
นักพัฒนาซอฟต์แวร์ต่างแสวงหาโมเดล AI ขั้นสูงอย่างต่อเนื่องเพื่อเพิ่มความสามารถในการให้เหตุผล การเขียนโค้ด และการแก้ปัญหาในแอปพลิเคชันของตน Qwen3-Max-Thinking API โดดเด่นในฐานะเวอร์ชันพรีวิวที่ผลักดันขีดจำกัดในด้านเหล่านี้ คู่มือนี้จะอธิบายวิธีการที่วิศวกรเข้าถึงและใช้งาน API นี้ได้อย่างมีประสิทธิภาพ นอกจากนี้ ยังเน้นย้ำถึงเครื่องมือที่ช่วยให้กระบวนการง่ายขึ้นอีกด้วย
Qwen3-Max-Thinking API ขับเคลื่อนโดย Alibaba Cloud โดยนำเสนอตัวอย่างล่วงหน้าของความสามารถในการคิดที่ได้รับการปรับปรุง โมเดลนี้เปิดตัวในฐานะจุดตรวจสอบกลางระหว่างการฝึกฝน และทำผลงานได้อย่างน่าทึ่งในการวัดประสิทธิภาพ เช่น AIME 2025 และ HMMT เมื่อรวมกับการใช้เครื่องมือและการประมวลผลที่ปรับขนาดได้ ยิ่งไปกว่านั้น ผู้ใช้สามารถเปิดใช้งานโหมดการคิดได้อย่างง่ายดายผ่านพารามิเตอร์เช่น enable_thinking=True เมื่อการฝึกฝนดำเนินไป คาดว่าจะได้เห็นคุณสมบัติที่แข็งแกร่งยิ่งขึ้น บทความนี้ครอบคลุมทุกอย่างตั้งแต่การลงทะเบียนไปจนถึงการใช้งานขั้นสูง เพื่อให้มั่นใจว่าคุณสามารถผสานรวม Qwen3-Max-Thinking API เข้ากับเวิร์กโฟลว์ของคุณได้อย่างราบรื่น
ทำความเข้าใจ Qwen3-Max-Thinking API
วิศวกรยอมรับ Qwen3-Max-Thinking API ว่าเป็นการพัฒนาต่อยอดจาก ซีรีส์ Qwen ของ Alibaba ซึ่งออกแบบมาโดยเฉพาะสำหรับงานการให้เหตุผลที่เหนือกว่า แตกต่างจากโมเดลมาตรฐาน เวอร์ชันพรีวิวนี้รวม "งบประมาณการคิด" ที่ช่วยให้ผู้ใช้สามารถควบคุมความลึกของการให้เหตุผลในด้านต่างๆ เช่น คณิตศาสตร์ การเขียนโค้ด และการวิเคราะห์ทางวิทยาศาสตร์ Alibaba ได้เปิดตัวเวอร์ชันนี้เพื่อแสดงความคืบหน้า แม้ว่าการฝึกอบรมจะยังคงดำเนินต่อไป

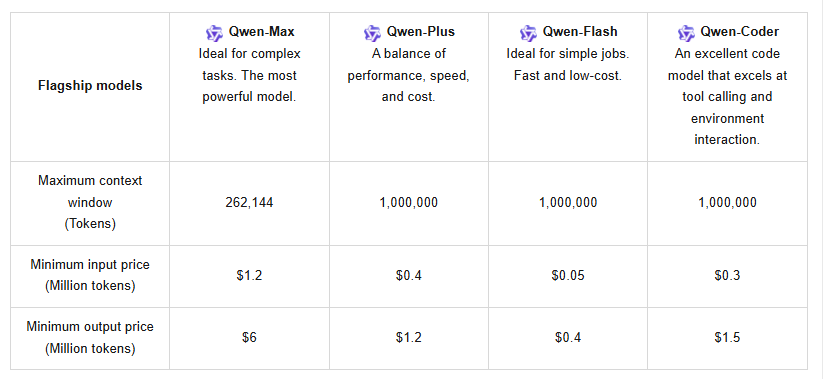
โมเดล Qwen3-Max พื้นฐาน มีพารามิเตอร์มากกว่าหนึ่งล้านล้านตัว และได้รับการฝึกฝนด้วยโทเค็น 36 ล้านล้านโทเค็น ซึ่งเป็นปริมาณข้อมูลที่เพิ่มขึ้นเป็นสองเท่าของรุ่นก่อนอย่าง Qwen2.5 รองรับหน้าต่างบริบทขนาดใหญ่ถึง 262,144 โทเค็น โดยมีอินพุตสูงสุด 258,048 โทเค็น และเอาต์พุตสูงสุด 65,536 โทเค็น นอกจากนี้ยังรองรับมากกว่า 100 ภาษา ทำให้มีความหลากหลายสำหรับการใช้งานทั่วโลก อย่างไรก็ตาม Qwen3-Max-Thinking รุ่นนี้เพิ่มคุณสมบัติเชิงตัวแทน (agentic features) ซึ่งช่วยลดการหลอนและเปิดใช้งานกระบวนการหลายขั้นตอนผ่านการเรียกใช้เครื่องมือ Qwen-Agent
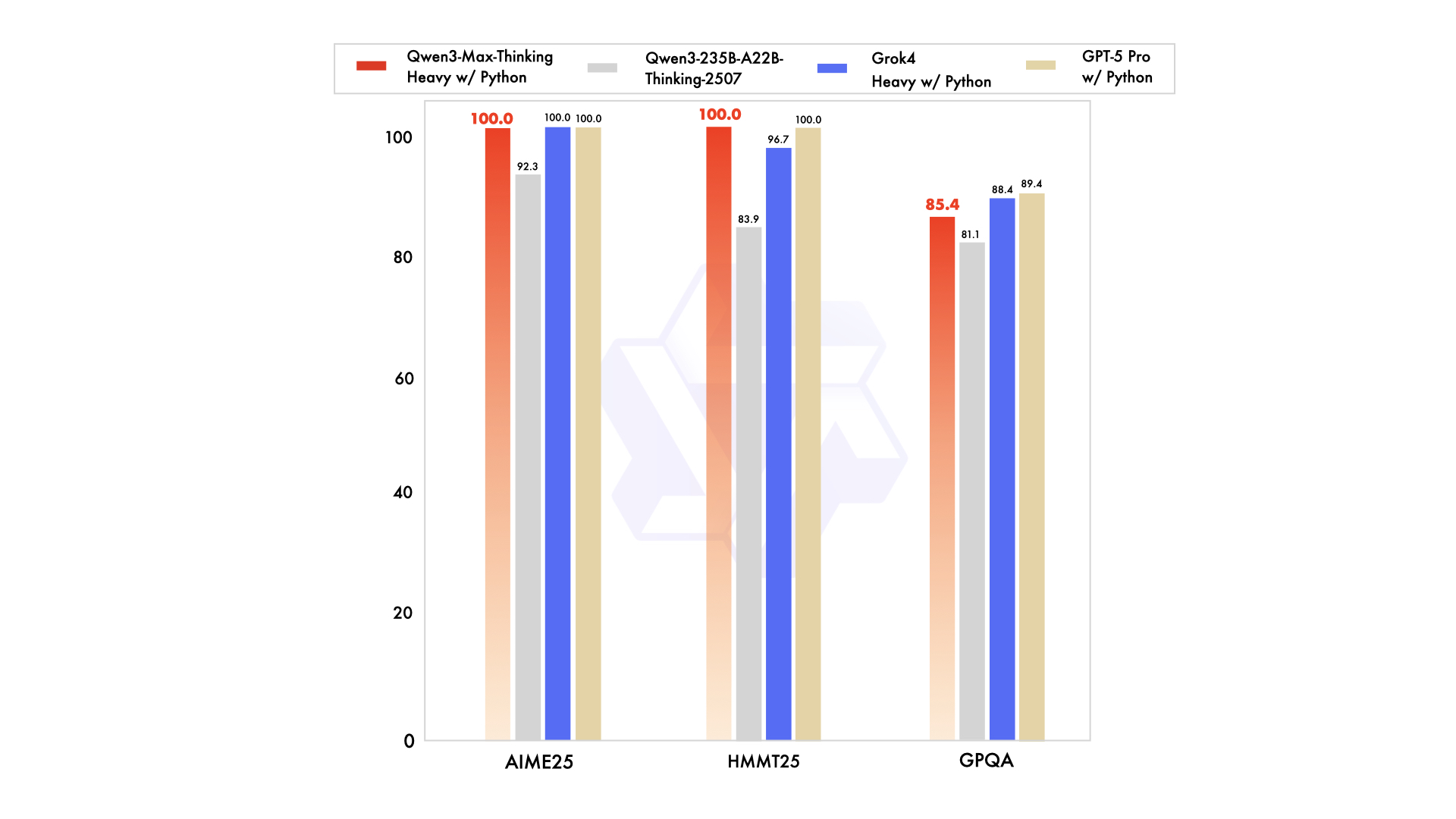
ตัวชี้วัดประสิทธิภาพเน้นย้ำถึงจุดแข็งของมัน ตัวอย่างเช่น ได้คะแนน 74.8 ใน LiveCodeBench v6 สำหรับการเขียนโค้ด และ 81.6 ใน AIME25 สำหรับคณิตศาสตร์ เมื่อเสริมประสิทธิภาพแล้ว จะได้คะแนน 100% ในเกณฑ์มาตรฐานที่ท้าทาย เช่น AIME 2025 และ HMMT อย่างไรก็ตาม เวอร์ชันพรีวิวนี้ทำงานเป็นโมเดลสั่งงานแบบไม่คิด (non-thinking instruct model) ในตอนแรก โดยมีการปรับปรุงการให้เหตุผลที่เปิดใช้งานผ่านแฟล็กเฉพาะ นักพัฒนาสามารถเข้าถึงได้ผ่าน API ของ Alibaba Cloud ซึ่งยังคงรักษาความเข้ากันได้กับมาตรฐาน OpenAI เพื่อการย้ายข้อมูลที่ง่ายดาย
นอกจากนี้ API ยังรองรับการแคชบริบท ซึ่งช่วยเพิ่มประสิทธิภาพการสอบถามซ้ำและลดค่าใช้จ่าย ราคา เป็นไปตามโครงสร้างแบบแบ่งระดับ: สำหรับ 0–32K โทเค็น ค่าใช้จ่ายอินพุตคือ $1.2 ต่อล้านโทเค็น และเอาต์พุตคือ $6 ต่อล้านโทเค็น; สำหรับ 32K–128K โทเค็น อินพุตเพิ่มขึ้นเป็น $2.4 และเอาต์พุตเป็น $12; และสำหรับ 128K–252K โทเค็น อินพุตสูงถึง $3 และเอาต์พุตที่ $15 ผู้ใช้ใหม่จะได้รับประโยชน์จากโควตาฟรีหนึ่งล้านโทเค็น ซึ่งใช้ได้ 90 วัน เพื่อส่งเสริมการทดสอบเบื้องต้น
เมื่อเปรียบเทียบกับคู่แข่งอย่าง Claude Opus 4 หรือ DeepSeek-V3.1 แล้ว Qwen3-Max-Thinking มีความเป็นเลิศในงานเชิงตัวแทน (agentic tasks) เช่น SWE-Bench Verified ที่ 72.5 อย่างไรก็ตาม สถานะพรีวิวหมายความว่าคุณสมบัติบางอย่าง เช่น งบประมาณการคิดเต็มรูปแบบ ยังคงอยู่ระหว่างการพัฒนา ผู้ใช้สามารถทดลองใช้ผ่าน Qwen Chat สำหรับเซสชันแบบโต้ตอบ หรือ API สำหรับการเข้าถึงแบบโปรแกรม การตั้งค่านี้ทำให้ Qwen3-Max-Thinking API เป็นเครื่องมือสำคัญสำหรับการพัฒนาซอฟต์แวร์ การศึกษา และระบบอัตโนมัติขององค์กร
ข้อกำหนดเบื้องต้นสำหรับการเข้าถึง Qwen3-Max-Thinking API
ก่อนที่นักพัฒนาจะดำเนินการ พวกเขาต้องรวบรวมข้อกำหนดที่จำเป็น ประการแรก สร้างบัญชี Alibaba Cloud หากยังไม่มี เยี่ยมชมเว็บไซต์ Alibaba Cloud และลงทะเบียนโดยใช้ที่อยู่อีเมลหรือหมายเลขโทรศัพท์ ยืนยันบัญชีผ่านลิงก์หรือรหัสที่ให้มาเพื่อเปิดใช้งานการเข้าถึงเต็มรูปแบบ
ถัดไป ตรวจสอบให้แน่ใจว่าคุ้นเคยกับแนวคิด API รวมถึง ปลายทาง RESTful และ เพย์โหลด JSON Qwen3-Max-Thinking API ใช้ โปรโตคอล HTTPS ดังนั้นการเชื่อมต่อที่ปลอดภัยจึงเป็นสิ่งสำคัญ นอกจากนี้ เตรียมเครื่องมือพัฒนา: Python 3.x หรือภาษาที่คล้ายกันพร้อมไลบรารีเช่น requests สำหรับการเรียก HTTP สำหรับการผสานรวมขั้นสูง พิจารณาเฟรมเวิร์กเช่น vLLM หรือ SGLang ซึ่งรองรับการให้บริการที่มีประสิทธิภาพบน GPU หลายตัว
การรับรองความถูกต้องต้องใช้คีย์ API จาก Alibaba Cloud ไปที่คอนโซลหลังจากเข้าสู่ระบบและสร้างคีย์ภายใต้ส่วนการจัดการ API เก็บสิ่งเหล่านี้ไว้อย่างปลอดภัย เนื่องจากคีย์เหล่านี้ให้สิทธิ์การเข้าถึงปลายทางของโมเดล นอกจากนี้ ปฏิบัติตามนโยบายการใช้งาน—หลีกเลี่ยงการเรียกใช้มากเกินไปเพื่อป้องกันการจำกัดอัตรา ระบบมีเวอร์ชันล่าสุดและเวอร์ชันสแนปช็อต เลือกสแนปช็อตเพื่อประสิทธิภาพที่เสถียรภายใต้โหลดสูง
ข้อควรพิจารณาด้านฮาร์ดแวร์ใช้กับการทดสอบในเครื่อง แม้ว่าการเข้าถึงคลาวด์จะช่วยลดปัญหานี้ โมเดลต้องการการประมวลผลจำนวนมาก แต่ โครงสร้างพื้นฐานของ Alibaba จัดการได้ สุดท้าย ดาวน์โหลดเครื่องมือสนับสนุนเช่น Apidog เพื่อปรับปรุงการทดสอบ Apidog จัดการคำขอ สภาพแวดล้อม และการทำงานร่วมกัน ทำให้เหมาะสำหรับการทดลองกับพารามิเตอร์ Qwen3-Max-Thinking API
ด้วยสิ่งเหล่านี้ วิศวกรจะหลีกเลี่ยงข้อผิดพลาดทั่วไป เช่น ข้อผิดพลาดในการรับรองความถูกต้องหรือโควตาหมด การเตรียมการนี้ช่วยให้การเปลี่ยนไปสู่การใช้งานจริงเป็นไปอย่างราบรื่น
คำแนะนำทีละขั้นตอนในการรับและตั้งค่า Qwen3-Max-Thinking API
นักพัฒนาเริ่มต้นด้วยการเข้าสู่ระบบคอนโซล Alibaba Cloud ค้นหาส่วน ModelStudio ซึ่งเป็นที่อยู่ของโมเดล Qwen ค้นหา "qwen3-max-preview" หรือตัวระบุที่คล้ายกันเพื่อค้นหาหน้าเอกสารและการเปิดใช้งาน
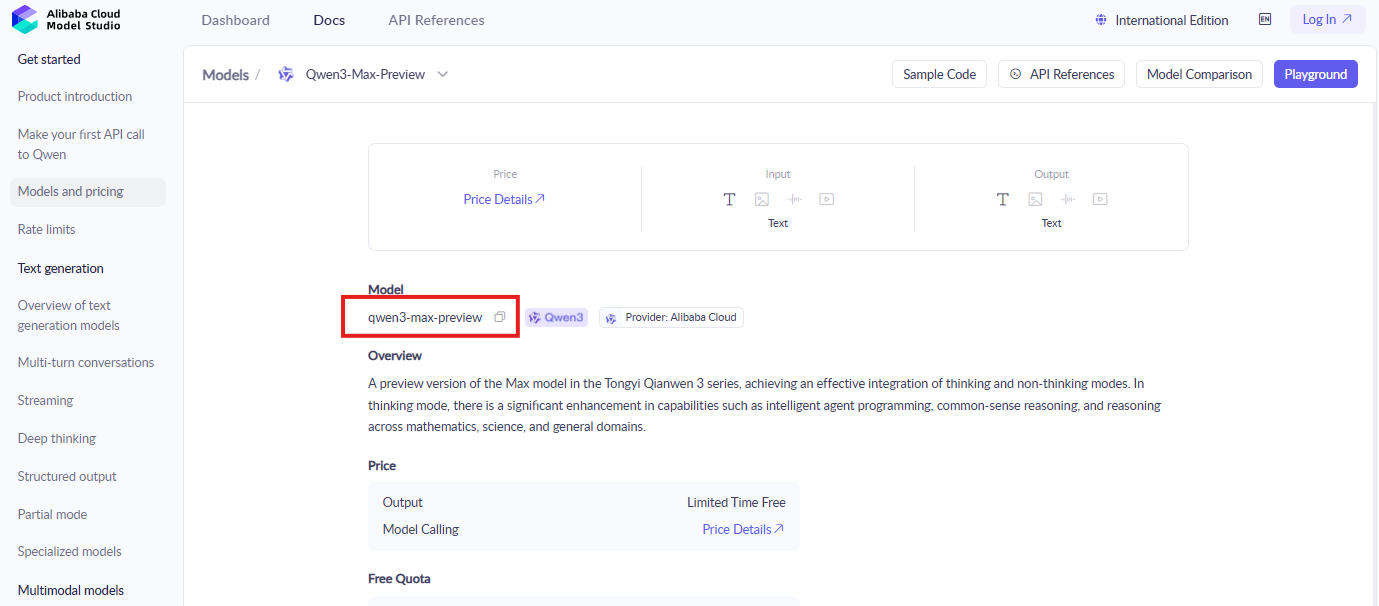
จากนั้นเปิดใช้งานโมเดล คลิกปุ่มเปิดใช้งานสำหรับ Qwen3-Max-Thinking และยอมรับข้อกำหนดหากได้รับแจ้ง ขั้นตอนนี้จะให้สิทธิ์การเข้าถึงคุณสมบัติพรีวิว นอกจากนี้ แลกโควตาโทเค็นฟรีโดยทำตามคำแนะนำบนหน้าจอ—บัญชีใหม่มีสิทธิ์โดยอัตโนมัติ
จากนั้นสร้างข้อมูลประจำตัว API ในพื้นที่การจัดการคีย์ API สร้างคู่คีย์ใหม่ บันทึกรหัสคีย์การเข้าถึงและความลับ; สิ่งเหล่านี้ใช้ในการรับรองความถูกต้องของคำขอ หลีกเลี่ยงการเปิดเผยต่อสาธารณะเพื่อรักษาความปลอดภัย
จากนั้นกำหนดค่าสภาพแวดล้อมการพัฒนาของคุณ ติดตั้งไลบรารีที่จำเป็นผ่าน pip เช่น pip install requests openai แม้ว่าจะเข้ากันได้กับ OpenAI แต่ให้ปรับปลายทางเป็น URL พื้นฐานของ Alibaba ซึ่งโดยทั่วไปจะคล้ายกับ "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
ทดสอบการเรียกใช้พื้นฐานเพื่อยืนยันการตั้งค่า สร้างเพย์โหลด JSON ด้วยชื่อโมเดล "qwen3-max-preview" พรอมต์อินพุต และพารามิเตอร์สำคัญ "enable_thinking": true ส่งคำขอ POST ไปยังปลายทาง ตัวอย่างเช่น:
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
ตรวจสอบการตอบสนองสำหรับขั้นตอนการคิดในเอาต์พุต หากสำเร็จ แสดงว่ามีการให้เหตุผลที่ใช้งานอยู่ อย่างไรก็ตาม ให้จัดการข้อผิดพลาดเช่น 401 สำหรับคีย์ที่ไม่ถูกต้องโดยการตรวจสอบข้อมูลประจำตัวอีกครั้ง
ขยายไปยังการกำหนดค่าขั้นสูง รวมการเรียกใช้เครื่องมือโดยการเพิ่มฟังก์ชันในเพย์โหลด API รองรับ Qwen-Agent สำหรับเวิร์กโฟลว์เชิงตัวแทน (agentic workflows) ซึ่งช่วยให้สามารถดำเนินการหลายขั้นตอนได้ นอกจากนี้ ใช้การแคชบริบทโดยการรวม ID แคชในคำขอเพื่อนำบริบทก่อนหน้ากลับมาใช้ใหม่ได้อย่างมีประสิทธิภาพ
แก้ไขปัญหาอย่างรวดเร็ว การจำกัดอัตราจะทำให้เกิดข้อผิดพลาด 429; เปลี่ยนไปใช้เวอร์ชันสแนปช็อตหรือปรับปรุงการสอบถาม ปัญหาเครือข่ายต้องมีการเชื่อมต่อที่เสถียร โดยทำตามขั้นตอนเหล่านี้ นักพัฒนาจะได้รับการเข้าถึง Qwen3-Max-Thinking API ที่เชื่อถือได้
การผสานรวม Qwen3-Max-Thinking API กับ Apidog
Apidog ช่วยลดความซับซ้อนของการโต้ตอบกับ API และนักพัฒนาใช้ประโยชน์จากมันสำหรับ Qwen3-Max-Thinking API เริ่มต้นด้วยการดาวน์โหลด Apidog จากเว็บไซต์ทางการ—ฟรีและติดตั้งได้อย่างรวดเร็วบนแพลตฟอร์มหลัก
จากนั้นนำเข้าข้อมูลจำเพาะ API Apidog รองรับรูปแบบ OpenAPI; ดาวน์โหลดข้อมูลจำเพาะของ Alibaba สำหรับโมเดล Qwen และอัปโหลด การดำเนินการนี้จะเติมปลายทางโดยอัตโนมัติ รวมถึงปลายทางสำหรับการสร้างข้อความ
จากนั้นตั้งค่าสภาพแวดล้อม สร้างสภาพแวดล้อมใหม่ใน Apidog โดยเพิ่มตัวแปรสำหรับคีย์ API และ URL พื้นฐาน การตั้งค่านี้ช่วยให้สามารถสลับระหว่างการทดสอบและการผลิตได้อย่างง่ายดาย
จากนั้นทดสอบคำขอ ใช้อินเทอร์เฟซของ Apidog เพื่อสร้างการเรียก POST ป้อนโมเดล พรอมต์ และพารามิเตอร์ enable_thinking ส่งคำขอและตรวจสอบการตอบสนองแบบเรียลไทม์ พร้อมคุณสมบัติเช่นการเน้นไวยากรณ์และการบันทึกข้อผิดพลาด
เชื่อมโยงคำขอสำหรับเวิร์กโฟลว์ที่ซับซ้อน Apidog อนุญาตให้จัดลำดับการเรียก ซึ่งเหมาะสำหรับงานเชิงตัวแทน (agentic tasks) ที่การตอบสนองหนึ่งส่งผลต่ออีกการตอบสนองหนึ่ง นอกจากนี้ ยังจำลองโหลดสูงเพื่อทดสอบประสิทธิภาพ
ทำงานร่วมกับทีมโดยใช้เครื่องมือการแบ่งปันของ Apidog ส่งออกคอลเลกชันเพื่อให้เพื่อนร่วมงานสามารถจำลองการตั้งค่าได้ นอกจากนี้ ตรวจสอบการใช้โทเค็นผ่านการวิเคราะห์แบบรวมเพื่อให้อยู่ในโควตา
ปรับปรุงการผสานรวมให้ดียิ่งขึ้น Apidog จัดการเพย์โหลดขนาดใหญ่ได้อย่างมีประสิทธิภาพ รองรับหน้าต่างบริบท 262K แก้ไขการหลอนโดยการปรับงบประมาณการคิดเมื่อพร้อมใช้งานเต็มรูปแบบ
สำรวจปลายทางและพารามิเตอร์ API
Qwen3-Max-Thinking API มีปลายทางหลายจุด โดยหลักๆ สำหรับการสร้างข้อความ จุดหลักคือ /api/v1/services/aigc/text-generation/generation ซึ่งจัดการงานการเติมข้อความ นักพัฒนาส่งข้อมูล JSON ที่นี่
พารามิเตอร์หลักได้แก่ "model" ซึ่งระบุ "qwen3-max-preview" ออบเจกต์ "input" มีข้อความในรูปแบบแชท นอกจากนี้ "parameters" กำหนดพฤติกรรม: ตั้งค่า "enable_thinking" เป็น True สำหรับโหมดการให้เหตุผล
- ตัวเลือกอื่นๆ ช่วยเพิ่มการควบคุม "max_tokens" จำกัดความยาวเอาต์พุตสูงสุด 65,536 "temperature" ปรับความคิดสร้างสรรค์ โดยมีค่าเริ่มต้นที่ 0.7 "top_p" ปรับแต่งการสุ่มตัวอย่าง
- สำหรับการใช้เครื่องมือ ให้รวมอาร์เรย์ "tools" พร้อมคำจำกัดความฟังก์ชัน API จะตอบสนองด้วยการเรียกใช้ ซึ่งช่วยให้เวิร์กโฟลว์เชิงตัวแทน (agentic flows) เป็นไปได้
- การแคชบริบทใช้ "cache_prompt" เพื่อจัดเก็บและอ้างอิงอินพุตก่อนหน้า ซึ่งช่วยลดค่าใช้จ่าย ระบุ ID แคชในคำขอถัดไป
- พารามิเตอร์การจัดการข้อผิดพลาดเช่น "retry" จัดการข้อผิดพลาดชั่วคราว นอกจากนี้ การกำหนดเวอร์ชันผ่าน "snapshot" ช่วยให้มั่นใจถึงความสอดคล้อง
การทำความเข้าใจสิ่งเหล่านี้ช่วยให้สามารถปรับแต่งได้อย่างแม่นยำ สำหรับปัญหาทางคณิตศาสตร์ การคิดที่สูงขึ้นจะช่วยให้มีขั้นตอนโดยละเอียด สำหรับการเขียนโค้ด จะสร้างโซลูชันที่แข็งแกร่ง นักพัฒนาทดลองเพื่อค้นหาการตั้งค่าที่เหมาะสมที่สุด
ตัวอย่างการใช้งาน Qwen3-Max-Thinking API ในทางปฏิบัติ
วิศวกรนำ API ไปใช้ในสถานการณ์ที่หลากหลาย พิจารณาการเขียนโค้ด: พรอมต์ "เขียนฟังก์ชัน Python เพื่อเรียงลำดับรายการ" เมื่อเปิดใช้งานการคิด ระบบจะสรุปตรรกะก่อนเขียนโค้ด
- ในทางคณิตศาสตร์ สอบถาม "แก้ปริพันธ์ของ x^2 dx" การตอบสนองจะแยกย่อยขั้นตอน แสดงกฎการอินทิเกรต
- สำหรับงานเชิงตัวแทน (agentic tasks) กำหนดเครื่องมือเช่นการค้นหาเว็บ โมเดลจะวางแผนการดำเนินการ ดำเนินการผ่านการเรียกกลับ และสังเคราะห์ผลลัพธ์
- การใช้งานในองค์กร: วิเคราะห์เอกสารยาวๆ โดยป้อนบริบท หน้าต่างขนาดใหญ่จะประมวลผลประวัติผู้ใช้เพื่อแนะนำ
- การศึกษา: สร้างคำอธิบายสำหรับหัวข้อที่ซับซ้อน โดยปรับความลึกผ่านพารามิเตอร์
- การดูแลสุขภาพ: สนับสนุนการตัดสินใจทางจริยธรรมด้วยผลลัพธ์ที่มีเหตุผล แม้ว่าจะต้องตรวจสอบเสมอ
- การเขียนเชิงสร้างสรรค์: สร้างเรื่องราวที่มีโครงเรื่องเชิงตรรกะ
ตัวอย่างเหล่านี้แสดงให้เห็นถึงความหลากหลาย นักพัฒนาสามารถปรับขนาดได้โดยใช้ Apidog สำหรับการทดสอบ
แนวทางปฏิบัติที่ดีที่สุดสำหรับการใช้งานอย่างมีประสิทธิภาพ
อันดับแรก ให้เพิ่มประสิทธิภาพการใช้โทเค็น สร้างพรอมต์ที่กระชับเพื่อหลีกเลี่ยงการสิ้นเปลือง ใช้การแคชสำหรับองค์ประกอบที่ซ้ำกัน
ตรวจสอบโควตาอย่างขยันขันแข็ง ติดตามการใช้งานในคอนโซล; อัปเกรดหากจำเป็น
รักษาความปลอดภัยคีย์ด้วยตัวแปรสภาพแวดล้อมหรือ vaults หมุนเวียนคีย์เป็นระยะ
จัดการการจำกัดอัตราโดยการใช้ exponential backoff ในโค้ด
ทดสอบอย่างละเอียดด้วย Apidog ก่อนนำไปใช้งานจริง จำลองกรณีขอบ
อัปเดตเป็นสแนปช็อตใหม่เมื่อมีการเผยแพร่ ตรวจสอบบันทึกการเปลี่ยนแปลง
รวมกับเครื่องมืออื่นๆ สำหรับระบบไฮบริด
ปฏิบัติตามสิ่งเหล่านี้เพื่อเพิ่มศักยภาพของ Qwen3-Max-Thinking API ให้สูงสุด
สรุป
Qwen3-Max-Thinking API เปลี่ยนแปลงแอปพลิเคชัน AI ด้วยการให้เหตุผลขั้นสูง ด้วยการปฏิบัติตามคู่มือนี้ นักพัฒนาสามารถเข้าถึงและผสานรวมได้อย่างมีประสิทธิภาพ โดยใช้ประโยชน์จาก Apidog เพื่อประสิทธิภาพ ในขณะที่คุณสมบัติมีการพัฒนาอย่างต่อเนื่อง API นี้ยังคงเป็นตัวเลือกอันดับต้นๆ สำหรับโครงการนวัตกรรม