
Chạy Gemma 3 cục bộ với Ollama cho bạn toàn quyền kiểm soát môi trường AI của mình mà không cần dựa vào dịch vụ đám mây. Hướng dẫn này sẽ hướng dẫn bạn cách thiết lập Ollama, tải về Gemma 3 và chạy nó trên máy của bạn.
Hãy bắt đầu nào.
Tại sao chạy Gemma 3 cục bộ với Ollama?
“Tại sao phải bận tâm đến việc chạy Gemma 3 cục bộ?” Chà, có một số lý do chính đáng. Thứ nhất, triển khai cục bộ giúp bạn toàn quyền kiểm soát dữ liệu và quyền riêng tư của mình mà không cần gửi thông tin nhạy cảm lên đám mây. Ngoài ra, nó tiết kiệm chi phí, vì bạn tránh được các phí sử dụng API liên tục. Thêm vào đó, hiệu quả của Gemma 3 có nghĩa là ngay cả mô hình 27B cũng có thể chạy trên một GPU duy nhất, làm cho nó dễ tiếp cận với các nhà phát triển có phần cứng khiêm tốn.
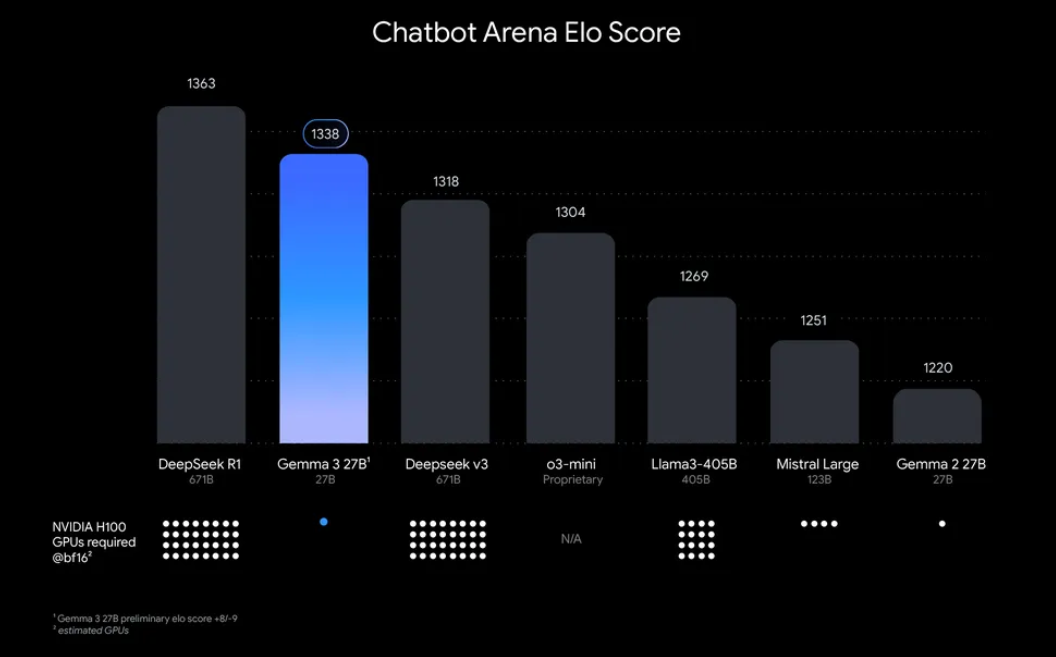
Ollama, một nền tảng nhẹ để chạy các mô hình ngôn ngữ lớn (LLMs) cục bộ, đơn giản hóa quy trình này. Nó đóng gói mọi thứ bạn cần: trọng số mô hình, cấu hình và phụ thuộc vào một định dạng dễ sử dụng. Sự kết hợp giữa Gemma 3 và Ollama thật hoàn hảo cho việc thử nghiệm, xây dựng ứng dụng hoặc kiểm tra quy trình AI trên máy của bạn. Vậy hãy xắn tay áo lên và bắt đầu nào!
Những gì bạn cần để chạy Gemma 3 với Ollama
Trước khi bước vào quy trình thiết lập, đảm bảo bạn có các yêu cầu cần thiết sau:
- Một máy tính tương thích: Bạn sẽ cần một máy tính với GPU (tốt nhất là NVIDIA để có hiệu suất tối ưu) hoặc CPU mạnh mẽ. Mô hình 27B yêu cầu tài nguyên đáng kể, nhưng các phiên bản nhỏ hơn như 1B hoặc 4B có thể chạy trên phần cứng ít mạnh mẽ hơn.
- Ollama đã được cài đặt: Tải xuống và cài đặt Ollama, có sẵn cho MacOS, Windows và Linux. Bạn có thể tải nó từ ollama.com.
- Kỹ năng dòng lệnh cơ bản: Bạn sẽ tương tác với Ollama thông qua terminal hoặc command prompt.
- Kết nối Internet: Ban đầu, bạn sẽ cần tải xuống các mô hình Gemma 3, nhưng khi đã tải xuống, bạn có thể chạy chúng ngoại tuyến.
- Tùy chọn: Apidog để thử nghiệm API: Nếu bạn dự định tích hợp Gemma 3 với một API hoặc thử nghiệm các phản hồi của nó theo cách lập trình, giao diện trực quan của Apidog có thể tiết kiệm cho bạn thời gian và nỗ lực.
Bây giờ bạn đã sẵn sàng, hãy khám phá quy trình cài đặt và thiết lập.
Hướng dẫn từng bước: Cài đặt Ollama và tải xuống Gemma 3
1. Cài đặt Ollama trên máy của bạn
Ollama giúp việc triển khai LLM cục bộ trở nên đơn giản, và việc cài đặt nó cũng vậy. Dưới đây là cách thực hiện:
- Đối với MacOS/Windows: Truy cập ollama.com và tải xuống trình cài đặt cho hệ điều hành của bạn. Làm theo hướng dẫn trên màn hình để hoàn tất quá trình cài đặt.
- Đối với Linux (ví dụ: Ubuntu): Mở terminal của bạn và chạy lệnh sau:
curl -fsSL https://ollama.com/install.sh | sh
Script này tự động phát hiện phần cứng của bạn (bao gồm cả GPU) và cài đặt Ollama.
Sau khi cài đặt, xác minh quá trình cài đặt bằng cách chạy:
ollama --version

Bạn sẽ thấy số phiên bản hiện tại, xác nhận rằng Ollama đã sẵn sàng để sử dụng.
2. Tải các mô hình Gemma 3 bằng Ollama
Thư viện mô hình của Ollama bao gồm Gemma 3, nhờ vào sự tích hợp với các nền tảng như Hugging Face và các sản phẩm AI của Google. Để tải Gemma 3, sử dụng lệnh ollama pull.
ollama pull gemma3

Đối với các mô hình nhỏ hơn, bạn có thể sử dụng:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
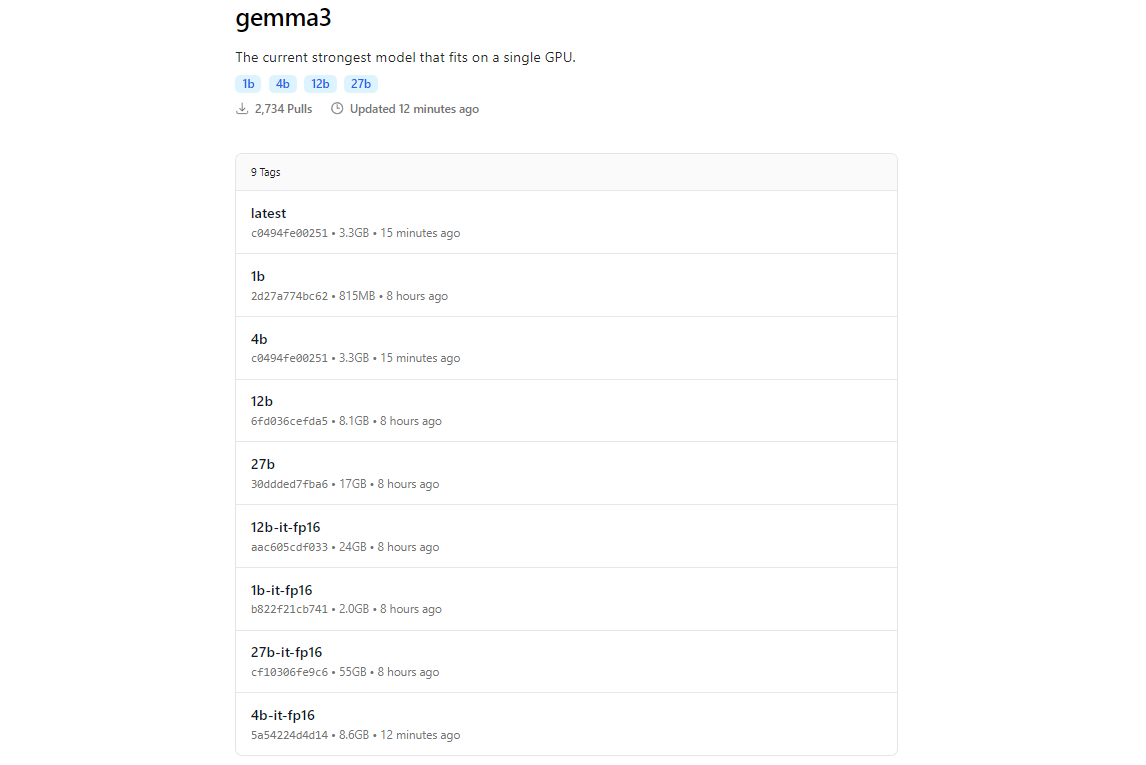
Kích thước tải xuống thay đổi theo mô hình, hãy dự đoán mô hình 27B sẽ có kích thước vài gigabyte, vì vậy hãy đảm bảo bạn có đủ bộ nhớ. Các mô hình Gemma 3 được tối ưu hóa cho hiệu suất, nhưng chúng vẫn yêu cầu phần cứng tốt cho các biến thể lớn hơn.
3. Xác minh quá trình cài đặt
Sau khi tải xuống, kiểm tra xem mô hình có khả dụng bằng cách liệt kê tất cả các mô hình:
ollama list

Bạn sẽ thấy gemma3 (hoặc kích thước bạn đã chọn) trong danh sách. Nếu nó có ở đó, bạn đã sẵn sàng để chạy Gemma 3 cục bộ!
Chạy Gemma 3 với Ollama: Chế độ tương tác và tích hợp API
Chế độ tương tác: Trò chuyện với Gemma 3
Chế độ tương tác của Ollama cho phép bạn trò chuyện với Gemma 3 trực tiếp từ terminal. Để bắt đầu, hãy chạy:
ollama run gemma3
Bạn sẽ thấy một nhắc nhở nơi bạn có thể gõ các truy vấn. Ví dụ, hãy thử:
Các tính năng chính của Gemma 3 là gì?
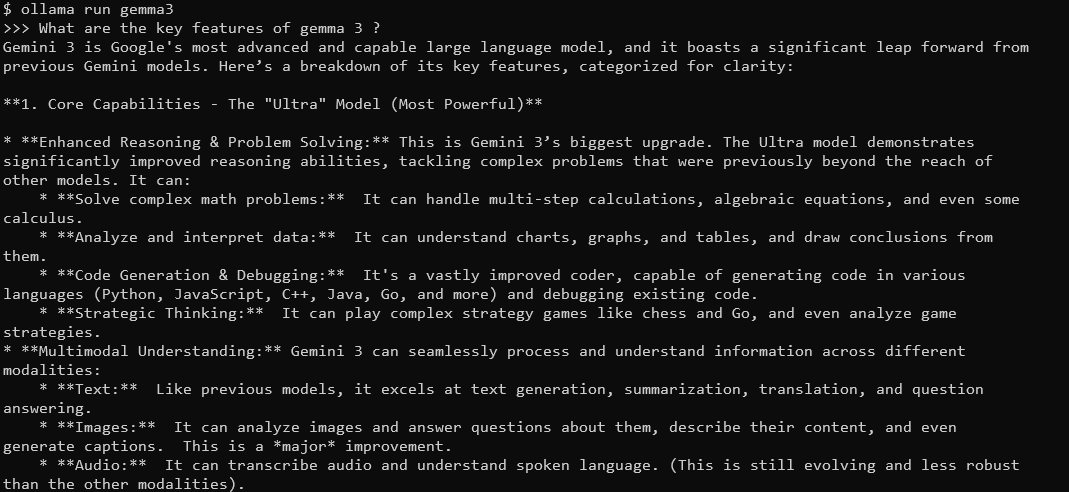
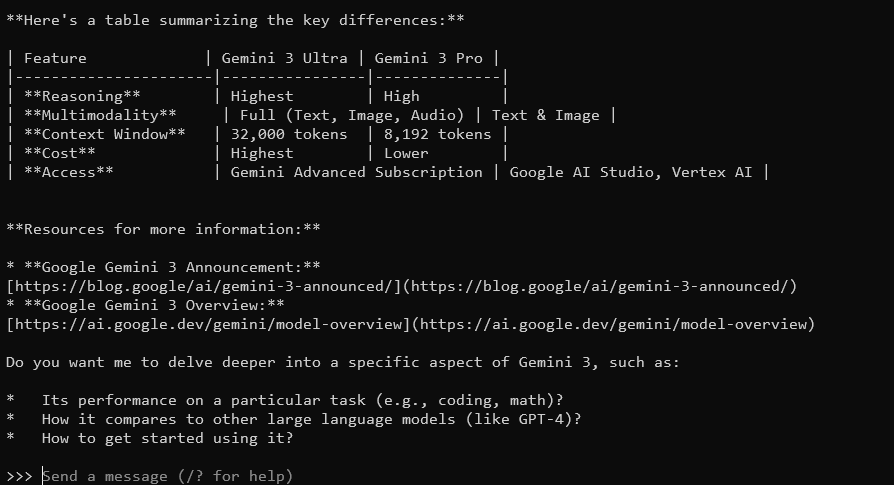
Gemma 3, với cửa sổ ngữ cảnh 128K và khả năng đa mô hình, sẽ phản hồi bằng các câu trả lời chi tiết, nhạy cảm với ngữ cảnh. Nó hỗ trợ hơn 140 ngôn ngữ và có thể xử lý văn bản, hình ảnh, và thậm chí là đầu vào video (đối với một số kích thước).
Để thoát, gõ Ctrl+D hoặc /bye.
Tích hợp Gemma 3 với API của Ollama
Nếu bạn muốn xây dựng ứng dụng hoặc tự động hóa các tương tác, Ollama cung cấp một API mà bạn có thể sử dụng. Đây là nơi Apidog tỏa sáng, giao diện thân thiện của nó giúp bạn thử nghiệm và quản lý các yêu cầu API một cách hiệu quả. Dưới đây là cách bắt đầu:
Bắt đầu máy chủ Ollama: Chạy lệnh sau để khởi động máy chủ API của Ollama:
ollama serve
Điều này khởi động máy chủ trên localhost:11434 theo mặc định.
Thực hiện các yêu cầu API: Bạn có thể tương tác với Gemma 3 qua các yêu cầu HTTP. Ví dụ, sử dụng curl để gửi một lời nhắc:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "Thủ đô của Pháp là gì?"}'
Phản hồi sẽ bao gồm đầu ra của Gemma 3, được định dạng dưới dạng JSON.
Sử dụng Apidog để thử nghiệm: Tải Apidog miễn phí và tạo một yêu cầu API để kiểm tra phản hồi của Gemma 3. Giao diện trực quan của Apidog cho phép bạn nhập điểm cuối (http://localhost:11434/api/generate), thiết lập tải trọng JSON, và phân tích phản hồi mà không cần viết mã phức tạp. Điều này đặc biệt hữu ích cho việc gỡ lỗi và tối ưu hóa tích hợp của bạn.
Hướng dẫn từng bước để sử dụng thử nghiệm SSE trên Apidog
Hãy cùng tìm hiểu quy trình sử dụng tính năng thử nghiệm SSE tối ưu trên Apidog, hoàn chỉnh với các cải tiến Auto-Merge mới. Làm theo các bước sau để thiết lập và tối đa hóa trải nghiệm gỡ lỗi thời gian thực của bạn.
Bước 1: Tạo một yêu cầu API mới
Bắt đầu bằng cách khởi chạy một dự án HTTP mới trên Apidog. Thêm một điểm cuối mới và nhập URL cho API hoặc điểm cuối mô hình AI của bạn. Đây là điểm xuất phát của bạn cho việc thử nghiệm và gỡ lỗi các luồng dữ liệu thời gian thực.
Bước 2: Gửi yêu cầu
Khi bạn đã thiết lập điểm cuối, hãy gửi yêu cầu API. Quan sát kỹ các tiêu đề phản hồi. Nếu tiêu đề bao gồm Content-Type: text/event-stream, Apidog sẽ tự động nhận diện và diễn giải phản hồi như một luồng SSE. Việc phát hiện này rất quan trọng cho quy trình tự động hợp nhất tiếp theo.

Bước 3: Theo dõi dòng thời gian thời gian thực
Sau khi kết nối SSE được thiết lập, Apidog sẽ mở một chế độ xem dòng thời gian chuyên dụng nơi tất cả các sự kiện SSE đến sẽ được hiển thị theo thời gian thực. Dòng thời gian này sẽ liên tục cập nhật khi có dữ liệu mới đến, cho phép bạn theo dõi luồng dữ liệu một cách chính xác. Dòng thời gian này không chỉ là một sự tràn ngập dữ liệu thô mà còn là một hình ảnh được cấu trúc cẩn thận giúp bạn nhìn thấy chính xác khi và làm thế nào dữ liệu được truyền dẫn.
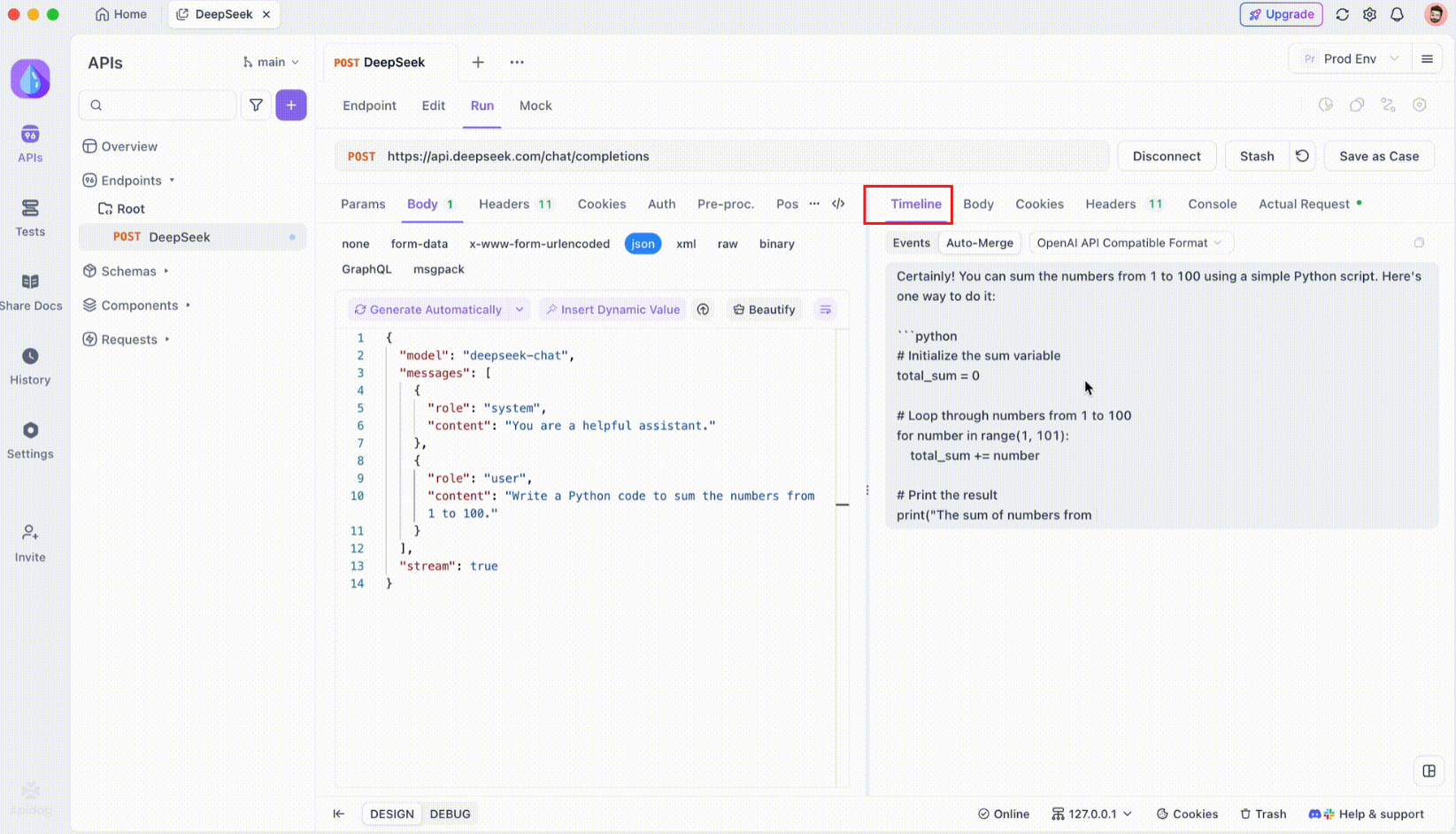
Bước 4: Tự động hợp nhất tin nhắn
Đây là nơi phép thuật xảy ra. Với các cải tiến tự động hợp nhất, Apidog tự động nhận diện các định dạng mô hình AI phổ biến và hợp nhất các phản hồi SSE bị phân mảnh thành một phản hồi hoàn chỉnh. Bước này bao gồm:
- Nhận diện tự động: Apidog kiểm tra xem phản hồi có định dạng được hỗ trợ (OpenAI, Gemini, hoặc Claude) hay không.
- Hợp nhất tin nhắn: Nếu định dạng được nhận diện, nền tảng sẽ tự động kết hợp tất cả các mảnh SSE, mang đến một phản hồi liền mạch, đầy đủ.
- Hình ảnh hóa nâng cao: Đối với một số mô hình AI, chẳng hạn như DeepSeek R1, dòng thời gian cũng hiển thị quá trình suy nghĩ của mô hình, cung cấp một lớp hiểu biết bổ sung về lý do đằng sau phản hồi được tạo ra.
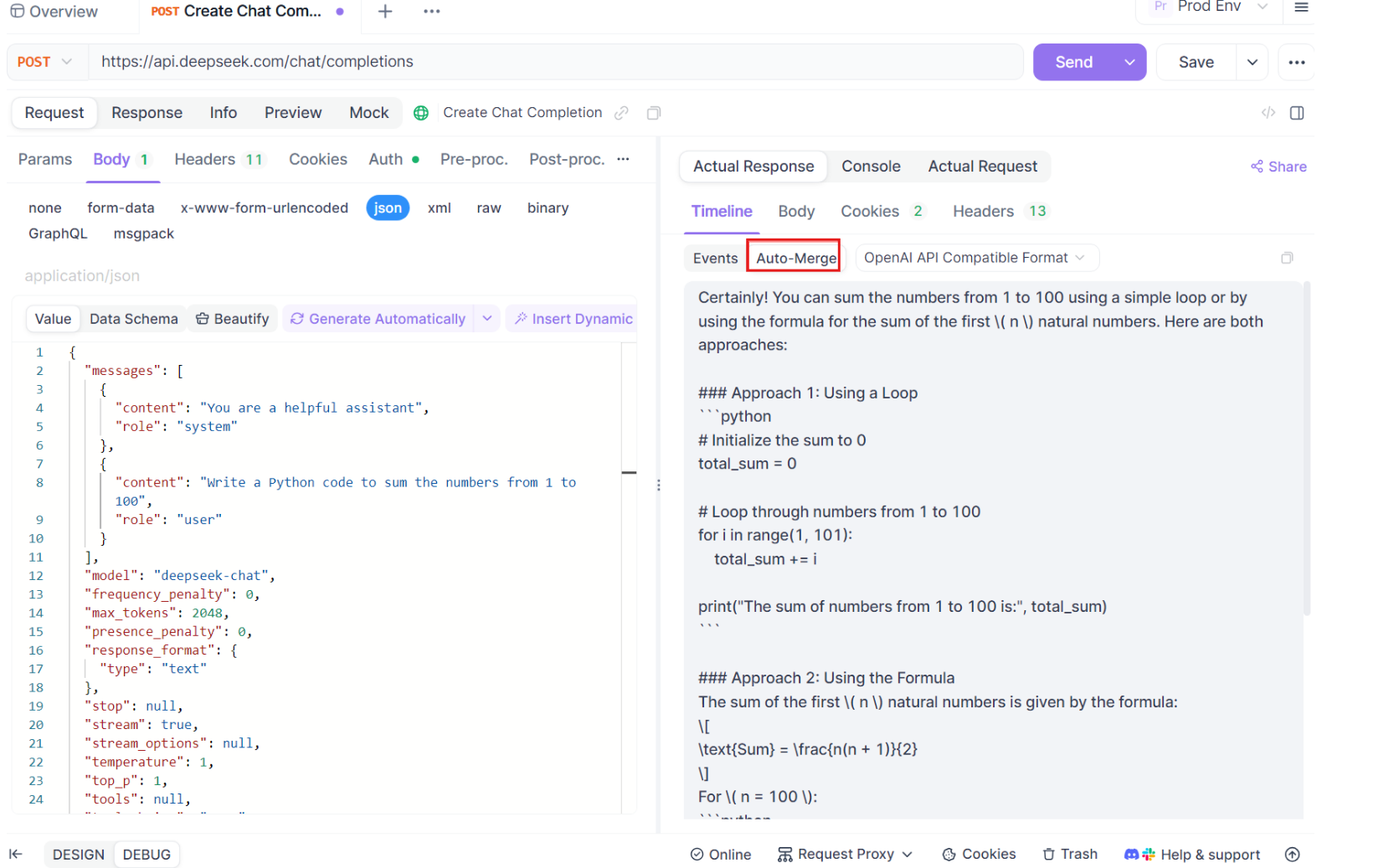
Tính năng này đặc biệt hữu ích khi xử lý các ứng dụng dựa trên AI, đảm bảo rằng mọi phần của phản hồi đều được ghi lại và trình bày một cách hoàn chỉnh mà không cần can thiệp thủ công.
Bước 5: Cấu hình các quy tắc trích xuất JSONPath
Không phải mọi phản hồi SSE sẽ tự động tuân theo các định dạng tích hợp sẵn. Khi làm việc với các phản hồi JSON yêu cầu trích xuất tùy chỉnh, Apidog cho phép bạn cấu hình JSONPath quy tắc. Ví dụ, nếu phản hồi SSE thô của bạn chứa một đối tượng JSON và bạn cần trích xuất trường content, bạn có thể thiết lập cấu hình JSONPath như sau:
- JSONPath:
$.choices[0].message.content - Giải thích:
$ám chỉ đến gốc của đối tượng JSON.choices[0]chọn phần tử đầu tiên của mảngchoices.message.contentchỉ định trường nội dung trong đối tượng tin nhắn.
Cấu hình này chỉ đạo Apidog cách trích xuất dữ liệu mong muốn từ phản hồi SSE của bạn, đảm bảo rằng ngay cả các phản hồi không chuẩn cũng được xử lý hiệu quả.
Kết luận
Chạy Gemma 3 cục bộ với Ollama là một cách thú vị để tận dụng khả năng AI tiên tiến của Google mà không rời khỏi máy của bạn. Từ việc cài đặt Ollama và tải mô hình đến tương tác qua terminal hoặc API, hướng dẫn này đã dẫn bạn qua từng bước. Với các tính năng đa mô hình, hỗ trợ đa ngôn ngữ và hiệu suất ấn tượng, Gemma 3 là một bước ngoặt cho cả các nhà phát triển và những người yêu thích AI. Đừng quên tận dụng các công cụ như Apidog để thử nghiệm và tích hợp API liền mạch - tải ngay miễn phí hôm nay để nâng cao các dự án Gemma 3 của bạn!
Dù bạn đang thử nghiệm với mô hình 1B trên laptop hay đẩy giới hạn của mô hình 27B trên một rig GPU, bạn đã sẵn sàng để khám phá những khả năng. Chúc bạn lập trình vui vẻ và hãy xem những điều tuyệt vời mà bạn xây dựng với Gemma 3!