
Developers constantly seek advanced AI models to enhance reasoning, coding, and problem-solving in their applications. The Qwen3-Max-Thinking API stands out as a preview version that pushes boundaries in these areas. This guide explains how engineers access and implement this API effectively. Moreover, it highlights tools that simplify the process.
Alibaba Cloud powers the Qwen3-Max-Thinking API, providing an early preview of enhanced thinking capabilities. Released as an intermediate checkpoint during training, this model achieves remarkable performance on benchmarks such as AIME 2025 and HMMT when combined with tool use and scaled compute. Furthermore, users activate the thinking mode easily through parameters like enable_thinking=True. As training progresses, expect even stronger features. This article covers everything from registration to advanced usage, ensuring you integrate the Qwen3-Max-Thinking API smoothly into your workflows.
Understanding the Qwen3-Max-Thinking API
Engineers recognize the Qwen3-Max-Thinking API as an evolution of Alibaba's Qwen series, specifically designed for superior reasoning tasks. Unlike standard models, this preview incorporates "thinking budgets" that allow users to control the depth of reasoning in areas like mathematics, coding, and scientific analysis. Alibaba released this version to showcase progress, even as training continues.

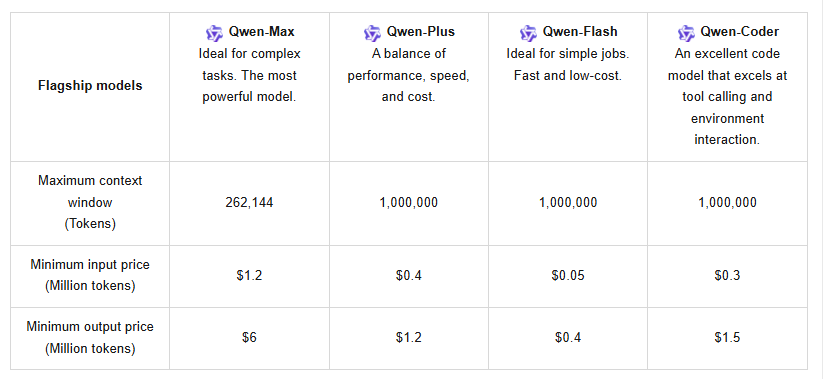
The base Qwen3-Max model boasts over one trillion parameters and training on 36 trillion tokens, doubling the data volume of its predecessor, Qwen2.5. It supports a massive context window of 262,144 tokens, with maximum input at 258,048 tokens and output at 65,536 tokens. Additionally, it handles over 100 languages, making it versatile for global applications. However, the Qwen3-Max-Thinking variant adds agentic features, reducing hallucinations and enabling multi-step processes through Qwen-Agent tool calling.
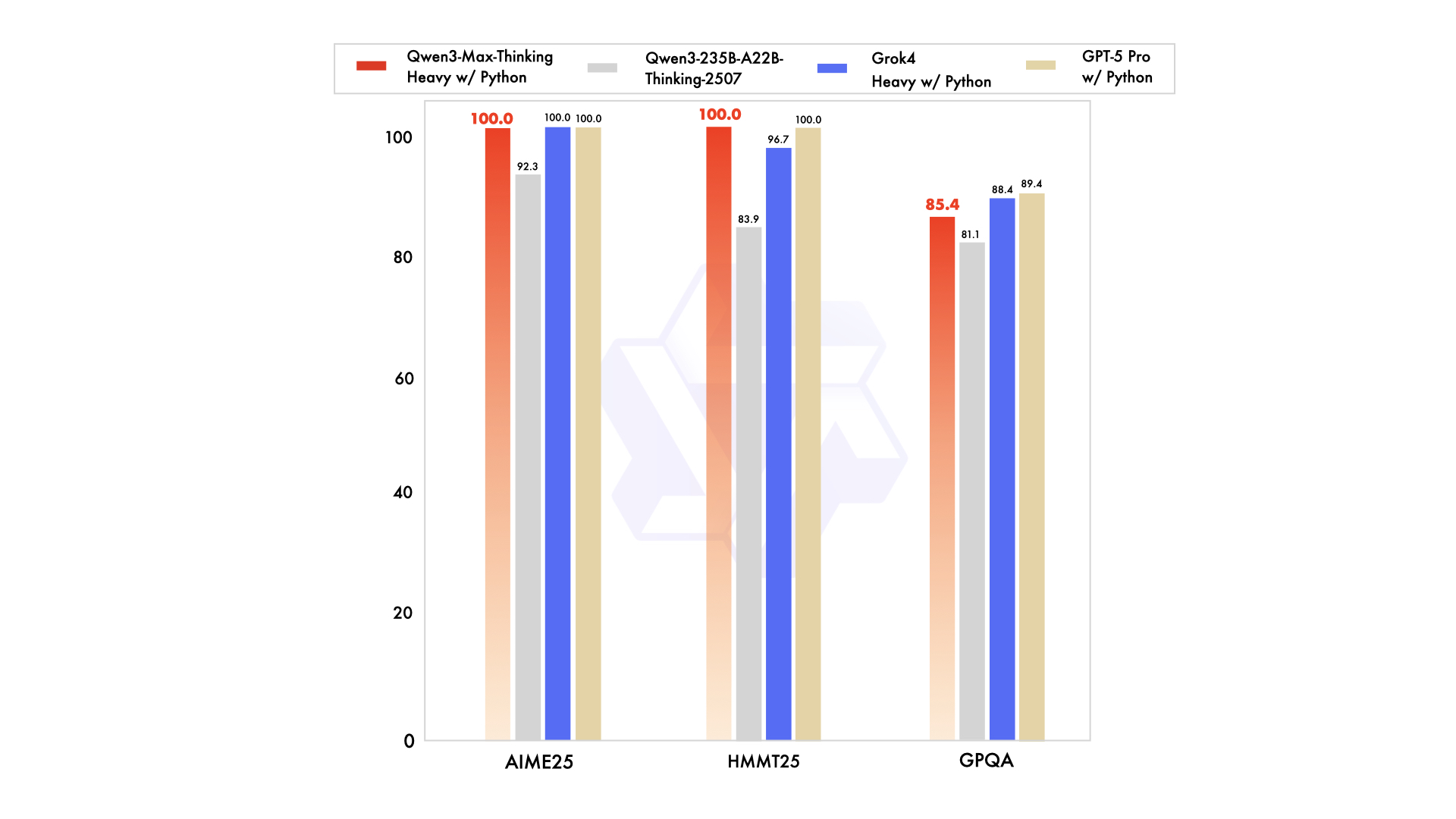
Performance metrics underline its strengths. For instance, it scores 74.8 on LiveCodeBench v6 for coding and 81.6 on AIME25 for mathematics. When augmented, it reaches 100% on challenging benchmarks like AIME 2025 and HMMT. Nevertheless, this preview operates as a non-thinking instruct model initially, with reasoning enhancements activated via specific flags. Developers access it through Alibaba Cloud's API, which maintains compatibility with OpenAI standards for easy migration.
Furthermore, the API supports context caching, which optimizes repeated queries and cuts costs. Pricing follows a tiered structure: for 0–32K tokens, input costs $1.2 per million and output $6 per million; for 32K–128K, input rises to $2.4 and output to $12; and for 128K–252K, input hits $3 with output at $15. New users benefit from a free quota of one million tokens, valid for 90 days, encouraging initial testing.
In comparison to competitors like Claude Opus 4 or DeepSeek-V3.1, Qwen3-Max-Thinking excels in agentic tasks, such as SWE-Bench Verified at 72.5. Yet, its preview status means some features, like full thinking budgets, remain in development. Users try it via Qwen Chat for interactive sessions or the API for programmatic access. This setup positions the Qwen3-Max-Thinking API as a key tool for software development, education, and enterprise automation.
Prerequisites for Accessing the Qwen3-Max-Thinking API
Before developers proceed, they gather essential requirements. First, create an Alibaba Cloud account if one does not exist. Visit the Alibaba Cloud website and sign up using an email address or phone number. Verify the account through the provided link or code to enable full access.
Next, ensure familiarity with API concepts, including RESTful endpoints and JSON payloads. The Qwen3-Max-Thinking API uses HTTPS protocols, so secure connections matter. Additionally, prepare development tools: Python 3.x or similar languages with libraries like requests for HTTP calls. For advanced integrations, consider frameworks such as vLLM or SGLang, which support efficient serving on multiple GPUs.
Authentication requires an API key from Alibaba Cloud. Navigate to the console after login and generate keys under the API management section. Store these securely, as they grant access to model endpoints. Moreover, comply with usage policies—avoid excessive calls to prevent rate limiting. The system offers latest and snapshot versions; select snapshots for stable performance under high loads.
Hardware considerations apply for local testing, though cloud access mitigates this. The model demands significant compute, but Alibaba's infrastructure handles it. Finally, download supporting tools like Apidog to streamline testing. Apidog manages requests, environments, and collaborations, making it ideal for experimenting with the Qwen3-Max-Thinking API parameters.
With these in place, engineers avoid common pitfalls like authentication errors or quota exhaustion. This preparation ensures a seamless transition to actual implementation.
Step-by-Step Guide to Obtaining and Setting Up the Qwen3-Max-Thinking API
Developers start by logging into the Alibaba Cloud console. Locate the ModelStudio section, where Qwen models reside. Search for "qwen3-max-preview" or similar identifiers to find the documentation and activation page.
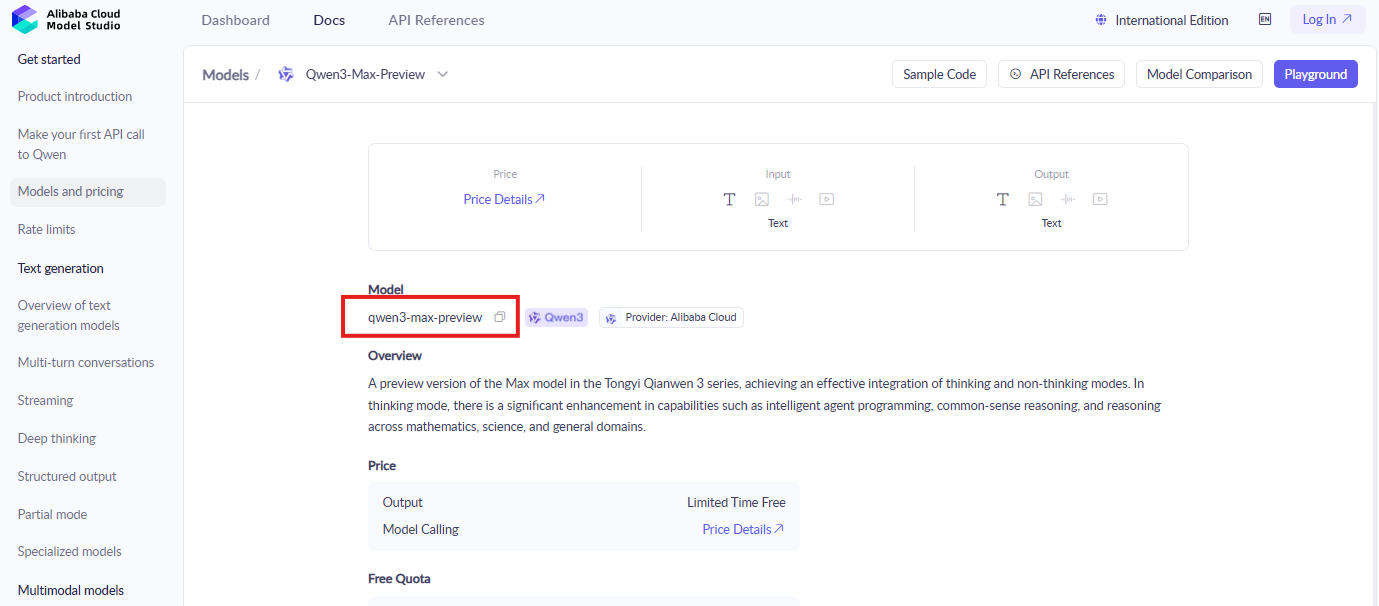
Activate the model next. Click the enable button for Qwen3-Max-Thinking, agreeing to terms if prompted. This step grants access to the preview features. Furthermore, redeem the free token quota by following on-screen instructions—new accounts automatically qualify.
Generate API credentials then. In the API keys management area, create a new key pair. Note the access key ID and secret; these authenticate requests. Avoid sharing them publicly to maintain security.
Configure your development environment afterward. Install necessary libraries via pip, such as pip install requests openai. Although OpenAI-compatible, adjust endpoints to Alibaba's base URL, typically something like "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation".
Test a basic call to verify setup. Construct a JSON payload with the model name "qwen3-max-preview", input prompt, and the crucial parameter "enable_thinking": true. Send a POST request to the endpoint. For example:
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Monitor the response for thinking steps in the output. If successful, it demonstrates active reasoning. However, handle errors like 401 for invalid keys by double-checking credentials.
Expand to advanced configurations. Incorporate tool calling by adding functions in the payload. The API supports Qwen-Agent for agentic workflows, allowing multi-step executions. Additionally, use context caching by including cache IDs in requests to reuse previous contexts efficiently.
Troubleshoot issues promptly. Rate limits trigger 429 errors; switch to snapshot versions or optimize queries. Network problems require stable connections. By following these steps, developers secure reliable access to the Qwen3-Max-Thinking API.
Integrating the Qwen3-Max-Thinking API with Apidog
Apidog simplifies API interactions, and developers leverage it for the Qwen3-Max-Thinking API. Begin by downloading Apidog from their official site—it's free and installs quickly on major platforms.
Import the API specification next. Apidog supports OpenAPI formats; download Alibaba's spec for Qwen models and upload it. This action populates endpoints automatically, including text-generation ones.
Set up environments then. Create a new environment in Apidog, adding variables for API keys and base URLs. This setup enables easy switching between testing and production.
Test requests afterward. Use Apidog's interface to build POST calls. Input the model, prompt, and enable_thinking parameter. Send the request and inspect responses in real-time, with features like syntax highlighting and error logging.
Chain requests for complex workflows. Apidog allows sequencing calls, ideal for agentic tasks where one response feeds another. Moreover, simulate high loads to test performance.
Collaborate with teams using Apidog's sharing tools. Export collections for colleagues to replicate setups. Additionally, monitor token usage through integrated analytics to stay within quotas.
Optimize integrations further. Apidog handles large payloads efficiently, supporting the 262K context window. Debug hallucinations by tweaking thinking budgets once fully available.
Exploring API Endpoints and Parameters
The Qwen3-Max-Thinking API exposes several endpoints, primarily for text generation. The core one, /api/v1/services/aigc/text-generation/generation, handles completion tasks. Developers POST JSON data here.
Key parameters include "model", specifying "qwen3-max-preview". The "input" object contains messages in chat format. Furthermore, "parameters" dictate behavior: set "enable_thinking" to True for reasoning mode.
- Other options enhance control. "max_tokens" limits output length, up to 65,536. "temperature" adjusts creativity, defaulting to 0.7. "top_p" refines sampling.
- For tool use, include "tools" array with function definitions. The API responds with calls, enabling agentic flows.
- Context caching uses "cache_prompt" to store and reference prior inputs, reducing costs. Specify cache IDs in subsequent requests.
- Error handling parameters like "retry" manage transients. Additionally, versioning via "snapshot" ensures consistency.
Understanding these allows precise tuning. For math problems, higher thinking enables detailed steps; for coding, it generates robust solutions. Developers experiment to find optimal settings.
Practical Examples of Using the Qwen3-Max-Thinking API
Engineers apply the API in diverse scenarios. Consider coding: Prompt "Write a Python function to sort a list." With thinking enabled, it outlines logic before code.
- In mathematics, query "Solve integral of x^2 dx." The response breaks down steps, showing integration rules.
- For agentic tasks, define tools like web search. The model plans actions, executes via callbacks, and synthesizes results.
- Enterprise use: Analyze long documents by feeding contexts. The large window processes user histories for recommendations.
- Education: Generate explanations for complex topics, adapting depth via parameters.
- Healthcare: Support ethical decisions with reasoned outputs, though always verify.
- Creative writing: Produce stories with logical plots.
These examples illustrate versatility. Developers scale them using Apidog for testing.
Best Practices for Efficient Usage
Optimize token consumption first. Craft concise prompts to avoid waste. Use caching for repetitive elements.
Monitor quotas diligently. Track usage in the console; upgrade if needed.
Secure keys with environment variables or vaults. Rotate them periodically.
Handle rate limits by implementing exponential backoff in code.
Test thoroughly with Apidog before production. Simulate edge cases.
Update to new snapshots as released, checking changelogs.
Combine with other tools for hybrid systems.
Follow these to maximize the Qwen3-Max-Thinking API's potential.
Conclusion
The Qwen3-Max-Thinking API transforms AI applications with advanced reasoning. By following this guide, developers access and integrate it effectively, leveraging Apidog for efficiency. As features evolve, it remains a top choice for innovative projects.


