
빠르게 발전하는 대형 언어 모델 환경에서 NVIDIA의 Llama Nemotron Ultra 253B는 고급 추론 능력을 요구하는 기업들에게 강력한 선택지로 자리 잡고 있습니다. 이 포괄적인 가이드는 모델의 인상적인 성능을 살펴보고, 다른 주요 오픈소스 모델과 비교하며, 애플리케이션에서 API를 구현하기 위한 명확한 단계를 제공합니다.
llama-3.1-nemotron-ultra-253b 벤치마크
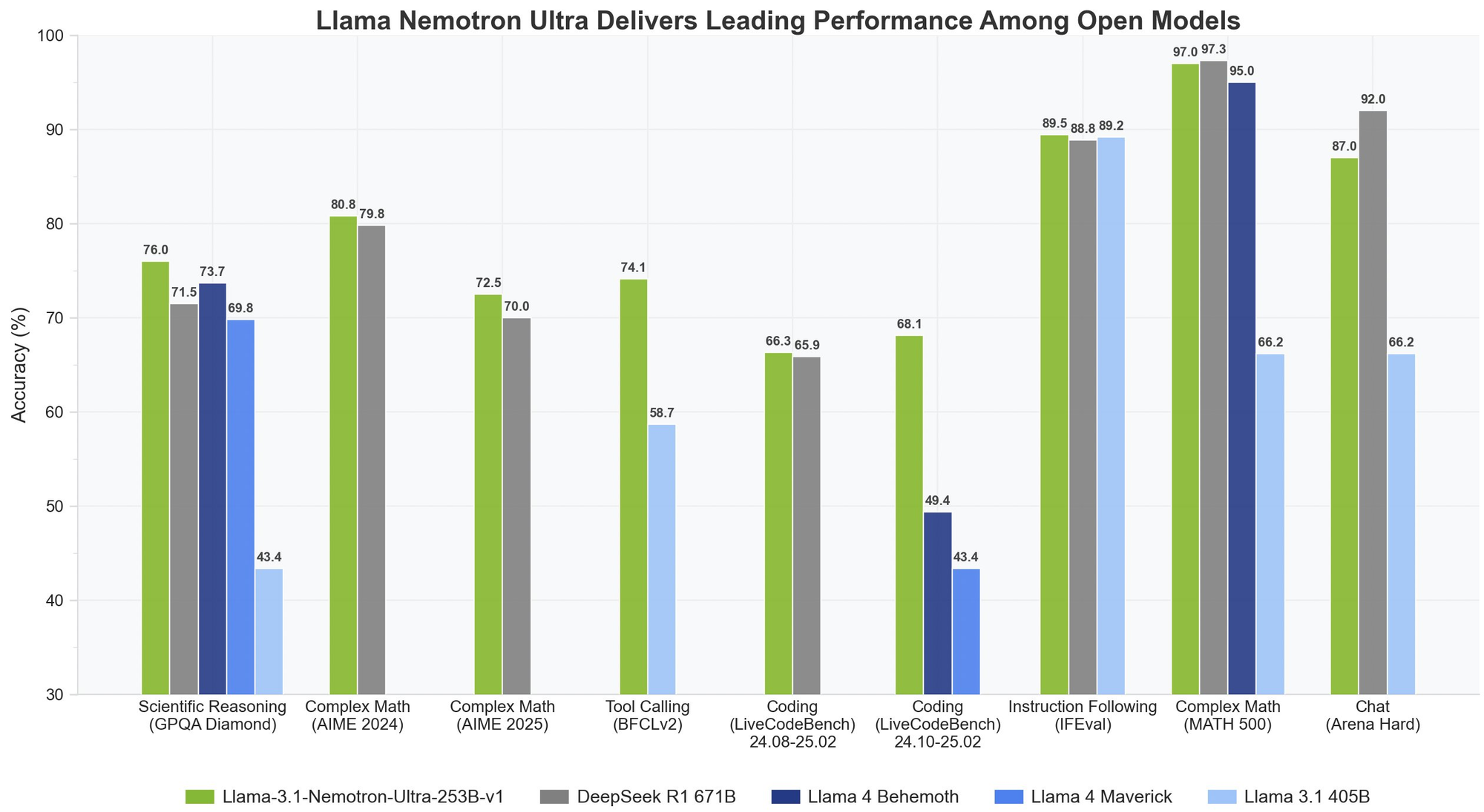
Llama Nemotron Ultra 253B는 중요한 추론 및 에이전트 벤치마크에서 뛰어난 결과를 제공합니다. 특히 "Reasoning ON/OFF" 기능이 성능 차이를 극적으로 보여줍니다:
수학적 추론
Llama Nemotron Ultra 253B는 수학적 추론 작업에서 진가를 발휘합니다:
- MATH500
- Reasoning OFF: 80.4% pass@1
- Reasoning ON: 97.0% pass@1
Reasoning ON 상태에서 97%의 정확도로, Llama Nemotron Ultra 253B는 이 도전적인 수학 벤치마크를 거의 완벽하게 수행합니다.
- AIME25 (미국 초대 수학 시험)
- Reasoning OFF: 16.7% pass@1
- Reasoning ON: 72.50% pass@1
이 놀라운 56점 향상은 Llama Nemotron Ultra 253B의 추론 능력이 복잡한 수학 문제에 대한 성능을 어떻게 변화시키는지를 보여줍니다.
과학적 추론
- GPQA (대학원 수준의 물리학 질문 및 답변)
- Reasoning OFF: 56.6% pass@1
- Reasoning ON: 76.01% pass@1
뛰어난 향상은 Llama Nemotron Ultra 253B가 대학원 수준의 물리학 문제를 체계적으로 분석하여 해결할 수 있는 능력을 보여줍니다.
프로그래밍 및 도구 사용
- LiveCodeBench (20240801-20250201)
- Reasoning OFF: 29.03% pass@1
- Reasoning ON: 66.31% pass@1
Llama Nemotron Ultra 253B는 추론 활성화 상태에서 코딩 성능이 두 배 이상 향상됩니다.
- BFCL V2 Live (기능 호출)
- Reasoning OFF: 73.62점
- Reasoning ON: 74.10점
이 벤치마크는 모델이 두 가지 모드에서 강력한 도구 사용 능력을 제공함을 보여주며, 효과적인 AI 에이전트를 구축하는 데 필수적입니다.
지시 사항 따르기
- IFEval (지시 사항 따르기 평가)
- Reasoning OFF: 88.85% 엄격한 정확도
- Reasoning ON: 89.45% 엄격한 정확도
두 모드 모두 탁월한 성능을 보여주며, Llama Nemotron Ultra 253B는 추론 모드에 관계없이 강력한 지시 사항 따르기 능력을 유지합니다.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1은 오픈소스 추론 모델의 금본위 제도로 여겨지지만, Llama Nemotron Ultra 253B는 주요 추론 벤치마크에서 그 성능을 맞추거나 초과합니다:
- GPQA에서 Llama Nemotron Ultra 253B는 76.01%의 정확도로 DeepSeek-R1의 최고 성능에 경쟁하고 있습니다.
- Llama Nemotron Ultra 253B는 DeepSeek-R1의 고정 추론 접근 방식과 달리 이중 추론 모드를 제공합니다.
- Llama Nemotron Ultra 253B는 기능 호출 능력이 우수하여 에이전트 애플리케이션에 더 다재다능합니다.
Llama Nemotron Ultra 253B vs. Llama 4
다가오는 Llama 4 Behemoth 및 Maverick 모델과 비교할 때:
- Llama Nemotron Ultra 253B는 과학적 및 복잡한 수학적 추론 벤치마크에서 우수한 성능을 보여줍니다.
- Llama Nemotron Ultra 253B의 명시적 추론 스위치는 표준 Llama 4 모델보다 더 많은 유연성을 제공합니다.
- Llama Nemotron Ultra 253B는 NVIDIA 하드웨어에 최적화되어 있어 더 나은 추론 효율성을 제공합니다.
Llama Nemotron Ultra 253B를 API를 통해 테스트해 보세요
Llama Nemotron Ultra 253B를 애플리케이션에 구현하려면 최적의 성능을 보장하기 위해 특정 단계를 따라야 합니다:
1단계: API 접근 권한 얻기
Llama Nemotron Ultra 253B에 접근하려면:
- https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1의 NVIDIA API 포털을 방문하세요.
- 아직 API 키가 없다면 등록하세요.
- NVIDIA의 NGC 환경 내에서 실행 중이라면 API 키 구성 과정이 단순화될 수 있습니다.
2단계: 개발 환경 설정하기
API 호출을 하기 전에:
pip install openai를 사용하여 OpenAI Python 패키지를 설치하세요.- 필요한 라이브러리를 임포트하세요:
from openai import OpenAI - API 키를 안전하게 저장할 수 있도록 환경을 구성하세요.
3단계: API 클라이언트 구성하기
NVIDIA의 엔드포인트로 OpenAI 클라이언트를 초기화하세요:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- Postman과는 달리 Apidog는 내장된 API 문서, 자동화된 테스트 및 AI 모델 엔드포인트에 특화된 모의 서버를 제공하여 더 통합된 경험을 제공합니다.
- Apidog의 직관적인 인터페이스는 API 테스트에 필요한 복잡한 매개변수 집합을 구성하는데 유용하며, 모델의 스트리밍 출력을 분석하는 데 특히 도움이 되는 응답 시각화 기능을 제공합니다.
- Postman은 여전히 대중적인 범용 API 테스트 도구지만, Apidog의 AI 중심 기능과 간소화된 워크플로우는 개발 과정을 상당히 가속화할 수 있습니다.

4단계: 적절한 추론 모드 결정하기
Llama Nemotron Ultra 253B는 두 가지 뚜렷한 작동 모드를 제공합니다:
- Reasoning ON: 단계별 사고가 필요한 복잡한 문제에 가장 적합 (수학, 물리, 코딩)
- Reasoning OFF: 간략한 지시 사항 따르기 및 일반 채팅에 최적
5단계: 시스템 및 사용자 프롬프트 제작하기
Reasoning ON 모드에서는:
- 시스템 프롬프트를
"detailed thinking on"으로 설정하세요. - 모든 지시 사항을 사용자 메시지에 기입하세요.
- 벤치마크된 작업(예: 수학 문제)에 대해 특정 템플릿을 사용하는 것을 고려하세요.
Reasoning OFF 모드에서는:
- 추론 시스템 프롬프트를 제거하세요.
- 사용자 메시지에 간결하고 명확한 지시 사항을 사용하세요.
6단계: 생성 매개변수 구성하기
최적의 결과를 위해:
- Reasoning ON: NVIDIA에서 권장하는 대로 temperature=0.6 및 top_p=0.95로 설정하세요.
- Reasoning OFF: temperature=0일 때 탐욕적인 디코딩을 사용하세요.
- 예상 응답 길이에 따라 적절한
max_tokens를 설정하세요. - 실시간 응답을 위해 스트리밍을 활성화하는 것을 고려하세요.
7단계: API 요청을 하고 응답 처리하기
모든 매개변수가 구성된 완료 요청을 생성하세요:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
8단계: 응답 처리 및 표시하기
스트리밍을 사용하는 경우:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
비스트리밍 응답은 completion.choices[0].message.content에 간단히 접근하면 됩니다.
결론
Llama Nemotron Ultra 253B는 오픈소스 추론 모델에서 상당한 발전을 나타내며, 다양한 벤치마크에서 최첨단 성능을 제공합니다. 고유한 이중 추론 모드, 뛰어난 기능 호출 능력 및 대규모 컨텍스트 창을 결합하여 고급 추론 능력이 필요한 기업 AI 애플리케이션에 이상적인 선택이 됩니다.
이 기사에 개략적으로 설명된 단계별 API 구현 가이드를 통해 개발자는 Llama Nemotron Ultra 253B의 잠재력을 최대한 활용하여 복잡한 문제를 인간 수준의 추론으로 해결하는 정교한 AI 시스템을 구축할 수 있습니다. AI 에이전트를 구축하든, RAG 시스템을 향상시키든, 전문 애플리케이션을 개발하든, Llama Nemotron Ultra 253B는 상업적으로 유용한 오픈소스 패키지로 차세대 AI 기능의 강력한 기초를 제공합니다.