
알리바바의 Qwen 팀은 Qwen2.5-VL-32B-Instruct 모델을 출시하며 인공지능의 한계를 다시 한 번 확장했습니다. 이 획기적인 비전-언어 모델(VLM)은 더 스마트하고 가벼울 것을 약속합니다.
2025년 3월 24일 발표된 이 320억 매개변수 모델은 성능과 효율성 간의 최적의 균형을 이루어 개발자와 연구자에게 이상적인 선택이 됩니다. Qwen2.5-VL 시리즈의 성공을 바탕으로, 이 새로운 버전은 수학적 추론, 인간 선호 정렬, 비전 작업에서 중요한 진전을 도입하면서도 현지 배치를 위한 관리 가능한 크기를 유지합니다.
강력한 모델을 프로젝트에 통합하고자 하는 개발자에게는 견고한 API 도구 탐색이 필수적입니다. 그래서 우리는 무료로 Apidog를 다운로드할 것을 추천합니다. Apidog는 Qwen과 같은 모델을 당신의 애플리케이션에 통합하고 테스트하는 것을 간소화하는 사용자 친화적인 API 개발 플랫폼입니다. Apidog를 사용하면 Qwen API와 원활하게 상호 작용하고, 작업 흐름을 간소화하며, 이 혁신적인 VLM의 완전한 잠재력을 열 수 있습니다. 오늘 Apidog를 다운로드하고 더 스마트한 애플리케이션을 구축하세요!
이 API 도구는 모델의 엔드포인트를 손쉽게 테스트하고 디버그할 수 있게 해줍니다. 오늘 무료로 Apidog를 다운로드하고 Mistral Small 3.1의 기능을 탐색하면서 작업 흐름을 간소화하세요!
Qwen2.5-VL-32B: 더 스마트한 비전-언어 모델
Qwen2.5-VL-32B의 독창성은 무엇인가?
Qwen2.5-VL-32B는 Qwen 시리즈의 더 크고 작은 모델의 한계를 해결하기 위해 설계된 320억 매개변수 비전-언어 모델로 두드러집니다. Qwen2.5-VL-72B와 같은 720억 매개변수 모델은 강력한 능력을 제공하지만, 종종 상당한 컴퓨팅 자원을 요구해 로컬 배치에 실용적이지 않습니다. 반면, 70억 매개변수 모델은 가벼운 반면 복잡한 작업을 수행하기 위한 깊이가 부족할 수 있습니다. Qwen2.5-VL-32B는 더 관리 가능한 발자국으로 높은 성능을 제공하여 이러한 간극을 메웁니다.
이 모델은 광범위한 찬사를 받은 Qwen2.5-VL 시리즈의 기반을 두고 있습니다. 그러나 Qwen2.5-VL-32B는 강화 학습(RL)을 통한 최적화를 포함하여 중요한 개선 사항을 도입합니다. 이 접근 방식은 모델의 인간 선호와의 정렬을 개선하여 더 세부적이고 사용자 친화적인 출력을 보장합니다. 또한, 이 모델은 복잡한 문제 해결 및 데이터 분석이 포함된 작업에 필수적인 특성인 뛰어난 수학적 추론을 보여줍니다.

주요 기술 개선 사항
Qwen2.5-VL-32B는 강화 학습을 활용하여 출력 스타일을 다듬어 반응을 더 일관되게, 자세하게, 그리고 인간 상호작용을 위해 형식을 갖추도록 합니다. 게다가, 수학적 추론 능력은 MathVista와 MMMU와 같은 벤치마크에서의 성능을 통해 상당한 개선을 보여주었습니다. 이러한 개선은 정확성과 논리적 추론을 우선시하는 미세 조정된 훈련 과정에서 비롯됩니다. 특히 텍스트와 시각적 데이터가 교차하는 멀티모달 맥락에서 중요합니다.
이 모델은 또한 정밀한 이미지 이해 및 추론에서 뛰어나, 차트, 그래프 및 문서와 같은 시각 콘텐츠의 정확한 분석을 가능하게 합니다. 이 기능은 Qwen2.5-VL-32B를 첨단 시각 논리 추론 및 콘텐츠 인식이 필요한 응용 프로그램의 주요 후보로 만듭니다.
Qwen2.5-VL-32B 성능 벤치마크: 더 큰 모델을 초월하다
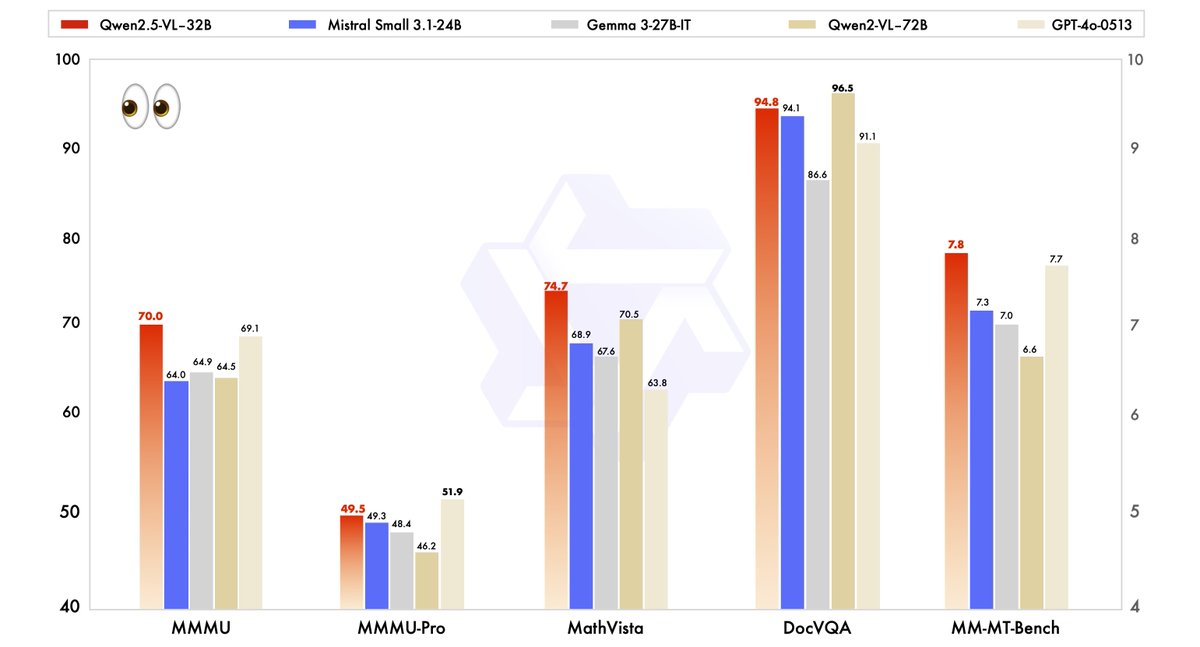
Qwen2.5-VL-32B의 성능은 최신 모델들과 철저하게 평가되었으며, 여기에는 더욱 큰 형제인 Qwen2.5-VL-72B와 Mistral-Small-3.1–24B, Gemma-3–27B-IT와 같은 경쟁자들도 포함됩니다. 결과는 여러 주요 분야에서 모델의 우수성을 강조합니다.
- MMMU (Massive Multitask Language Understanding): Qwen2.5-VL-32B는 70.0 점을 기록하며 Qwen2.5-VL-72B의 64.5를 초과합니다. 이 벤치마크는 다양한 작업에서 복잡하고 다단계의 추론을 테스트하여 모델의 인지 능력을 향상시킵니다.
- MathVista: 74.7 점을 기록한 Qwen2.5-VL-32B는 Qwen2.5-VL-72B의 70.5를 초과하여 수학적 및 시각적 추론 작업에서의 강점을 강조합니다.
- MM-MT-Bench: 이 주관적인 사용자 경험 평가 벤치마크에서 Qwen2.5-VL-32B는 이전 모델에 비해 큰 차이로 앞서 있으며, 인간 선호 정렬의 개선을 반영합니다.
- 텍스트 기반 작업 (예: MMLU, MATH, HumanEval): 이 모델은 GPT-4o-Mini와 같은 더 큰 모델과 효과적으로 경쟁하며, MMLU에서 78.4, MATH에서 82.2, HumanEval에서 91.5의 점수를 기록합니다. 매개변수 수가 적음에도 불구하고 이 성과를 달성했습니다.
이러한 벤치마크는 Qwen2.5-VL-32B가 더 큰 모델의 성능을 단순히 충족하는 것뿐만 아니라 종종 초월함을 보여주며, 적은 컴퓨팅 자원으로도 가능합니다. 이 힘과 효율성의 균형은 제한된 하드웨어로 작업하는 개발자와 연구자에게 매력적인 선택지가 됩니다.
왜 크기가 중요한가: 32B의 장점
Qwen2.5-VL-32B의 320억 매개변수 크기는 로컬 배치에 적합한 지점을 잡습니다. 광범위한 GPU 자원을 요구하는 720B 모델과 달리, 이 더 가벼운 모델은 SGLang 및 vLLM과 같은 추론 엔진과 원활하게 통합되어 관련 웹 결과에 언급된 대로 빠른 배치와 메모리 사용량 감소를 보장합니다. 이러한 호환성은 스타트업부터 대기업까지 더 넓은 사용자 범위에 접근할 수 있도록 합니다.
게다가, 속도 및 효율성에 대한 모델의 최적화는 능력을 훼손하지 않으며, 물체 인식, 차트 분석, 인보이스와 같은 구조적 출력 처리와 같은 멀티모달 작업을 처리하는 능력은 여전히 강력하여 실제 응용 프로그램에 효과적인 도구로 만듭니다.

MLX를 사용하여 Qwen2.5-VL-32B를 로컬에서 실행하기
Apple Silicon이 탑재된 Mac에서 이 강력한 모델을 로컬로 실행하려면 다음 단계를 따르십시오:
시스템 요구 사항
- Apple Silicon(M1, M2 또는 M3 칩)이 탑재된 Mac
- 최소 32GB RAM(64GB 추천)
- 60GB 이상의 여유 저장 공간
- macOS 소노마 또는 최신 버전
설치 단계
- Python 종속성 설치
pip install mlx mlx-llm transformers pillow
- 모델 다운로드
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- 모델을 MLX 형식으로 변환
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- 모델과 상호 작용하는 간단한 스크립트 작성
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# 모델 로드
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# 이미지 로드
image = Image.open("path/to/your/image.jpg")
# 이미지를 사용하여 프롬프트 생성
prompt = "이 이미지에서 무엇을 볼 수 있습니까?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
실용적인 응용 프로그램: Qwen2.5-VL-32B 활용하기
비전 작업 및 그 이상
Qwen2.5-VL-32B의 고급 시각 능력은 다양한 응용 프로그램의 기회를 제공합니다. 예를 들어, 이는 비주얼 에이전트로 작용하여 네비게이션이나 데이터 추출과 같은 작업을 수행하기 위해 컴퓨터 또는 휴대전화 인터페이스와 동적으로 상호작용할 수 있습니다. 최대 1시간 분량의 긴 비디오를 이해하고 관련 세그먼트를 pinpoint할 수 있는 능력은 비디오 분석 및 시간 로컬라이징에서 유용성을 더욱 높입니다.
문서 파싱에서 이 모델은 손으로 쓴 텍스트, 표, 차트 및 화학 공식 등 다중 장면, 다국어 콘텐츠를 처리하는 데 탁월합니다. 이는 구조화된 데이터의 정확한 추출이 중요한 금융, 교육 및 의료와 같은 산업에서 매우 중요합니다.
텍스트 및 수학적 추론
비전 작업을 넘어 Qwen2.5-VL-32B는 수학적 추론 및 코딩을 포함하는 텍스트 기반 응용 프로그램에서 빛을 발합니다. MATH 및 HumanEval과 같은 벤치마크에서의 높은 점수는 복잡한 대수 문제 해결, 함수 그래프 해석 및 정확한 코드 스니펫 생성을 포함한 뛰어난 능력을 나타냅니다. 비전과 텍스트에 대한 이중 전문성은 Qwen2.5-VL-32B가 멀티모달 AI 문제를 해결하기 위한 총체적 솔루션으로 자리 잡게 합니다.

Qwen2.5-VL-32B를 사용할 수 있는 곳
오픈 소스 및 API 접근
Qwen2.5-VL-32B는 Apache 2.0 라이센스에 따라 제공되어 오픈 소스이며 전 세계의 개발자가 접근할 수 있습니다. 여러 플랫폼에서 모델에 접근할 수 있습니다:
- Hugging Face: 모델은 Hugging Face에 호스팅되어 있어, 로컬 사용을 위해 다운로드하거나 Transformers 라이브러리를 통해 통합할 수 있습니다.
- ModelScope: 알리바바의 ModelScope 플랫폼는 모델에 접근하고 배치하는 또 다른 경로를 제공합니다.
원활한 통합을 위해 개발자는 모델과의 상호작용을 간소화하는 Qwen API를 사용할 수 있습니다. 맞춤형 애플리케이션을 구축하든 멀티모달 작업을 실험하든 Qwen API는 효율적인 연결성과 강력한 성능을 보장합니다.
추론 엔진을 통한 배치
Qwen2.5-VL-32B는 SGLang 및 vLLM과 같은 추론 엔진 배치를 지원합니다. 이러한 도구들은 빠른 추론을 위해 모델을 최적화하여 대기 시간과 메모리 사용량을 줄입니다. 이러한 엔진을 활용하여 개발자는 특정 사용 사례에 맞게 로컬 하드웨어나 클라우드 플랫폼에 모델을 배치할 수 있습니다.
시작하려면 필요한 라이브러리(예: transformers, vllm)를 설치하고 Qwen GitHub 페이지 또는 Hugging Face 문서의 지침을 따르십시오. 이 과정은 원활한 통합을 보장하여 모델의 전체 잠재력을 활용할 수 있도록 합니다.
로컬 성능 최적화
Qwen2.5-VL-32B를 로컬에서 실행할 때는 다음의 최적화 팁을 고려하십시오:
- 양자화: 메모리 요구 사항을 줄이기 위해 변환 중에
--quantize플래그를 추가하십시오. - 맥락 길이 관리: 더 빠른 반응을 위해 입력 토큰을 제한하십시오.
- 모델을 실행할 때 자원이 많은 애플리케이션을 닫으십시오.
- 배치 처리: 여러 이미지를 처리할 때 개별적으로 처리하는 대신 배치 처리하십시오.
결론: 왜 Qwen2.5-VL-32B가 중요한가
Qwen2.5-VL-32B는 비전-언어 모델 진화의 중요한 이정표를 나타냅니다. 더 스마트한 추론, 가벼운 자원 요구 사항 및 강력한 성능을 결합한 이 320억 매개변수 모델은 개발자와 연구자의 요구를 충족합니다. 수학적 추론, 인간 선호 정렬 및 비전 작업의 발전은 이를 로컬 배치 및 실제 응용 프로그램에 적합한 최고의 선택으로 만듭니다.
교육 도구, 비즈니스 인텔리전스 시스템, 고객 지원 솔루션을 구축하든 간에 Qwen2.5-VL-32B는 필요로 하는 다양한 기능과 효율성을 제공합니다. 오픈 소스 플랫폼과 Qwen API를 통해 이 모델을 프로젝트에 통합하는 것은 그 어느 때보다 쉬워졌습니다. Qwen 팀이 계속해서 혁신함에 따라 우리는 다가오는 멀티모달 AI의 놀라운 발전을 기대할 수 있습니다.
이 API 도구는 모델의 엔드포인트를 손쉽게 테스트하고 디버그할 수 있게 해줍니다. 오늘 무료로 Apidog를 다운로드하고 Mistral Small 3.1의 기능을 탐색하면서 작업 흐름을 간소화하세요!