
تشغيل LLM على جهازك المحلي له العديد من المزايا. أولاً، يمنحك السيطرة الكاملة على بياناتك، مما يضمن الحفاظ على الخصوصية. ثانياً، يمكنك التجريب دون القلق بشأن مكالمات API المكلفة أو الاشتراكات الشهرية. بالإضافة إلى ذلك، توفر النشر المحلي طريقة عملية لتعلم كيفية عمل هذه النماذج من الداخل.
علاوة على ذلك، عندما تقوم بتشغيل LLMs محلياً، تتجنب مشاكل تأخير الشبكة المحتملة والاعتماد على خدمات السحابة. وهذا يعني أنه يمكنك البناء والاختبار والتكرار بشكل أسرع، خاصة إذا كنت تعمل على مشاريع تتطلب تكاملًا وثيقًا مع قاعدة التعليمات البرمجية الخاصة بك.
فهم LLMs: نظرة سريعة
قبل أن نتعمق في اختياراتنا الأفضل، دعونا نتحدث باختصار عن ماهية LLM. ببساطة، فإن نموذج اللغة الكبيرة (LLM) هو نموذج ذكاء اصطناعي تم تدريبه على كميات هائلة من بيانات النص. تتعلم هذه النماذج الأنماط الإحصائية في اللغة، مما يسمح لها بتوليد نصوص مشابهة للبشر بناءً على المطالبات التي تقدمها.
LLMs هي في جوهر العديد من تطبيقات الذكاء الاصطناعي الحديثة. إنها تشغل الدردشة الآلية، مساعدي الكتابة، مولدات الشيفرات، وحتى الوكلاء المحادثة المعقدين. ومع ذلك، فإن تشغيل هذه النماذج - خاصة الأكبر منها - يمكن أن يكون مُكلفًا بالموارد. لهذا السبب من المهم أن يكون لديك أداة موثوقة لتشغيلها محليًا.
باستخدام أدوات LLM المحلية، يمكنك التجريب مع هذه النماذج دون إرسال بياناتك إلى خوادم بعيدة. يمكن أن يعزز ذلك من أمان الأداء. على مدار هذا البرنامج التعليمي، ستلاحظ أن الكلمة المفتاحية "LLM" تم التأكيد عليها بينما نستكشف كيف تساعدك كل أداة في الاستفادة من هذه النماذج القوية على الأجهزة الخاصة بك.
الأداة #1: Llama.cpp
Llama.cpp هي واحدة من أكثر الأدوات شعبية عند تشغيل LLMs محليًا. تم إنشاؤها بواسطة جورجي جيرجانوف وصيانتها بواسطة مجتمع نابض، هذه المكتبة C/C++ مصممة لأداء الاستدلال على نماذج مثل LLaMA وغيرها مع الحد الأدنى من الاعتماديات.

لماذا ستحب Llama.cpp
- خفيفة وسريعة: تم تصميم Llama.cpp للسرعة والكفاءة. مع إعداد قليل، يمكنك تشغيل نماذج معقدة حتى على الأجهزة المتواضعة. إنها تستفيد من تعليمات وحدة المعالجة المركزية المتقدمة مثل AVX وNeon، مما يعني أنك تحصل على أقصى استفادة من أداء نظامك.
- دعم الأجهزة المتنوع: سواء كنت تستخدم جهاز x86، أو جهاز ARM، أو حتى ماك بسيلكون من آبل، فإن Llama.cpp يلبي احتياجاتك.
- مرونة سطر الأوامر: إذا كنت تفضل المحطة على الواجهات الرسومية، تجعل أدوات سطر الأوامر في Llama.cpp من السهل تحميل النماذج وتوليد الردود مباشرة من صدفتك.
- مجتمع ومفتوح المصدر: كمشروع مفتوح المصدر، يستفيد من المساهمات والتحسينات المستمرة من المطورين حول العالم.
كيفية البدء
- التثبيت: قم باستنساخ المستودع من GitHub وتجميع الكود على جهازك.
- إعداد النموذج: قم بتنزيل النموذج المفضل لديك (على سبيل المثال، نسخة LLaMA المقدرة) واستخدم الأدوات المتاحة عبر سطر الأوامر لبدء الاستدلال.
- التخصيص: اضبط المعلمات مثل طول السياق، درجة الحرارة، وحجم الشعاع لترى كيف يتغير مخرجات النموذج.
على سبيل المثال، قد تبدو رسالة بسيطة مثل:
./main -m ./models/llama-7b.gguf -p "قل لي نكتة عن البرمجة" --temp 0.7 --top_k 100
يقوم هذا الأمر بتحميل النموذج وتوليد نص استنادًا إلى مطلبك. بساطة هذا الإعداد هي ميزة كبيرة لأي شخص يبدأ في تشغيل LLM محليًا.
دعنا ننتقل بسلاسة من Llama.cpp، لاستكشاف أداة رائعة أخرى تتخذ نهجًا مختلفًا قليلاً.
الأداة #2: GPT4All
GPT4All هو نظام مفتوح المصدر صممه Nomic AI يهدف إلى ديمقراطية الوصول إلى LLMs. واحدة من أكثر الجوانب إثارة في GPT4All هي أنه تم بناؤه للعمل على الأجهزة ذات المواصفات الاستهلاكية، سواء كنت على وحدة معالجة مركزية أو وحدة معالجة رسوميات. وهذا يجعله مثاليًا للمطورين الذين يرغبون في التجريب دون الحاجة إلى أجهزة مكلفة.
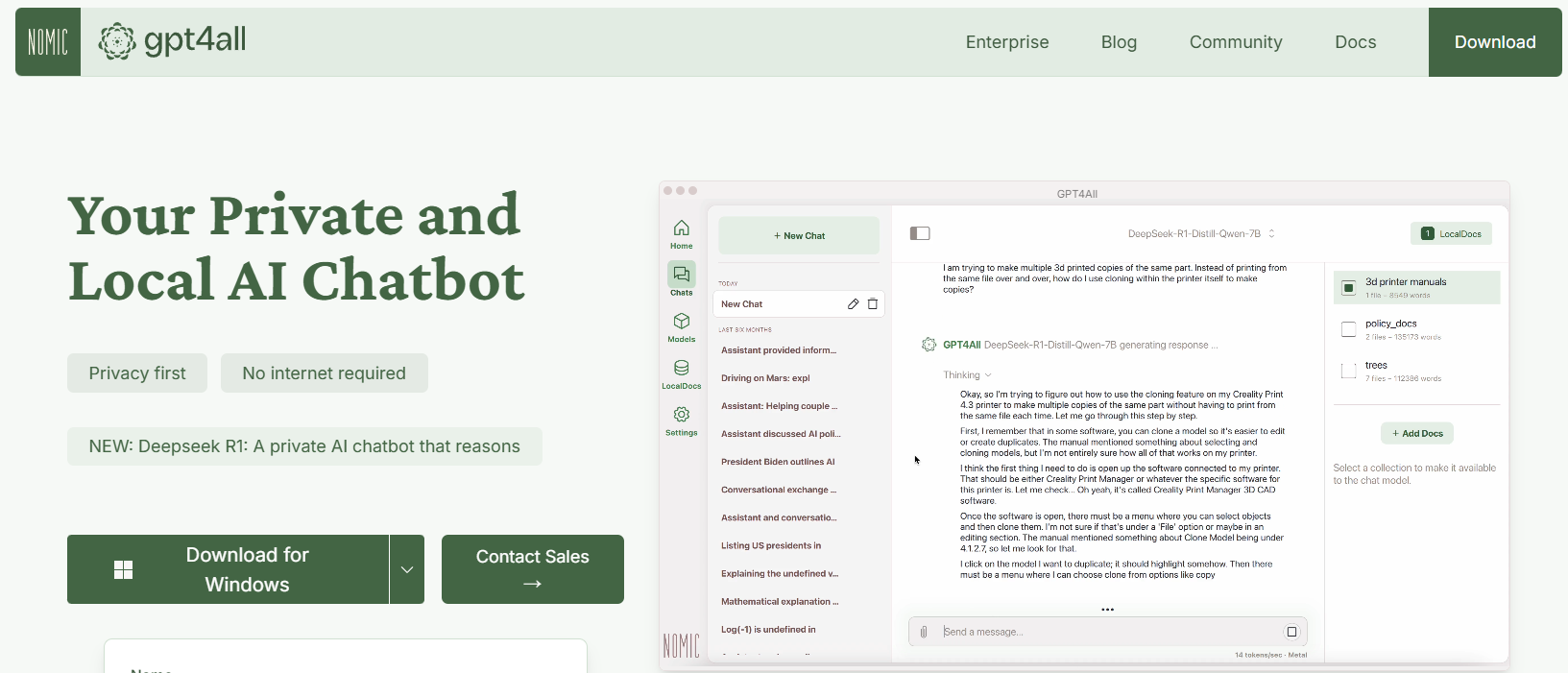
الميزات الرئيسية لـ GPT4All
- نهج محلي أول: تم تصميم GPT4All للعمل بالكامل على جهازك المحلي. وهذا يعني أنه لن تترك أي بيانات جهازك أبدًا، مما يضمن الخصوصية وسرعة استجابة سريعة.
- سهل الاستخدام: حتى إذا كنت جديدًا على LLMs، يأتي GPT4All مع واجهة بسيطة وبديهية تتيح لك التفاعل مع النموذج دون الحاجة إلى معرفة تقنية عميقة.
- خفيف وفعال: النماذج في نظام GPT4All تم تحسينها للأداء. يمكنك تشغيلها على الكمبيوتر المحمول الخاص بك، مما يجعلها متاحة لجمهور أوسع.
- مفتوح المصدر ومدفوع بالمجتمع: مع طبيعته المفتوحة المصدر، يدعو GPT4All المساهمات من المجتمع، مما يضمن أنه يبقى محدثًا بأحدث الابتكارات.
كيفية البدء مع GPT4All
- التثبيت: يمكنك تنزيل GPT4All من موقعه الرسمي. عملية التثبيت مباشرة، وهناك ثنائيات مسبقة التجميع متاحة لنظامي التشغيل Windows وmacOS وLinux.
- تشغيل النموذج: بعد التثبيت، ببساطة قم بتشغيل التطبيق واختر من مجموعة متنوعة من النماذج المعدة مسبقًا. تقدم الأداة حتى واجهة للدردشة، والتي تعتبر مثالية للتجريب غير الرسمي.
- التخصيص: اضبط المعلمات مثل طول استجابة النموذج وإعدادات الإبداع لترى كيف تتغير المخرجات. يساعدك ذلك على فهم كيف تعمل LLMs في ظروف مختلفة.
على سبيل المثال، يمكنك كتابة طلب مثل:
ما هي بعض الحقائق الممتعة حول الذكاء الاصطناعي؟
وسيقوم GPT4All بتوليد استجابة ودية وملهمة - كل ذلك دون الحاجة إلى اتصال بالإنترنت.
الأداة #3: LM Studio
للانتقال، LM Studio هي أداة ممتازة أخرى لتشغيل LLMs محليًا، خاصة إذا كنت تبحث عن واجهة رسومية تجعل إدارة النماذج سهلة.
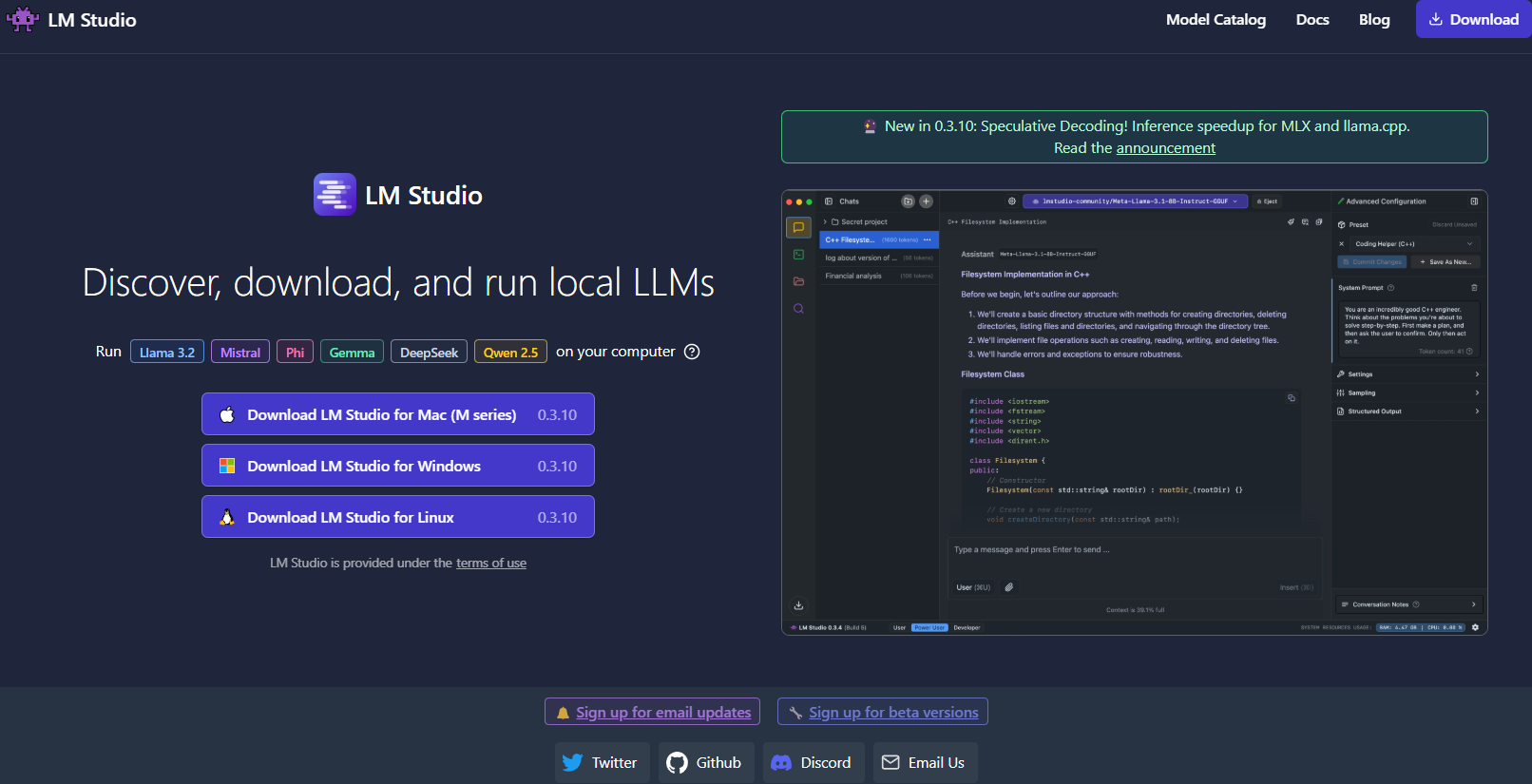
ما الذي يميز LM Studio؟
- واجهة مستخدم بديهية: يوفر LM Studio تطبيق سطح مكتب أنيق وسهل الاستخدام. هذا مثالي لأولئك الذين يفضلون عدم العمل فقط على سطر الأوامر.
- إدارة النموذج: مع LM Studio، يمكنك بسهولة تصفح وتنزيل والتبديل بين LLMs المختلفة. يتميز التطبيق بفلترات مدمجة ووظائف بحث، لذلك يمكنك العثور على النموذج المثالي لمشروعك.
- إعدادات قابلة للتخصيص: اضبط المعلمات مثل درجة الحرارة والحد الأقصى من الرموز ونافذة السياق مباشرة من واجهة المستخدم. تعتبر هذه الحلقة الفورية من التعليقات مثالية لتعلم كيفية تأثير التكوينات المختلفة على سلوك النموذج.
- متوافق عبر الأنظمة: يعمل LM Studio على Windows وmacOS وLinux، مما يجعله متاحًا لشريحة واسعة من المستخدمين.
- خادم الاستدلال المحلي: يمكن للمطورين أيضًا الاستفادة من خادمه المحلي HTTP، الذي يحاكي واجهة OpenAI API. مما يجعل دمج ميزات LLM في تطبيقاتك أسهل بكثير.
كيفية إعداد LM Studio
- التنزيل والتثبيت: توجه إلى موقع LM Studio، وقم بتنزيل المثبت الخاص بنظام التشغيل الخاص بك، واتبع تعليمات الإعداد.
- تشغيل واستكشاف: افتح التطبيق، واستكشف مكتبة النماذج المتاحة، واختر من بينها ما يناسب احتياجاتك.
- التجريب: استخدم واجهة الدردشة المدمجة للتفاعل مع النموذج. يمكنك أيضًا التجريب مع نماذج متعددة في وقت واحد لمقارنة الأداء والجودة.
تخيل أنك تعمل على مشروع كتابة إبداعية؛ تجعل واجهة LM Studio من السهل التبديل بين النماذج وضبط المخرجات في الوقت الفعلي. إن ملاحظتها البصرية وسهولة استخدامها يجعلها خيارًا قويًا لأولئك الذين بدأوا للتو أو للمحترفين الذين يحتاجون إلى حل محلي قوي.
الأداة #4: Ollama
التالي هو Ollama، أداة سطر الأوامر القوية ولكن البسيطة التي تركز على كل من البساطة والوظائف. تم تصميم Ollama لمساعدتك في تشغيل وإنشاء ومشاركة LLMs دون عناء الإعدادات المعقدة.
لماذا تختار Ollama؟
- نشر النماذج بسهولة: يقوم Ollama بتغليف كل ما تحتاجه - أوزان النموذج، والتكوين، وحتى البيانات - في وحدة واحدة محمولة تعرف باسم "Modelfile". وهذا يعني أنه يمكنك بسرعة تنزيل وتشغيل نموذج مع الحد الأدنى من الإعدادات.
- قدرات متعددة الوسائط: بخلاف بعض الأدوات التي تركز فقط على النص، يدعم Ollama المدخلات متعددة الوسائط. يمكنك توفير كل من النصوص والصور كمطالب، وستولد الأداة استجابات تأخذ كلاهما في الاعتبار.
- متاح عبر الأنظمة: يتوفر Ollama على نظامي macOS وLinux وWindows. إنه خيار رائع للمطورين الذين يعملون عبر أنظمة مختلفة.
- كفاءة سطر الأوامر: بالنسبة لأولئك الذين يفضلون العمل في المحطة، يوفر Ollama واجهة سطر أوامر نظيفة وكفء تتيح لك النشر السريع والتفاعل.
- تحديثات سريعة: يتم تحديث الأداة بشكل متكرر من قبل مجتمعها، مما يضمن أنك تعمل دائمًا بأحدث التحسينات والميزات.
إعداد Ollama
1. التثبيت: انتقل إلى موقع Ollama وقم بتنزيل المثبت الخاص بنظام التشغيل لديك. التثبيت بسيط مثل تشغيل بعض الأوامر في سطر الأوامر لديك.
2. تشغيل نموذج: بمجرد التثبيت، استخدم أمرًا مثل:
ollama run llama3
سيقوم هذا الأمر بتحميل نموذج لاما 3 تلقائيًا (أو أي نموذج مدعوم آخر) وبدء عملية الاستدلال.
3. تجريب مع تعددية الوسائط: حاول تشغيل نموذج يدعم الصور. على سبيل المثال، إذا كانت لديك صورة جاهزة، يمكنك سحبها وإفلاتها في مطلبك (أو استخدام معلمة API للصور) لرؤية كيف يستجيب النموذج.
يعد Ollama جذابًا بشكل خاص إذا كنت تبحث عن تصميم نماذج أو نشر LLMs محليًا بسرعة. لا تأتي بساطته على حساب القوة، مما يجعله مثاليًا لكل من المبتدئين والمطورين المتمرسين.
الأداة #5: Jan
وأخيرًا، لدينا Jan. Jan هو منصة مفتوحة المصدر، محلية أولاً، تكتسب شعبية بسرعة بين أولئك الذين يفضلون خصوصية البيانات والتشغيل دون اتصال. فلسفتها بسيطة: دع المستخدمين يشغلون LLMs القوية بالكامل على عتادهم الخاص، دون أي تحويلات بيانات مخفية.
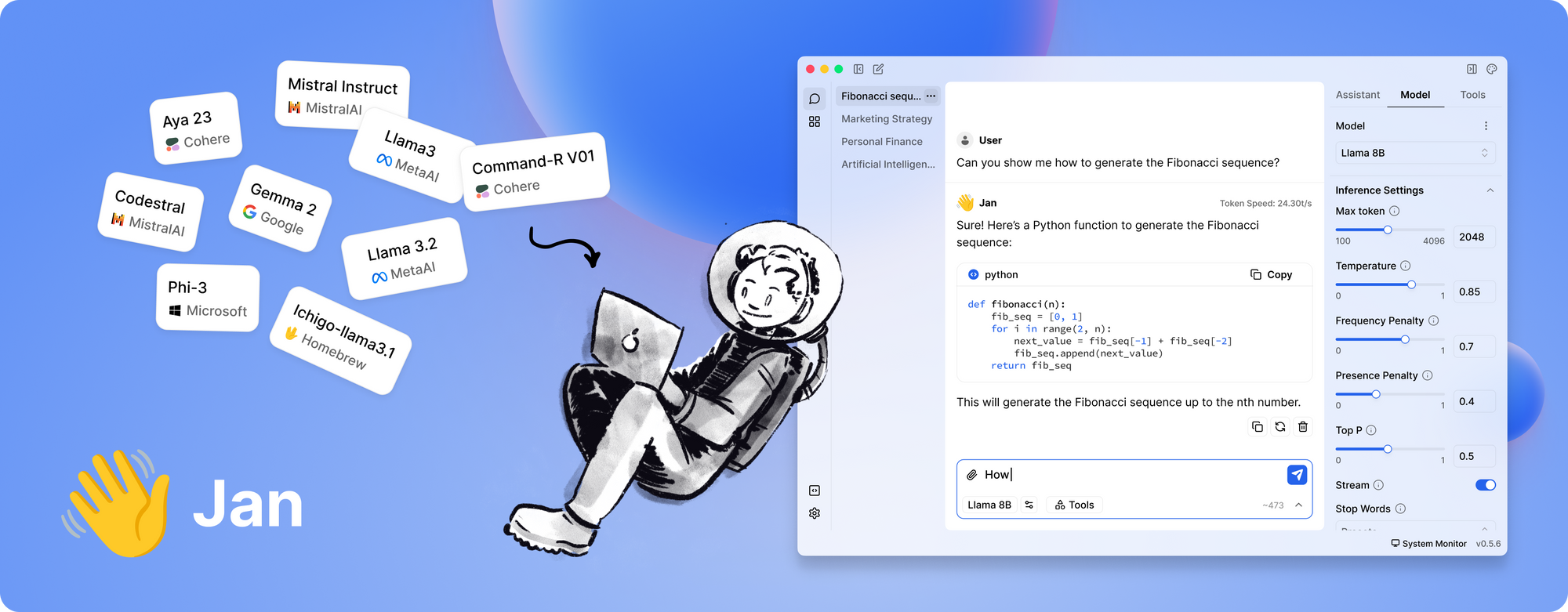
ما الذي يجعل Jan مميزًا؟
- غير متصل تمامًا: تم تصميم Jan للعمل بدون اتصال بالإنترنت. يضمن ذلك أن جميع تفاعلاتك وبياناتك تبقى محلية، مما يعزز الخصوصية والأمان.
- مركزية للمستخدم وقابلة للتوسع: تقدم الأداة واجهة نظيفة وتدعم إطار عمل للتطبيقات/الإضافات. وهذا يعني أنه يمكنك بسهولة توسيع قدراتها أو دمجها مع الأدوات الحالية لديك.
- تنفيذ النموذج بشكل فعال: تم بناء Jan لتحمل مجموعة متنوعة من النماذج، بما في ذلك تلك المضبوطة ليتماشى مع مهام معينة. إنه محسن للعمل حتى على الأجهزة المتواضعة، دون التأثير على الأداء.
- تطوير مدفوع بالمجتمع: مثل العديد من الأدوات في قائمتنا، يعد Jan مفتوح المصدر ويستفيد من المساهمات من مجتمع م dedicated من المطورين.
- لا توجد رسوم اشتراك: بخلاف العديد من الحلول السحابية، فإن Jan مجاني للاستخدام. وهذا يجعله خيارًا ممتازًا لشركات الناشئة، والهواة، وأي شخص يرغب في تجربة LLMs دون حواجز مالية.
كيفية البدء مع Jan
- قم بالتنزيل والتثبيت: انتقل إلى الموقع الرسمي لـ Jan أو مستودع GitHub الخاص به. اتبع تعليمات التثبيت، التي هي مباشرة ومصممة لجعلك تعمل بسرعة.
- فتح وتخصيص: افتح Jan واختر من مجموعة متنوعة من النماذج المثبتة مسبقًا. إذا لزم الأمر، يمكنك استيراد نماذج من مصادر خارجية مثل Hugging Face.
- التجرب والتوسع: استخدم واجهة الدردشة للتفاعل مع LLM الخاص بك. اضبط المعلمات، وثبت الإضافات، وانظر كيف يتكيف Jan مع سير العمل الخاص بك. تتيح لك مرونته تخصيص تجربة LLM المحلية وفقًا لاحتياجاتك الدقيقة.
حقًا يجسد Jan روح التنفيذ المحلي والتركيز على الخصوصية لـ LLM. إنه مثالي لأي شخص يريد أداة قابلة للتخصيص وسهلة الاستخدام تحتفظ بكل البيانات على جهازه الخاص.
نصيحة احترافية: تدفق استجابات LLM باستخدام تصحيح الأخطاء SSE
إذا كنت تعمل مع LLMs (نماذج اللغة الكبيرة)، فإن التفاعل في الزمن الحقيقي يمكن أن يعزز تجربة المستخدم بشكل كبير. سواء كان دردشة آلية تقدم استجابات مباشرة أو أداة محتوى تتحدث ديناميكيًا مع البيانات المُولَّدة، فإن التدفق هو النقطة الرئيسية. توفر الأحداث التي يتم إرسالها من الخادم (SSE) حلاً فعالًا لهذا، مما يمكّن الخوادم من دفع التحديثات إلى العملاء عبر اتصال HTTP واحد. وعلى عكس البروتوكولات ثنائية الاتجاه مثل WebSockets، فإن SSE أبسط وأكثر مباشرة، مما يجعله خيارًا رائعًا للميزات في الوقت الفعلي.
يمكن أن يكون تصحيح أخطاء SSE تحديًا. وهنا يأتي دور Apidog. تتيح لك ميزة تصحيح أخطاء SSE لـ Apidog اختبار ورصد وتصحيح تدفقات SSE بسهولة. في هذا القسم، سنستعرض لماذا تعتبر SSE مهمة لتصحيح أخطاء واجهات برمجة التطبيقات LLM وسنرشدك خلال برنامج تدريبي خطوة بخطوة لاستخدام Apidog لإعداد واختبار اتصالات SSE.
لماذا تعتبر SSE مهمة لتصحيح أخطاء واجهات برمجة التطبيقات LLM
قبل أن نتعمق في البرنامج التدريبي، إليك لماذا تعتبر SSE مناسبة تمامًا لتصحيح أخطاء واجهات برمجة التطبيقات LLM:
- تغذية مرجعية في الزمن الحقيقي: تدفق SSE بيانات حسب ما يتم إنشاؤه، مما يسمح للمستخدمين برؤية الاستجابات تتكشف بشكل طبيعي.
- عبء منخفض: بخلاف الاقتراع، تستخدم SSE اتصالًا دائمًا واحدًا، مما يقلل من استخدام الموارد.
- سهولة الاستخدام: تندمج SSE بسلاسة في تطبيقات الويب، مما يتطلب إعدادًا قليلاً على جانب العميل.
جاهز لتجربته؟ دعنا نعد تصحيح أخطاء SSE في Apidog.
برنامج تعليمي خطوة بخطوة: استخدام تصحيح الأخطاء SSE في Apidog
اتبع هذه الخطوات لتكوين واختبار اتصال SSE مع Apidog.
الخطوة 1: إنشاء نقطة نهاية جديدة في Apidog
أنشئ مشروع HTTP جديد في Apidog لاختبار وتصحيح طلبات API. أضف نقطة نهاية باستخدام عنوان URL لنموذج AI لتدفق SSE - باستخدام DeepSeek في هذا المثال. (نصيحة احترافية: استنساخ مشروع DeepSeek API الجاهز من مركز واجهات برمجة التطبيقات Apidog).
الخطوة 2: إرسال الطلب
بعد إضافة نقطة النهاية، انقر على إرسال لإرسال الطلب. إذا كانت رأس الاستجابة تتضمن Content-Type: text/event-stream، سيكتشف Apidog تدفق SSE، ويحلل البيانات، ويعرضها في الوقت الفعلي.
الخطوة 3: مشاهدة الاستجابات في الوقت الفعلي
تحديث عرض الجدول الزمني في Apidog في الوقت الفعلي حيث يقوم نموذج AI بتدفق الاستجابات، مما يعرض كل جزء ديناميكيًا. وهذا يتيح لك تتبع عملية تفكير AI والحصول على رؤى حول كيفية توليد مخرجاته.
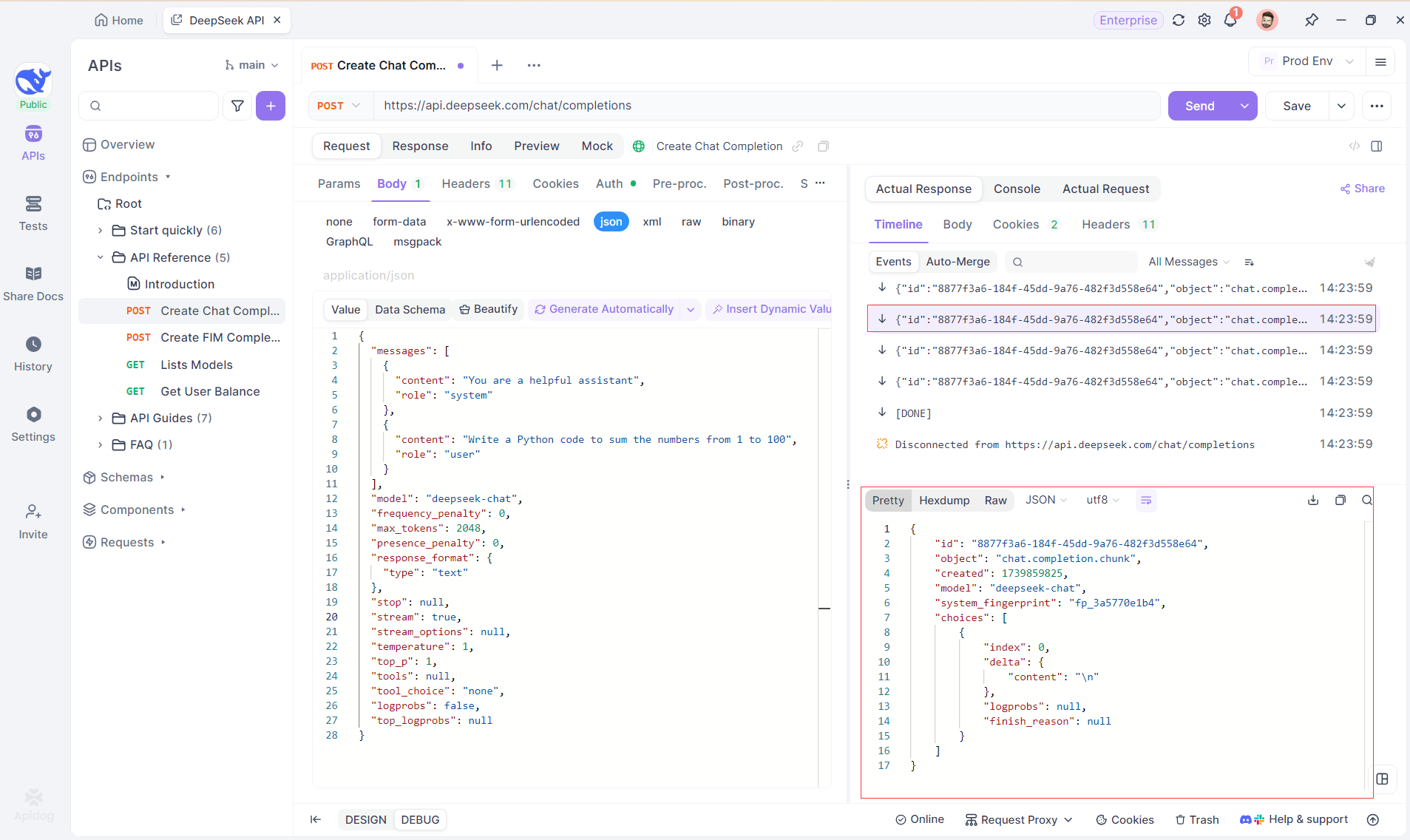
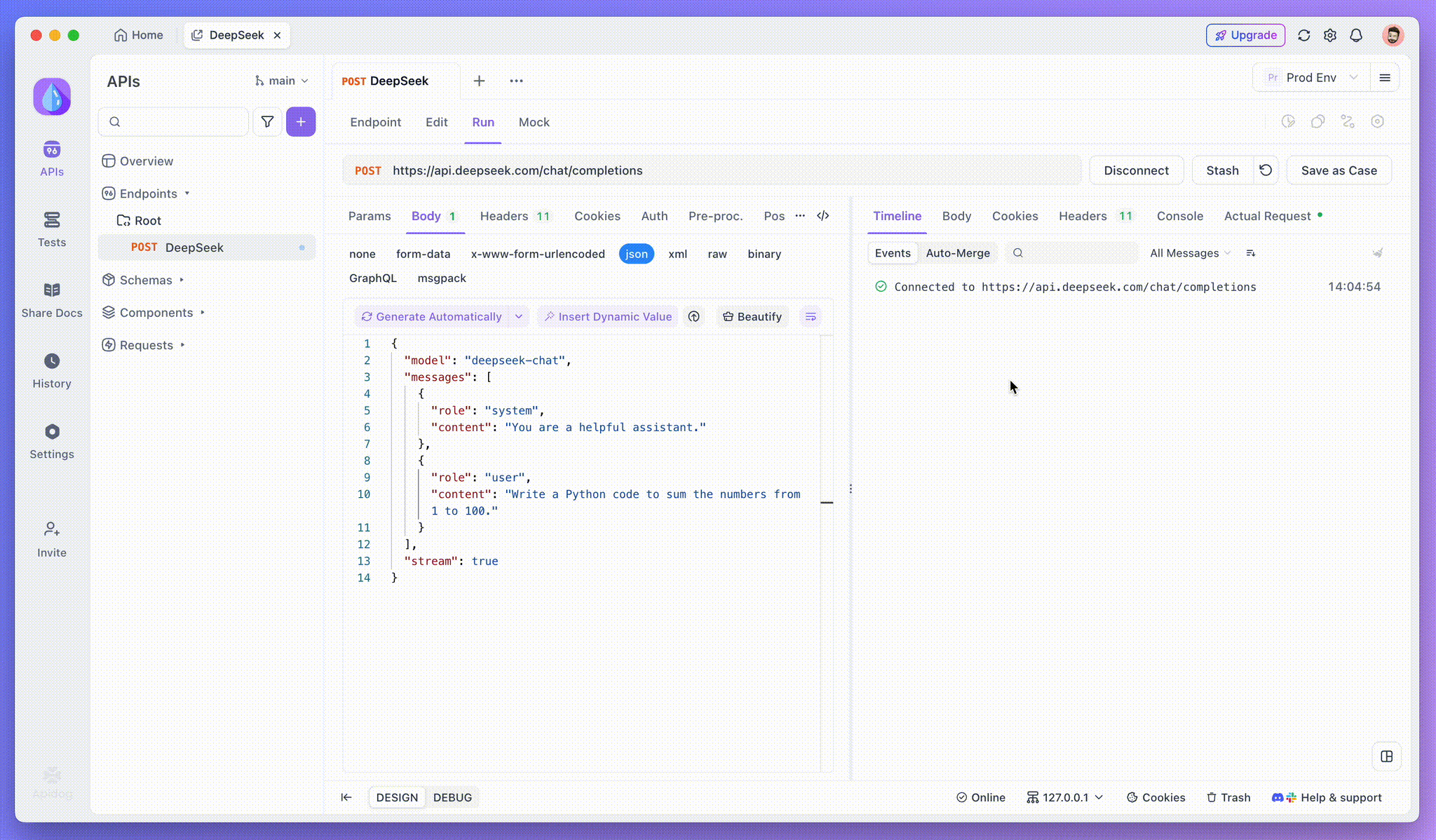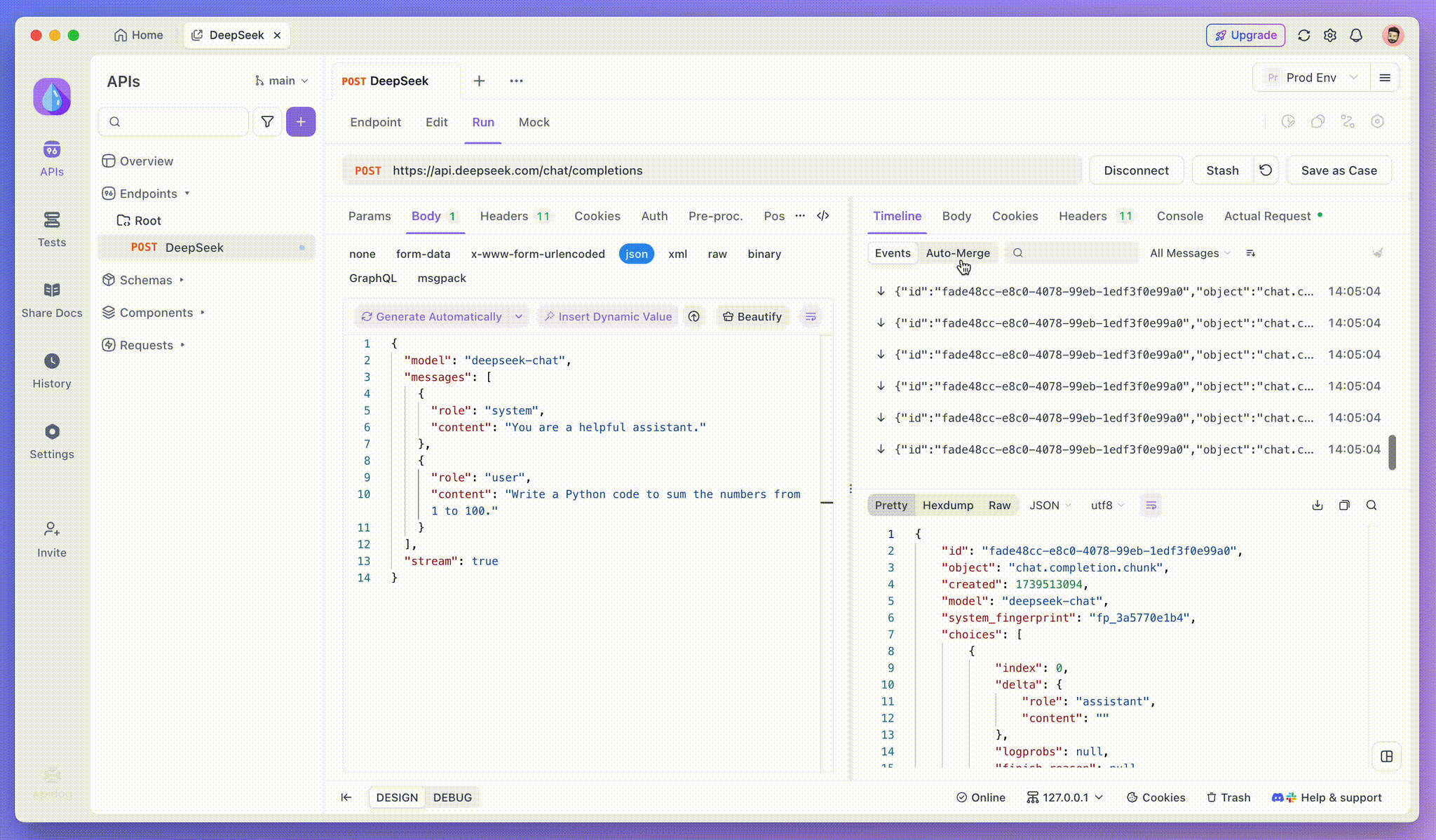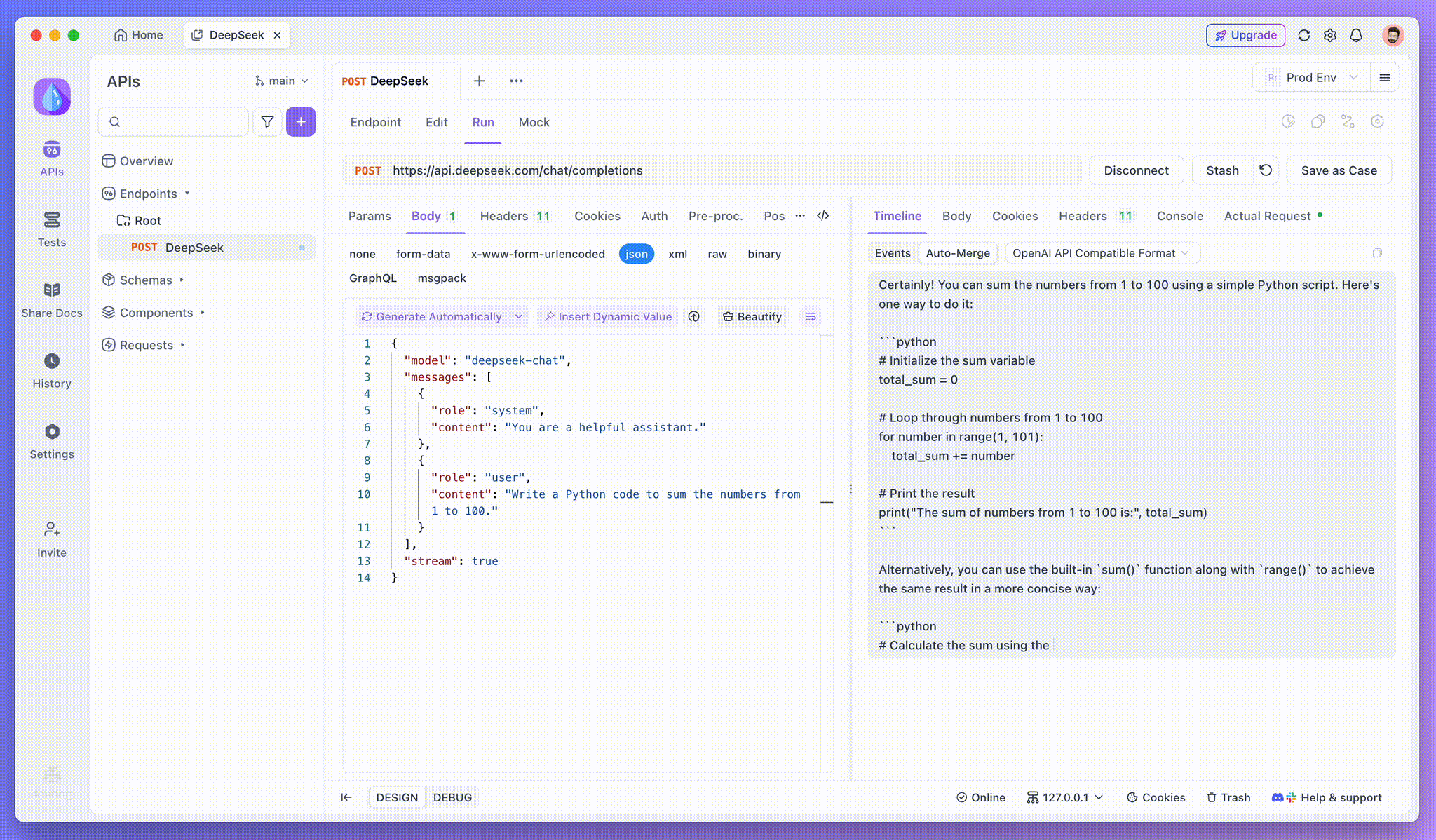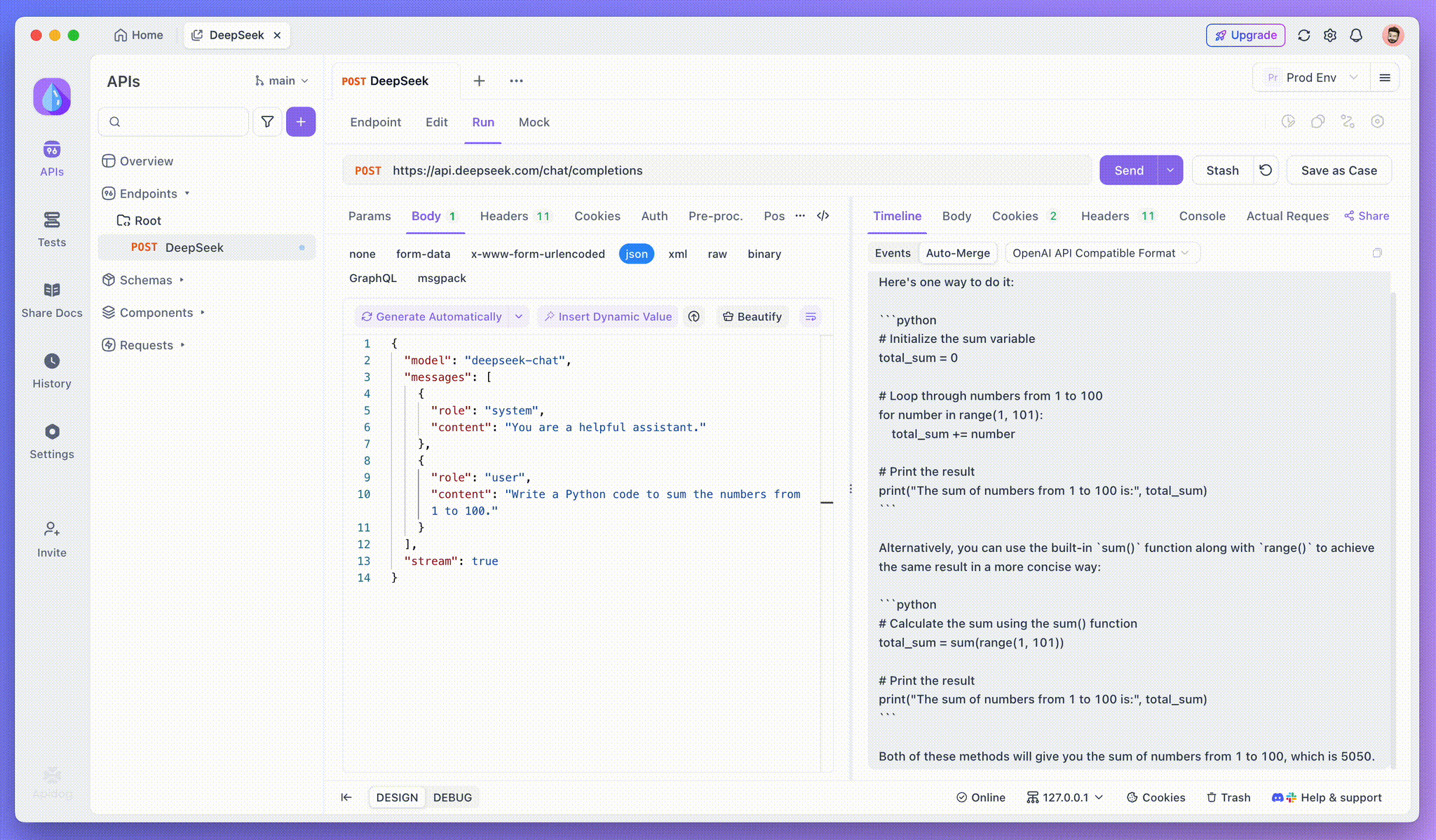
الخطوة 4: عرض استجابة SSE في رد كامل
تقوم SSE بتدفق البيانات في أجزاء، مما يتطلب معالجة إضافية. يحل ميزة الدمج التلقائي الخاصة بـ Apidog هذه المشكلة عن طريق دمج الاستجابات المجزأة من نماذج مثل OpenAI أو Gemini أو Claude إلى إخراج كامل.
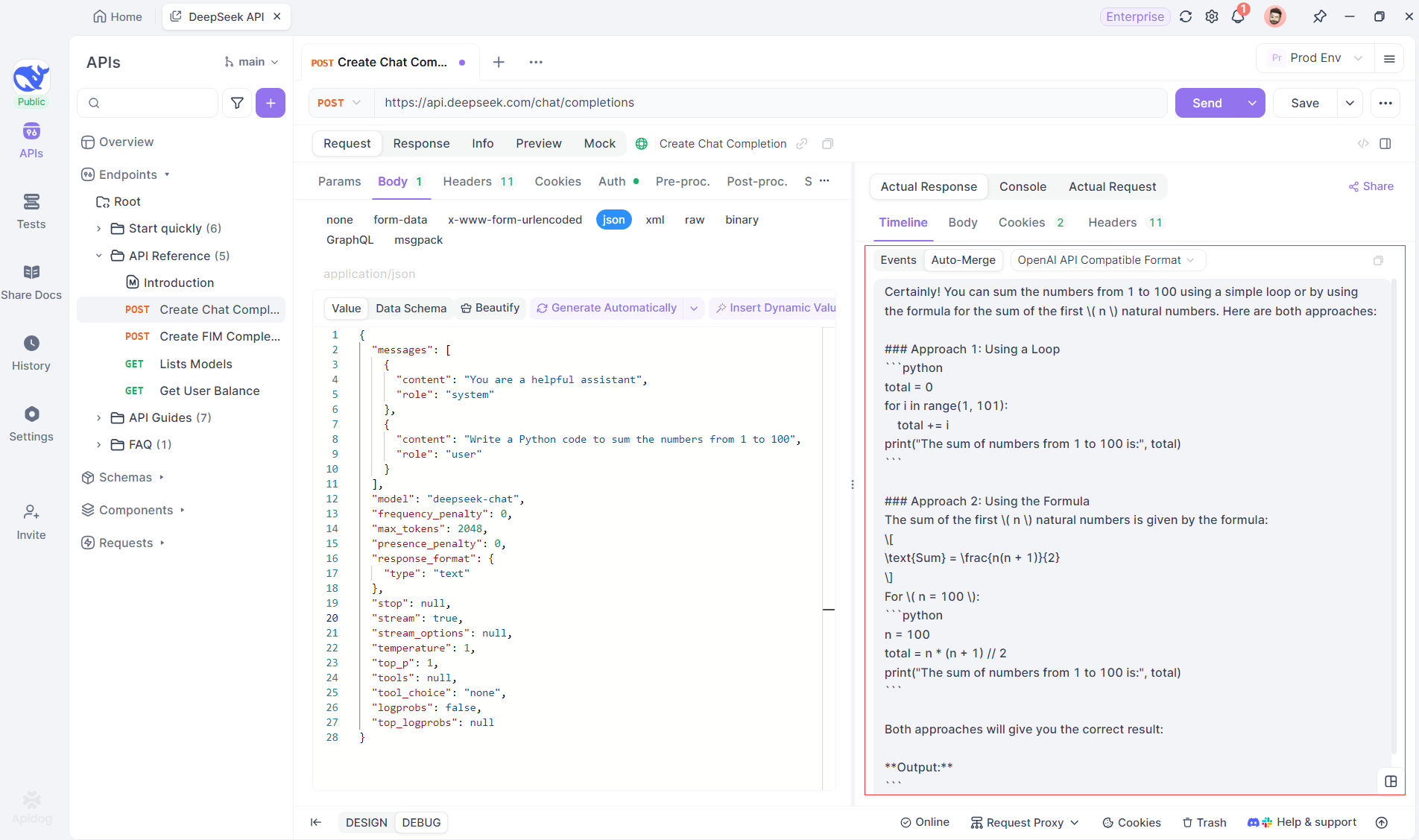
تزيل ميزة الدمج التلقائي في Apidog التعامل اليدوي مع البيانات عن طريق دمج الاستجابات المجزأة من نماذج مثل OpenAI أو Gemini أو Claude تلقائيًا.
بالنسبة لنماذج التفكير مثل DeepSeek R1، تُظهر ميزة عرض الجدول الزمني الخاصة بـ Apidog خريطة بصرية لعملية تفكير AI، مما يسهل تصحيح الأخطاء وفهم كيفية تشكُل الاستنتاجات.
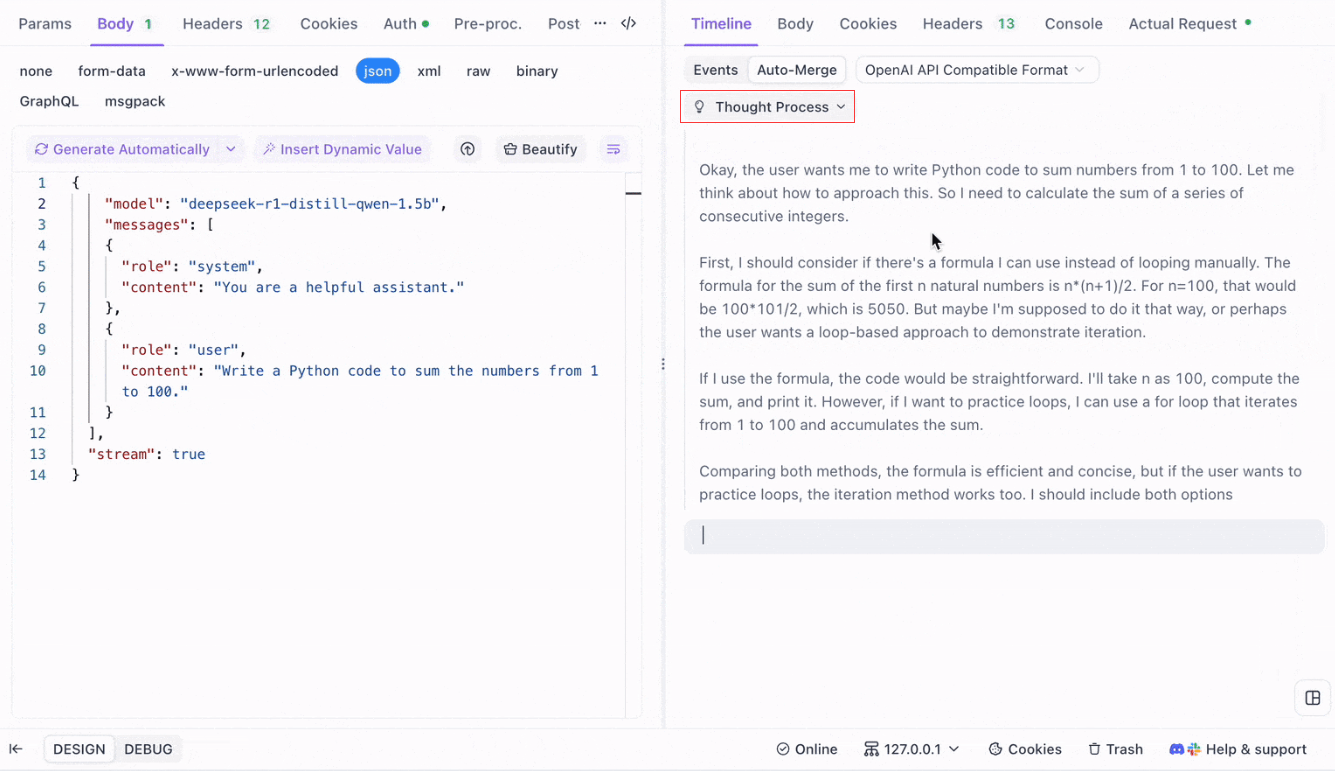
يتعرف Apidog بسلاسة على استجابات AI من:
- تنسيق واجهة برمجة تطبيقات OpenAI
- تنسيق واجهة برمجة تطبيقات Gemini
- تنسيق واجهة برمجة تطبيقات Claude
عندما تطابق الاستجابة هذه التنسيقات، يقوم Apidog تلقائيًا بدمج الأجزاء، مما يلغي خياطة اليد ويسهل تصحيح أخطاء SSE.
الخاتمة والخطوات التالية
لقد غطينا الكثير من الأمور اليوم! لتلخيص، إليك خمس أدوات بارزة لتشغيل LLMs محليًا:
- Llama.cpp: مثالي للمطورين الذين يرغبون في أداة خفيفة وسريعة وعالية الكفاءة مع دعم واسع للأجهزة.
- GPT4All: نظام محلي أول يعمل على الأجهزة ذات المواصفات الاستهلاكية، ويقدم واجهة بديهية وأداء قوي.
- LM Studio: مثالي لأولئك الذين يفضلون واجهة رسومية، مع سهولة إدارة النماذج وخيارات تخصيص واسعة النطاق.
- Ollama: أداة قوية لسطر الأوامر مع قدرات متعددة الوسائط وتجميع سلس للنماذج من خلال نظام "Modelfile".
- Jan: منصة مفتوحة المصدر تركز على الخصوصية تعمل بالكامل بدون اتصال، وتقدم إطار عمل قابل للتوسع لدمج نماذج LLM مختلفة.
كل من هذه الأدوات تقدم مزايا فريدة، سواء كان ذلك في الأداء أو سهولة الاستخدام أو الخصوصية. اعتمادًا على متطلبات مشروعك، قد تكون واحدة من هذه الحلول هي الخيار المثالي لاحتياجاتك. جمال أدوات LLM المحلية هو أنها تمكنك من الاستكشاف والتجريب دون الحاجة للقلق بشأن تسرب البيانات أو تكاليف الاشتراك أو تأخير الشبكة.
تذكر أن التجريب مع LLMs المحلية هو عملية تعليمية. لا تتردد في مزج ومطابقة هذه الأدوات، اختبار تكوينات مختلفة، ورؤية أي منها يتناسب بشكل أفضل مع سير العمل الخاص بك. بالإضافة إلى ذلك، إذا كنت تقوم بدمج هذه النماذج في تطبيقاتك الخاصة، يمكن أن تساعدك أدوات مثل Apidog في إدارة واختبار نقاط نهاية LLM API الخاصة بك باستخدام الأحداث المُرسلة من الخادم (SSE) بسلاسة. لا تنسَ تنزيل Apidog مجانًا ورفعه تجربتك في التطوير المحلي.
خطوات التالية
- التجريب: اختر أداة واحدة من قائمتنا وقم بإعدادها على جهازك. جرّب نماذج وبيانات مختلفة لفهم كيفية تأثير التغييرات على المخرجات.
- التكامل: إذا كنت تقوم بتطوير تطبيق، فاستخدم أداة LLM المحلية كجزء من الخلفية الخاصة بك. تقدم العديد من هذه الأدوات توافق API (مثل خادم الاستدلال المحلي في LM Studio) مما يمكن أن يجعل التكامل أكثر سلاسة.
- المساهمة: معظم هذه المشاريع مفتوحة المصدر. إذا وجدت خطأ، ميزة مفقودة، أو لديك أفكار للتحسين، فكر في المساهمة في المجتمع. يمكن لمساهمتك أن تساعد في تحسين هذه الأدوات.
- تعلم المزيد: تابع استكشاف عالم LLMs من خلال قراءة عن مواضيع مثل تقدير النماذج، تقنيات التحسين، وهندسة المطالبات. كلما زادت معرفتك، زادت قدرتك على الاستفادة من هذه النماذج إلى أقصى إمكاناتها.
بنهاية هذا، يجب أن تكون لديك قاعدة صلبة لاختيار الأداة المحلية LLM المناسبة لمشاريعك. إن تكنولوجيا LLM تتطور بسرعة، ويعتبر تشغيل النماذج محليًا خطوة رئيسية نحو بناء حلول ذكاء اصطناعي خاصة، وقابلة للتوسيع، وعالية الأداء.
بينما تجرب هذه الأدوات، ستكتشف أن الإمكانيات لا حصر لها. سواء كنت تعمل على دردشة آلية، مساعد كتابة أكواد، أو أداة كتابة إبداعية مخصصة، يمكن أن توفر LLMs المحلية المرونة والقوة التي تحتاجها. استمتع برحلتك، ونتمنى لك برمجة سعيدة!