
Trong bối cảnh phát triển nhanh chóng của các mô hình ngôn ngữ lớn, Llama Nemotron Ultra 253B của NVIDIA nổi bật như một cỗ máy mạnh mẽ cho các doanh nghiệp đang tìm kiếm khả năng suy luận tiên tiến. Hướng dẫn toàn diện này xem xét các tiêu chuẩn ấn tượng của mô hình, so sánh nó với các mô hình mã nguồn mở hàng đầu khác, và cung cấp các bước rõ ràng để triển khai API của nó trong các ứng dụng của bạn.
Tiêu chuẩn llama-3.1-nemotron-ultra-253b
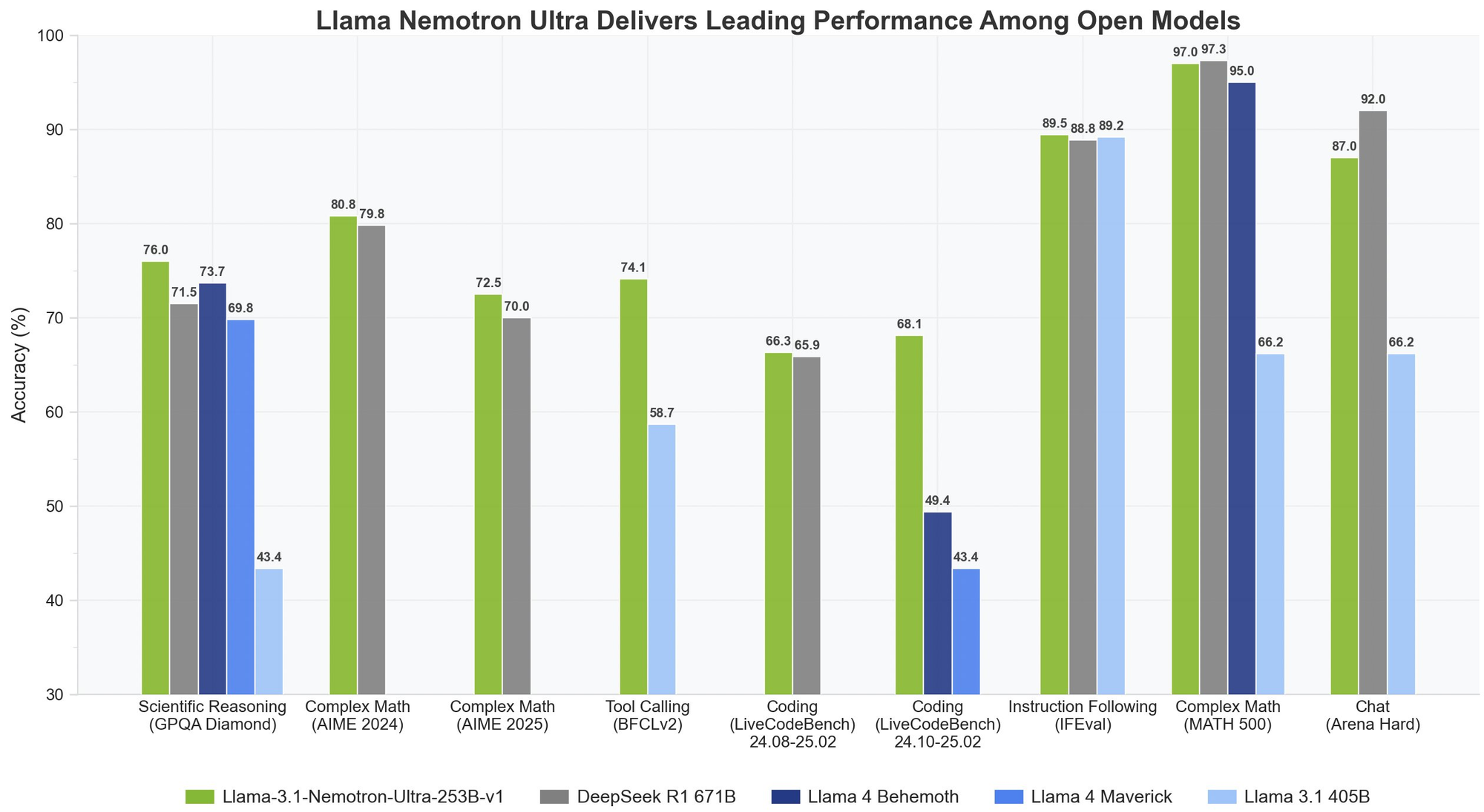
Llama Nemotron Ultra 253B mang lại kết quả xuất sắc trên các tiêu chuẩn suy luận và tác nhân quan trọng, với khả năng "Suy luận BẬT/TẮT" độc đáo cho thấy sự khác biệt về hiệu suất:
Suy luận Toán học
Llama Nemotron Ultra 253B thực sự nổi bật trong các nhiệm vụ suy luận toán học:
- MATH500
- Suy luận TẮT: 80.4% pass@1
- Suy luận BẬT: 97.0% pass@1
Với độ chính xác 97% khi Suy luận BẬT, Llama Nemotron Ultra 253B gần như hoàn hảo trong tiêu chuẩn toán học thách thức này.
- AIME25 (Kỳ thi Toán học Quốc tế Hoa Kỳ)
- Suy luận TẮT: 16.7% pass@1
- Suy luận BẬT: 72.50% pass@1
Sự cải thiện đáng kể 56 điểm này cho thấy khả năng suy luận của Llama Nemotron Ultra 253B đã biến đổi hiệu suất của nó trên các bài toán toán học phức tạp.
Suy luận Khoa học
- GPQA (Câu hỏi và Đáp án Vật lý cấp Cao học)
- Suy luận TẮT: 56.6% pass@1
- Suy luận BẬT: 76.01% pass@1
Sự cải thiện đáng kể này cho thấy Llama Nemotron Ultra 253B có thể giải quyết các bài toán vật lý cấp cao thông qua phân tích có phương pháp khi suy luận được kích hoạt.
Lập trình và Sử dụng Công cụ
- LiveCodeBench (20240801-20250201)
- Suy luận TẮT: 29.03% pass@1
- Suy luận BẬT: 66.31% pass@1
Llama Nemotron Ultra 253B gấp đôi hiệu suất mã hóa khi suy luận được kích hoạt.
- BFCL V2 Live (Gọi Hàm)
- Suy luận TẮT: 73.62 điểm
- Suy luận BẬT: 74.10 điểm
Tiêu chuẩn này cho thấy khả năng sử dụng công cụ mạnh mẽ của mô hình ở cả hai chế độ, rất quan trọng cho việc xây dựng các tác nhân AI hiệu quả.
Theo dõi Hướng dẫn
- IFEval (Đánh giá Theo dõi Hướng dẫn)
- Suy luận TẮT: 88.85% độ chính xác nghiêm ngặt
- Suy luận BẬT: 89.45% độ chính xác nghiêm ngặt
Cả hai chế độ đều hoạt động xuất sắc, cho thấy Llama Nemotron Ultra 253B duy trì khả năng theo dõi hướng dẫn mạnh mẽ không phụ thuộc vào chế độ suy luận.
Llama Nemotron Ultra 253B so với DeepSeek-R1
DeepSeek-R1 đã là tiêu chuẩn vàng cho các mô hình suy luận mã nguồn mở, nhưng Llama Nemotron Ultra 253B phù hợp hoặc vượt trội hiệu suất của nó trên các tiêu chuẩn suy luận chính:
- Trên GPQA, Llama Nemotron Ultra 253B đạt 76.01% độ chính xác, cạnh tranh với hiệu suất hàng đầu của DeepSeek-R1
- Llama Nemotron Ultra 253B cung cấp hai chế độ suy luận, khác với cách tiếp cận suy luận cố định của DeepSeek-R1
- Llama Nemotron Ultra 253B cung cấp khả năng gọi hàm vượt trội, làm cho nó linh hoạt hơn cho các ứng dụng tác nhân
Llama Nemotron Ultra 253B so với Llama 4
Khi so sánh với các mô hình Behemoth và Maverick sắp ra mắt:
- Llama Nemotron Ultra 253B thể hiện hiệu suất vượt trội trên các tiêu chuẩn suy luận khoa học và phức tạp
- Công tắc suy luận rõ ràng trong Llama Nemotron Ultra 253B cung cấp tính linh hoạt hơn so với các mô hình Llama 4 tiêu chuẩn
- Llama Nemotron Ultra 253B được tối ưu hóa đặc biệt cho phần cứng NVIDIA, cung cấp hiệu suất suy luận tốt hơn
Hãy kiểm tra Llama Nemotron Ultra 253B qua API
Triển khai Llama Nemotron Ultra 253B trong các ứng dụng của bạn yêu cầu thực hiện các bước cụ thể để đảm bảo hiệu suất tối ưu:
Bước 1: Nhận quyền truy cập API
Để truy cập Llama Nemotron Ultra 253B:
- Truy cập cổng thông tin API của NVIDIA tại https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Đăng ký để nhận khóa API nếu bạn chưa có
- Nếu chạy trong môi trường NGC của NVIDIA, việc cấu hình khóa API có thể được đơn giản hóa
Bước 2: Thiết lập môi trường phát triển của bạn
Trước khi thực hiện các cuộc gọi API:
- Cài đặt gói OpenAI Python bằng cách sử dụng
pip install openai - Nhập thư viện cần thiết:
from openai import OpenAI - Cấu hình môi trường của bạn để lưu trữ an toàn khóa API
Bước 3: Cấu hình khách hàng API
Khởi tạo khách hàng OpenAI với các điểm cuối của NVIDIA:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "KHÓA_API_CỦA_BẠN_TẠI_ĐÂY"
)

- Khác với Postman, Apidog cung cấp trải nghiệm tích hợp hơn với tài liệu API tích hợp sẵn, thử nghiệm tự động và các máy chủ giả lập được tối ưu hóa đặc biệt cho các điểm cuối mô hình AI.
- Giao diện trực quan của Apidog giúp dễ dàng cấu hình các bộ tham số phức tạp cần thiết cho việc thử nghiệm API, và các tính năng trực quan hóa phản hồi đặc biệt hữu ích cho việc phân tích đầu ra stream của mô hình.
- Trong khi Postman vẫn là một công cụ thử nghiệm API đa năng phổ biến, các tính năng tập trung vào AI và quy trình làm việc hiệu quả của Apidog có thể tăng tốc đáng kể quá trình phát triển của bạn.

Bước 4: Xác định chế độ suy luận phù hợp
Llama Nemotron Ultra 253B cung cấp hai chế độ hoạt động khác nhau:
- Suy luận BẬT: Tốt nhất cho các vấn đề phức tạp yêu cầu suy nghĩ từng bước (toán, vật lý, lập trình)
- Suy luận TẮT: Tối ưu cho việc theo dõi hướng dẫn đơn giản và trò chuyện chung
Bước 5: Tạo các nhắc nhở hệ thống và người dùng của bạn
Đối với chế độ Suy luận BẬT:
- Đặt nhắc nhở hệ thống thành
"suy nghĩ chi tiết" - Đặt tất cả hướng dẫn trong tin nhắn người dùng
- Xem xét sử dụng các mẫu cụ thể cho các nhiệm vụ đã được tiêu chuẩn hóa (như bài toán toán học)
Đối với chế độ Suy luận TẮT:
- Loại bỏ nhắc nhở hệ thống suy luận
- Sử dụng hướng dẫn ngắn gọn, rõ ràng trong tin nhắn người dùng
Bước 6: Cấu hình các tham số tạo ra
Để có kết quả tối ưu:
- Suy luận BẬT: Đặt temperature=0.6 và top_p=0.95 như được khuyến nghị bởi NVIDIA
- Suy luận TẮT: Sử dụng mã hóa tham lam với temperature=0
- Đặt giá trị
max_tokensphù hợp dựa trên độ dài phản hồi mong đợi - Xem xét kích hoạt tính năng streaming cho phản hồi thời gian thực
Bước 7: Thực hiện yêu cầu API và xử lý phản hồi
Tạo yêu cầu hoàn thành của bạn với tất cả các tham số đã được cấu hình:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "suy nghĩ chi tiết"},
{"role": "user", "content": "Nhắc nhở của bạn ở đây"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Bước 8: Xử lý và hiển thị phản hồi
Nếu sử dụng tính năng streaming:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Đối với các phản hồi không phải streaming, chỉ cần truy cập completion.choices[0].message.content.
Kết luận
Llama Nemotron Ultra 253B đại diện cho một bước tiến quan trọng trong các mô hình suy luận mã nguồn mở, mang lại hiệu suất hàng đầu trên nhiều tiêu chuẩn. Hai chế độ suy luận độc đáo của nó, kết hợp với khả năng gọi hàm xuất sắc và một cửa sổ ngữ cảnh lớn, khiến nó trở thành lựa chọn lý tưởng cho các ứng dụng AI doanh nghiệp yêu cầu khả năng suy luận tiên tiến.
Với hướng dẫn triển khai API từng bước được nêu trong bài viết này, các nhà phát triển có thể khai thác tối đa tiềm năng của Llama Nemotron Ultra 253B để xây dựng các hệ thống AI tinh vi giải quyết các vấn đề phức tạp với khả năng suy luận giống như con người. Cho dù là xây dựng các tác nhân AI, nâng cao hệ thống RAG, hay phát triển các ứng dụng chuyên biệt, Llama Nemotron Ultra 253B cung cấp một nền tảng mạnh mẽ cho khả năng AI thế hệ tiếp theo trong một gói mã nguồn mở thân thiện với thương mại.