
Nếu bạn từng ước có thể hỏi trực tiếp các câu hỏi về một tệp PDF hoặc hướng dẫn kỹ thuật, hướng dẫn này dành cho bạn. Hôm nay, chúng ta sẽ xây dựng một hệ thống Generative Tăng cường Lấy lại (RAG) sử dụng DeepSeek R1, một nguồn mở về lý luận, và Ollama, một khung nhẹ để chạy các mô hình AI cục bộ.
Chuẩn bị tăng tốc thử nghiệm API của bạn? Đừng quên kiểm tra Apidog! Apidog hoạt động như một nền tảng một cửa để tạo, quản lý và chạy các thử nghiệm và máy chủ giả lập, giúp bạn xác định các nút cổ chai và giữ cho các API của bạn đáng tin cậy.
Thay vì phải xử lý nhiều công cụ hoặc viết các kịch bản dài dòng, bạn có thể tự động hóa các phần quan trọng trong quy trình làm việc của mình, đạt được các pipeline CI/CD mượt mà và dành nhiều thời gian hơn để hoàn thiện các tính năng sản phẩm của mình.
Nếu điều đó nghe có vẻ như điều gì đó có thể làm đơn giản hóa cuộc sống của bạn, hãy thử Apidog!
Trong bài viết này, chúng ta sẽ khám phá cách mà DeepSeek R1—một mô hình cạnh tranh với o1 của OpenAI về hiệu suất nhưng có chi phí thấp hơn 95%—có thể làm tăng cường các hệ thống RAG của bạn. Hãy phân tích lý do tại sao các nhà phát triển đang đổ xô đến công nghệ này và cách bạn có thể xây dựng pipeline RAG riêng của mình với nó.
Hệ thống RAG cục bộ này tốn bao nhiêu?
| Thành phần | Chi phí |
|---|---|
| DeepSeek R1 1.5B | Miễn phí |
| Ollama | Miễn phí |
| PC RAM 16GB | $0 |
Mô hình 1.5B của DeepSeek R1 nổi bật ở đây vì:
- Lấy lại có trọng tâm: Chỉ có 3 khối tài liệu cung cấp cho mỗi câu trả lời
- Đưa ra điều kiện nghiêm ngặt: “Tôi không biết” ngăn chặn ảo giác
- Thực hiện cục bộ: Không có độ trễ so với các API trên đám mây
Những gì bạn sẽ cần
Trước khi bắt đầu mã, chúng ta hãy thiết lập các bộ công cụ của mình:
1. Ollama
Ollama cho phép bạn chạy các mô hình như DeepSeek R1 cục bộ.
- Tải xuống: https://ollama.com/
- Cài đặt, sau đó mở terminal của bạn và chạy:
ollama run deepseek-r1 # Đối với mô hình 7B (mặc định)
2. Các biến thể mô hình DeepSeek R1
DeepSeek R1 có nhiều kích cỡ từ 1.5B đến 671B tham số. Đối với bản demo này, chúng ta sẽ sử dụng mô hình 1.5B—hoàn hảo cho RAG nhẹ:
ollama run deepseek-r1:1.5b
Mẹo chuyên nghiệp: Các mô hình lớn hơn như 70B cung cấp khả năng lý luận tốt hơn nhưng yêu cầu nhiều RAM hơn. Bắt đầu từ nhỏ, sau đó mở rộng!

Xây dựng Pipeline RAG: Hướng dẫn mã
Bước 1: Nhập thư viện
Chúng ta sẽ sử dụng:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
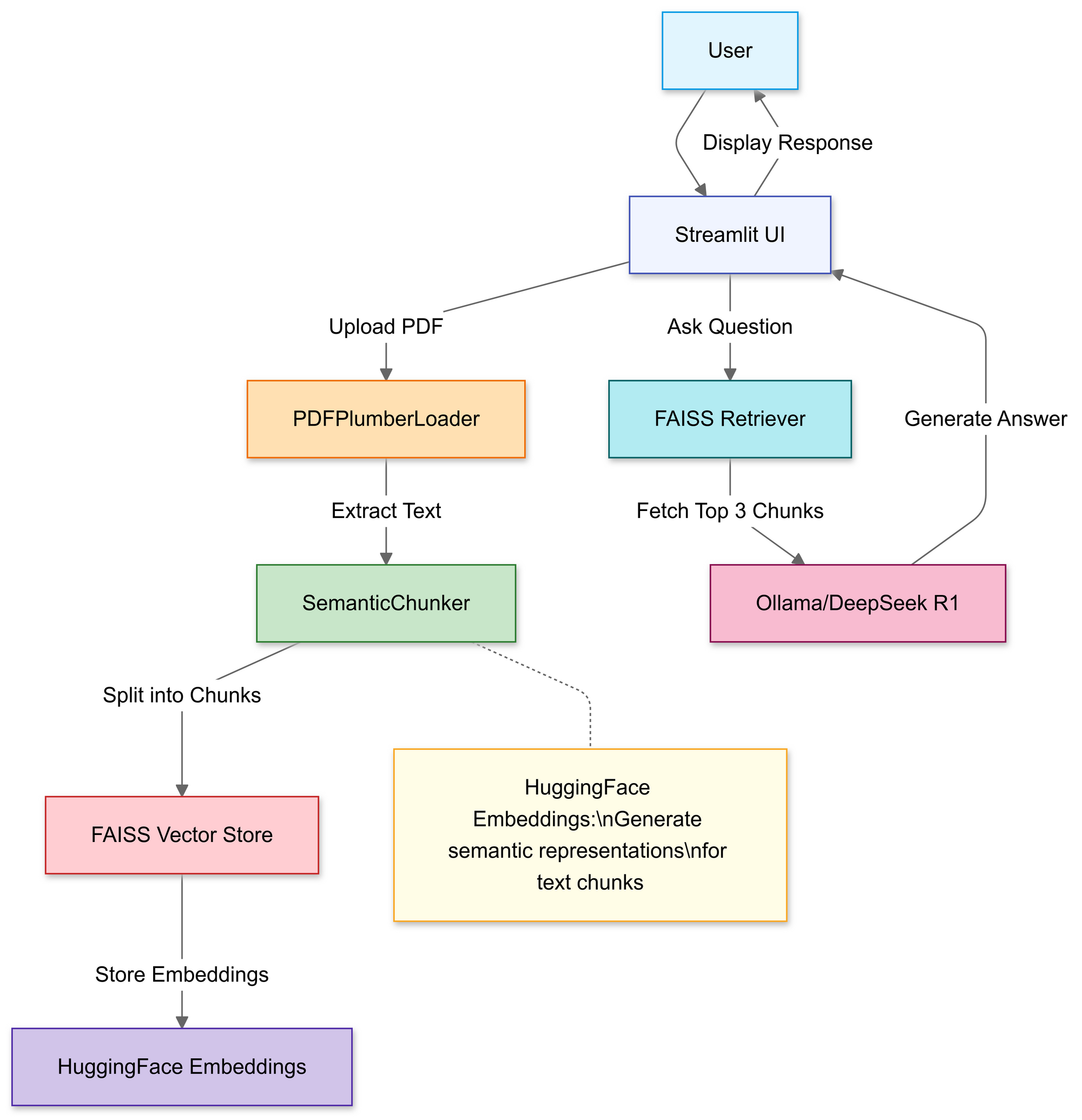
Bước 2: Tải lên & Xử lý PDF
Trong phần này, bạn sử dụng trình tải tệp của Streamlit để cho phép người dùng chọn một tệp PDF cục bộ.
# Trình tải tệp Streamlit
uploaded_file = st.file_uploader("Tải lên một tệp PDF", type="pdf")
if uploaded_file:
# Lưu PDF tạm thời
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Tải văn bản PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Khi đã tải lên, hàm PDFPlumberLoader sẽ trích xuất văn bản từ tệp PDF, chuẩn bị cho giai đoạn tiếp theo của pipeline. Phương pháp này rất thuận tiện vì nó xử lý việc đọc nội dung tệp mà không cần phải phân tích thủ công nhiều.
Bước 3: Chia nhỏ tài liệu một cách chiến lược
Chúng ta muốn sử dụng RecursiveCharacterTextSplitter, mã này chia nhỏ văn bản PDF gốc thành các đoạn nhỏ hơn (khối). Hãy giải thích các khái niệm của việc chia nhỏ tốt vs xấu ở đây:
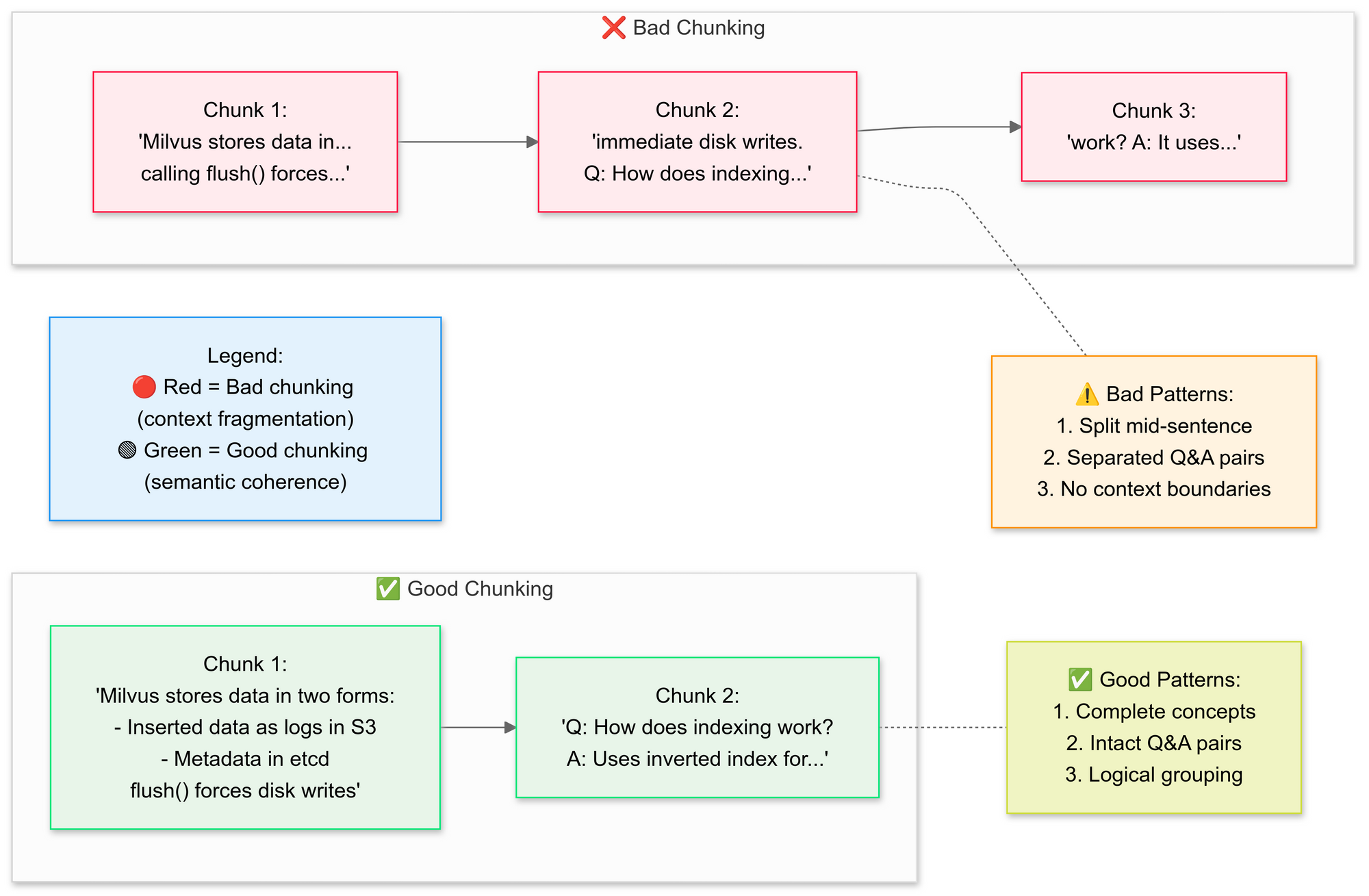
Tại sao lại là chia nhỏ ngữ nghĩa?
- Nhóm các câu liên quan (ví dụ: "Cách Milvus lưu trữ dữ liệu" giữ nguyên)
- Tránh việc chia nhỏ các bảng hoặc hình vẽ
# Chia văn bản thành các khối ngữ nghĩa
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Bước này giữ lại bối cảnh bằng cách chồng chéo các đoạn một chút, giúp mô hình ngôn ngữ trả lời câu hỏi chính xác hơn. Những khối tài liệu nhỏ, được xác định tốt cũng làm cho việc tìm kiếm trở nên hiệu quả và liên quan hơn.
Bước 4: Tạo một cơ sở dữ liệu tri thức có thể tìm kiếm
Sau khi chia nhỏ, pipeline sẽ tạo ra các vector embeddings cho các đoạn và lưu trữ chúng trong chỉ mục FAISS.
# Tạo embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Kết nối retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Lấy 3 khối hàng đầu
Điều này biến văn bản thành đại diện số mà dễ dàng truy vấn hơn nhiều. Các truy vấn sau đó sẽ chạy trên chỉ mục này để tìm các khối phù hợp nhất về ngữ cảnh.
Bước 5: Cấu hình DeepSeek R1
Tại đây, bạn khởi tạo một chuỗi RetrievalQA sử dụng Deepseek R1 1.5B như một mô hình ngôn ngữ cục bộ.
llm = Ollama(model="deepseek-r1:1.5b") # Mô hình tham số 1.5B của chúng ta
# Tạo mẫu câu hỏi
prompt = """
1. Chỉ sử dụng bối cảnh bên dưới.
2. Nếu không chắc chắn, hãy nói "Tôi không biết".
3. Giữ cho câu trả lời dưới 4 câu.
Bối cảnh: {context}
Câu hỏi: {question}
Câu trả lời:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Mẫu này buộc mô hình phải dựa vào nội dung trong PDF của bạn để trả lời. Bằng cách bao bọc mô hình ngôn ngữ với một retriever liên kết với chỉ mục FAISS, bất kỳ truy vấn nào được thực hiện qua chuỗi sẽ tìm kiếm bối cảnh từ nội dung PDF, khiến câu trả lời được dựa trên tài liệu gốc.
Bước 6: Lắp ráp chuỗi RAG
Tiếp theo, bạn có thể kết nối các bước tải lên, chia nhỏ và lấy lại thành một pipeline hợp lý.
# Chuỗi 1: Tạo câu trả lời
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chuỗi 2: Kết hợp các khối tài liệu
document_prompt = PromptTemplate(
template="Bối cảnh:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Pipeline RAG cuối cùng
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Đây là phần lõi của thiết kế RAG (Generative Tăng cường Lấy lại), cung cấp cho mô hình ngôn ngữ lớn bối cảnh đã xác minh thay vì chỉ dựa vào việc đào tạo nội bộ của nó.
Bước 7: Khởi động giao diện web
Cuối cùng, mã sử dụng các hàm nhập và ghi của Streamlit để người dùng có thể nhập câu hỏi và xem phản hồi ngay lập tức.
# Giao diện Streamlit
user_input = st.text_input("Hãy hỏi PDF của bạn một câu hỏi:")
if user_input:
with st.spinner("Đang suy nghĩ..."):
response = qa(user_input)["result"]
st.write(response)
Ngay khi người dùng nhập truy vấn, chuỗi sẽ lấy lại các khối phù hợp nhất, đưa chúng vào mô hình ngôn ngữ, và hiển thị một câu trả lời. Với thư viện langchain được cài đặt đúng cách, mã này sẽ hoạt động mà không gây ra lỗi thiếu mô-đun.
Hãy hỏi và gửi câu hỏi và nhận câu trả lời ngay lập tức!
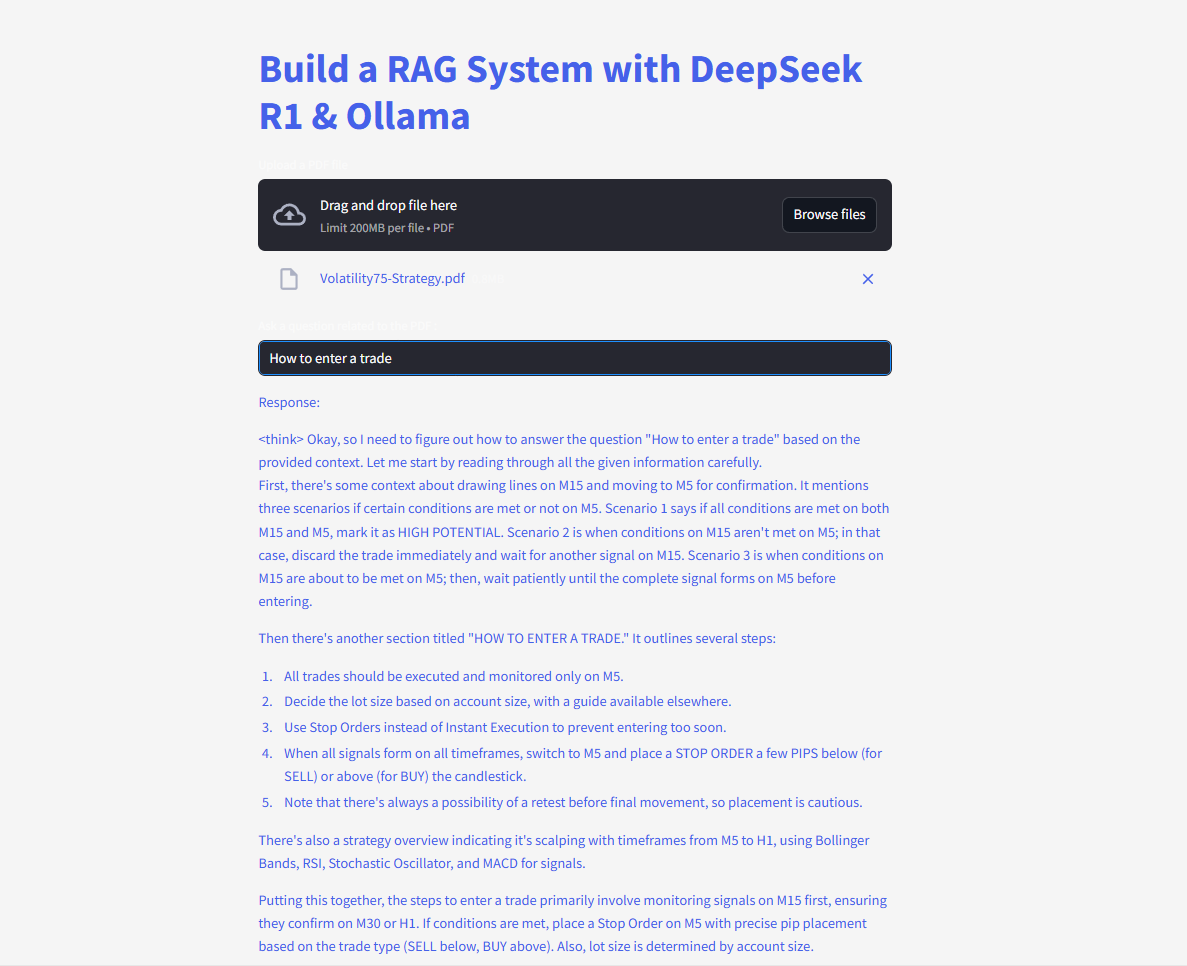
Dưới đây là mã hoàn chỉnh:
Tương lai của RAG với DeepSeek
Với các tính năng như tự xác minh và lý luận đa bước đang được phát triển, DeepSeek R1 sẵn sàng mở khóa thêm nhiều ứng dụng RAG tiên tiến hơn. Hãy tưởng tượng một AI không chỉ trả lời câu hỏi mà còn tranh luận về logic của chính nó—một cách tự chủ.