
مقدمة
إن دمج نماذج الاستدلال المتقدمة والأطر البسيطة يُحوِّل الطريقة التي تسترجع بها أنظمة الذكاء الاصطناعي المعلومات وتعالجها وتعرضها. في هذا الدليل، سنقوم بإنشاء نظام جيل معزز بالاسترجاع (RAG) باستخدام DeepSeek R1، وهو نموذج استدلال عالي الأداء، و SmolAgents، إطار وكيل بسيط من Hugging Face. سيمكن هذا النظام من معالجة الوثائق بشكل فعال، والبحث الذكي، والاستدلال الشبيه بالبشر—وهو مثالي للتطبيقات البحثية ودعم العملاء وإدارة المعرفة.
متطلبات النظام لتشغيل الإعداد
سيقوم وكيل الذكاء الاصطناعي بأداء أربع مهام رئيسية:
- تحميل ومعالجة ملفات PDF: تحويل الوثائق إلى قطع نص قابلة للبحث.
- إنشاء قاعدة بيانات متجهات: تخزين التضمينات للبحث الدلالي السريع.
- الاسترجاع والاستدلال: استخدم DeepSeek R1 لتحليل البيانات المسترجعة وتوليد الإجابات.
- التفاعل مع المستخدمين: توفير واجهة محادثة للتفاعل السلس.
الخطوة 1: تحميل ومعالجة مستندات PDF
الأدوات والمكتبات
- LangChain: لتحميل الوثائق وتقسيم النص.
- ChromaDB: قاعدة بيانات متجهات بسيطة لتخزين التضمينات.
- تضمينات Hugging Face: لتحويل النص إلى تمثيلات متجهية.
التنفيذ
1.1 تحميل ملفات PDF
استخدم DirectoryLoader من LangChain لتحميل جميع ملفات PDF من دليل. يتم تقسيم كل PDF إلى صفحات لمعالجتها.
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_and_process_pdfs(data_dir: str):
loader = DirectoryLoader(
data_dir,
glob="**/*.pdf",
loader_cls=PyPDFLoader
)
documents = loader.load()
# تقسيم الوثائق إلى قطع
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
return text_splitter.split_documents(documents)
1.2 إنشاء قاعدة بيانات متجهات
قم بتحويل قطع النص إلى تضمينات وتخزينها في ChromaDB لاسترجاع فعال.
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
import os
import shutil
def create_vector_store(chunks, persist_directory: str):
if os.path.exists(persist_directory):
shutil.rmtree(persist_directory)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={'device': 'cpu'}
)
vectordb = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=persist_directory
)
return vectordb
نقاط يجب مراعاتها
- حجم القطعة: 1000 حرف مع تداخل 200 حرف يوازن بين الاحتفاظ بالسياق وكفاءة البحث.
- نموذج التضمين:
all-mpnet-base-v2يوفر تضمينات جمل عالية الجودة.
الخطوة 2: تنفيذ وكيل الاستدلال مع DeepSeek R1
لماذا DeepSeek R1؟
يتخصص DeepSeek R1 في الاستدلال متعدد الخطوات، مما يمكنه من تفكيك الاستفسارات المعقدة، واستنتاج العلاقات، وتوليد إجابات هيكلية.
تهيئة نموذج الاستدلال
قم بضبط DeepSeek R1 عبر Ollama للاستدلال المحلي:
from smolagents import OpenAIServerModel, CodeAgent
reasoning_model_id = "deepseek-r1:7b"
def get_model(model_id):
return OpenAIServerModel(
model_id=model_id,
api_base="http://localhost:11434/v1",
api_key="ollama"
)
reasoning_model = get_model(reasoning_model_id)
reasoner = CodeAgent(
tools=[],
model=reasoning_model,
add_base_tools=False,
max_steps=2 # تحديد تكرارات الاستدلال لزيادة الكفاءة
)
الخطوة 3: بناء خط أنابيب الجيل المعزز بالاسترجاع (RAG)
تصميم الأداة
إنشاء أداة RAG تجمع بين استرجاع الوثائق وقدرات الاستدلال الخاصة بـ DeepSeek R1.
from smolagents import tool
@tool
def rag_with_reasoner(user_query: str) -> str:
# استرجاع الوثائق ذات الصلة
docs = vectordb.similarity_search(user_query, k=3)
context = "\n\n".join(doc.page_content for doc in docs)
# توليد موجه الاستدلال
prompt = f"""
بناءً على السياق التالي، أجب عن سؤال المستخدم بإيجاز.
إذا كانت المعلومات غير كافية، اقترح استفسارًا محسّنًا.
السياق:
{context}
السؤال: {user_query}
الإجابة:
"""
return reasoner.run(prompt, reset=False)
الميزات الرئيسية
- الموجهات السياقية: حقن الوثائق المسترجعة في الموجه للحصول على ردود مستندة.
- آلية الطوارئ: يقترح النموذج استفسارات أفضل عندما تكون البيانات غير كافية.
الخطوة 4: نشر وكيل الذكاء الاصطناعي الأساسي
تنسيق سير العمل
يدير الوكيل الأساسي، المدعوم من Llama 3.2، التفاعلات مع المستخدمين ويستدعي أداة RAG حسب الحاجة:
from smolagents import ToolCallingAgent, GradioUI
tool_model = get_model("llama3.2")
primary_agent = ToolCallingAgent(
tools=[rag_with_reasoner],
model=tool_model,
add_base_tools=False,
max_steps=3
)
def main():
GradioUI(primary_agent).launch()
if __name__ == "__main__":
main()
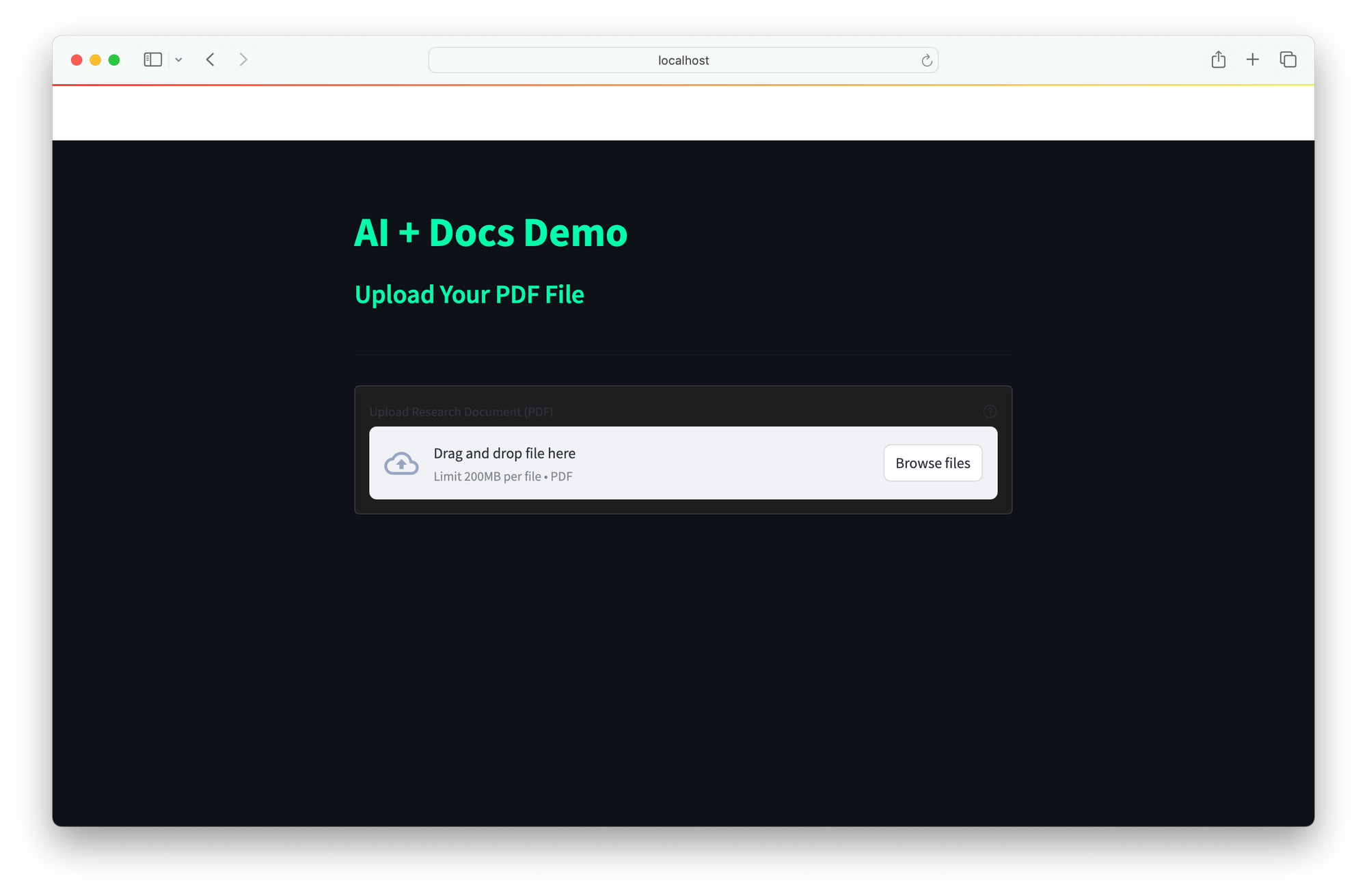
واجهة المستخدم
تقدم واجهة المستخدم واجهة ويب بسيطة للتفاعل في الوقت الحقيقي:
- يدخل المستخدمون استفسارات.
- يسترجع الوكيل الوثائق، ويستدعي مع DeepSeek R1، ويعيد الإجابات.
إن دمج DeepSeek R1 و SmolAgents يقدم حلاً قويًا للذكاء الاصطناعي يجمع بين الاستدلال المعزز لتفكيك الاستفسارات المعقدة، واسترجاع فعال عبر البحث الدلالي السريع لـ ChromaDB، والنشر المحلي الفعّال من حيث التكلفة لتجاوز الاعتماد على واجهات برمجة التطبيقات السحابية المكلفة. يسمح هيكله القابل للتوسع بالدمج السلس للأدوات الجديدة، مما يجعله مثاليًا للتطبيقات مثل البحث (تحليل الوثائق الفنية)، ودعم العملاء (حل الأسئلة المتداولة)، وإدارة المعرفة (تحويل الموارد الثابتة إلى أنظمة تفاعلية).
يمكن أن تشمل التحسينات المستقبلية توسيع دعم الوثائق ليشمل وورد، HTML، وmarkdown، ودمج البحث على الويب في الوقت الحقيقي للحصول على سياق أوسع، وتنفيذ حلقات التغذية الراجعة لتحسين دقة الإجابات بمرور الوقت. يقدم هذا الإطار أساسًا متعدد الاستخدامات لبناء مساعدي ذكاء اصطناعي ذكيين وقابلين للتكيف ومخصصين لاحتياجات متنوعة.