
Các mô hình ngôn ngữ lớn (LLMs) như Qwen3 đang cách mạng hóa lĩnh vực AI với khả năng ấn tượng trong lập trình, suy luận và hiểu ngôn ngữ tự nhiên. Được phát triển bởi nhóm Qwen tại Alibaba, Qwen3 cung cấp các mô hình lượng tử hóa (quantized) cho phép triển khai cục bộ hiệu quả, giúp các nhà phát triển, nhà nghiên cứu và những người đam mê dễ dàng chạy các mô hình mạnh mẽ này trên phần cứng của riêng họ. Cho dù bạn đang sử dụng Ollama, LM Studio hay vLLM, hướng dẫn này sẽ hướng dẫn bạn quy trình thiết lập và chạy các mô hình lượng tử hóa Qwen3 cục bộ.
Trong hướng dẫn kỹ thuật này, chúng ta sẽ khám phá quy trình thiết lập, lựa chọn mô hình, các phương pháp triển khai và tích hợp API. Hãy bắt đầu.
Các Mô Hình Lượng Tử Hóa Qwen3 Là Gì?
Qwen3 là thế hệ LLM mới nhất từ Alibaba, được thiết kế cho hiệu suất cao trong các tác vụ như lập trình, toán học và suy luận chung. Các mô hình lượng tử hóa, chẳng hạn như ở định dạng BF16, FP8, GGUF, AWQ và GPTQ, giảm yêu cầu tính toán và bộ nhớ, khiến chúng trở nên lý tưởng để triển khai cục bộ trên phần cứng phổ thông.
Dòng Qwen3 bao gồm nhiều mô hình khác nhau:
- Qwen3-235B-A22B (MoE): Một mô hình hỗn hợp chuyên gia (mixture-of-experts) với định dạng BF16, FP8, GGUF và GPTQ-int4.
- Qwen3-30B-A3B (MoE): Một biến thể MoE khác với các tùy chọn lượng tử hóa tương tự.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Các mô hình dày đặc (dense) có sẵn ở định dạng BF16, FP8, GGUF, AWQ và GPTQ-int8.
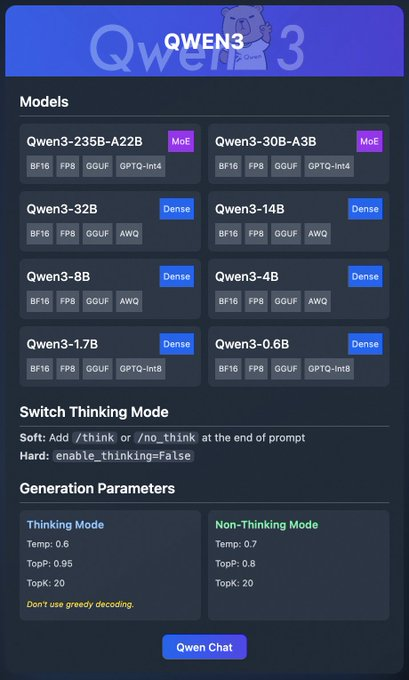
Các mô hình này hỗ trợ triển khai linh hoạt thông qua các nền tảng như Ollama, LM Studio và vLLM, mà chúng ta sẽ trình bày chi tiết. Ngoài ra, Qwen3 còn cung cấp các tính năng như "chế độ suy nghĩ" (thinking mode), có thể bật tắt để suy luận tốt hơn, và các tham số tạo sinh (generation parameters) để tinh chỉnh chất lượng đầu ra.
Giờ đây khi chúng ta đã hiểu những điều cơ bản, hãy chuyển sang các điều kiện tiên quyết để chạy Qwen3 cục bộ.
Các Điều Kiện Tiên Quyết để Chạy Qwen3 Cục bộ
Trước khi triển khai các mô hình lượng tử hóa Qwen3, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu sau:
Phần cứng:
- CPU hoặc GPU hiện đại (khuyến nghị sử dụng GPU NVIDIA cho vLLM).
- Ít nhất 16GB RAM cho các mô hình nhỏ hơn như Qwen3-4B; 32GB trở lên cho các mô hình lớn hơn như Qwen3-32B.
- Dung lượng lưu trữ đủ (ví dụ: Qwen3-235B-A22B GGUF có thể yêu cầu ~150GB).
Phần mềm:
- Hệ điều hành tương thích (Windows, macOS hoặc Linux).
- Python 3.8+ cho vLLM và tương tác API.
- Docker (tùy chọn, cho vLLM).
- Git để nhân bản kho lưu trữ.
Các Phụ Thuộc:
- Cài đặt các thư viện cần thiết như
torch,transformersvàvllm(cho vLLM). - Tải xuống các tệp nhị phân của Ollama hoặc LM Studio từ trang web chính thức của họ.
Với các điều kiện tiên quyết này, hãy tiến hành tải xuống các mô hình lượng tử hóa Qwen3.
Bước 1: Tải Xuống Các Mô Hình Lượng Tử Hóa Qwen3
Đầu tiên, bạn cần tải xuống các mô hình lượng tử hóa từ các nguồn đáng tin cậy. Nhóm Qwen cung cấp các mô hình Qwen3 trên Hugging Face và ModelScope
- Hugging Face: Bộ sưu tập Qwen3
- ModelScope: Bộ sưu tập Qwen3
Cách Tải Xuống từ Hugging Face
- Truy cập bộ sưu tập Qwen3 trên Hugging Face.
- Chọn một mô hình, chẳng hạn như Qwen3-4B ở định dạng GGUF để triển khai nhẹ nhàng.
- Nhấp vào nút "Download" hoặc sử dụng lệnh
git cloneđể lấy các tệp mô hình:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Lưu trữ các tệp mô hình trong một thư mục, chẳng hạn như
/models/qwen3-4b-gguf.
Cách Tải Xuống từ ModelScope
- Điều hướng đến bộ sưu tập Qwen3 trên ModelScope.
- Chọn mô hình và định dạng lượng tử hóa mong muốn của bạn (ví dụ: AWQ hoặc GPTQ).
- Tải xuống các tệp thủ công hoặc sử dụng API của họ để truy cập theo chương trình.
Sau khi các mô hình được tải xuống, hãy khám phá cách triển khai chúng bằng **Ollama**.
Bước 2: Triển Khai Qwen3 Sử Dụng Ollama
Ollama cung cấp một cách thân thiện với người dùng để chạy LLM cục bộ với thiết lập tối thiểu. Nó hỗ trợ định dạng GGUF của Qwen3, làm cho nó lý tưởng cho người mới bắt đầu.
Cài Đặt Ollama
- Truy cập trang web chính thức của Ollama và tải xuống tệp nhị phân cho hệ điều hành của bạn.
- Cài đặt Ollama bằng cách chạy trình cài đặt hoặc làm theo hướng dẫn dòng lệnh:
curl -fsSL https://ollama.com/install.sh | sh
- Xác minh cài đặt:
ollama --version
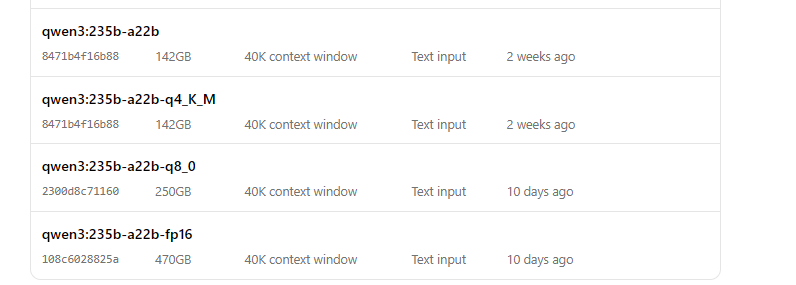
Chạy Qwen3 với Ollama
- Khởi động mô hình:
ollama run qwen3:235b-a22b-q8_0- Khi mô hình đang chạy, bạn có thể tương tác với nó qua dòng lệnh:
>>> Hello, how can I assist you today?
Ollama cũng cung cấp một điểm cuối **API** cục bộ (thường là http://localhost:11434) để truy cập theo chương trình, mà chúng ta sẽ kiểm tra sau bằng cách sử dụng **Apidog**.
Tiếp theo, hãy khám phá cách sử dụng **LM Studio** để chạy Qwen3.
Bước 3: Triển Khai Qwen3 Sử Dụng LM Studio
LM Studio là một công cụ phổ biến khác để chạy LLM cục bộ, cung cấp giao diện đồ họa để quản lý mô hình.
Cài Đặt LM Studio
- Tải xuống LM Studio từ trang web chính thức của nó.
- Cài đặt ứng dụng bằng cách làm theo hướng dẫn trên màn hình.
- Khởi chạy LM Studio và đảm bảo nó đang chạy.
Tải Qwen3 trong LM Studio
Trong LM Studio, đi tới phần "Local Models".
Nhấp vào "Add Model" và tìm kiếm mô hình để tải xuống:
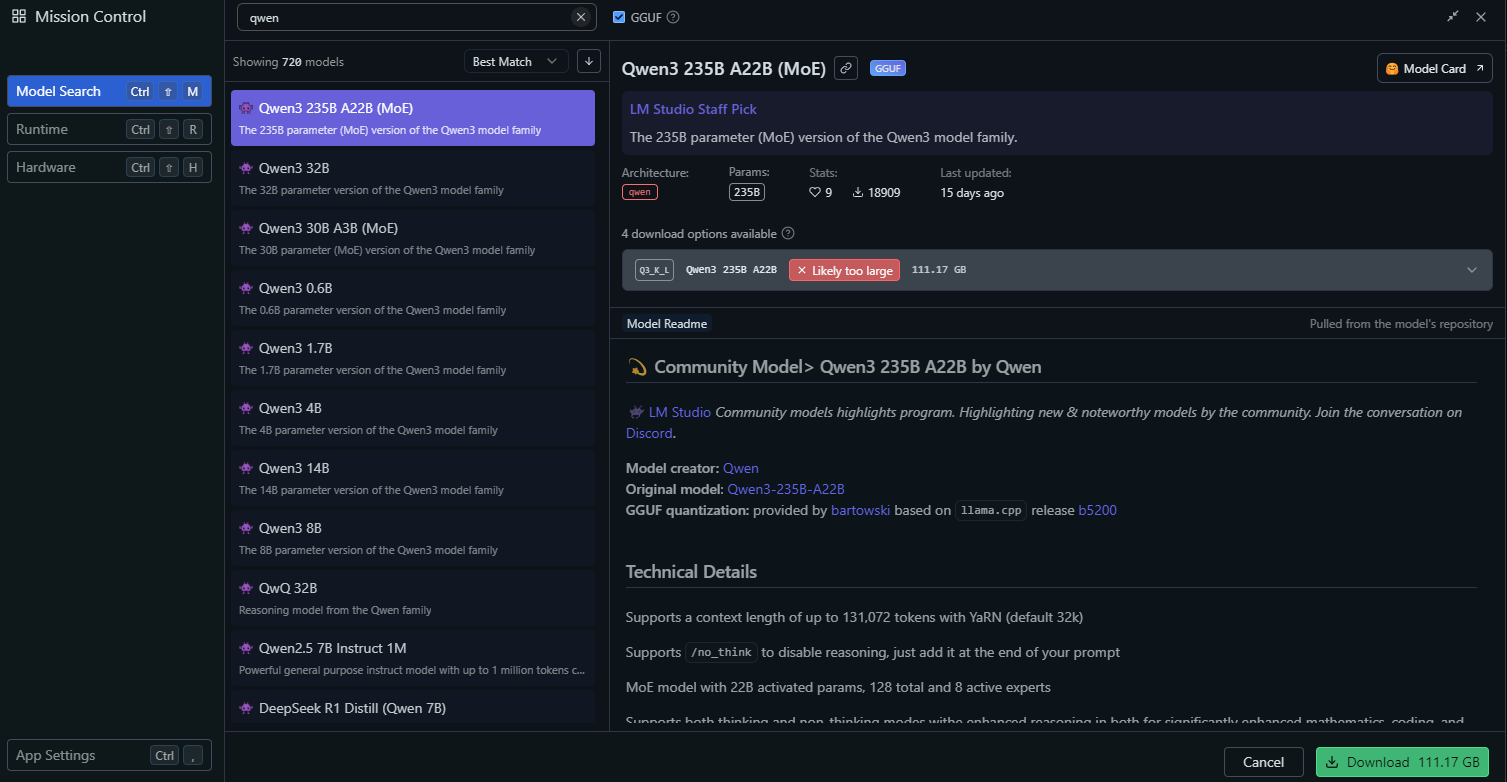
Cấu hình cài đặt mô hình, chẳng hạn như:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
Các cài đặt này khớp với các tham số chế độ suy nghĩ được khuyến nghị của Qwen3.
Khởi động máy chủ mô hình bằng cách nhấp vào "Start Server". LM Studio sẽ cung cấp một điểm cuối API cục bộ (ví dụ: http://localhost:1234).
Tương Tác với Qwen3 trong LM Studio
- Sử dụng giao diện trò chuyện tích hợp của LM Studio để kiểm tra mô hình.
- Ngoài ra, truy cập mô hình qua điểm cuối API của nó, mà chúng ta sẽ khám phá trong phần kiểm tra API.
Với LM Studio đã được thiết lập, hãy chuyển sang một phương pháp triển khai nâng cao hơn sử dụng **vLLM**.
Bước 4: Triển Khai Qwen3 Sử Dụng vLLM
vLLM là một giải pháp phục vụ hiệu suất cao được tối ưu hóa cho LLM, hỗ trợ các mô hình lượng tử hóa FP8 và AWQ của Qwen3. Nó lý tưởng cho các nhà phát triển xây dựng các ứng dụng mạnh mẽ.
Cài Đặt vLLM
- Đảm bảo Python 3.8+ được cài đặt trên hệ thống của bạn.
- Cài đặt vLLM bằng pip:
pip install vllm
- Xác minh cài đặt:
python -c "import vllm; print(vllm.__version__)"
Chạy Qwen3 với vLLM
Khởi động máy chủ vLLM với mô hình Qwen3 của bạn
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"Cờ `--enable-thinking=False` tắt chế độ suy nghĩ của Qwen3.
Khi máy chủ khởi động, nó sẽ cung cấp một điểm cuối **API** tại http://localhost:8000.
Cấu Hình vLLM để Đạt Hiệu Suất Tối Ưu
vLLM hỗ trợ các cấu hình nâng cao, chẳng hạn như:
- Tensor Parallelism: Điều chỉnh `--tensor-parallel-size` dựa trên thiết lập GPU của bạn.
- Context Length: Qwen3 hỗ trợ tối đa 32.768 token, có thể được đặt qua `--max-model-len 32768`.
- Generation Parameters: Sử dụng API để đặt `temperature`, `top_p` và `top_k` (ví dụ: 0.7, 0.8, 20 cho chế độ không suy nghĩ).
Với vLLM đang chạy, hãy kiểm tra điểm cuối API bằng cách sử dụng **Apidog**.
Bước 5: Kiểm Tra API Qwen3 với Apidog
Apidog là một công cụ mạnh mẽ để kiểm tra các điểm cuối API, khiến nó hoàn hảo để tương tác với mô hình Qwen3 được triển khai cục bộ của bạn.
Thiết Lập Apidog
- Tải xuống và cài đặt Apidog từ trang web chính thức.
- Khởi chạy Apidog và tạo một dự án mới.
Kiểm Tra API Ollama
- Tạo một yêu cầu API mới trong Apidog.
- Đặt điểm cuối thành
http://localhost:11434/api/generate. - Cấu hình yêu cầu:
- Phương thức: POST
- Nội dung (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Gửi yêu cầu và xác minh phản hồi.
Kiểm Tra API vLLM
- Tạo một yêu cầu API khác trong Apidog.
- Đặt điểm cuối thành
http://localhost:8000/v1/completions. - Cấu hình yêu cầu:
- Phương thức: POST
- Nội dung (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Gửi yêu cầu và kiểm tra đầu ra.
Apidog giúp bạn dễ dàng xác thực triển khai Qwen3 của mình và đảm bảo API hoạt động chính xác. Bây giờ, hãy tinh chỉnh hiệu suất của mô hình.
Bước 6: Tinh Chỉnh Hiệu Suất Qwen3
Để tối ưu hóa hiệu suất của Qwen3, hãy điều chỉnh các cài đặt sau dựa trên trường hợp sử dụng của bạn:
Chế Độ Suy Nghĩ
Qwen3 hỗ trợ "chế độ suy nghĩ" để tăng cường khả năng suy luận, như được nhấn mạnh trong hình ảnh bài đăng X. Bạn có thể kiểm soát nó theo hai cách:
- Chuyển đổi mềm: Thêm
/thinkhoặc/no_thinkvào lời nhắc của bạn.
- Ví dụ:
Solve this math problem /think.
- Chuyển đổi cứng: Tắt hoàn toàn chế độ suy nghĩ trong vLLM bằng
--enable-thinking=False.
Các Tham Số Tạo Sinh
Tinh chỉnh các tham số tạo sinh để có chất lượng đầu ra tốt hơn:
- Temperature: Sử dụng 0.6 cho chế độ suy nghĩ hoặc 0.7 cho chế độ không suy nghĩ.
- Top-P: Đặt thành 0.95 (suy nghĩ) hoặc 0.8 (không suy nghĩ).
- Top-K: Sử dụng 20 cho cả hai chế độ.
- Tránh giải mã tham lam (greedy decoding), theo khuyến nghị của nhóm Qwen.
Thử nghiệm với các cài đặt này để đạt được sự cân bằng mong muốn giữa sự sáng tạo và độ chính xác.
Khắc Phục Các Sự Cố Thường Gặp
Khi triển khai Qwen3, bạn có thể gặp một số vấn đề. Dưới đây là các giải pháp cho các sự cố thường gặp:
Mô Hình Không Tải Được trong Ollama:
- Đảm bảo đường dẫn tệp GGUF trong
Modelfilelà chính xác. - Kiểm tra xem hệ thống của bạn có đủ bộ nhớ để tải mô hình hay không.
Lỗi Song Song Tensor của vLLM:
- Nếu bạn thấy lỗi như "output_size is not divisible by weight quantization block_n," hãy giảm `--tensor-parallel-size` (ví dụ: xuống 4).
Yêu Cầu API Thất Bại trong Apidog:
- Xác minh rằng máy chủ (Ollama, LM Studio hoặc vLLM) đang chạy.
- Kiểm tra kỹ URL điểm cuối và tải trọng yêu cầu.
Bằng cách giải quyết các vấn đề này, bạn có thể đảm bảo trải nghiệm triển khai suôn sẻ.
Kết Luận
Chạy các mô hình lượng tử hóa **Qwen3** cục bộ là một quy trình đơn giản với các công cụ như **Ollama**, **LM Studio** và **vLLM**. Cho dù bạn là nhà phát triển xây dựng ứng dụng hay nhà nghiên cứu thử nghiệm LLM, Qwen3 đều cung cấp sự linh hoạt và hiệu suất bạn cần. Bằng cách làm theo hướng dẫn này, bạn đã học cách tải xuống các mô hình từ **Hugging Face** và **ModelScope**, triển khai chúng bằng nhiều framework khác nhau và kiểm tra các điểm cuối **API** của chúng với **Apidog**.
Hãy bắt đầu khám phá Qwen3 ngay hôm nay và khai phá sức mạnh của LLM cục bộ cho các dự án của bạn!