
هل أردت يومًا تشغيل نموذج لغة قوي على جهازك المحلي؟ نقدم لكم QwQ-32B، أحدث وأقوى نموذج لغة متاح من Alibaba. سواء كنت مطورًا، باحثًا، أو مجرد هاوٍ مهتم بالتكنولوجيا، فإن تشغيل QwQ-32B محليًا يمكن أن يفتح أمامك عالمًا من الإمكانيات — من بناء تطبيقات ذكاء صناعي مخصصة إلى تجربة مهام معالجة اللغة الطبيعية المتقدمة.
في هذا الدليل، سوف نأخذك خلال العملية بالكامل، خطوة بخطوة. سنستخدم أدوات مثل Ollama و LM Studio لجعل الإعداد سلسًا قدر الإمكان.
نظرًا لأنك ترغب في استخدام واجهات برمجة التطبيقات مع Ollama باستخدام أدوات اختبار API، فلا تنسَ الاطلاع على Apidog. إنه أداة رائعة لتبسيط سير عمل واجهات برمجة التطبيقات الخاصة بك، وأفضل جزء؟ يمكنك تنزيله مجانًا!
هل أنت مستعد للغوص؟ هيا بنا نبدأ!
1. فهم QwQ-32B؟
قبل أن نقفز إلى التفاصيل التقنية، دعنا نأخذ لحظة لفهم ما هو QwQ-32B. QwQ-32B هو نموذج لغة متطور يحتوي على 32 مليار معامل، مصمم للتعامل مع المهام المعقدة في معالجة اللغة الطبيعية مثل توليد النصوص والترجمة والتلخيص. إنه أداة متعددة الاستخدامات للمطورين والباحثين الذين يتطلعون إلى دفع حدود الذكاء الاصطناعي.
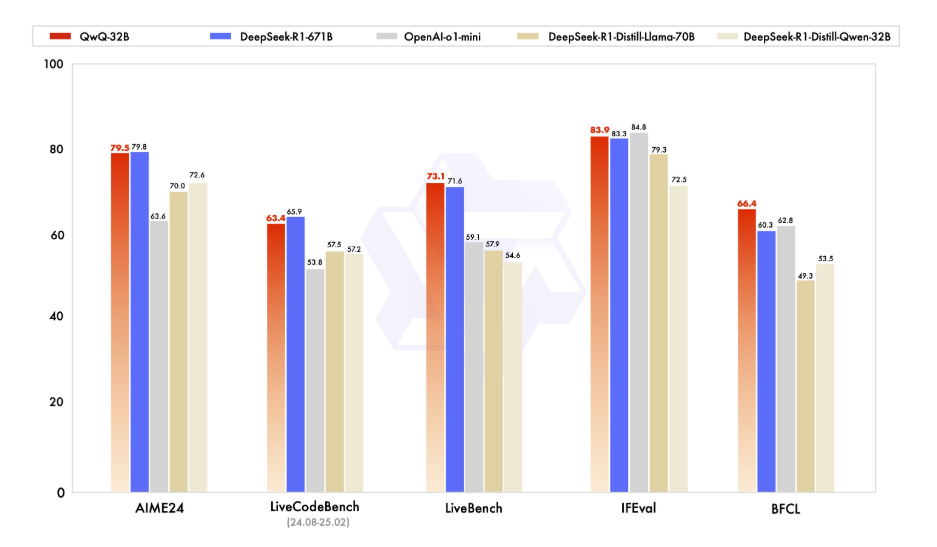
تشغيل QwQ-32B محليًا يمنحك السيطرة الكاملة على النموذج، مما يتيح لك تخصيصه للحالات الاستخدام المحددة دون الاعتماد على خدمات السحابة. الخصوصية، التخصيص، فعالية التكلفة، و الوصول دون اتصال هي بعض من العديد من الميزات التي يمكنك الاستفادة منها عند تشغيل هذا النموذج محليًا.
2. المتطلبات السابقة
يجب أن يلبي جهازك المحلي المتطلبات التالية قبل أن تتمكن من تشغيل QwQ-32B محليًا:
- الأجهزة: جهاز قوي بسعة لا تقل عن 16 جيجابايت من الذاكرة العشوائية و وحدة معالجة رسومات متطورة بسعة 24 جيجابايت على الأقل من ذاكرة الوصول العشوائي (مثل NVIDIA RTX 3090 أو أفضل) لتحقيق الأداء المثالي.
- البرامج: بايثون 3.8 أو أحدث، جيت، ومدير حزم مثل pip أو conda.
- الأدوات: Ollama و LMStudio (سنغطي هذه بالتفصيل لاحقًا).
3. تشغيل QwQ-32B محليًا باستخدام Ollama
Ollama هو إطار عمل خفيف يبسط عملية تشغيل نماذج اللغة الكبيرة محليًا. إليك كيفية تثبيته:
الخطوة 1: تنزيل وتثبيت Ollama:
- لـ Windows و macOS، قم بتنزيل الملف التنفيذي من الموقع الرسمي لـ Ollama وقم بتشغيله للتثبيت. ثم اتبع التعليمات البسيطة المقدمة في إعداد التثبيت.
- لمستخدمي Linux، يمكنك استخدام الأمر التالي:
curl -fsSL https://ollama.ai/install.sh | sh
- تحقق من التثبيت: بعد التثبيت، إذا كنت ترغب في التحقق من أنك قمت بتثبيت Ollama بشكل صحيح، افتح نافذة الأوامر وقم بتشغيل:
ollama --version
- إذا كان التثبيت ناجحًا، سترى رقم الإصدار.
الخطوة 2: العثور على نموذج QwQ-32B
- ارجع إلى موقع Ollama وانتقل إلى قسم "النماذج".
- استخدم شريط البحث للعثور على "QwQ-32B."
- بمجرد العثور على نموذج QwQ-32B، سترى أمر التثبيت المقدم على الصفحة.
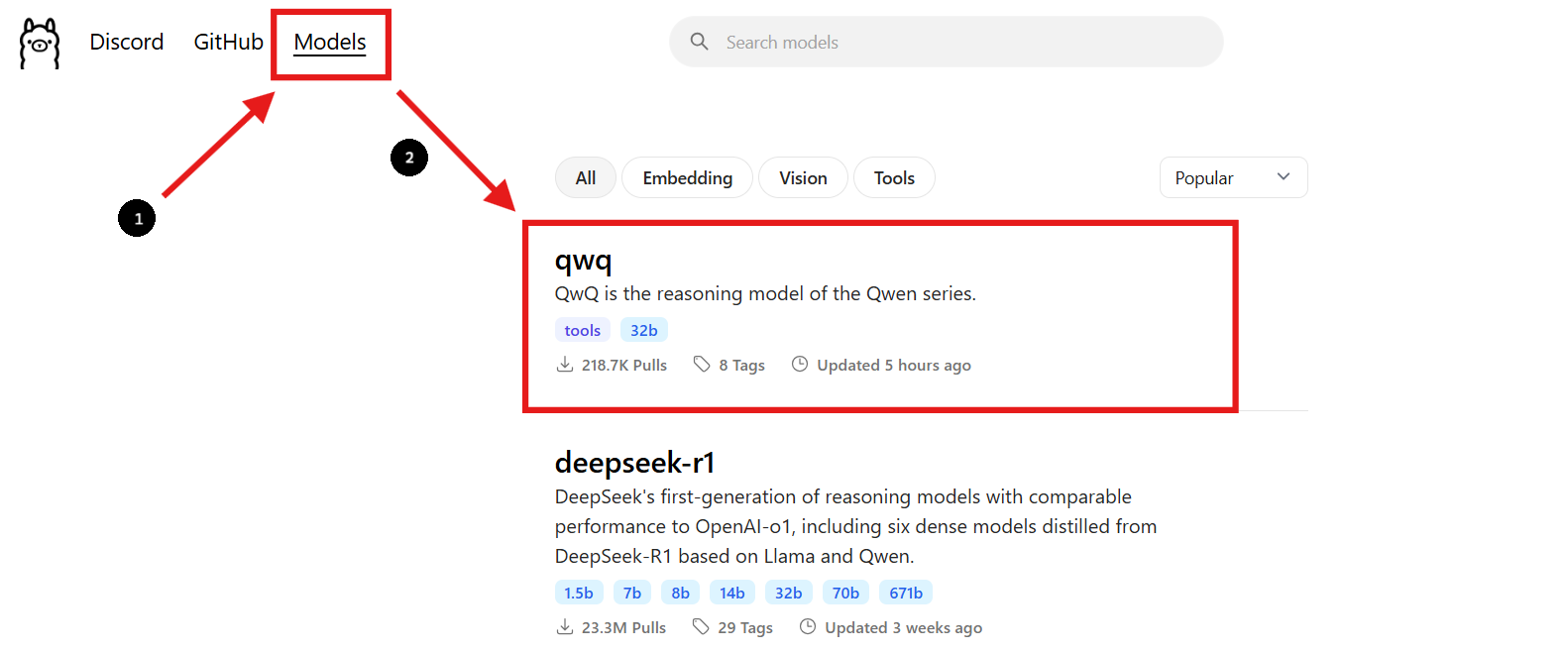
الخطوة 3: تنزيل نموذج QwQ-32B
- افتح نافذة أوامر جديدة لتنزيل النموذج وقم بتشغيل الأمر التالي:
ollama pull qwq:32b- بعد اكتمال التنزيل، يمكنك التحقق من أن النموذج تم تثبيته عن طريق تشغيل الأمر التالي:
ollama list
- سيسرد الأمر جميع النماذج التي قمت بتنزيلها باستخدام Ollama، مما يؤكد أن QwQ-32B متاح.
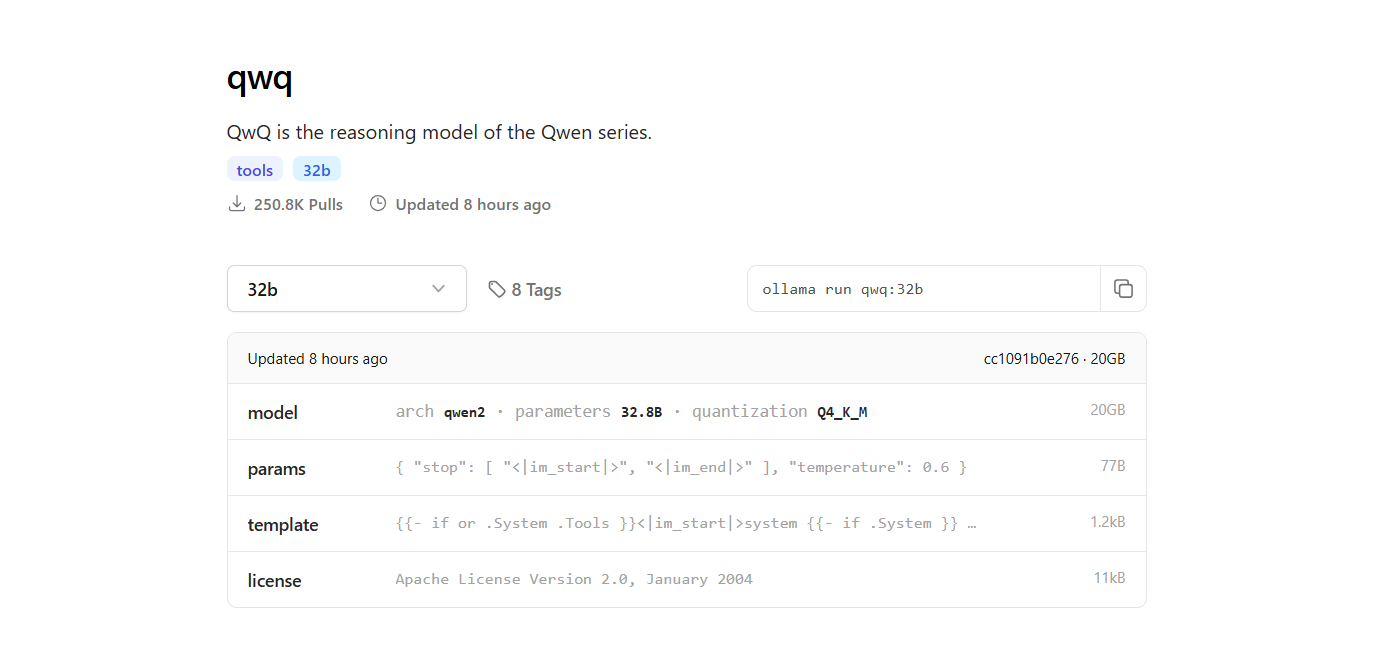
الخطوة 4: تشغيل نموذج QwQ-32B
تشغيل النموذج في نافذة الأوامر:
- للتفاعل مع نموذج QwQ-32B مباشرة في نافذة الأوامر، استخدم الأمر التالي:
ollama run qwq:32b
- يمكنك طرح أسئلة أو تقديم مطالبات في نافذة الأوامر، وسيرد النموذج وفقًا لذلك.
استخدم واجهة دردشة تفاعلية:
- بدلاً من ذلك، يمكنك استخدام أدوات مثل Chatbox أو OpenWebUI لإنشاء واجهة GUI تفاعلية للدردشة مع نموذج QwQ-32B.
- توفر هذه الواجهات طريقة أكثر سهولة للتفاعل مع النموذج، خاصة إذا كنت تفضل واجهة رسومية على واجهة سطر الأوامر.
4. تشغيل QwQ-32B محليًا باستخدام LM Studio
LM Studio هو واجهة سهلة الاستخدام لتشغيل وإدارة نماذج اللغة محليًا. إليك كيفية إعدادها:
الخطوة 1: تنزيل LM Studio:
- للبدء، قم بزيارة الموقع الرسمي لـ LM Studio على lmstudio.ai. هنا يمكنك تنزيل تطبيق LM Studio لنظام التشغيل الخاص بك.
- على صفحتهم، انتقل إلى قسم التنزيل واختر الإصدار الذي يتناسب مع نظام التشغيل الخاص بك (Windows أو macOS أو Linux).
الخطوة 2: تثبيت LM Studio:
- اتبع التعليمات البسيطة للتثبيت الخاصة بنظام التشغيل الخاص بك.
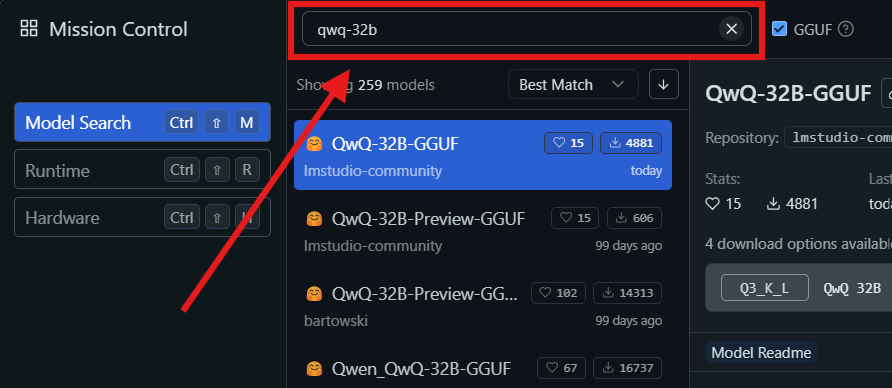
الخطوة 3: العثور على نموذج QwQ-32B وتنزيله:
- افتح LM Studio وانتقل إلى قسم "نماذجي".
- انقر على أيقونة البحث واكتب "QwQ-32B" في شريط البحث.
- اختر الإصدار المطلوب من نموذج QwQ-32B من نتائج البحث. قد تجد نسخ مختلفة تم تقليص حجمها، مثل نموذج بحجم 4-بت، مما يمكن أن يساعد في تقليل استخدام الذاكرة مع الحفاظ على الأداء.
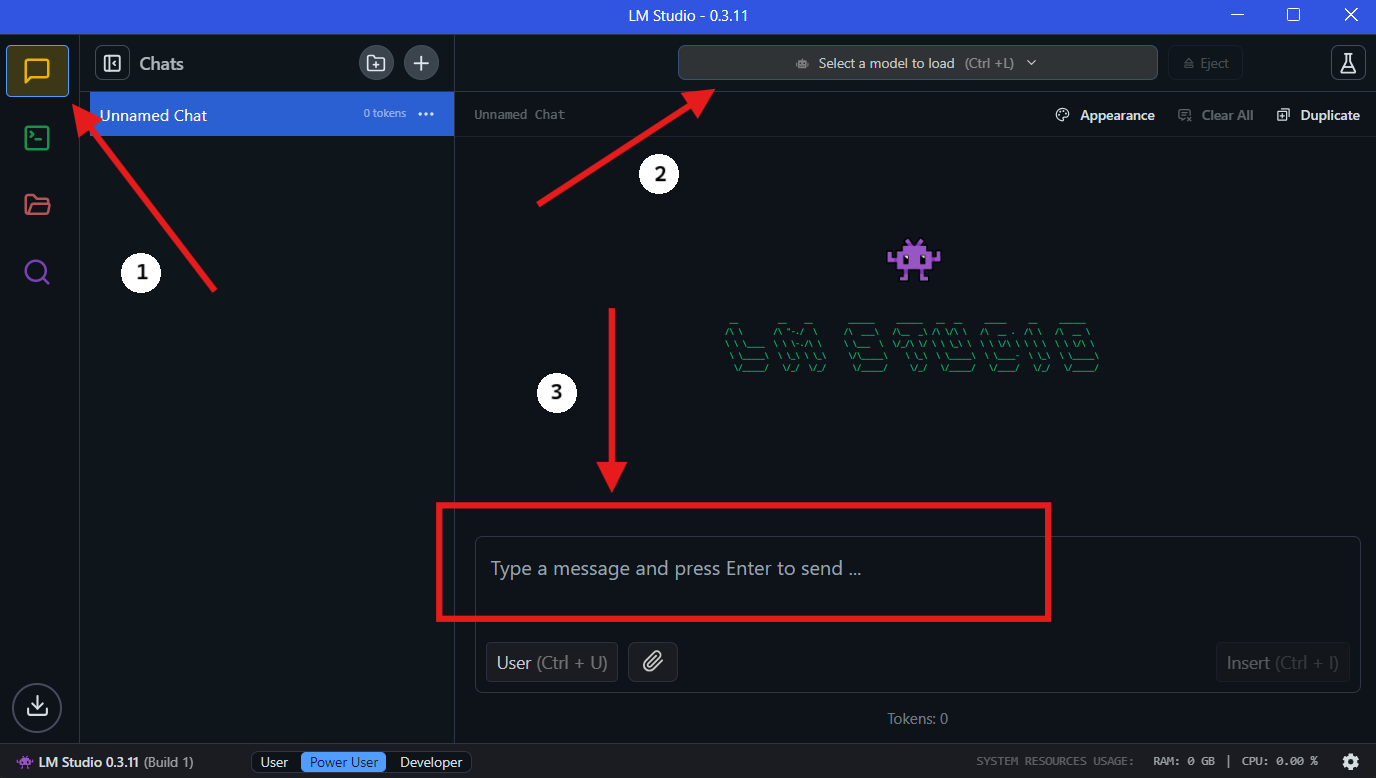
الخطوة 4: تشغيل QwQ-32B محليًا في LM Studio
- اختر النموذج: بمجرد اكتمال التنزيل، انتقل إلى قسم "الدردشة" في LM Studio. في واجهة الدردشة، اختر نموذج QwQ-32B من القائمة المنسدلة.
- التفاعل مع QwQ-32B: ابدأ بطرح الأسئلة أو تقديم المطالبات في نافذة الدردشة. سيقوم النموذج بمعالجة مدخلاتك وتوليد الردود.
- تكوين الإعدادات: يمكنك ضبط إعدادات النموذج بناءً على تفضيلاتك في علامة التبويب "تكوين متقدم".
5. تبسيط تطوير واجهة برمجة التطبيقات باستخدام Apidog
يتطلب دمج QwQ-32B في تطبيقاتك إدارة فعالة لواجهات برمجة التطبيقات. Apidog هو منصة تطوير واجهات برمجة التطبيقات التعاونية الشاملة التي تبسط هذه العملية. الميزات الرئيسية لـ Apidog تشمل تصميم API، توثيق API و تصحيح API.
لتسهيل عملية الدمج، اتبع هذه الخطوات لإعداد Apidog لإدارة واختبار واجهات برمجة التطبيقات الخاصة بك مع QwQ-32B.

الخطوة 1: تنزيل وتثبيت Apidog
- قم بزيارة الموقع الرسمي لـ Apidog وقم بتنزيل الإصدار المتوافق مع نظام التشغيل الخاص بك (Windows أو macOS أو Linux).
- اتبع تعليمات التثبيت لإعداد Apidog على جهازك.
الخطوة 2: إنشاء مشروع API جديد
- افتح Apidog وقم بإنشاء مشروع API جديد.
- حدد نقاط نهاية واجهة برمجة التطبيقات، مع تحديد تنسيقات الطلبات والاستجابات للتفاعل مع QwQ-32B.
الخطوة 3: ربط QwQ-32B بـ Apidog عبر واجهة برمجة التطبيقات المحلية
للتفاعل مع QwQ-32B من خلال واجهة برمجة التطبيقات، تحتاج إلى كشف النموذج باستخدام خادم محلي. استخدم FastAPI أو Flask لإنشاء واجهة برمجة تطبيقات لنموذج QwQ-32B المحلي الخاص بك.
مثال: إعداد خادم FastAPI لـ QwQ-32B:
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# يشغل بـ: uvicorn script_name:app --reload
الخطوة 4: اختبار استدعاءات API باستخدام Apidog
- افتح Apidog وأنشئ طلب POST إلى
http://localhost:8000/generate. - أدخل نموذج منبه في جسم الطلب وانقر على "إرسال".
- إذا كان كل شيء مُعدًا بشكل صحيح، يجب أن تحصل على رد مُولد من QwQ-32B.
الخطوة 5: أتمتة اختبار واجهة برمجة التطبيقات وتصحيح الأخطاء
- استخدم الميزات المدمجة للاختبار في Apidog لمحاكاة مدخلات مختلفة وتحليل كيفية استجابة QwQ-32B.
- قم بضبط معلمات الطلب وتحسين أداء واجهة برمجة التطبيقات من خلال مراقبة أوقات الاستجابة.
🚀 مع Apidog، تصبح إدارة سير عمل واجهات برمجة التطبيقات لديك بلا جهد، مما يضمن تكامل سلس بين QwQ-32B وتطبيقاتك.
6. نصائح لتحسين الأداء
قد يكون تشغيل نموذج بحجم 32 مليار معامل كثيف الموارد. إليك بعض النصائح لتحسين الأداء:
- استخدم وحدة معالجة رسومات عالية الجودة: ستسرع وحدة معالجة الرسوميات القوية بشكل كبير من تنفيذ الاستدلال.
- تعديل حجم الدفعة: جرب أحجام دفعات مختلفة للعثور على الإعداد الأمثل.
- مراقبة استخدام الموارد: استخدم أدوات مثل
htopأوnvidia-smiلمراقبة استخدام وحدة المعالجة المركزية ووحدة معالجة الرسوميات.
7. استكشاف المشكلات الشائعة وإصلاحها
قد يكون تشغيل QwQ-32B محليًا أحيانًا صعبًا. إليك بعض المشكلات الشائعة وكيفية إصلاحها:
- نفاذ الذاكرة: قلل من حجم الدفعة أو قم بترقية أجهزتك.
- أداء بطيء: تأكد من تحديث برامج تشغيل وحدة معالجة الرسوميات لديك.
- النموذج لا يقوم بالتحميل: تحقق دوبل من مسار النموذج وسلامة الملفات.
8. أفكار أخيرة
يعد تشغيل QwQ-32B محليًا طريقة قوية للاستفادة من قدرات نماذج الذكاء الاصطناعي المتقدمة دون الاعتماد على خدمات السحابة. مع أدوات مثل Ollama و LM Studio، أصبحت العملية أكثر سهولة من أي وقت مضى.
وتذكر، إذا كنت تعمل مع واجهات برمجة التطبيقات، فإن Apidog هو الأداة التي ستحتاجها للاختبار والتوثيق. قم بتنزيلها مجانًا وارتقِ بسير عمل واجهات برمجة التطبيقات لديك إلى المستوى التالي!