
في المشهد المتطور بسرعة لنماذج اللغة الكبيرة، تبرز Llama Nemotron Ultra 253B من NVIDIA كقوة بالنسبة للمؤسسات التي تسعى للحصول على قدرات استدلال متقدمة. تتناول هذه الدليل الشامل المقاييس المثيرة للإعجاب للنموذج، وتقوم بمقارنته مع نماذج مفتوحة المصدر الرائدة الأخرى، وتوفر خطوات واضحة لتطبيق واجهة برمجة التطبيقات الخاصة به في تطبيقاتك.
مقياس llama-3.1-nemotron-ultra-253b
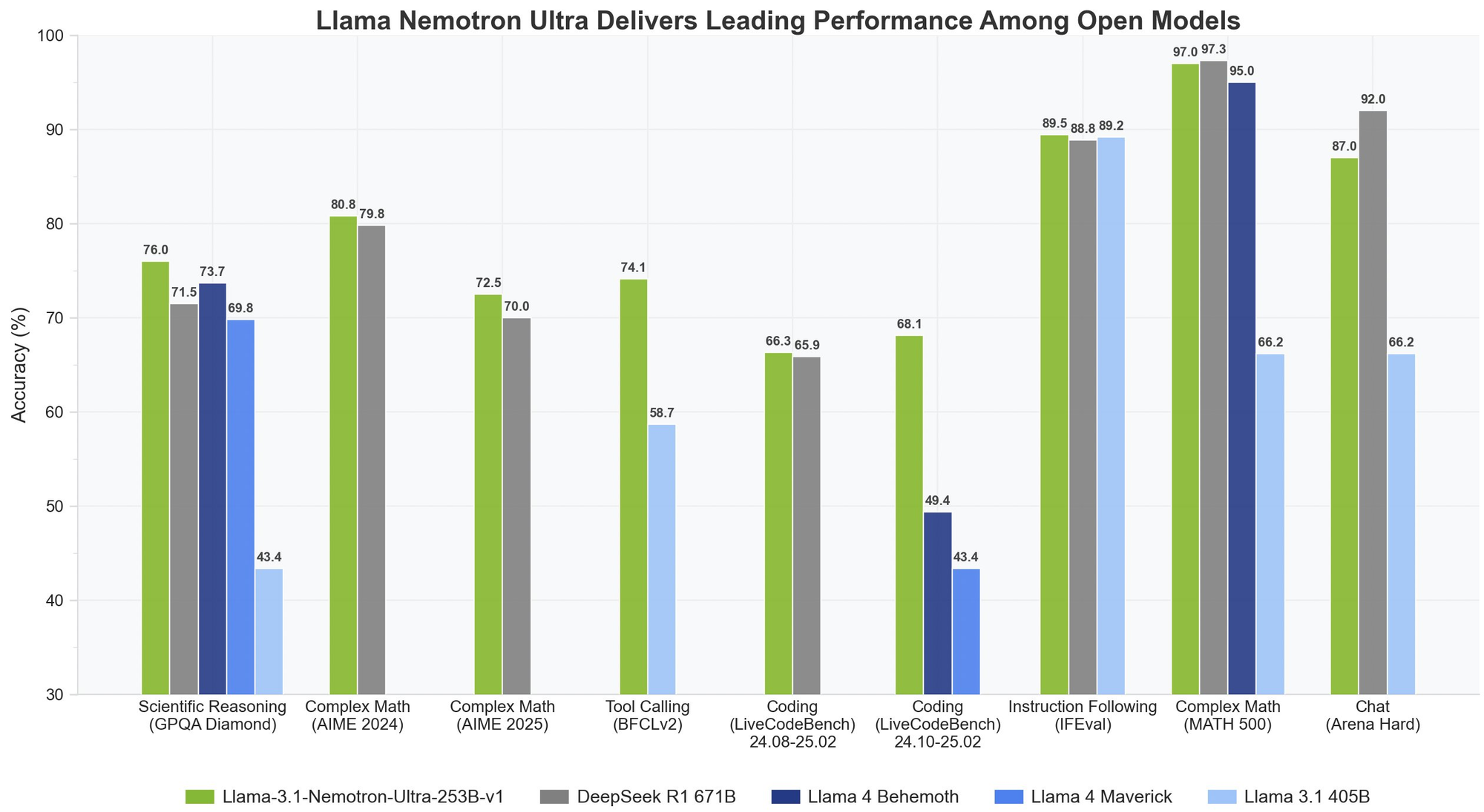
تقدم Llama Nemotron Ultra 253B نتائج استثنائية عبر مقاييس الاستدلال الحرجة، مع إظهار قدرتها الفريدة على "التفكير ON/OFF" اختلافات دراماتيكية في الأداء:
الاستدلال الرياضي
تتألق Llama Nemotron Ultra 253B حقًا في مهام الاستدلال الرياضي:
- MATH500
- التفكير OFF: 80.4%_pass@1
- التفكير ON: 97.0%_pass@1
بدرجة دقة تبلغ 97% مع تشغيل التفكير، تكاد Llama Nemotron Ultra 253B تكمل هذا المقياس الرياضي الصعب.
- AIME25 (اختبار الرياضيات الأمريكي)
- التفكير OFF: 16.7%_pass@1
- التفكير ON: 72.50%_pass@1
يظهر هذا التحسن الملحوظ البالغ 56 نقطة كيف أن قدرات الاستدلال لـ Llama Nemotron Ultra 253B تحول أدائها في حل مشاكل الرياضيات المعقدة.
الاستدلال العلمي
- GPQA (أسئلة وأجوبة فيزياء على مستوى الدراسات العليا)
- التفكير OFF: 56.6%_pass@1
- التفكير ON: 76.01%_pass@1
يعرض التحسن الكبير كيف يمكن لـ Llama Nemotron Ultra 253B معالجة مشاكل الفيزياء على مستوى دراسات الدراسات العليا من خلال التحليل المنهجي عندما يتم تفعيل التفكير.
برمجة واستخدام الأدوات
- LiveCodeBench (20240801-20250201)
- التفكير OFF: 29.03%_pass@1
- التفكير ON: 66.31%_pass@1
تضاعف Llama Nemotron Ultra 253B أكثر من ضعف أداء الترميز الخاص بها مع تفعيل التفكير.
- BFCL V2 Live (استدعاء الوظائف)
- التفكير OFF: 73.62 درجة
- التفكير ON: 74.10 درجة
يظهر هذا المقياس قدرات النموذج القوية في استخدام الأدوات في كلا الوضعين، وهو أمر حاسم لبناء وكلاء ذكاء اصطناعي فعالين.
اتباع التعليمات
- IFEval (تقييم اتباع التعليمات)
- التفكير OFF: 88.85% دقة صارمة
- التفكير ON: 89.45% دقة صارمة
يؤدي كلا الوضعين بشكل ممتاز، مما يظهر أن Llama Nemotron Ultra 253B تحافظ على قدرات قوية في اتباع التعليمات بغض النظر عن وضع التفكير.
Llama Nemotron Ultra 253B مقابل DeepSeek-R1
كان DeepSeek-R1 هو المعيار الذهبي لنماذج الاستدلال المفتوحة المصدر، لكن Llama Nemotron Ultra 253B تتطابق مع أو تتجاوز أدائها في مقاييس الاستدلال الرئيسية:
- على GPQA، تحقق Llama Nemotron Ultra 253B دقة تصل إلى 76.01%، متنافسة مع أداء DeepSeek-R1 من الدرجة الأولى
- تقدم Llama Nemotron Ultra 253B وضعين مختلفين للتفكير، على عكس نهج DeepSeek-R1 الثابت في التفكير
- توفر Llama Nemotron Ultra 253B قدرات متفوقة في استدعاء الوظائف، مما يجعلها أكثر تنوعًا لتطبيقات الوكيل.
Llama Nemotron Ultra 253B مقابل Llama 4
عند المقارنة مع طرازات Llama 4 Behemoth وMaverick القادمة:
- تظهر Llama Nemotron Ultra 253B أداءًا متفوقًا في مقاييس الاستدلال العلمي والرياضي المعقد
- يوفر مفتاح التفكير الصريح في Llama Nemotron Ultra 253B مرونة أكبر من نماذج Llama 4 القياسية
- تم تحسين Llama Nemotron Ultra 253B بشكل خاص لأجهزة NVIDIA، مما يوفر كفاءة استنتاج أفضل
لنختبر Llama Nemotron Ultra 253B عبر واجهة برمجة التطبيقات
تطبيق Llama Nemotron Ultra 253B في تطبيقاتك يتطلب اتباع خطوات معينة لضمان الأداء الأمثل:
الخطوة 1: الحصول على الوصول إلى واجهة برمجة التطبيقات
للوصول إلى Llama Nemotron Ultra 253B:
- قم بزيارة بوابة NVIDIA API على https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- سجل للحصول على مفتاح API إذا لم يكن لديك واحد بالفعل
- إذا كنت تعمل ضمن بيئة NGC من NVIDIA، قد يتم تبسيط تكوين مفتاح API
الخطوة 2: إعداد بيئة التطوير الخاصة بك
قبل إجراء مكالمات واجهة برمجة التطبيقات:
- قم بتثبيت حزمة OpenAI Python باستخدام
pip install openai - استورد المكتبة الضرورية:
from openai import OpenAI - قم بتكوين بيئتك لتخزين مفتاح API بشكل آمن
الخطوة 3: تكوين عميل واجهة برمجة التطبيقات
قم بتهيئة عميل OpenAI مع نهايات NVIDIA:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- على عكس Postman، يوفر Apidog تجربة أكثر تكاملاً مع وثائق واجهة برمجة التطبيقات المدمجة، واختبار تلقائي، وخوادم وهمية مصممة خصيصًا لنقاط نهاية نموذج الذكاء الاصطناعي.
- تسهّل واجهة Apidog البديهية تهيئة مجموعات المعلمات المعقدة اللازمة لاختبار واجهة برمجة التطبيقات، وتكون ميزات تصور الاستجابة مفيدة بشكل خاص لتحليل مخرجات النموذج المتدفقة.
- بينما لا يزال Postman أداة شائعة لاختبار واجهة برمجة التطبيقات، فإن ميزات Apidog الموجهة نحو الذكاء الاصطناعي وتدفق العمل المصدر يمكن أن تسارع بشكل كبير من عملية التطوير الخاصة بك.

الخطوة 4: تحديد وضع التفكير المناسب
تقدم Llama Nemotron Ultra 253B وضعين تشغيل مختلفين:
- التفكير ON: الأفضل للمشكلات المعقدة التي تتطلب تفكيرًا خطوة بخطوة (رياضيات، فيزياء، برمجة)
- التفكير OFF: الأمثل لاتباع التعليمات المباشرة والدردشة العامة
الخطوة 5: صياغة طلبات النظام والمستخدم
لوضع التفكير ON:
- قم بتعيين طلب النظام إلى
"تفكير مفصل على" - ضع جميع التعليمات في رسالة المستخدم
- اعتبر استخدام قوالب محددة للمهام المقاسة (مثل مشاكل الرياضيات)
لوضع التفكير OFF:
- قم بإزالة طلب التفكير عن النظام
- استخدم تعليمات واضحة وموجزة في رسالة المستخدم
الخطوة 6: تكوين معلمات الجيل
للحصول على نتائج مثلى:
- التفكير ON: ضع temperature=0.6 و top_p=0.95 كما أوصت NVIDIA
- التفكير OFF: استخدم فك تشفير جشع مع temperature=0
- حدد
max_tokensالمناسبة بناءً على طول الاستجابة المتوقع - اعتبر تمكين البث للاستجابات الفورية
الخطوة 7: إجراء طلب واجهة برمجة التطبيقات والتعامل مع الاستجابات
أنشئ طلب الإكمال الخاص بك مع تكوين جميع المعلمات:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "تفكير مفصل على"},
{"role": "user", "content": "طلبك هنا"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
الخطوة 8: معالجة وعرض الاستجابة
إذا كنت تستخدم البث:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
بالنسبة للاستجابات غير المتدفقة، يمكنك ببساطة الوصول إلى completion.choices[0].message.content.
الخاتمة
تمثل Llama Nemotron Ultra 253B تقدمًا كبيرًا في نماذج الاستدلال المفتوحة المصدر، حيث توفر أداءً رائدًا عبر مجموعة واسعة من المقاييس. تجعل أوضاع التفكير الثنائية الفريدة لها، إلى جانب قدرات استدعاء الوظائف الاستثنائية ونافذة السياق الكبيرة، منها خيارًا مثاليًا لتطبيقات الذكاء الاصطناعي المؤسسية التي تتطلب قدرات استدلال متقدمة.
مع دليل تنفيذ واجهة برمجة التطبيقات خطوة بخطوة الموضح في هذه المقالة، يمكن للمطورين استغلال الإمكانيات الكاملة لـ Llama Nemotron Ultra 253B لبناء أنظمة ذكاء اصطناعي متطورة تتعامل مع المشكلات المعقدة بتفكير يشبه تفكير البشر. سواء كنت تبني وكلاء ذكاء اصطناعي، أو تعزز أنظمة RAG، أو تطور تطبيقات متخصصة، توفر Llama Nemotron Ultra 253B أساسًا قويًا لقدرات الذكاء الاصطناعي من الجيل المقبل في حزمة مفتوحة المصدر ودية تجاريًا.