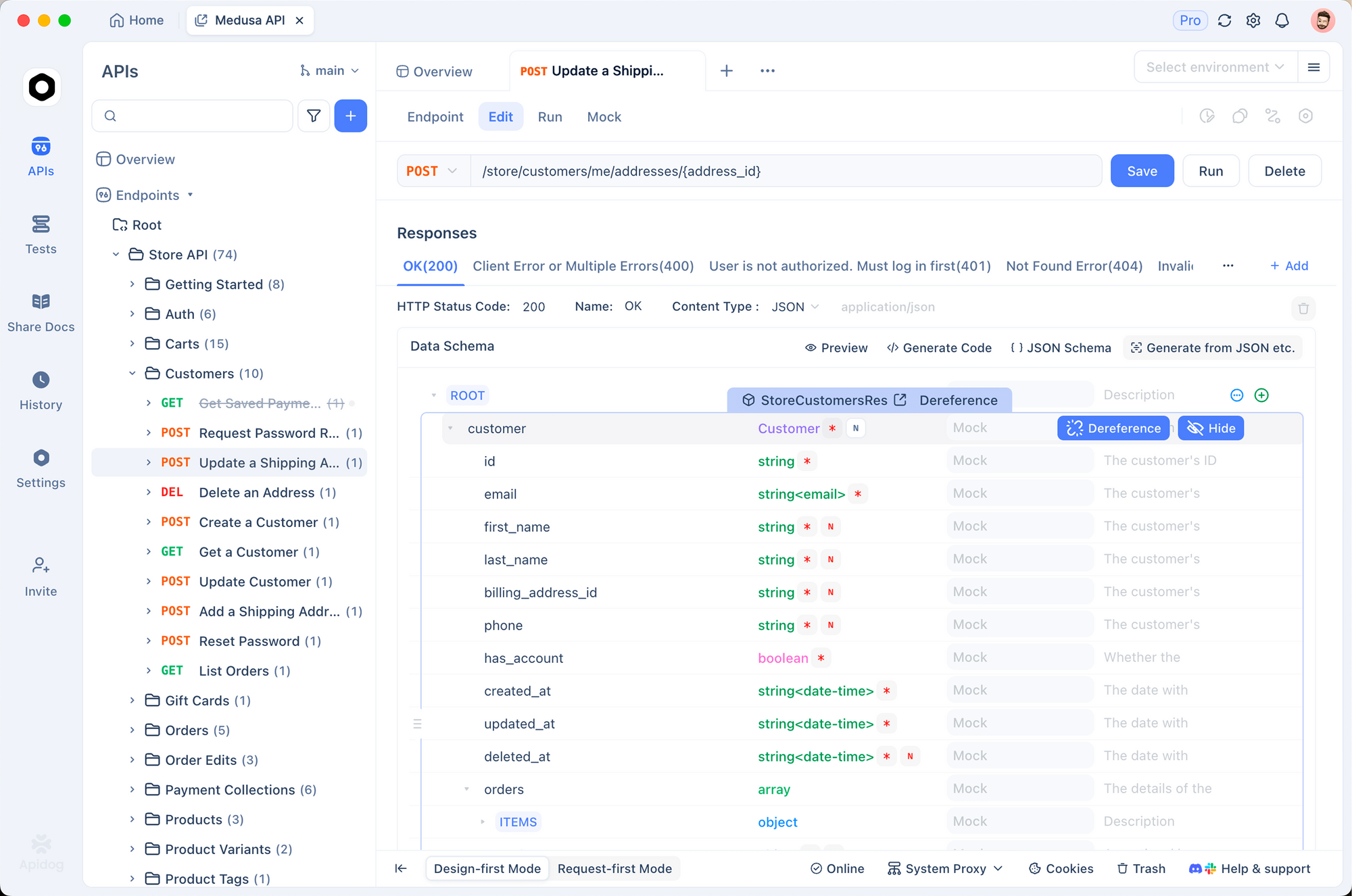
يستخدم المطورون Apidog لتصميم واختبار وتوثيق واجهات برمجة التطبيقات، مما يضمن عمل التعليمات البرمجية التي تم إنشاؤها بواسطة CodeX بشكل صحيح.
على سبيل المثال، قم بمحاكاة نقاط النهاية في Apidog قبل تنفيذ CodeX، مما يقلل الأخطاء.
علاوة على ذلك، يوفر تنزيل Apidog المجاني ميزات التعاون، وإدارة الإصدارات، والأتمتة—وهو مثالي للفرق التي تواجه قيود CodeX.
بالانتقال بسلاسة، يتكامل Apidog مع بيئات البرمجة، مما يتحقق من صحة مخرجات الذكاء الاصطناعي.
وبالتالي، فإن إقران CodeX مع Apidog يحسن التطوير، ويخفف من التدهورات المتصورة.
دراسات حالة: أمثلة واقعية من مناقشات X
توفر سلاسل X أمثلة حية. سلط أحد المستخدمين الضوء على نجاح CodeX في توليد طموح مفرط، مرددًا صدى تطور الاستخدام في التقرير.
ناقش آخر سرعة واجهة سطر الأوامر (CLI)، والتحول إلى بدائل للمهام السريعة، مما يؤكد مخاوف زمن الاستجابة.
علاوة على ذلك، عالجت عمليات إعادة تعيين الفواتير الرسوم الزائدة، مما أعاد الثقة.
توضح هذه الحكايات، جنبًا إلى جنب مع بيانات التقرير، قضايا متعددة الأوجه.
أفضل الممارسات لزيادة أداء CodeX
لمواجهة التصورات، اتبع الممارسات التالية: اجعل الجلسات قصيرة، قلل من استخدام الأدوات، استخدم /feedback.
علاوة على ذلك، راقب التحديثات؛ فتحسينات CLI تؤثر مباشرة على النتائج.
بالإضافة إلى ذلك، جرب الأوامر للحصول على دقة.
وبالتالي، تعزز هذه الخطوات التجارب.
الخاتمة: احتضان التغيير في CodeX وما بعده
يرى المستخدمون أن CodeX أقل ذكاءً بسبب المهام المعقدة والمشكلات الثانوية، لكن الأدلة تظهر تطورًا، وليس تدهورًا. يؤكد تحقيق OpenAI وإصلاحاتها الالتزام.
علاوة على ذلك، يضمن دمج Apidog سير عمل مرن.
في النهاية، قم بتكييف الاستراتيجيات، واستفد من الأدوات، وساهم بالملاحظات—فالتعديلات الصغيرة تحقق مكاسب كبيرة في الإنتاجية.
زر