
Se você é um desenvolvedor web, provavelmente sabe como é importante se comunicar efetivamente com os servidores web que hospedam suas aplicações. Você precisa enviar os pedidos certos e receber as respostas certas, para que suas aplicações possam funcionar corretamente e proporcionar uma ótima experiência ao usuário. Mas você sabe como usar o cabeçalho accept do HTTP para otimizar essa comunicação e tornar suas aplicações mais flexíveis e eficientes? Se não, não se preocupe.
Neste post do blog, eu vou te ensinar tudo que você precisa saber sobre o cabeçalho accept do HTTP e como usar ferramentas como o Apidog para testar e depurar suas solicitações e respostas HTTP.
O que é o Cabeçalho Accept do HTTP e como ele funciona?
O cabeçalho accept do HTTP é parte da mensagem de solicitação. É uma forma do cliente informar ao servidor que tipo de conteúdo pode aceitar e processar. O conteúdo pode ser qualquer coisa que o servidor pode fornecer, como HTML, XML, JSON, imagens, vídeos, áudio, etc. O cabeçalho accept do HTTP tem o seguinte formato:
Accept: tipo-de-mídia, tipo-de-mídia, ...
O tipo-de-mídia é uma string que especifica o tipo e subtipo do conteúdo, como text/html, application/json, image/jpeg, etc. Você também pode usar caracteres curinga para indicar qualquer tipo ou subtipo, como */*, text/*, image/*, etc. Você também pode usar parâmetros para fornecer mais detalhes sobre o conteúdo, como a qualidade, o idioma, a codificação, etc. Por exemplo, text/html;q=0.8,en-US significa que o cliente pode aceitar documentos HTML com uma qualidade de 0.8 (de 1) e em inglês dos EUA.
Você pode especificar múltiplos tipos-de-mídia no cabeçalho accept do HTTP, separados por vírgulas. A ordem dos tipos-de-mídia indica a preferência do cliente. O primeiro tipo-de-mídia é o mais preferido, o segundo é o segundo mais preferido, e assim por diante. Por exemplo, Accept: text/html,application/json,image/png significa que o cliente prefere documentos HTML, depois dados JSON, depois imagens PNG.
Por que o Cabeçalho Accept do HTTP é importante?
O cabeçalho accept do HTTP é uma forma poderosa de negociar o conteúdo entre o cliente e o servidor. Ele permite que o cliente solicite diferentes tipos de conteúdo com base em suas capacidades e preferências, e permite que o servidor entregue o melhor conteúdo possível para o cliente, com base em sua disponibilidade e compatibilidade. Isso pode melhorar o desempenho, a eficiência e a experiência do usuário tanto do cliente quanto do servidor.
O cabeçalho accept do HTTP é importante porque ajuda o servidor a entregar o melhor conteúdo possível para o cliente, com base em suas capacidades e preferências. Ele também ajuda o servidor a evitar enviar dados desnecessários ou incompatíveis que o cliente não pode usar ou exibir. Isso pode melhorar o desempenho, a eficiência e a experiência do usuário tanto do cliente quanto do servidor.
Como usar o Cabeçalho Accept do HTTP para solicitar diferentes tipos de conteúdo do servidor
Para escrever o cabeçalho accept do HTTP na sua mensagem de solicitação, você precisa usar uma ferramenta ou uma biblioteca que permita enviar solicitações HTTP. Existem muitas ferramentas e bibliotecas disponíveis para diferentes linguagens e plataformas, como curl, Apidog, Axios, Fetch, etc. Para este exemplo, eu vou usar curl, que é uma ferramenta de linha de comando que você pode usar para enviar solicitações HTTP e receber respostas HTTP.
Para usar curl, você precisa digitar o seguinte comando no seu terminal:
curl -H "Accept: tipo-de-mídia, tipo-de-mídia, ..." URL
A opção -H permite que você adicione um cabeçalho à sua solicitação. O Accept: tipo-de-mídia, tipo-de-mídia, ... é o cabeçalho accept do HTTP que você deseja enviar. O URL é o endereço do servidor de onde você deseja solicitar dados. Por exemplo, se você quiser solicitar documentos HTML de https://example.com, você pode digitar:
curl -H "Accept: text/html" https://example.com
Isso enviará uma solicitação para https://example.com com o cabeçalho Accept: text/html, significando que você pode aceitar apenas documentos HTML como resposta.
Para ler a mensagem de resposta do servidor, você precisa olhar o código de status, o cabeçalho content-type e o corpo da mensagem.
Por exemplo, se você enviar a solicitação curl -H "Accept: text/html" https://example.com, você pode receber a seguinte resposta:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
<html>
<head>
<title>Domínio de Exemplo</title>
</head>
<body>
<h1>Domínio de Exemplo</h1>
<p>Este domínio é para uso em exemplos ilustrativos em documentos. Você pode usar este domínio em literatura sem coordenação prévia ou pedir permissão.</p>
<p><a href="https://www.iana.org/domains/example">Mais informações...</a></p>
</body>
</html>
O código de status é 200, significando que a solicitação foi bem-sucedida. O cabeçalho content-type é text/html; charset=UTF-8, significando que o servidor enviou de volta um documento HTML com codificação UTF-8.
Você pode usar o cabeçalho accept do HTTP para solicitar diferentes tipos de conteúdo do servidor alterando o tipo-de-mídia na sua solicitação. Por exemplo, se você quiser solicitar dados JSON de https://example.com, você pode digitar:
curl -H "Accept: application/json" https://example.com
Isso enviará uma solicitação para https://example.com com o cabeçalho Accept: application/json, significando que você pode aceitar apenas dados JSON como resposta. Você pode receber a seguinte resposta:
HTTP/1.1 200 OK
Content-Type: application/json
{
"domain": "example.com",
"purpose": "exemplos ilustrativos em documentos",
"link": "https://www.iana.org/domains/example"
}
O código de status é 200, significando que a solicitação foi bem-sucedida. O cabeçalho content-type é application/json, significando que o servidor enviou de volta dados JSON. O corpo da mensagem é os dados JSON propriamente ditos, que você pode ver no seu navegador ou no site do Apidog.
Você também pode solicitar múltiplos tipos de conteúdo do servidor especificando mais de um tipo-de-mídia na sua solicitação. Por exemplo, se você quiser solicitar documentos HTML ou dados JSON de https://example.com, você pode digitar:
curl -H "Accept: text/html,application/json" https://example.com
Como lidar com diferentes tipos de respostas do servidor com base no cabeçalho Accept do HTTP
Às vezes, o servidor pode não ser capaz de enviar de volta o tipo exato de conteúdo que você solicitou com o cabeçalho accept do HTTP. Isso pode acontecer por várias razões, como:
- O servidor não tem o conteúdo no formato que você solicitou
- O servidor tem o conteúdo no formato que você solicitou, mas não está disponível no momento
- O servidor tem o conteúdo no formato que você solicitou, mas não está autorizado a compartilhá-lo com você
- O servidor tem o conteúdo no formato que você solicitou, mas é muito grande ou muito complexo para enviar de volta
- O servidor não entende ou não suporta o tipo-de-mídia que você solicitou
Existem muitos códigos de status possíveis que o servidor pode enviar de volta, mas aqui estão alguns dos mais comuns que você pode encontrar ao usar o cabeçalho accept do HTTP:
- 200 (OK): Isso significa que a solicitação foi bem-sucedida e o servidor enviou de volta o tipo exato de conteúdo que você solicitou com o cabeçalho accept do HTTP. Por exemplo, se você enviar a solicitação
curl -H "Accept: text/html" https://example.com, e o servidor enviar de volta um documento HTML com o código de status 200, isso significa que tudo correu bem e você pode usar o documento HTML como desejar. - 206 (Conteúdo Parcial): Isso significa que a solicitação foi bem-sucedida e o servidor enviou de volta um tipo diferente de conteúdo que você também pode aceitar com o cabeçalho accept do HTTP. Por exemplo, se você enviar a solicitação
curl -H "Accept: text/html,application/json" https://example.com, e o servidor enviar de volta dados JSON com o código de status 206, isso significa que o servidor não pôde fornecer documentos HTML, mas pôde fornecer dados JSON, que você também pode aceitar. Você pode usar os dados JSON como desejar, mas deve estar ciente que não é o tipo preferido de conteúdo que você solicitou. - 406 (Não Aceitável): Isso significa que a solicitação falhou e o servidor não pôde fornecer nenhum tipo de conteúdo que você possa aceitar com o cabeçalho accept do HTTP. Por exemplo, se você enviar a solicitação
curl -H "Accept: text/html" https://example.com, e o servidor enviar de volta uma mensagem de erro com o código de status 406, isso significa que o servidor não possui documentos HTML para enviar de volta, e não tem nenhum outro tipo de conteúdo que você possa aceitar. Você não pode usar a mensagem de erro como desejar, mas deve lê-la cuidadosamente e tentar entender por que o servidor não pôde enviar o conteúdo que você solicitou. Você pode precisar alterar sua solicitação ou entrar em contato com o administrador do servidor para obter mais informações. - 415 (Tipo de Mídia Não Suportado): Isso significa que a solicitação falhou e o servidor não entende ou não suporta o tipo-de-mídia que você solicitou com o cabeçalho accept do HTTP. Por exemplo, se você enviar a solicitação
curl -H "Accept: application/x-custom" https://example.com, e o servidor enviar de volta uma mensagem de erro com o código de status 415, isso significa que o servidor não sabe o que éapplication/x-custom, e não pode fornecer conteúdo nesse formato. Você não pode usar a mensagem de erro como desejar, mas deve lê-la cuidadosamente e tentar entender por que o servidor não suporta o tipo-de-mídia que você solicitou. Você pode precisar alterar sua solicitação ou entrar em contato com o administrador do servidor para obter mais informações.
O cabeçalho content-type e o corpo da mensagem de resposta também podem variar dependendo do código de status e do tipo-de-mídia que o servidor enviou de volta. Você pode usar ferramentas como Apidog para visualizar o cabeçalho content-type e o corpo da mensagem de uma forma amigável ao usuário.
Como usar o Apidog para testar e depurar meu cabeçalho accept do HTTP?
Apidog é uma ferramenta baseada na web que ajuda você a testar, depurar e documentar suas APIs gratuitamente.
Para usar o Apidog para testar e depurar seu cabeçalho accept do HTTP, você precisa seguir estas etapas:
- Clique no botão “Nova Solicitação” para criar uma nova solicitação HTTP.
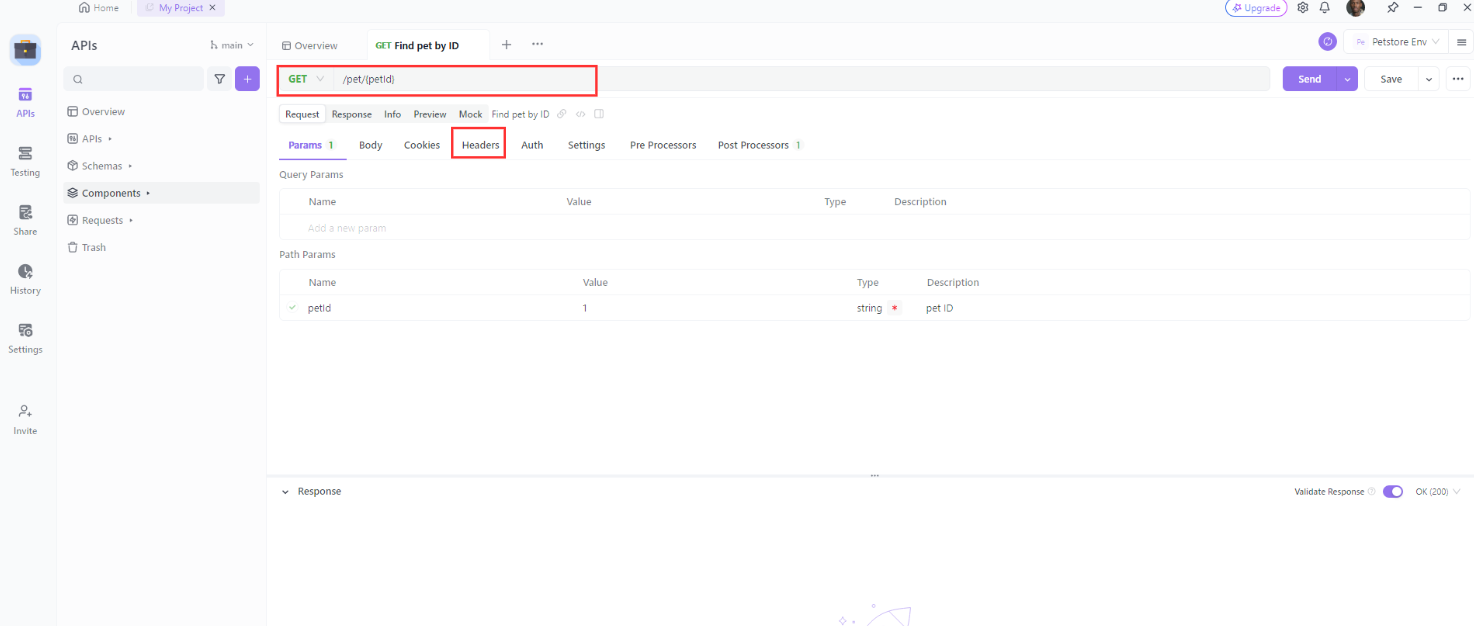
- Selecione o método HTTP (GET, POST, PUT, etc.) no menu suspenso e insira a URL do endpoint da API que você deseja testar no campo “URL” e depois clique na seção “Cabeçalhos” para abri-la.
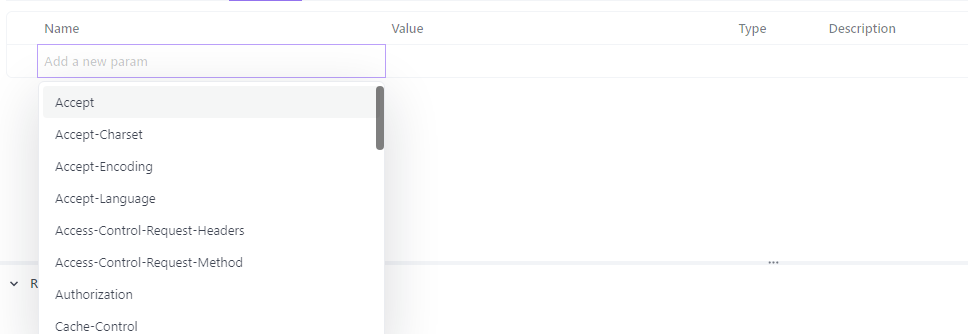
- Você geralmente verá uma lista de cabeçalhos com campos para “Nome” e “Valor”.

- Para adicionar um novo cabeçalho, basta clicar no nome e selecionar o nome e o tipo de conteúdo que você deseja solicitar como o valor. Por exemplo,
Accept: application/jsonsignifica que você deseja receber dados JSON do servidor.

- Envie sua solicitação ao servidor e você verá a resposta do servidor na seção “Resposta”. Você pode inspecionar o código de status, os cabeçalhos de resposta e o corpo da resposta.
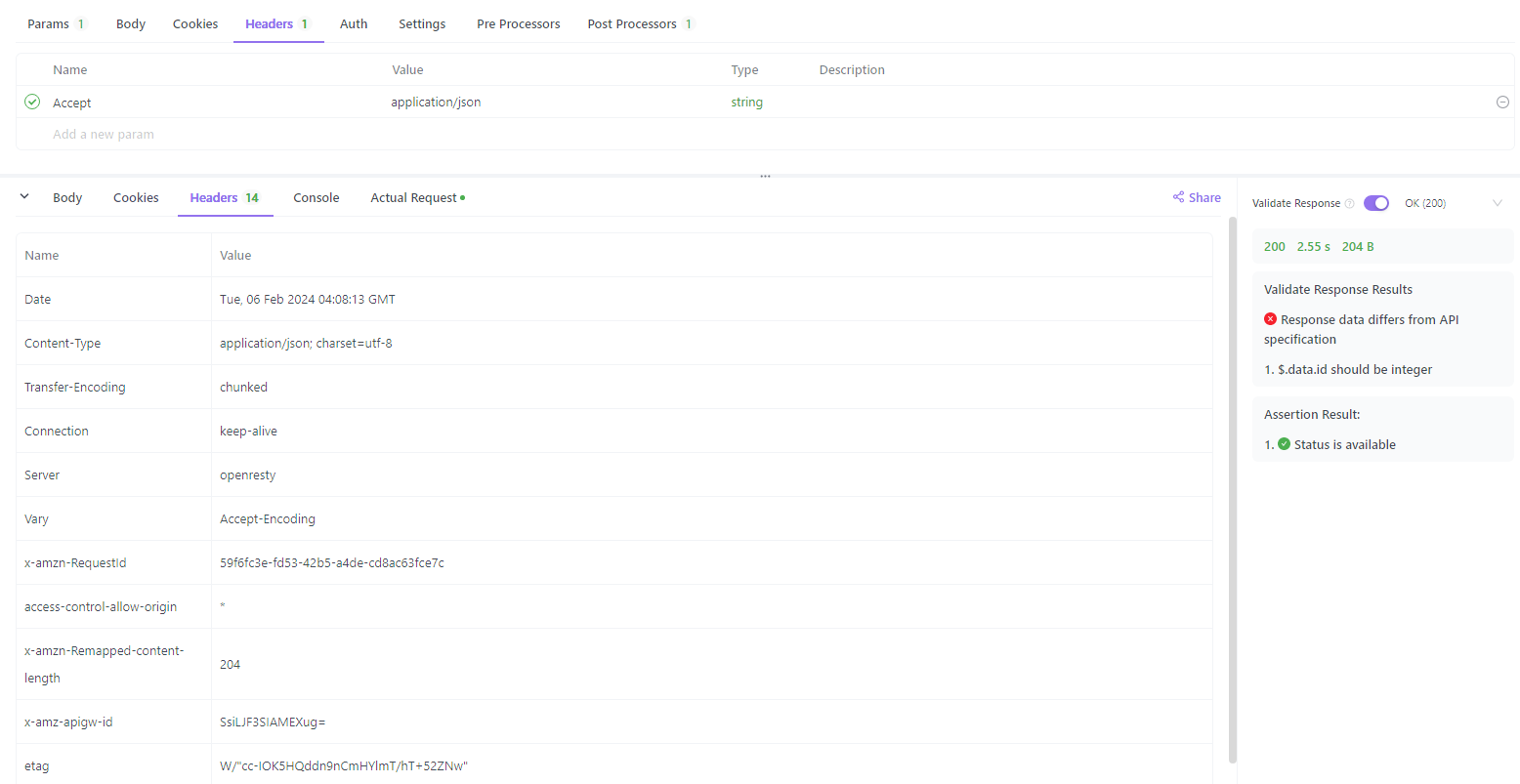
- Para verificar se o servidor respeita seu cabeçalho accept do HTTP, olhe o cabeçalho “Content-Type” na resposta. Deve corresponder a um dos tipos de conteúdo que você solicitou na solicitação. Por exemplo, se você solicitou
Accept: application/json, a resposta deve terContent-Type: application/json.

Melhores práticas e dicas para usar o cabeçalho accept do HTTP.
O cabeçalho accept do HTTP é um cabeçalho de solicitação que indica quais tipos de conteúdo, expressos como tipos MIME, o cliente é capaz de entender. O servidor usa a negociação de conteúdo para selecionar uma das propostas e informa ao cliente da escolha com o cabeçalho de resposta Content-Type. Aqui estão algumas melhores práticas e dicas para usar o cabeçalho accept do HTTP em seus projetos de desenvolvimento web:
- Use a sintaxe de valor de qualidade para especificar a ordem de preferência dos tipos de conteúdo. Por exemplo,
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8significa que o cliente prefere HTML, depois XHTML, depois XML, e qualquer outro tipo. - Use o caractere curinga (*) para indicar que o cliente pode aceitar qualquer subtipo ou qualquer tipo. Por exemplo,
Accept: image/*significa que o cliente pode aceitar qualquer formato de imagem, eAccept: */*significa que o cliente pode aceitar qualquer tipo de conteúdo. - Seja específico sobre os tipos de conteúdo que o cliente pode lidar e evite usar
Accept: */*a menos que seja necessário. Isso pode ajudar o servidor a enviar o formato mais apropriado para o cliente e evitar o envio de dados desnecessários que o cliente não pode processar. - Teste seu cabeçalho accept do HTTP com diferentes servidores web e serviços web, e verifique o cabeçalho de resposta Content-Type para ver se o servidor respeita suas preferências. Você pode usar ferramentas como curl ou Apidog para enviar solicitações HTTP personalizadas e inspecionar os cabeçalhos de resposta.
Conclusão
Neste post, eu expliquei a importância do cabeçalho Accept do HTTP e como ele pode ser usado para negociar o tipo de conteúdo entre o cliente e o servidor. Também mostrei como configurar o cabeçalho Accept em diferentes cenários.
Ao usar o cabeçalho Accept, podemos garantir que o servidor responda com o formato mais apropriado para nossas necessidades, e evitar conversões ou erros desnecessários. O cabeçalho Accept é um dos muitos cabeçalhos HTTP que podem nos ajudar a construir aplicações web mais robustas e eficientes.


