
Bạn đang tìm cách triển khai Deepseek R1 —một trong những mô hình ngôn ngữ lớn mạnh mẽ nhất—trên nền tảng đám mây? Dù bạn đang làm việc trên AWS, Azure hay Digital Ocean, hướng dẫn này sẽ giúp bạn. Cuối bài viết này, bạn sẽ có một lộ trình rõ ràng để đưa mô hình Deepseek R1 của bạn vào hoạt động dễ dàng. Thêm vào đó, chúng tôi sẽ chỉ cho bạn cách các công cụ như Apidog có thể giúp đơn giản hóa việc kiểm thử API trong quá trình triển khai.
Tại Sao Triển Khai Deepseek R1 Trên Đám Mây?
Việc triển khai Deepseek R1 trên đám mây không chỉ về khả năng mở rộng; mà còn là việc tận dụng sức mạnh của GPU và cơ sở hạ tầng không máy chủ để xử lý các khối lượng công việc lớn một cách hiệu quả. Với 671B tham số, Deepseek R1 đòi hỏi phần cứng mạnh mẽ và các cấu hình tối ưu. Đám mây cung cấp sự linh hoạt, tiết kiệm chi phí và tài nguyên hiệu suất cao làm cho việc triển khai các mô hình như vậy trở nên khả thi ngay cả cho các đội nhỏ hơn.
Trong hướng dẫn này, chúng tôi sẽ hướng dẫn bạn triển khai Deepseek R1 trên ba nền tảng phổ biến: AWS, Azure và Digital Ocean. Chúng tôi cũng sẽ chia sẻ các mẹo để tối ưu hóa hiệu suất và tích hợp các công cụ như Apidog cho quản lý API.
Chuẩn Bị Môi Trường Của Bạn
Trước khi đi vào triển khai, hãy chuẩn bị môi trường của bạn. Điều này liên quan đến việc thiết lập mã thông báo xác thực, đảm bảo khả dụng của GPU và tổ chức các tệp của bạn.
Mã Thông Báo Xác Thực
Mỗi nhà cung cấp đám mây yêu cầu một số hình thức xác thực. Ví dụ:
- Trên AWS , bạn sẽ cần một vai trò IAM với quyền truy cập vào các vùng chứa S3 và các phiên bản EC2.
- Trên Azure , bạn có thể sử dụng các trải nghiệm xác thực đơn giản hóa do Azure Machine Learning SDK cung cấp.
- Trên Digital Ocean , tạo một mã thông báo API từ bảng điều khiển tài khoản của bạn.
Các mã thông báo này rất quan trọng vì chúng cho phép giao tiếp an toàn giữa máy tính của bạn và nền tảng đám mây.
Tổ Chức Tệp
Tổ chức các tệp của bạn một cách có hệ thống. Nếu bạn đang sử dụng Docker (điều này được khuyến nghị cao), hãy tạo một Dockerfile chứa tất cả các phụ thuộc. Các công cụ như Tensorfuse cung cấp các mẫu đã được xây dựng sẵn cho việc triển khai Deepseek R1. Tương tự, người dùng IBM Cloud nên tải lên các tệp mô hình của họ lên Object Storage trước khi tiếp tục.
Tùy Chọn 1: Triển Khai Deepseek R1 Trên AWS Sử Dụng Tensorfuse
Hãy bắt đầu với Dịch vụ Web Amazon (AWS), một trong những nền tảng đám mây được sử dụng rộng rãi nhất. AWS giống như dao Thụy Sĩ—nó có công cụ cho mọi nhiệm vụ, từ lưu trữ đến sức mạnh tính toán. Trong phần này, chúng tôi sẽ tập trung vào việc triển khai Deepseek R1 sử dụng Tensorfuse, giúp đơn giản hóa quá trình này đáng kể.
Tại Sao Xây Dựng Với Deepseek-R1?
Trước khi đi vào chi tiết kỹ thuật, hãy hiểu tại sao Deepseek R1 lại nổi bật:
- Hiệu Suất Cao Trong Đánh Giá: Đạt được kết quả mạnh mẽ trên các tiêu chuẩn ngành, ghi điểm 90,8% trên MMLU và 79,8% trên AIME 2024.
- Lập Luận Nâng Cao: Xử lý các tác vụ lập luận logic nhiều bước với ngữ cảnh tối thiểu, xuất sắc trong các tiêu chuẩn như LiveCodeBench (Pass@1-COT) với điểm số 65,9%.
- Hỗ Trợ Đa Ngôn Ngữ: Được đào tạo trước trên dữ liệu ngôn ngữ đa dạng, giúp nó thành thạo trong việc hiểu đa ngôn ngữ.
- Các Mô Hình Chưng Cất Có Thể Mở Rộng: Các biến thể nhỏ hơn (2B, 7B và 70B) cung cấp các tùy chọn rẻ hơn mà không làm giảm chi phí.
Các điểm mạnh này khiến Deepseek R1 trở thành một lựa chọn tuyệt vời cho các ứng dụng sẵn sàng sản xuất, từ chatbot đến phân tích dữ liệu cấp doanh nghiệp.
Yêu Cầu Trước Khi Bắt Đầu
Trước khi bạn bắt đầu, hãy đảm bảo bạn đã cấu hình Tensorfuse trên tài khoản AWS của mình. Nếu bạn chưa làm điều đó, hãy làm theo hướng dẫn Bắt đầu. Thiết lập này giống như chuẩn bị không gian làm việc của bạn trước khi bắt đầu một dự án—nó đảm bảo mọi thứ đã sẵn sàng cho một quá trình suôn sẻ.
Bước 1: Đặt Mã Thông Báo Xác Thực API Của Bạn
Tạo một chuỗi ngẫu nhiên sẽ được sử dụng làm mã thông báo xác thực API của bạn. Lưu nó như một bí mật trong Tensorfuse bằng lệnh sau:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
Đảm bảo rằng trong môi trường sản xuất, bạn sử dụng mã thông báo được tạo ngẫu nhiên. Bạn có thể nhanh chóng tạo một cái bằng cách sử dụng openssl rand -base64 32 và nhớ giữ nó an toàn vì các bí mật Tensorfuse là mờ.
Bước 2: Chuẩn Bị Dockerfile
Chúng tôi sẽ sử dụng hình ảnh chính thức vLLM OpenAI làm hình ảnh cơ sở của chúng tôi. Hình ảnh này đi kèm với tất cả các phụ thuộc cần thiết để chạy vLLM.
Dưới đây là cấu hình Dockerfile:
# Dockerfile cho Deepseek-R1-671B
FROM vllm/vllm-openai:latest
# Kích hoạt Chuyển Nhượng HF Hub
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# Công khai cổng 80
EXPOSE 80
# Entrypoint với mã API
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
Cấu hình này đảm bảo rằng máy chủ vLLM được tối ưu hóa cho các yêu cầu cụ thể của Deepseek R1, bao gồm việc sử dụng bộ nhớ GPU và song song tensor.
Bước 3: Cấu Hình Triển Khai
Tạo một tệp deployment.yaml để xác định các cài đặt triển khai của bạn:
# deployment.yaml cho Deepseek-R1-671B
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
Triển khai dịch vụ của bạn bằng lệnh sau:
tensorkube deploy --config-file ./deployment.yaml
Lệnh này thiết lập một dịch vụ LLM sản xuất tự động mở rộng sẵn sàng phục vụ các yêu cầu đã xác thực.
Bước 4: Truy Cập Ứng Dụng Được Triển Khai
Ngay khi triển khai thành công, bạn có thể thử nghiệm điểm cuối của mình bằng cách sử dụng curl hoặc thư viện khách hàng OpenAI của Python. Dưới đây là một ví dụ sử dụng curl:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Trái đất tới Robotland. Có chuyện gì vậy?",
"max_tokens": 200
}'
Đối với người dùng Python, dưới đây là một đoạn mã mẫu:
import openai
# Thay thế bằng URL và mã thông báo thực tế của bạn
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="Xin chào, Deepseek R1! Bạn hôm nay thế nào?",
max_tokens=200
)
print(response)
Tùy Chọn 2: Triển Khai Deepseek R1 Trên Azure
Triển khai Deepseek R1 trên Azure Machine Learning (Azure ML) là một quy trình đơn giản hóa tận dụng cơ sở hạ tầng mạnh mẽ và các công cụ tiên tiến của nền tảng cho suy luận thời gian thực. Trong phần này, chúng tôi sẽ hướng dẫn bạn triển khai Deepseek R1 sử dụng Các Điểm Cuối Trực Tuyến Được Quản Lý của Azure ML. Cách tiếp cận này đảm bảo khả năng mở rộng, hiệu quả và dễ quản lý.
Bước 1: Tạo Môi Trường Tùy Chỉnh cho vLLM trên Azure ML
Để bắt đầu, chúng tôi cần tạo một môi trường tùy chỉnh phù hợp cho vLLM, sẽ phục vụ như xương sống cho việc triển khai Deepseek R1. Khung vLLM được tối ưu hóa cho suy luận hiệu năng cao, điều này làm cho nó lý tưởng cho việc xử lý các mô hình ngôn ngữ lớn như Deepseek R1.
1.1: Định nghĩa Dockerfile : Chúng tôi sẽ bắt đầu bằng cách tạo một Dockerfile xác định môi trường cho mô hình của chúng tôi. Bộ chứa vLLM bao gồm tất cả các phụ thuộc và trình điều khiển cần thiết, đảm bảo một thiết lập suôn sẻ:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
Dockerfile này cho phép chúng tôi truyền tên mô hình qua một biến môi trường (MODEL_NAME), cho phép tính linh hoạt trong việc chọn mô hình mong muốn trong quá trình triển khai. Ví dụ, bạn có thể dễ dàng chuyển đổi giữa các phiên bản khác nhau của Deepseek R1 mà không cần thay đổi mã cơ bản.
1.2: Đăng Nhập Vào Azure ML Workspace: Tiếp theo, hãy đăng nhập vào không gian làm việc Azure ML của bạn bằng cách sử dụng Azure CLI. Thay thế <subscription ID>, <Azure Machine Learning workspace name> và <resource group> bằng các chi tiết cụ thể của bạn:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Bước này đảm bảo rằng tất cả các lệnh tiếp theo được thực hiện trong ngữ cảnh của không gian làm việc của bạn.
1.3: Tạo Tệp Cấu Hình Môi Trường: Bây giờ, hãy tạo một tệp environment.yml để xác định các cài đặt môi trường. Tệp này tham chiếu đến Dockerfile mà chúng tôi đã tạo trước đó:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: Xây Dựng Môi Trường: Với tệp cấu hình đã sẵn sàng, hãy xây dựng môi trường bằng lệnh sau:
az ml environment create -f environment.yml
Bước này biên dịch môi trường, làm cho nó có sẵn để sử dụng trong triển khai của bạn.
Bước 2: Triển Khai Điểm Cuối Trực Tuyến Được Quản Lý Azure ML
Khi môi trường đã được thiết lập, chúng tôi tiếp tục triển khai mô hình Deepseek R1 bằng cách sử dụng Các Điểm Cuối Trực Tuyến Được Quản Lý của Azure ML. Những điểm cuối này cung cấp khả năng suy luận thời gian thực có thể mở rộng, làm cho chúng trở nên hoàn hảo cho các ứng dụng cấp sản xuất.
2.1: Tạo Tệp Cấu Hình Điểm Cuối: Bắt đầu bằng cách tạo một tệp endpoint.yml để xác định Điểm Cuối Trực Tuyến Được Quản Lý:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
Cấu hình này xác định tên của điểm cuối (r1-prod) và chế độ xác thực (key). Bạn có thể lấy URI của điểm cuối và khóa API sau đó để kiểm tra.
2.2: Tạo Điểm Cuối: Sử dụng lệnh sau để tạo điểm cuối:
az ml online-endpoint create -f endpoint.yml
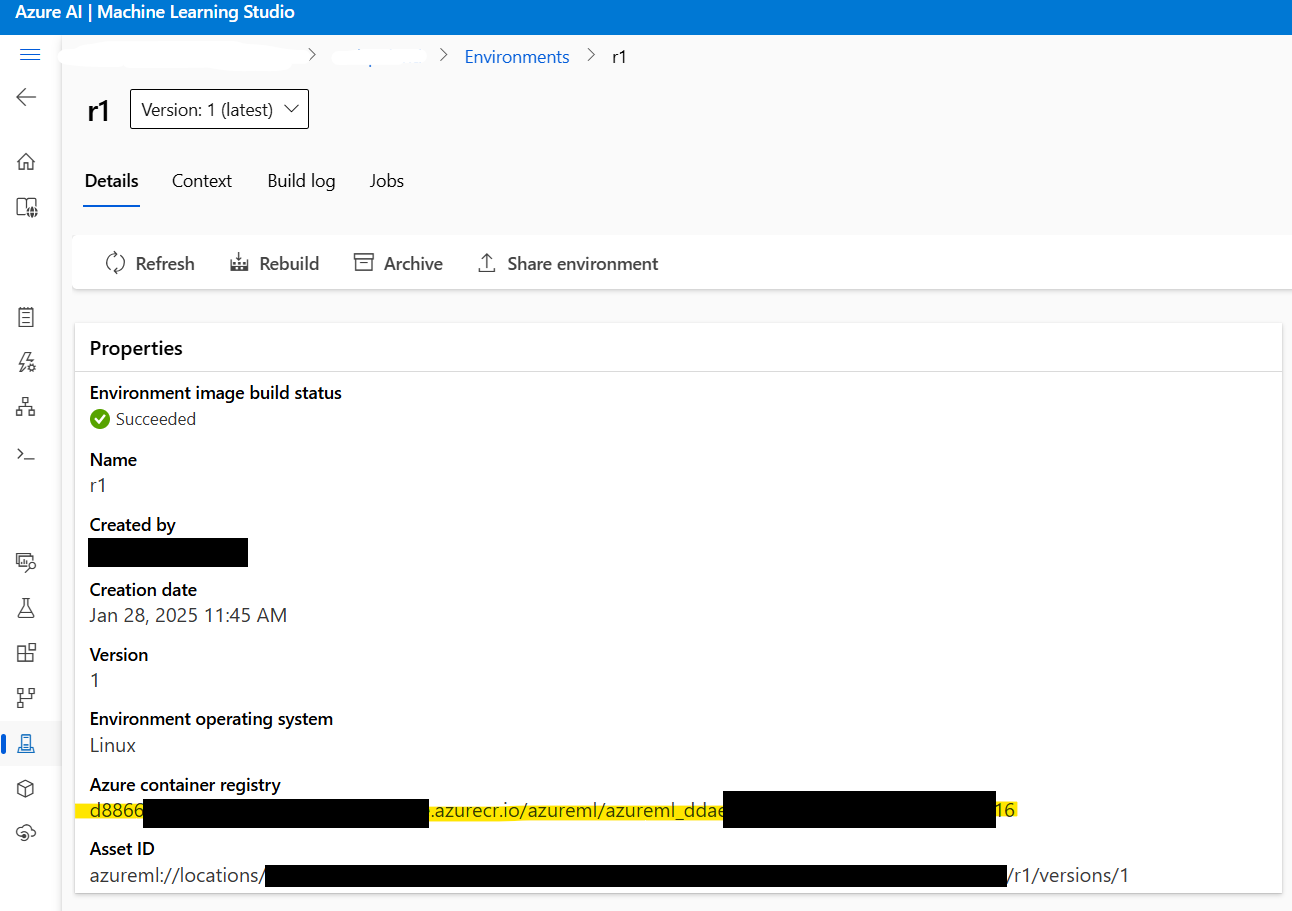
2.3: Lấy Địa Chỉ Hình Ảnh Docker: Trước khi tiếp tục, hãy lấy địa chỉ của hình ảnh Docker được tạo trong Bước 1. Điều hướng đến Azure ML Studio > Environments > r1 để tìm địa chỉ hình ảnh. Nó sẽ trông giống như thế này:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
2.4: Tạo Tệp Cấu Hình Triển Khai: Tiếp theo, tạo một tệp deployment.yml để cấu hình cài đặt triển khai. Tệp này xác định mô hình, loại mẫu và các tham số khác:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # Tham số tùy chọn cho thời gian chạy vLLM
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # Dán địa chỉ hình ảnh Docker tại đây
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # Tùy chọn nhưng quan trọng để tối ưu hóa thông lượng
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # Chờ 120 giây trước khi kiểm tra, cho phép mô hình tải một cách bình yên
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Các tham số chính cần xem xét:
instance_count: Xác định số lượng nútStandard_NC24ads_A100_v4sẽ được khởi động. Tăng giá trị này sẽ mở rộng thông lượng theo cách tuyến tính nhưng cũng làm tăng chi phí.max_concurrent_requests_per_instance: Kiểm soát số yêu cầu đồng thời được phép trên mỗi phiên bản. Giá trị cao hơn làm tăng thông lượng nhưng có thể làm tăng độ trễ.request_timeout_ms: Xác định thời gian tối đa (tính bằng mili giây) mà điểm cuối sẽ chờ phản hồi trước khi hết thời gian. Điều chỉnh điều này dựa trên yêu cầu khối lượng công việc của bạn.
2.5: Triển Khai Mô Hình: Cuối cùng, triển khai mô hình Deepseek R1 bằng lệnh sau:
az ml online-deployment create -f deployment.yml --all-traffic
Bước này hoàn tất việc triển khai, làm cho mô hình có thể truy cập qua điểm cuối đã chỉ định.
Bước 3: Kiểm Tra Việc Triển Khai
Ngay khi việc triển khai hoàn tất, đã đến lúc kiểm tra điểm cuối để đảm bảo mọi thứ hoạt động như mong đợi.
3.1: Lấy Chi Tiết Điểm Cuối: Sử dụng các lệnh sau để lấy URI điểm số của điểm cuối và khóa API:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: Phát Nhạc Các Phản Hồi Sử Dụng SDK OpenAI: Để phát nhạc các phản hồi, bạn có thể sử dụng SDK OpenAI:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "Cái nào tốt hơn, mùa hè hay mùa đông?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Bước 4: Giám Sát và Tự Động Mở Rộng
Azure Monitor cung cấp cái nhìn tổng thể về việc sử dụng tài nguyên, bao gồm các chỉ số GPU. Khi chịu tải liên tục, bạn sẽ thấy rằng vLLM tiêu tốn khoảng 90% bộ nhớ GPU, với sự sử dụng GPU gần 100%. Các chỉ số này giúp bạn tinh chỉnh hiệu suất và tối ưu hóa chi phí.
Để kích hoạt tự động mở rộng, hãy cấu hình các chính sách mở rộng dựa trên các mô hình lưu lượng. Ví dụ, bạn có thể tăng instance_count trong giờ cao điểm và giảm nó trong các khoảng thời gian thấp điểm để cân bằng hiệu suất và chi phí.
Tùy Chọn 3: Triển Khai Deepseek R1 Trên Digital Ocean
Cuối cùng, hãy thảo luận về việc triển khai Deepseek R1 trên Digital Ocean , nổi tiếng với sự đơn giản và giá cả phải chăng.
Các Yêu Cầu Trước Khi Bắt Đầu
Trước khi bắt tay vào quá trình triển khai, hãy đảm bảo bạn có tất cả những gì bạn cần:
- Tài Khoản DigitalOcean: Nếu bạn chưa có, hãy đăng ký tài khoản DigitalOcean. Người dùng mới nhận được một khoản tín dụng 100 đô la cho 60 ngày đầu tiên, điều này hoàn hảo để thử nghiệm với các giọt được tăng cường bởi GPU.
- Quen Thuộc Với Bash Shell: Bạn sẽ sử dụng terminal để tương tác với giọt của mình, tải xuống các phụ thuộc và thực hiện các lệnh. Đừng lo lắng nếu bạn không phải là một chuyên gia—mỗi lệnh sẽ được cung cấp từng bước.
- Giọt GPU: DigitalOcean hiện cung cấp các giọt GPU được thiết kế đặc biệt cho khối lượng công việc AI/ML. Các giọt này được trang bị GPU NVIDIA H100, làm cho chúng lý tưởng cho việc triển khai các mô hình lớn như Deepseek R1.
Với các yêu cầu trước khi bắt đầu này, bạn đã sẵn sàng để tiến về phía trước.
Thiết Lập Giọt GPU
Bước đầu tiên là thiết lập máy của bạn. Hãy nghĩ về điều này như chuẩn bị canvas trước khi vẽ—bạn muốn mọi thứ sẵn sàng trước khi đi vào chi tiết.
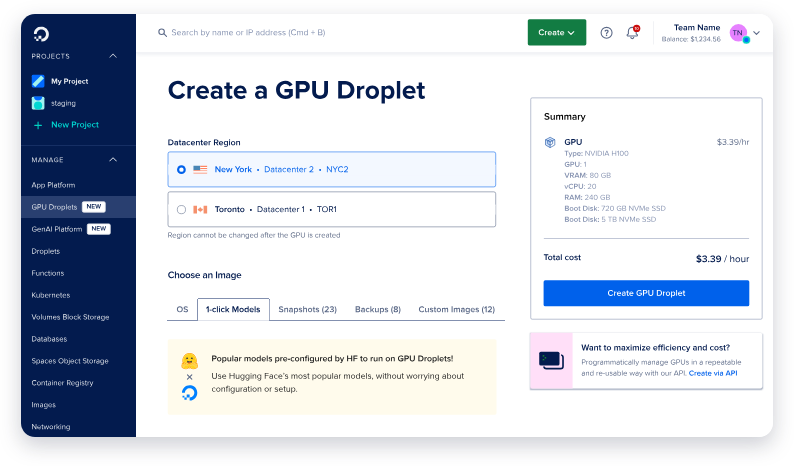
Bước 1: Tạo Một Giọt GPU Mới
- Đăng nhập vào tài khoản DigitalOcean của bạn và điều hướng đến mục Giọt.
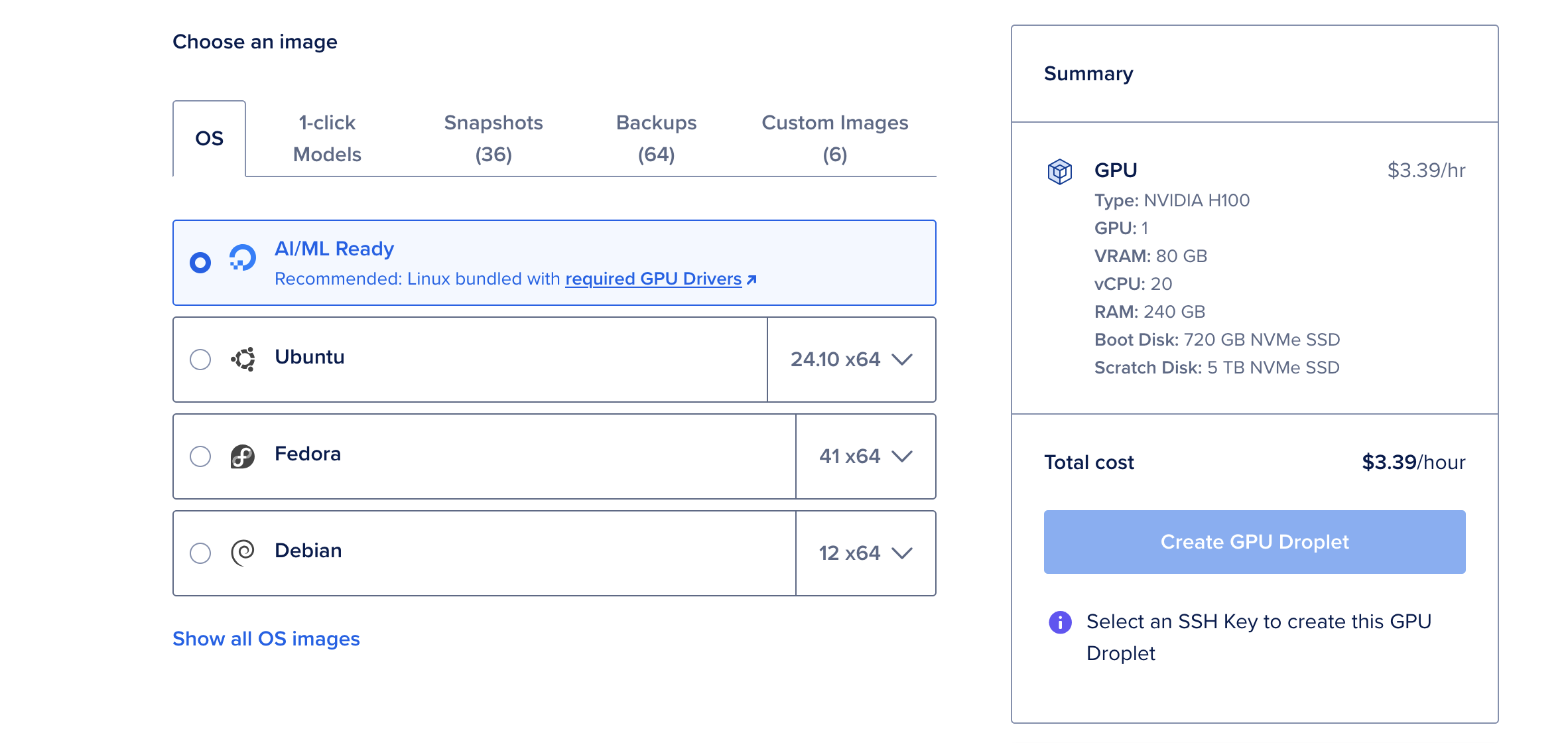
- Nhấp vào Tạo Giọt và chọn hệ điều hành sẵn sàng cho AI/ML. Hệ điều hành này đã được cấu hình trước với các trình điều khiển CUDA và các phụ thuộc khác cần thiết cho tăng tốc GPU.
- Chọn một GPU NVIDIA H100 đơn lẻ trừ khi bạn có kế hoạch triển khai phiên bản tham số 671B lớn nhất của Deepseek R1, điều này có thể yêu cầu nhiều GPU.
- Khi giọt của bạn được tạo, hãy đợi nó khởi động. Quá trình này thường chỉ mất vài phút.
Tại Sao Chọn GPU H100?
GPU NVIDIA H100 là một cỗ máy mạnh mẽ, cung cấp 80GB vRAM, 240GB RAM và 720GB dung lượng lưu trữ. Với giá 6,47 USD mỗi giờ, nó là một lựa chọn tiết kiệm chi phí cho việc triển khai các mô hình ngôn ngữ lớn như Deepseek R1. Đối với các mô hình nhỏ hơn, chẳng hạn như phiên bản tham số 70B, một GPU H100 là đủ.
Cài Đặt Ollama & Deepseek R1
Bây giờ giọt GPU của bạn đã hoạt động, đã đến lúc cài đặt các công cụ cần thiết để chạy Deepseek R1. Chúng tôi sẽ sử dụng Ollama, một khung nhẹ được thiết kế để đơn giản hóa việc triển khai các mô hình ngôn ngữ lớn.
Bước 1: Mở Bảng Điều Khiển Web
Từ trang chi tiết giọt của bạn, nhấp vào nút Bảng Điều Khiển Web nằm ở góc trên bên phải. Điều này mở một cửa sổ terminal trực tiếp trong trình duyệt của bạn, loại bỏ nhu cầu cấu hình SSH.
Bước 2: Cài Đặt Ollama
Trong terminal, dán lệnh sau để cài đặt Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Script này tự động hóa quá trình cài đặt, tải xuống và cấu hình tất cả các phụ thuộc cần thiết. Việc cài đặt có thể mất vài phút, nhưng khi hoàn tất, máy của bạn sẽ sẵn sàng để chạy Deepseek R1.
Bước 3: Chạy Deepseek R1
Với Ollama đã được cài đặt, việc chạy Deepseek R1 dễ dàng như chạy một lệnh duy nhất. Đối với cuộc thử nghiệm này, chúng tôi sẽ sử dụng phiên bản tham số 70B, phù hợp giữa hiệu suất và sử dụng tài nguyên:
ollama run deepseek-r1:70b
Lần đầu tiên bạn chạy lệnh này, nó sẽ tải mô hình (khoảng 40GB) và tải nó vào bộ nhớ. Quá trình này có thể mất vài phút, nhưng các lần chạy tiếp theo sẽ nhanh hơn nhiều vì mô hình được lưu vào bộ nhớ đệm cục bộ.
Ngay khi mô hình được tải, bạn sẽ thấy một dấu nhắc tương tác nơi bạn có thể bắt đầu tương tác với Deepseek R1. Nó giống như có một cuộc trò chuyện với một trợ lý thông minh!
Kiểm Tra và Giám Sát Với Apidog
Ngay khi mô hình Deepseek R1 của bạn được triển khai, đã đến lúc kiểm tra và giám sát hiệu suất của nó. Đây chính là lúc Apidog tỏa sáng.
Apidog Là Gì?
Apidog là một công cụ kiểm thử API mạnh mẽ được thiết kế để đơn giản hóa việc gỡ lỗi và xác thực. Với giao diện trực quan, bạn có thể nhanh chóng tạo các trường hợp kiểm thử, mô phỏng các phản hồi và giám sát tình trạng API.
Tại Sao Sử Dụng Apidog?
- Dễ Sử Dụng: Không cần mã hóa! Chức năng kéo và thả cho phép bạn tạo kiểm thử một cách trực quan.
- Các Khả Năng Tích Hợp: Tích hợp liền mạch với các pipeline CI/CD, làm cho nó trở nên lý tưởng cho các quy trình DevOps.
- Cái Nhìn Thời Gian Thực: Giám sát độ trễ, tỷ lệ lỗi và thông lượng trong thời gian thực.
Bằng cách tích hợp Apidog vào quy trình làm việc của bạn, bạn có thể đảm bảo rằng việc triển khai Deepseek R1 của bạn vẫn tin cậy và hoạt động ở mức tối ưu dưới các tải trọng khác nhau.
Kết Luận
Triển khai Deepseek R1 trên đám mây không nhất thiết phải là một việc khó. Bằng cách làm theo các bước được nêu trên, bạn có thể thiết lập thành công mô hình tiên tiến này trên AWS, Azure hoặc Digital Ocean. Hãy nhớ tận dụng các công cụ như Apidog để đơn giản hóa quy trình kiểm thử và giám sát.