
ローカルマシンで強力な言語モデルを実行したくありませんか?QwQ-32B、Alibabaの最新かつ最も強力なLLMの紹介です。開発者、研究者、または技術に興味のある方、QwQ-32Bをローカルで実行することで、カスタムAIアプリケーションの構築から高度な自然言語処理タスクの実験まで、さまざまな可能性が広がります。
このガイドでは、プロセス全体をステップバイステップで説明します。OllamaやLM Studioなどのツールを使用して、セットアップをできるだけスムーズにしましょう。
OllamaでAPIを使用したい場合は、Apidogをぜひチェックしてください。APIワークフローの効率化に最適なツールで、しかも無料でダウンロードできます!

準備はできましたか?始めましょう!
1. QwQ-32Bの理解
技術的な詳細に入る前に、まずQwQ-32Bが何であるかを理解しましょう。QwQ-32Bは、32億個のパラメータを持つ最先端の言語モデルで、テキスト生成、翻訳、要約などの複雑な自然言語タスクを処理するために設計されています。AIの限界を押し広げたい開発者や研究者にとって、非常に多用途なツールです。
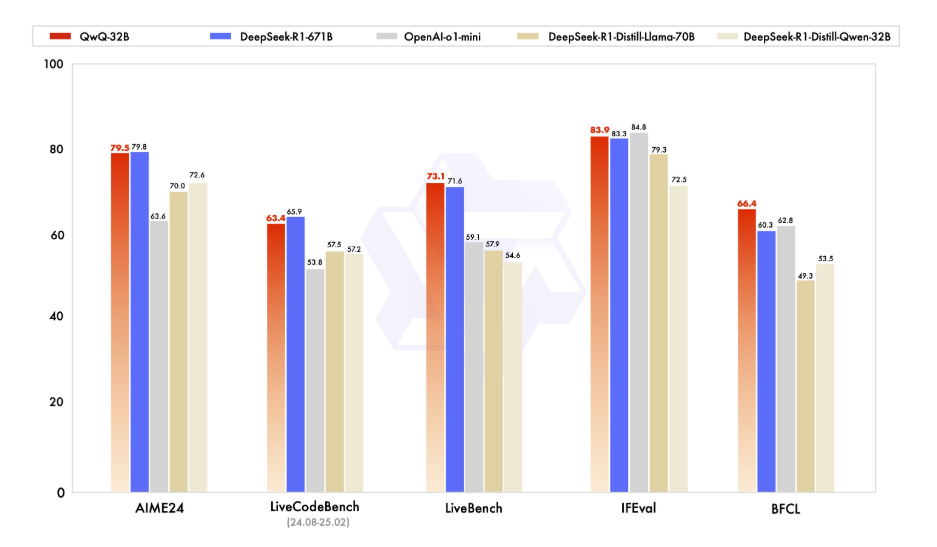
QwQ-32Bをローカルで実行することで、モデルに対する完全な制御が可能となり、クラウドベースのサービスに依存することなく特定のユースケースに合わせてカスタマイズできます。プライバシー、カスタマイズ、コスト効果、オフラインアクセスなど、多くの機能を活用できます。
2. 前提条件
QwQ-32Bをローカルで実行する前に、ローカルマシンが以下の要件を満たしている必要があります:
- ハードウェア:最低でも16GBのRAMと、最低24GBのVRAMを持つ高性能なGPU(例:NVIDIA RTX 3090以上)が必要です。
- ソフトウェア:Python 3.8以降、Git、およびpipまたはcondaなどのパッケージマネージャ。
- ツール:OllamaとLM Studio(詳細については後述します)。
3. Ollamaを使用してQwQ-32Bをローカルで実行する
Ollamaは、大型言語モデルをローカルで実行するプロセスを簡素化する軽量フレームワークです。インストール方法は以下の通りです:
ステップ1:Ollamaのダウンロードとインストール:
- WindowsおよびmacOSの場合は、Ollamaの公式ウェブサイトから実行可能ファイルをダウンロードしてインストールします。次に、インストールセットアップに記載されている簡単なインストール手順に従います。
- Linuxユーザーの場合は、以下のコマンドを使用できます:
curl -fsSL https://ollama.ai/install.sh | sh
- インストールの確認:インストールが完了したら、正しくインストールされたか確認するためにターミナルを開き、次のコマンドを実行します:
ollama --version
- インストールが成功すれば、バージョン番号が表示されます。
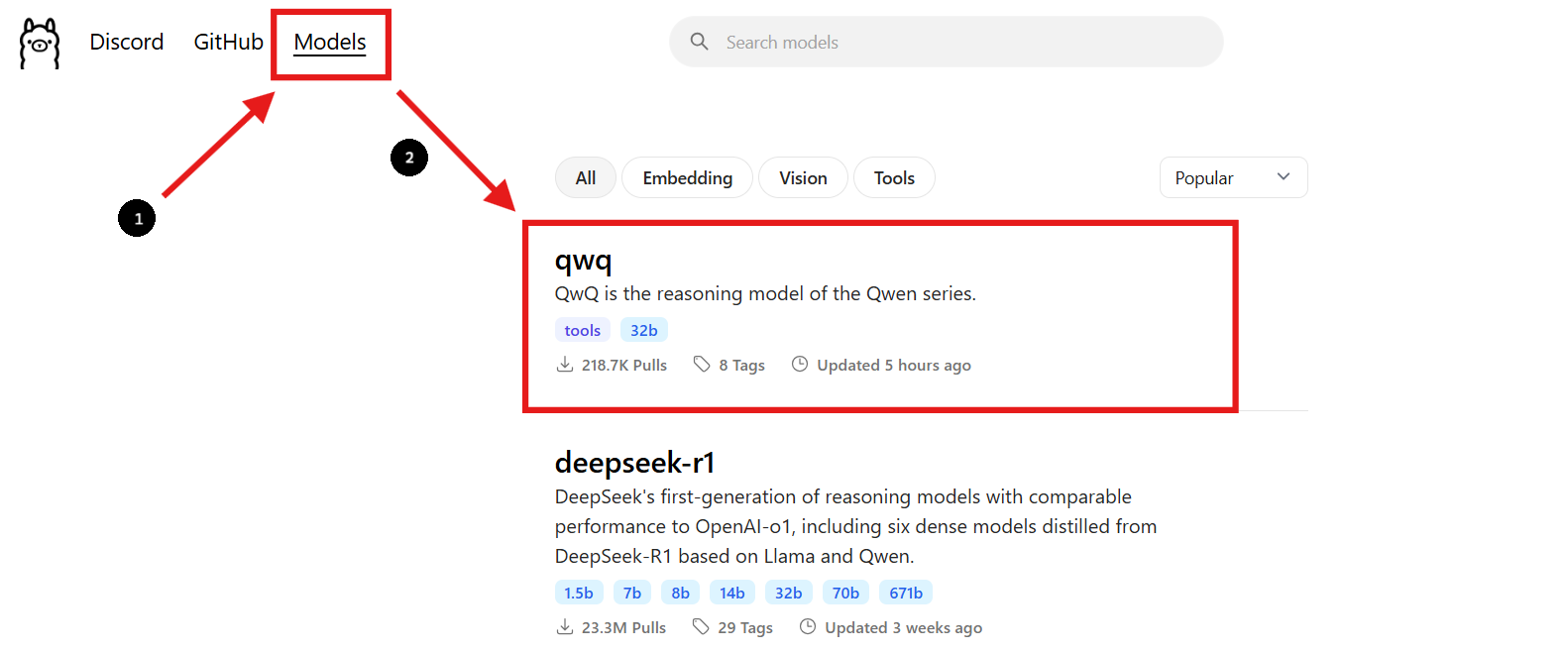
ステップ2:QwQ-32Bモデルを見つける
- Ollamaのウェブサイトに戻り、「モデル」セクションに移動します。
- 検索バーを使用して「QwQ-32B」を見つけます。
- QwQ-32Bモデルを見つけたら、ページに記載されているインストールコマンドを確認できます。
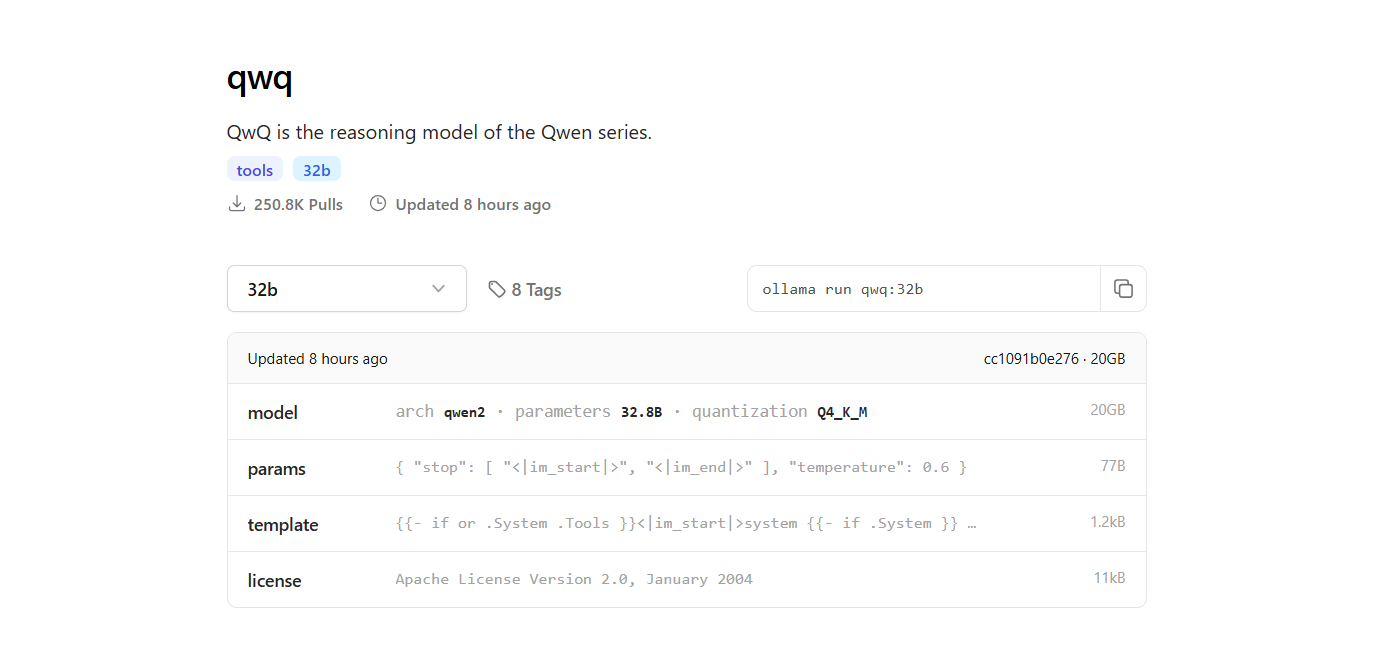
ステップ3:QwQ-32Bモデルをダウンロード
- 新しいターミナルウィンドウを開いてモデルをダウンロードし、次のコマンドを実行します:
ollama pull qwq:32b- ダウンロードが完了したら、次のコマンドを実行してモデルがインストールされていることを確認できます:
ollama list
- このコマンドは、Ollamaを使用してダウンロードしたすべてのモデルを一覧表示し、QwQ-32Bが利用可能であることを確認します。
ステップ4:QwQ-32Bモデルを実行する
ターミナルでモデルを実行します:
- QwQ-32Bモデルと直接対話するには、次のコマンドを使用します:
ollama run qwq:32b
- ターミナルで質問をしたりプロンプトを提供すると、モデルがそれに応じて回答します。
インタラクティブチャットインターフェースを使用:
- または、ChatboxやOpenWebUIなどのツールを使用して、QwQ-32BモデルとチャットするためのインタラクティブなGUIを作成できます。
- これらのインターフェースは、コマンドラインインターフェースよりもグラフィカルなインターフェースを好む方にとって、モデルと対話するためのよりユーザーフレンドリーな方法を提供します。
4. LM Studioを使用してQwQ-32Bをローカルで実行
LM Studioは、言語モデルをローカルで実行および管理するためのユーザーフレンドリーなインターフェースです。セットアップ方法は以下の通りです:
ステップ1:LM Studioのダウンロード:
- まず、lmstudio.aiの公式LM Studioウェブサイトにアクセスします。ここから、オペレーティングシステムに合ったLM Studioアプリケーションをダウンロードできます。
- ページ内のダウンロードセクションに移動し、オペレーティングシステム(Windows、macOS、またはLinux)に対応するバージョンを選択します。
ステップ2:LM Studioをインストール:
- オペレーティングシステム用の簡単なインストール手順に従います。
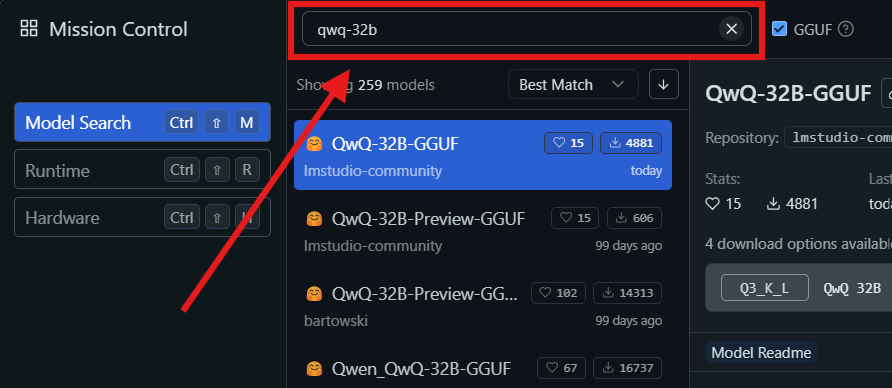
ステップ3:QwQ-32Bモデルを見つけてダウンロード:
- LM Studioを開いて「マイモデル」セクションに移動します。
- 検索アイコンをクリックして検索バーに「QwQ-32B」と入力します。
- 検索結果から希望するQwQ-32Bモデルのバージョンを選択します。メモリ使用量を削減しつつパフォーマンスを維持するのに役立つ4ビット量子化モデルなど、異なる量子化バージョンが見つかるかもしれません。
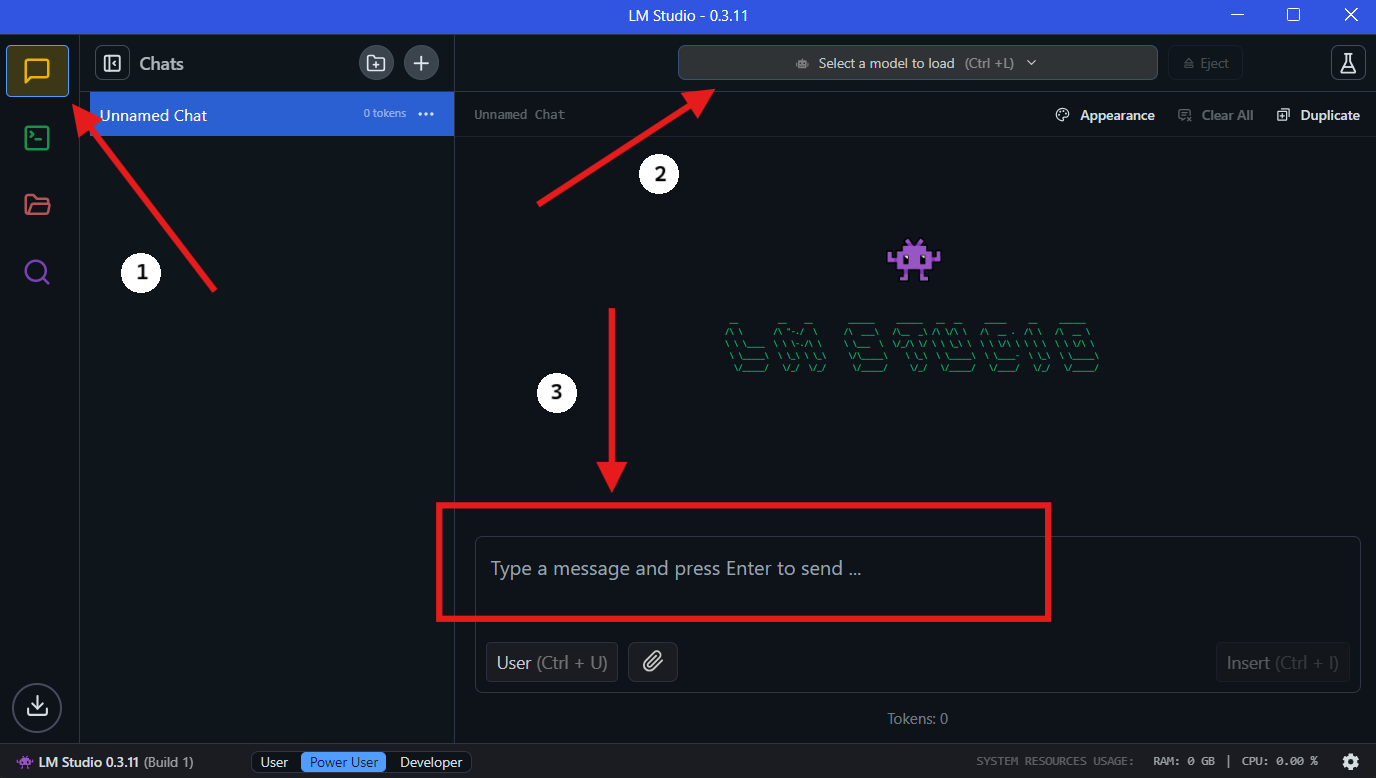
ステップ4:LM StudioでQwQ-32Bをローカルで実行
- モデルを選択:ダウンロードが完了したら、LM Studioの「チャット」セクションに移動します。チャットインターフェースで、ドロップダウンメニューからQwQ-32Bモデルを選択します。
- QwQ-32Bと対話:チャットウィンドウで質問をしたりプロンプトを提供したりします。モデルが入力を処理し、応答を生成します。
- 設定の構成:モデルの設定は「詳細設定タブ」で好みに応じて調整できます。
5. Apidogを使ったAPI開発の効率化
QwQ-32Bをアプリケーションに統合するには、効率的なAPI管理が必要です。Apidogは、これを簡素化するオールインワンのコラボレーティブAPI開発プラットフォームです。Apidogの主な機能には、API設計、APIドキュメント、およびAPIデバッグが含まれています。シームレスな統合プロセスを実現するために、QwQ-32Bを使用したAPIを管理およびテストするためにApidogを設定するステップに従ってください。

ステップ1:Apidogのダウンロードとインストール
- Apidog公式ウェブサイトを訪問し、自分のオペレーティングシステム(Windows、macOS、またはLinux)に対応するバージョンをダウンロードします。
- インストール手順に従って、Apidogをマシンにセットアップします。
ステップ2:新しいAPIプロジェクトを作成
- Apidogを開いて新しいAPIプロジェクトを作成します。
- QwQ-32Bと対話するためのリクエストとレスポンス形式を指定し、APIエンドポイントを定義します。
ステップ3:ローカルAPI経由でQwQ-32BをApidogに接続
APIを通じてQwQ-32Bと対話するためには、ローカルサーバーを使用してモデルを公開する必要があります。FastAPIまたはFlaskを使用して、ローカルのQwQ-32Bモデル用のAPIを作成します。
例:QwQ-32BのFastAPIサーバーの設定:
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# 実行方法: uvicorn script_name:app --reload
ステップ4:ApidogでAPIコールをテスト
- Apidogを開いて、POSTリクエストを
http://localhost:8000/generateに作成します。 - リクエストボディにサンプルプロンプトを入力し、「送信」をクリックします。
- 設定が正しく行われていれば、QwQ-32Bから生成された応答が返ってきます。
ステップ5:APIテストとデバッグの自動化
- Apidogの組み込みテスト機能を使用して、さまざまな入力をシミュレーションし、QwQ-32Bの応答を分析します。
- リクエストパラメータを調整し、応答時間を監視してAPIのパフォーマンスを最適化します。
🚀 Apidogを使用すると、APIワークフローの管理が容易になり、QwQ-32Bとアプリケーション間のスムーズな統合が実現します。
6. パフォーマンス最適化のためのヒント
32億パラメータモデルを実行することは、リソースを大量に消費する場合があります。パフォーマンスを最適化するためのヒントをいくつか紹介します:
- ハイエンドGPUを使用: 強力なGPUは推論の速度を大幅に向上させます。
- バッチサイズを調整: 異なるバッチサイズを試して最適な設定を見つけます。
- リソース使用状況を監視:
htopやnvidia-smiなどのツールを使用してCPUとGPUの使用状況を監視します。
7. 一般的な問題のトラブルシューティング
QwQ-32Bをローカルで実行することは、時に困難な場合があります。一般的な問題とその解決方法を以下に示します:
- メモリ不足: バッチサイズを減らすか、ハードウェアをアップグレードします。
- パフォーマンスが遅い: GPUドライバーが最新であることを確認してください。
- モデルが読み込まれない: モデルパスとファイルの整合性を再確認してください。
8. 最後の考え
QwQ-32Bをローカルで実行することは、クラウドサービスに依存せずに高度なAIモデルの機能を活用する強力な方法です。OllamaやLM Studioのようなツールを使用すれば、そのプロセスはこれまで以上にアクセスしやすくなります。
APIを扱う場合は、テストとドキュメンテーションのためのツールとしてApidogが最適です。無料でダウンロードしてAPIワークフローを次のレベルに引き上げましょう!


