
開発者は、アプリケーションにおける推論、コーディング、問題解決を強化するために、常に高度なAIモデルを求めています。Qwen3-Max-Thinking APIは、これらの分野で限界を押し広げるプレビュー版として際立っています。このガイドでは、エンジニアがこのAPIに効果的にアクセスし、実装する方法を説明します。さらに、プロセスを簡素化するツールも紹介します。
Qwen3-Max-Thinking APIはAlibaba Cloudによって提供され、強化された思考機能の早期プレビューを提供します。トレーニング中の中間チェックポイントとしてリリースされたこのモデルは、ツール利用とスケーリングされたコンピューティングと組み合わせることで、AIME 2025やHMMTなどのベンチマークで目覚ましいパフォーマンスを達成しています。さらに、ユーザーはenable_thinking=Trueのようなパラメータを通じて思考モードを簡単にアクティブ化できます。トレーニングが進むにつれて、さらに強力な機能が期待されます。この記事では、登録から高度な使用法まで、Qwen3-Max-Thinking APIをワークフローにスムーズに統合するために必要なすべてを網羅しています。
Qwen3-Max-Thinking APIを理解する
エンジニアは、Qwen3-Max-Thinking APIを、推論タスクの優位性のために特別に設計されたAlibabaのQwenシリーズの進化形として認識しています。標準的なモデルとは異なり、このプレビュー版には、数学、コーディング、科学分析などの分野で推論の深さをユーザーが制御できる「思考バジェット」が組み込まれています。Alibabaは、トレーニングが継続中であるにもかかわらず、進捗状況を示すためにこのバージョンをリリースしました。

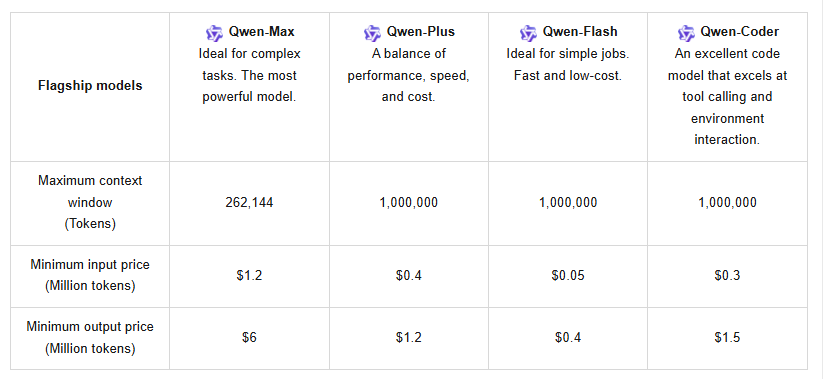
ベースとなるQwen3-Maxモデルは、1兆以上のパラメータと36兆トークンでのトレーニングを誇り、前身のQwen2.5のデータ量を2倍にしています。262,144トークンという巨大なコンテキストウィンドウをサポートし、最大入力は258,048トークン、最大出力は65,536トークンです。さらに、100以上の言語に対応しており、グローバルなアプリケーションに多用途です。しかし、Qwen3-Max-Thinkingバリアントは、エージェント機能を付加し、幻覚を減らし、Qwen-Agentツール呼び出しを通じて多段階プロセスを可能にします。
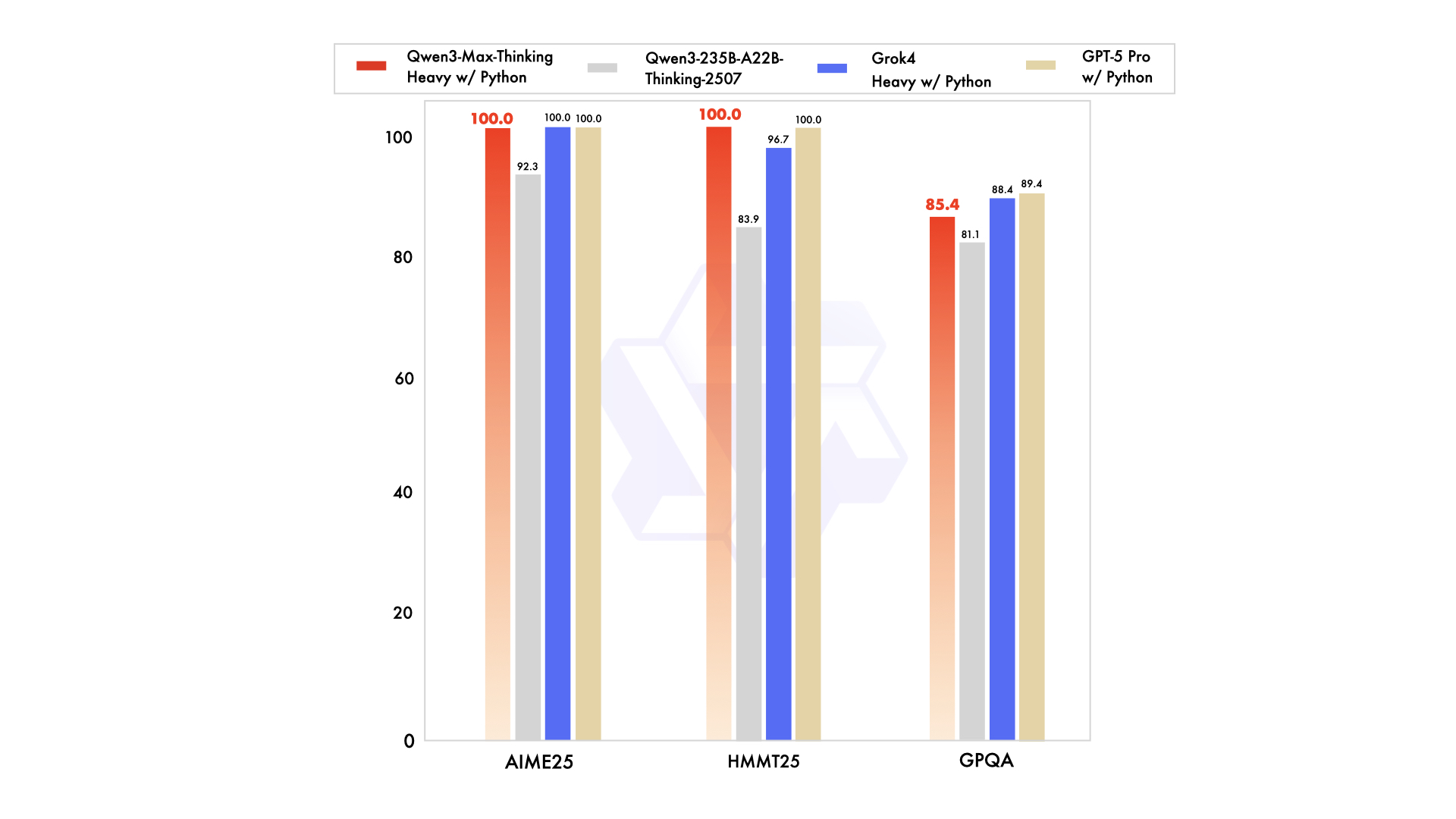
パフォーマンス指標はその強みを強調しています。例えば、コーディングではLiveCodeBench v6で74.8点、数学ではAIME25で81.6点を獲得しています。拡張時には、AIME 2025やHMMTのような困難なベンチマークで100%に達します。それにもかかわらず、このプレビュー版は最初は非思考型指示モデルとして動作し、特定のフラグを介して推論機能が強化されます。開発者は、OpenAI標準との互換性を維持し、簡単な移行を可能にするAlibaba CloudのAPIを通じてこれにアクセスします。
さらに、このAPIはコンテキストキャッシュをサポートしており、繰り返しのクエリを最適化し、コストを削減します。料金は段階的な構造になっており、0~32Kトークンの場合、入力は100万トークンあたり1.2ドル、出力は100万トークンあたり6ドルです。32K~128Kの場合、入力は2.4ドル、出力は12ドルに上昇します。128K~252Kの場合、入力は3ドル、出力は15ドルになります。新規ユーザーは、90日間有効な100万トークンの無料枠を利用でき、初期テストを奨励します。
Claude Opus 4やDeepSeek-V3.1のような競合他社と比較して、Qwen3-Max-ThinkingはSWE-Bench Verifiedで72.5を記録するなど、エージェントタスクにおいて優れています。しかし、そのプレビュー版というステータスは、完全な思考バジェットのような一部の機能がまだ開発中であることを意味します。ユーザーは、インタラクティブなセッションにはQwen Chatを、プログラムによるアクセスにはAPIを介して試すことができます。この設定により、Qwen3-Max-Thinking APIは、ソフトウェア開発、教育、企業オートメーションにとって重要なツールとして位置づけられます。
Qwen3-Max-Thinking APIにアクセスするための前提条件
開発者は作業を進める前に、必要な要件を収集します。まず、Alibaba Cloudアカウントがない場合は作成します。Alibaba Cloudのウェブサイトにアクセスし、メールアドレスまたは電話番号を使用してサインアップします。提供されたリンクまたはコードを通じてアカウントを認証し、完全なアクセスを有効にします。
次に、RESTfulエンドポイントやJSONペイロードを含むAPIの概念に精通していることを確認してください。Qwen3-Max-Thinking APIはHTTPSプロトコルを使用するため、セキュアな接続が重要です。さらに、開発ツールを準備します。HTTP呼び出しには、Python 3.xまたはrequestsのようなライブラリを持つ同様の言語を使用します。高度な統合には、複数のGPUで効率的なサービスをサポートするvLLMやSGLangなどのフレームワークを検討してください。
認証にはAlibaba CloudからのAPIキーが必要です。ログイン後、コンソールに移動し、API管理セクションでキーを生成します。これらはモデルエンドポイントへのアクセスを許可するため、安全に保管してください。さらに、使用ポリシーを遵守し、レート制限を防ぐために過度な呼び出しを避けてください。システムは最新バージョンとスナップショットバージョンを提供しており、高負荷下での安定したパフォーマンスのためにはスナップショットを選択してください。
ローカルテストにはハードウェアの考慮事項が適用されますが、クラウドアクセスによりこれは軽減されます。このモデルはかなりの計算能力を要求しますが、Alibabaのインフラストラクチャがそれを処理します。最後に、テストを効率化するためにApidogのようなサポートツールをダウンロードしてください。Apidogはリクエスト、環境、およびコラボレーションを管理するため、Qwen3-Max-Thinking APIのパラメータを試すのに理想的です。
これらを整えることで、エンジニアは認証エラーやクォータ枯渇といった一般的な落とし穴を回避できます。この準備は、実際の実装へのシームレスな移行を確実にします。
Qwen3-Max-Thinking APIの取得と設定のステップバイステップガイド
開発者は、Alibaba Cloudコンソールにログインすることから始めます。ModelStudioセクションを見つけます。そこにはQwenモデルが配置されています。「qwen3-max-preview」または類似の識別子を検索して、ドキュメントとアクティベーションページを見つけます。
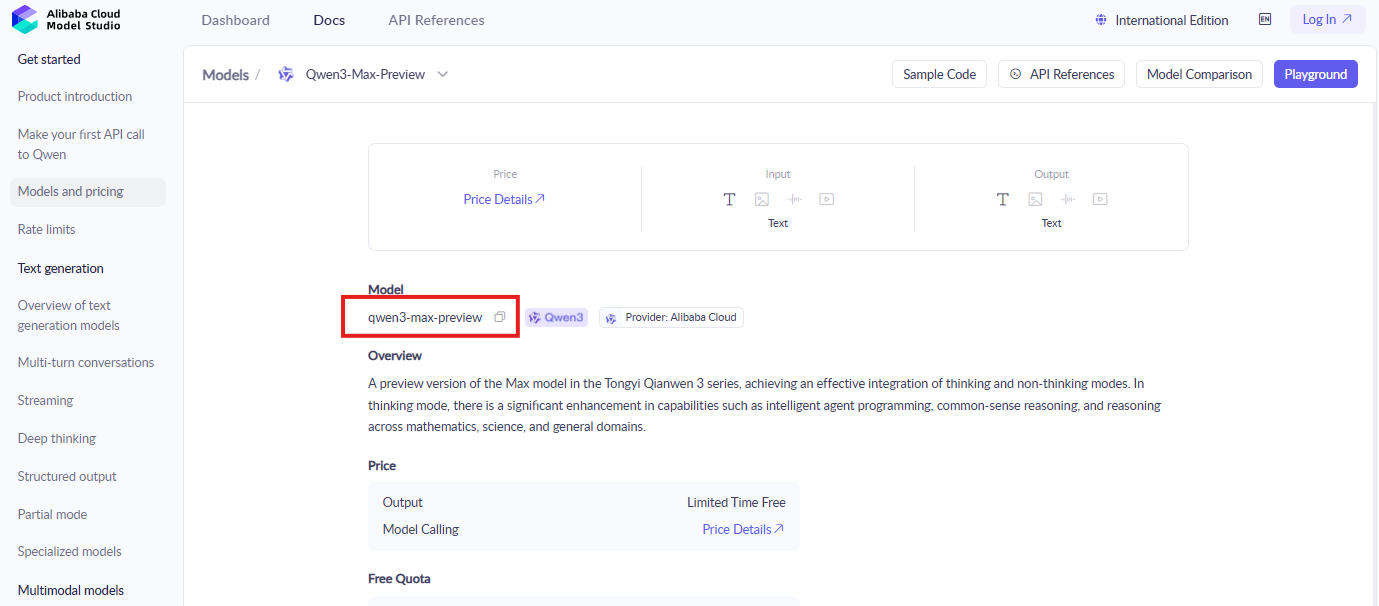
次にモデルをアクティブ化します。Qwen3-Max-Thinkingの有効化ボタンをクリックし、プロンプトが表示された場合は規約に同意します。このステップにより、プレビュー機能へのアクセスが許可されます。さらに、画面の指示に従って無料トークンクォータを引き換えます。新規アカウントは自動的に対象となります。
次にAPIクレデンシャルを生成します。APIキー管理エリアで新しいキーペアを作成します。アクセスキーIDとシークレットをメモしてください。これらはリクエストを認証します。セキュリティを維持するため、これらを公開しないようにしてください。
その後、開発環境を設定します。pip install requests openai のように、pip経由で必要なライブラリをインストールします。OpenAI互換ですが、エンドポイントはAlibabaのベースURL、通常は「https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation」のようなものに調整してください。
設定を確認するために基本的な呼び出しをテストします。モデル名「qwen3-max-preview」、入力プロンプト、および重要なパラメータ「enable_thinking": true を含むJSONペイロードを構築します。エンドポイントにPOSTリクエストを送信します。例:
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
出力内の思考ステップについて応答を監視します。成功した場合、それは活発な推論を示しています。ただし、無効なキーに対する401のようなエラーは、クレデンシャルを再確認して処理してください。
高度な設定に拡張します。ペイロードに関数を追加してツール呼び出しを組み込みます。このAPIはエージェントワークフローのためにQwen-Agentをサポートしており、多段階実行を可能にします。さらに、リクエストにキャッシュIDを含めることでコンテキストキャッシュを使用し、以前のコンテキストを効率的に再利用します。
問題を迅速にトラブルシューティングします。レート制限は429エラーを引き起こします。スナップショットバージョンに切り替えるか、クエリを最適化してください。ネットワークの問題には安定した接続が必要です。これらの手順に従うことで、開発者はQwen3-Max-Thinking APIへの信頼性の高いアクセスを確保できます。
ApidogとQwen3-Max-Thinking APIの統合
ApidogはAPIインタラクションを簡素化し、開発者はQwen3-Max-Thinking APIのためにそれを活用します。まず、Apidogの公式サイトからダウンロードしてください。無料で、主要なプラットフォームに迅速にインストールできます。
次にAPI仕様をインポートします。ApidogはOpenAPI形式をサポートしています。Qwenモデル用のAlibabaの仕様をダウンロードしてアップロードしてください。この操作により、テキスト生成エンドポイントを含むエンドポイントが自動的に入力されます。
次に環境を設定します。Apidogで新しい環境を作成し、APIキーとベースURLの変数を追加します。この設定により、テスト環境と本番環境の切り替えが簡単になります。
その後、リクエストをテストします。Apidogのインターフェースを使用してPOST呼び出しを構築します。モデル、プロンプト、およびenable_thinkingパラメータを入力します。リクエストを送信し、構文ハイライトやエラーログなどの機能を使用してリアルタイムで応答を検査します。
複雑なワークフローのためにリクエストを連結します。Apidogは呼び出しのシーケンスを可能にし、一つの応答が次の応答に供給されるエージェントタスクに理想的です。さらに、高負荷をシミュレートしてパフォーマンスをテストします。
Apidogの共有ツールを使用してチームと共同作業します。同僚がセットアップを再現できるようにコレクションをエクスポートします。さらに、統合された分析機能を通じてトークン使用量を監視し、クォータ内に収まるようにします。
統合をさらに最適化します。Apidogは大きなペイロードを効率的に処理し、262Kのコンテキストウィンドウをサポートします。思考バジェットが完全に利用可能になったら、それを調整して幻覚をデバッグします。
APIエンドポイントとパラメータの探索
Qwen3-Max-Thinking APIは、主にテキスト生成のためにいくつかのエンドポイントを公開しています。コアとなる/api/v1/services/aigc/text-generation/generationは、完了タスクを処理します。開発者はここにJSONデータをPOSTします。
主要なパラメータには、「qwen3-max-preview」を指定する「model」が含まれます。「input」オブジェクトにはチャット形式のメッセージが含まれます。さらに、「parameters」が動作を決定します。推論モードの場合は「enable_thinking」をTrueに設定します。
- その他のオプションは制御を強化します。「max_tokens」は出力長を最大65,536に制限します。「temperature」は創造性を調整し、デフォルトは0.7です。「top_p」はサンプリングを微調整します。
- ツールを使用するには、関数定義を含む「tools」配列を含めます。APIは呼び出しに応答し、エージェントフローを可能にします。
- コンテキストキャッシュは「cache_prompt」を使用して以前の入力を保存および参照し、コストを削減します。後続のリクエストでキャッシュIDを指定します。
- 「retry」のようなエラー処理パラメータは一時的な問題を管理します。さらに、「snapshot」によるバージョン管理は一貫性を保証します。
これらを理解することで、正確なチューニングが可能になります。数学の問題では、より高度な思考が詳細なステップを可能にし、コーディングでは堅牢なソリューションを生成します。開発者は最適な設定を見つけるために実験します。
Qwen3-Max-Thinking APIの実践的な使用例
エンジニアは様々なシナリオでAPIを適用します。コーディングを考えてみましょう。「リストをソートするPython関数を記述してください」とプロンプトします。思考が有効になっている場合、コードの前にロジックを概説します。
- 数学では、「x^2 dxの積分を解いてください」とクエリします。応答はステップを分解し、積分規則を示します。
- エージェントタスクの場合、ウェブ検索などのツールを定義します。モデルはアクションを計画し、コールバックを介して実行し、結果を統合します。
- エンタープライズ利用:コンテキストを与えて長いドキュメントを分析します。大きなウィンドウは、推奨のためにユーザー履歴を処理します。
- 教育:パラメータを通じて深さを調整し、複雑なトピックの説明を生成します。
- ヘルスケア:常に検証が必要ですが、論理的な出力で倫理的な決定をサポートします。
- クリエイティブライティング:論理的なプロットを持つ物語を作成します。
これらの例は多用途性を示しています。開発者はApidogを使用してテストのためにそれらをスケールします。
効率的な使用のためのベストプラクティス
まずトークン消費を最適化します。無駄を避けるために簡潔なプロンプトを作成します。繰り返しの要素にはキャッシュを使用します。
クォータを注意深く監視します。コンソールで使用状況を追跡し、必要に応じてアップグレードします。
環境変数またはボルトでキーを保護します。定期的にそれらをローテーションします。
コードで指数バックオフを実装することで、レート制限を処理します。
本番環境の前にApidogで徹底的にテストします。エッジケースをシミュレートします。
リリースされたら新しいスナップショットに更新し、変更ログを確認します。
ハイブリッドシステムのために他のツールと組み合わせます。
これらに従うことで、Qwen3-Max-Thinking APIの可能性を最大限に引き出せます。
結論
Qwen3-Max-Thinking APIは、高度な推論によりAIアプリケーションを変革します。このガイドに従うことで、開発者は効率のためにApidogを活用し、効果的にアクセスして統合できます。機能が進化するにつれて、革新的なプロジェクトにとって最高の選択肢であり続けます。