تستمر الذكاء الاصطناعي في التطور بسرعة، ويطلب المطورون الآن أدوات توفر إمكانيات التفكير المتقدم. تلبي NVIDIA هذه الحاجة من خلال عائلة نماذج NVIDIA Llama Nemotron. تتفوق هذه النماذج في المهام التي تتطلب التفكير المعقد، وتوفر كفاءة في الحساب، وتأتي مع ترخيص مفتوح للاستخدام المؤسسي. يمكن للمطورين الوصول إلى هذه النماذج من خلال واجهة برمجة التطبيقات NVIDIA Llama Nemotron، المقدمة عبر خدمات NIM المصغرة من NVIDIA، مما يجعل التكامل في التطبيقات سلسًا.
فهم نماذج NVIDIA Llama Nemotron
قبل الغوص في واجهة برمجة التطبيقات، دعونا نفحص نماذج NVIDIA Llama Nemotron. تشمل هذه العائلة ثلاث نسخ: نانو، سوبر، وألترا. يستهدف كل منها احتياجات نشر معينة، مع تحقيق توازن بين الأداء ومتطلبات الموارد.
- نانو (8B باراميتر): يقوم المهندسون بتحسين هذا النموذج للأجهزة الطرفية وأجهزة الكمبيوتر. يوفر دقة عالية مع الحد الأدنى من قدرة الحوسبة، مما يجعله مثاليًا للتطبيقات خفيفة الوزن.
- سوبر (49B باراميتر): صمم المطورون هذا النموذج للإعدادات ذات بطاقة واحدة. يحقق توازنًا بين الإنتاجية والدقة، مناسب للمهام المعتدلة التعقيد.
- ألترا (253B باراميتر): يصمم الخبراء هذا النموذج لخوادم مراكز البيانات متعددة البطاقات. يوفر دقة من الطراز الأول لتطبيقات وكيل الذكاء الاصطناعي الأكثر تطلبًا.
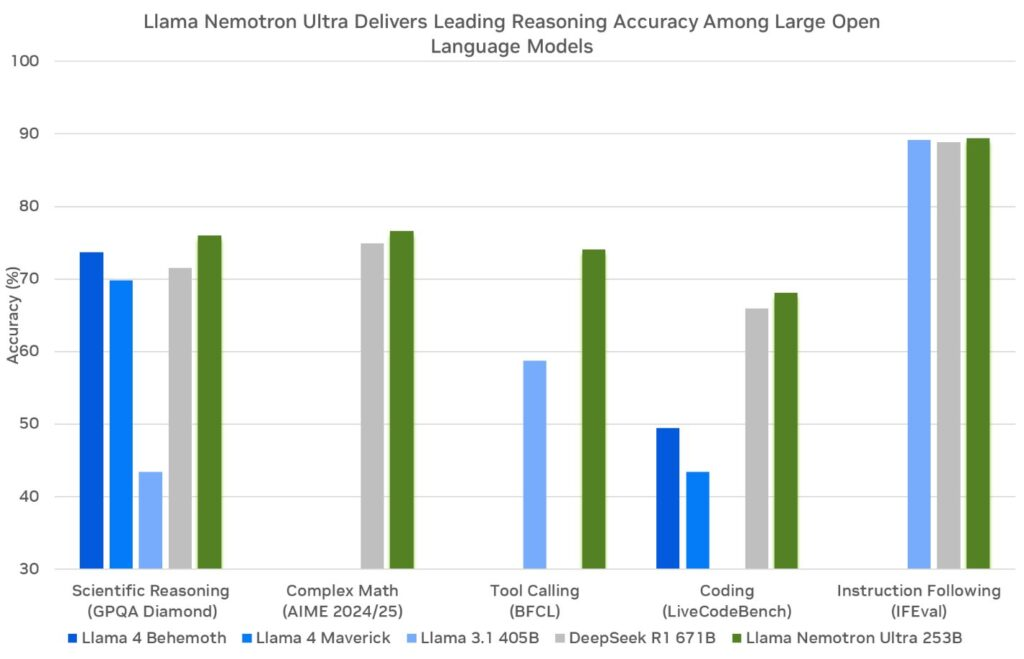
تبني NVIDIA هذه النماذج على إطار عمل Llama الخاص بـ Meta، مع تعزيزها بتقنيات بعد التدريب مثل التقطير وتعلم التعزيز. وبالتالي، تتفوق في مهام التفكير مثل التحليل العلمي، الرياضيات المتقدمة، البرمجة، واتباع التعليمات. يدعم كل نموذج طول سياق يبلغ 128,000 توكن، مما يمكنهم من معالجة المستندات الطويلة أو الحفاظ على السياق في التفاعلات الممتدة.
تتمثل خاصية بارزة في القدرة على تفعيل أو تعطيل التفكير عبر إشعار النظام. يقوم المطورون بتنشيط التفكير للاستفسارات المعقدة، مثل استكشاف الأخطاء، وتعطيله للمهام البسيطة، مثل استرجاع المعلومات الثابتة. هذه المرونة تعمل على تحسين استخدام الموارد، وهي ميزة حاسمة في التطبيقات الواقعية.
إعداد واجهة برمجة التطبيقات NVIDIA Llama Nemotron
للاستفادة من واجهة برمجة التطبيقات NVIDIA Llama Nemotron، يجب أولاً إعدادها. تقدم NVIDIA هذه الواجهة من خلال خدماتها المصغرة NIM، والتي تدعم النشر عبر بيئات السحابة والبيئات المحلية والطرفية. اتبع هذه الخطوات للبدء:
انضم إلى برنامج مطوري NVIDIA: سجّل الوصول إلى الموارد، الوثائق، والأدوات. تقوم هذه الخطوة بفتح النظام البيئي الذي تحتاجه.
احصل على بيانات اعتماد واجهة برمجة التطبيقات: تقدم NVIDIA مفاتيح واجهة برمجة التطبيقات. استخدمها لتوثيق طلباتك بأمان.
تثبيت المكتبات المطلوبة: لمطوري Python، قم بتثبيت مكتبة requests للتعامل مع استدعاءات HTTP. قم بتشغيل هذا الأمر في الطرفية الخاصة بك:
pip install requests
مع إتمام هذه الخطوات، ستعد بيئتك للتفاعل مع واجهة برمجة التطبيقات NVIDIA Llama Nemotron. بعد ذلك، سوف نستكشف كيفية إجراء الطلبات.
إجراء طلبات واجهة برمجة التطبيقات
تلتزم واجهة برمجة التطبيقات NVIDIA Llama Nemotron بمعايير RESTful، مما يبسط التكامل في مشاريعك. ترسل طلبات POST إلى نقطة نهاية واجهة برمجة التطبيقات، مع تضمين المعلمات في جسم الطلب. دعنا نفصل هذا بمثال عملي.
إليك كيفية استعلام واجهة برمجة التطبيقات باستخدام Python:
import requests
import json
# تحديد نقطة نهاية واجهة برمجة التطبيقات والمصادقة
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# إنشاء الحمولة الخاصة بالطلب
payload = {
"model": "llama-nemotron-super",
"prompt": "كم عدد حرف R في كلمة 'strawberry'؟",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# إرسال الطلب
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# معالجة الاستجابة
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"خطأ: {response.status_code} - {response.text}")
شرح المعلمات الرئيسية
model: تحدد نسخة النموذج—نانو، سوبر، أو ألترا. اختر بناءً على نشر الخاص بك.prompt: يوفر النص المدخل ليقوم النموذج بمعالجته.max_tokens: يحدد طول الاستجابة بالرموز. قم بضبطه للتحكم في حجم الإخراج.temperature: يتراوح من 0 إلى 1. القيم الأدنى (مثل 0.5) تنتج مخرجات متوقعة، بينما القيم الأعلى (مثل 0.9) تزيد من الإبداع.reasoning: يتم تفعيل أو تعطيل قدرات التفكير. يتم تعيينها إلى "on" للمهام المعقدة، و"off" للمهام البسيطة.
على سبيل المثال، تمكين التفكير يناسب المهام مثل حل مشاكل الرياضيات، بينما تعطيله يناسب البحث البسيط. يمكنك أيضًا إضافة معلمات مثل top_p للتحكم في التنوع أو stop_sequences لإيقاف التوليد عند رموز معينة، مثل "\n\n".
إليك مثال موسع:
payload = {
"model": "llama-nemotron-super",
"prompt": "اشرح التكرار في البرمجة.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
هذا الطلب يولد تفسيرًا مفصلًا للتكرار، ويتوقف عند إدخال مزدوج. تساعدك أدوات مثل Apidog في اختبار وتحسين تلك الطلبات بكفاءة.
معالجة استجابات واجهة برمجة التطبيقات
بعد إرسال الطلب، تعيد واجهة برمجة التطبيقات NVIDIA Llama Nemotron استجابة JSON. يتضمن ذلك النص المُولد وبيانات وصفية. إليك نموذج استجابة:
{
"text": "يوجد ثلاثة أحرف R في كلمة 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: تحتوي على مخرجات النموذج.tokens_generated: تشير إلى عدد الرموز المُنتجة.time_taken: تقيس وقت التوليد بالثواني.
تحقق دائمًا من رمز الحالة. يشير الرمز 200 إلى النجاح، مما يسمح لك بتحليل JSON. ترجع الأخطاء رموز مثل 400 أو 500، مع تفاصيل في جسم الاستجابة للتصحيح. نفذ معالجة الأخطاء، مثل إعادة المحاولة أو الاحتياطات، لضمان المتانة في الإنتاج.
على سبيل المثال، قم بتوسيع الكود السابق:
if response.status_code == 200:
result = response.json()
print(f"الاستجابة: {result['text']}")
print(f"الرموز المستخدمة: {result['tokens_generated']}")
else:
print(f"فشل: {response.text}")
# أضف منطق إعادة المحاولة هنا إذا لزم الأمر
تساعدك هذه الطريقة في الحفاظ على موثوقية تطبيقك تحت ظروف متغيرة.
أفضل الممارسات وحالات الاستخدام
لزيادة إمكانيات واجهة برمجة التطبيقات NVIDIA Llama Nemotron، اعتمد على أفضل الممارسات هذه:
- تحسين استخدام الموارد: قم بتنشيط التفكير فقط للمهام المعقدة. يقلل هذا بشكل كبير من تكاليف الحوسبة.
- مراقبة الأداء: تتبع
time_takenلضمان ردود سريعة، خاصة للتطبيقات في الوقت الحقيقي. - ضبط المعلمات: جرب بعض القيم للـ
temperatureوmax_tokensلتحقيق توازن بين الإبداع والدقة. - تأمين البيانات الاعتمادية: قم بتخزين مفاتيح واجهة برمجة التطبيقات في متغيرات البيئة أو خزائن أمنة، ولا تستخدمها في الكود.
- طلبات الدفع الجماعي: قم بمعالجة عدة مطالبات في استدعاء واحد لتعزيز الكفاءة.
حالات الاستخدام العملية
- دعم العملاء: تطوير روبوتات الدردشة التي تحل الاستفسارات المعقدة باستخدام التفكير، مثل استكشاف مشكلات الأجهزة.
- التعليم: بناء معلمين يشرحون المفاهيم، مثل حساب التفاضل والتكامل، مع منطق تفصيلي.
- البحث: مساعدة العلماء في تحليل البيانات أو صياغة الفرضيات.
- تطوير البرمجيات: توليد الأكواد أو تصحيح السكربتات بناءً على المدخلات باللغة الطبيعية.
للحصول على مثال برمجي:
payload = {
"model": "llama-nemotron-super",
"prompt": "اكتب دالة Python لحساب المضاعف.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
قد يعيد النموذج:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
تظهر هذه الوظيفة قدرته على التفكير من خلال المنطق التكراري. يمكن أن يساعد Apidog في اختبار مثل هذه المكالمات API، لضمان الدقة.
خاتمة
تمكّن واجهة برمجة التطبيقات NVIDIA Llama Nemotron المطورين من إنشاء وكلاء ذكاء اصطناعي متقدمين مع قدرات تفكير قوية. تعمل ميزة التفكير القابلة للتبديل على تحسين الأداء، بينما تتناسب قابليتها للتطوير عبر نماذج نانو وسوبر وألترا مع الاحتياجات المتنوعة. سواء كنت تبني روبوتات محادثة، أدوات تعليمية، أو مساعدات برمجية، توفر هذه الواجهة المرونة والقوة.
علاوة على ذلك، يُعزز دمجها مع أدوات مثل Apidog سير العمل الخاص بك. اختبر نقاط النهاية، تحقق من الاستجابات، وتكرار بسرعة للتركيز على الابتكار. مع تقدم الذكاء الاصطناعي، تؤهلك إتقان واجهة برمجة التطبيقات NVIDIA Llama Nemotron لتكون في طليعة هذا المجال التحويلي.