
Desenvolvedores buscam constantemente modelos avançados de IA para aprimorar o raciocínio, a codificação e a resolução de problemas em suas aplicações. A API Qwen3-Max-Thinking se destaca como uma versão de prévia que expande os limites nessas áreas. Este guia explica como os engenheiros acessam e implementam esta API de forma eficaz. Além disso, ele destaca ferramentas que simplificam o processo.
A Alibaba Cloud impulsiona a API Qwen3-Max-Thinking, fornecendo uma prévia inicial de capacidades de pensamento aprimoradas. Lançado como um ponto de verificação intermediário durante o treinamento, este modelo alcança um desempenho notável em benchmarks como AIME 2025 e HMMT quando combinado com o uso de ferramentas e computação escalonada. Além disso, os usuários ativam o modo de pensamento facilmente através de parâmetros como enable_thinking=True. À medida que o treinamento avança, espere recursos ainda mais fortes. Este artigo cobre tudo, desde o registro até o uso avançado, garantindo que você integre a API Qwen3-Max-Thinking sem problemas em seus fluxos de trabalho.
Compreendendo a API Qwen3-Max-Thinking
Engenheiros reconhecem a API Qwen3-Max-Thinking como uma evolução da série Qwen da Alibaba, projetada especificamente para tarefas de raciocínio superiores. Ao contrário dos modelos padrão, esta prévia incorpora "orçamentos de pensamento" que permitem aos usuários controlar a profundidade do raciocínio em áreas como matemática, codificação e análise científica. A Alibaba lançou esta versão para demonstrar o progresso, mesmo com o treinamento em andamento.

O modelo base Qwen3-Max possui mais de um trilhão de parâmetros e treinamento em 36 trilhões de tokens, dobrando o volume de dados de seu predecessor, Qwen2.5. Ele suporta uma janela de contexto massiva de 262.144 tokens, com entrada máxima de 258.048 tokens e saída de 65.536 tokens. Além disso, ele lida com mais de 100 idiomas, tornando-o versátil para aplicações globais. No entanto, a variante Qwen3-Max-Thinking adiciona recursos de agente, reduzindo alucinações e permitindo processos de várias etapas através da chamada de ferramentas Qwen-Agent.
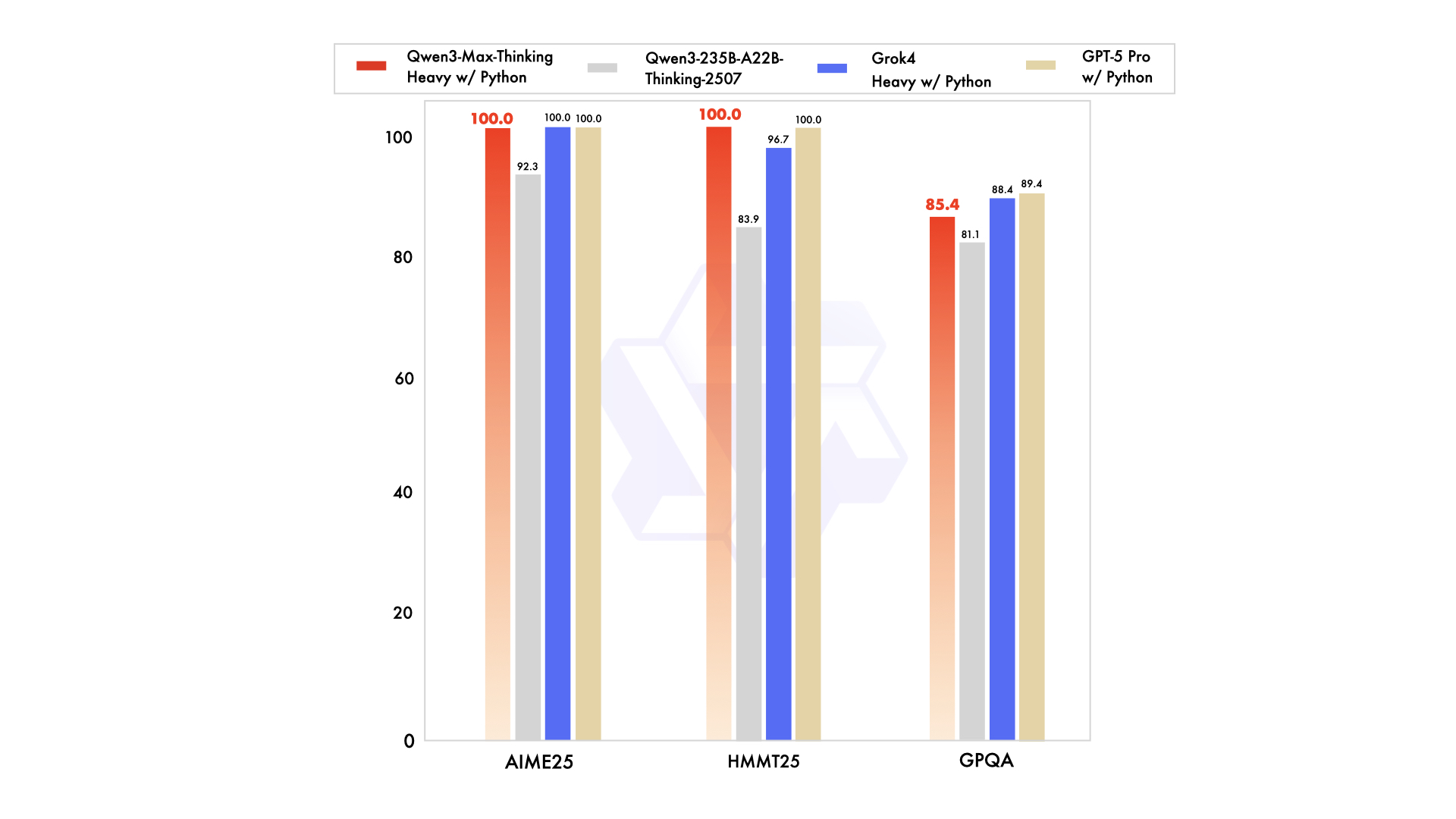
Métricas de desempenho destacam seus pontos fortes. Por exemplo, ele atinge 74,8 no LiveCodeBench v6 para codificação e 81,6 no AIME25 para matemática. Quando aumentado, ele alcança 100% em benchmarks desafiadores como AIME 2025 e HMMT. No entanto, esta prévia opera inicialmente como um modelo de instrução sem pensamento, com aprimoramentos de raciocínio ativados por meio de sinalizadores específicos. Os desenvolvedores o acessam através da API da Alibaba Cloud, que mantém compatibilidade com os padrões OpenAI para fácil migração.
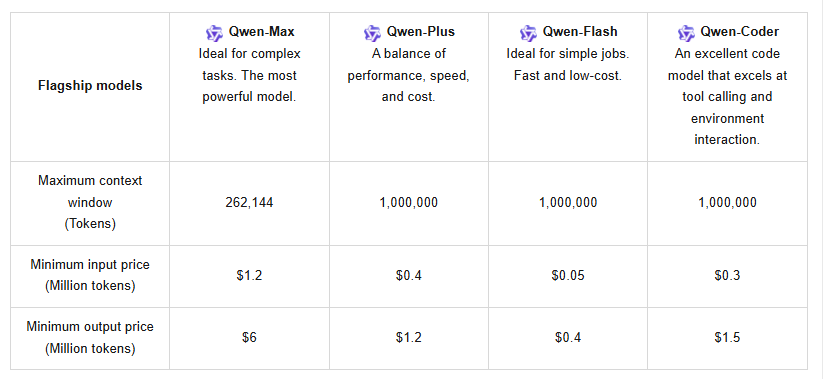
Além disso, a API suporta cache de contexto, o que otimiza consultas repetidas e reduz custos. A precificação segue uma estrutura em camadas: para 0–32K tokens, a entrada custa US$ 1,2 por milhão e a saída US$ 6 por milhão; para 32K–128K, a entrada sobe para US$ 2,4 e a saída para US$ 12; e para 128K–252K, a entrada atinge US$ 3 com a saída a US$ 15. Novos usuários se beneficiam de uma cota gratuita de um milhão de tokens, válida por 90 dias, incentivando o teste inicial.
Em comparação com concorrentes como Claude Opus 4 ou DeepSeek-V3.1, o Qwen3-Max-Thinking se destaca em tarefas de agente, como SWE-Bench Verified com 72,5. No entanto, seu status de prévia significa que alguns recursos, como orçamentos de pensamento completos, permanecem em desenvolvimento. Os usuários podem experimentá-lo via Qwen Chat para sessões interativas ou a API para acesso programático. Esta configuração posiciona a API Qwen3-Max-Thinking como uma ferramenta chave para desenvolvimento de software, educação e automação empresarial.
Pré-requisitos para Acessar a API Qwen3-Max-Thinking
Antes que os desenvolvedores prossigam, eles devem reunir os requisitos essenciais. Primeiro, crie uma conta Alibaba Cloud, caso ainda não tenha uma. Visite o site da Alibaba Cloud e registre-se usando um endereço de e-mail ou número de telefone. Verifique a conta através do link ou código fornecido para habilitar o acesso total.
Em seguida, certifique-se de estar familiarizado com os conceitos de API, incluindo endpoints RESTful e payloads JSON. A API Qwen3-Max-Thinking usa protocolos HTTPS, portanto, conexões seguras são importantes. Além disso, prepare ferramentas de desenvolvimento: Python 3.x ou linguagens semelhantes com bibliotecas como requests para chamadas HTTP. Para integrações avançadas, considere frameworks como vLLM ou SGLang, que suportam o serviço eficiente em várias GPUs.
A autenticação requer uma chave de API da Alibaba Cloud. Navegue até o console após o login e gere as chaves na seção de gerenciamento de API. Armazene-as com segurança, pois elas concedem acesso aos endpoints do modelo. Além disso, cumpra as políticas de uso — evite chamadas excessivas para evitar limites de taxa. O sistema oferece versões mais recentes e de snapshot; selecione snapshots para um desempenho estável sob altas cargas.
Considerações de hardware se aplicam para testes locais, embora o acesso à nuvem mitigue isso. O modelo exige computação significativa, mas a infraestrutura da Alibaba lida com isso. Finalmente, baixe ferramentas de suporte como o Apidog para otimizar os testes. O Apidog gerencia solicitações, ambientes e colaborações, tornando-o ideal para experimentar os parâmetros da API Qwen3-Max-Thinking.
Com isso em vigor, os engenheiros evitam armadilhas comuns como erros de autenticação ou esgotamento de cotas. Essa preparação garante uma transição suave para a implementação real.
Guia Passo a Passo para Obter e Configurar a API Qwen3-Max-Thinking
Os desenvolvedores começam fazendo login no console da Alibaba Cloud. Localize a seção ModelStudio, onde os modelos Qwen residem. Procure por "qwen3-max-preview" ou identificadores semelhantes para encontrar a documentação e a página de ativação.
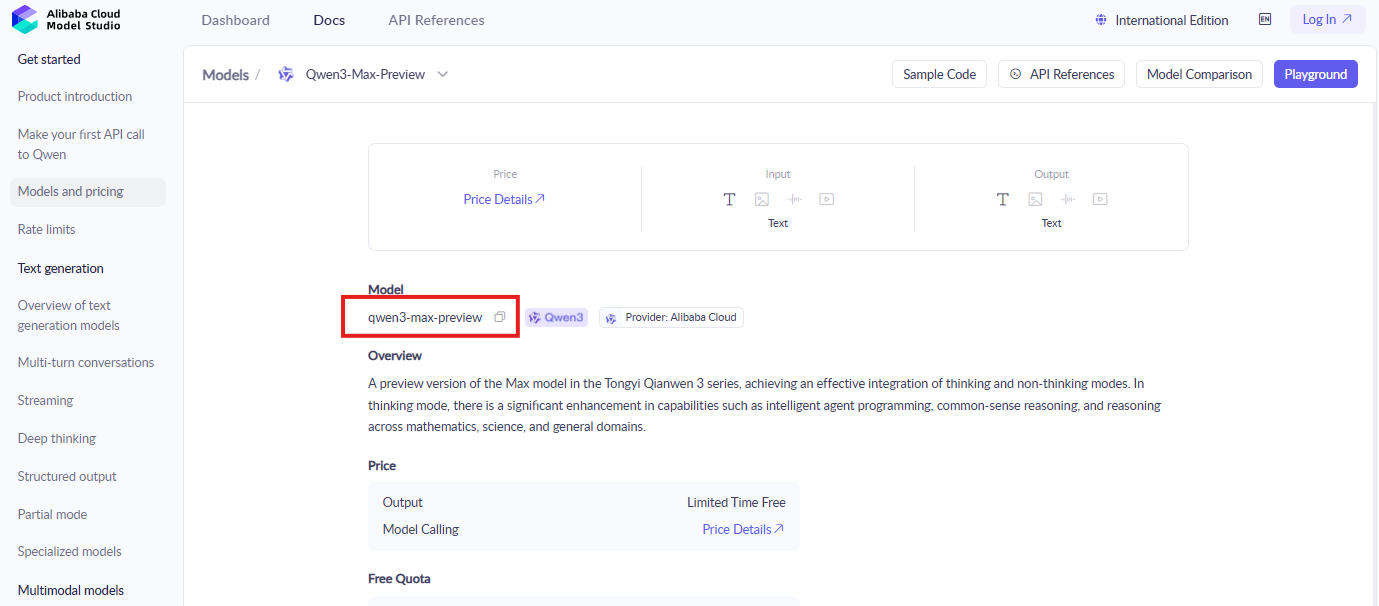
Ative o modelo em seguida. Clique no botão de ativação para Qwen3-Max-Thinking, concordando com os termos se solicitado. Este passo concede acesso aos recursos de prévia. Além disso, resgate a cota de tokens gratuita seguindo as instruções na tela — novas contas se qualificam automaticamente.
Gere as credenciais da API em seguida. Na área de gerenciamento de chaves de API, crie um novo par de chaves. Anote o ID da chave de acesso e o segredo; eles autenticam as solicitações. Evite compartilhá-los publicamente para manter a segurança.
Configure seu ambiente de desenvolvimento depois. Instale as bibliotecas necessárias via pip, como pip install requests openai. Embora compatível com OpenAI, ajuste os endpoints para a URL base da Alibaba, tipicamente algo como "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation".
Teste uma chamada básica para verificar a configuração. Construa um payload JSON com o nome do modelo "qwen3-max-preview", o prompt de entrada e o parâmetro crucial "enable_thinking": true. Envie uma solicitação POST para o endpoint. Por exemplo:
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Monitore a resposta para etapas de pensamento na saída. Se bem-sucedido, demonstra raciocínio ativo. No entanto, lide com erros como 401 para chaves inválidas verificando novamente as credenciais.
Expanda para configurações avançadas. Incorpore a chamada de ferramentas adicionando funções no payload. A API suporta Qwen-Agent para fluxos de trabalho de agente, permitindo execuções de várias etapas. Além disso, use o cache de contexto incluindo IDs de cache nas solicitações para reutilizar contextos anteriores de forma eficiente.
Solucione problemas prontamente. Limites de taxa acionam erros 429; mude para versões de snapshot ou otimize as consultas. Problemas de rede exigem conexões estáveis. Seguindo estas etapas, os desenvolvedores garantem acesso confiável à API Qwen3-Max-Thinking.
Integrando a API Qwen3-Max-Thinking com o Apidog
O Apidog simplifica as interações com a API, e os desenvolvedores o utilizam para a API Qwen3-Max-Thinking. Comece baixando o Apidog do site oficial — é gratuito e instala rapidamente nas principais plataformas.
Importe a especificação da API em seguida. O Apidog suporta formatos OpenAPI; baixe a especificação da Alibaba para modelos Qwen e faça o upload. Esta ação preenche os endpoints automaticamente, incluindo os de geração de texto.
Configure os ambientes em seguida. Crie um novo ambiente no Apidog, adicionando variáveis para chaves de API e URLs base. Esta configuração permite alternar facilmente entre testes e produção.
Teste as solicitações depois. Use a interface do Apidog para construir chamadas POST. Insira o modelo, o prompt e o parâmetro enable_thinking. Envie a solicitação e inspecione as respostas em tempo real, com recursos como realce de sintaxe e registro de erros.
Encadeie solicitações para fluxos de trabalho complexos. O Apidog permite sequenciar chamadas, ideal para tarefas de agente onde uma resposta alimenta outra. Além disso, simule altas cargas para testar o desempenho.
Colabore com equipes usando as ferramentas de compartilhamento do Apidog. Exporte coleções para que colegas repliquem as configurações. Além disso, monitore o uso de tokens através de análises integradas para permanecer dentro das cotas.
Otimize ainda mais as integrações. O Apidog lida com grandes payloads de forma eficiente, suportando a janela de contexto de 262K. Depure alucinações ajustando os orçamentos de pensamento quando totalmente disponíveis.
Explorando Endpoints e Parâmetros da API
A API Qwen3-Max-Thinking expõe vários endpoints, principalmente para geração de texto. O principal, /api/v1/services/aigc/text-generation/generation, lida com tarefas de conclusão. Desenvolvedores POSTAM dados JSON aqui.
Os parâmetros chave incluem "model", especificando "qwen3-max-preview". O objeto "input" contém mensagens no formato de chat. Além disso, "parameters" ditam o comportamento: defina "enable_thinking" como True para o modo de raciocínio.
- Outras opções aprimoram o controle. "max_tokens" limita o comprimento da saída, até 65.536. "temperature" ajusta a criatividade, com padrão de 0,7. "top_p" refina a amostragem.
- Para uso de ferramentas, inclua o array "tools" com definições de função. A API responde com chamadas, habilitando fluxos de agente.
- O cache de contexto usa "cache_prompt" para armazenar e referenciar entradas anteriores, reduzindo custos. Especifique IDs de cache em solicitações subsequentes.
- Parâmetros de tratamento de erros como "retry" gerenciam transientes. Além disso, o versionamento via "snapshot" garante consistência.
Compreender isso permite um ajuste preciso. Para problemas de matemática, um pensamento mais aprofundado permite etapas detalhadas; para codificação, gera soluções robustas. Os desenvolvedores experimentam para encontrar as configurações ideais.
Exemplos Práticos de Uso da API Qwen3-Max-Thinking
Engenheiros aplicam a API em diversos cenários. Considere a codificação: Solicite "Escreva uma função Python para ordenar uma lista." Com o pensamento ativado, ele descreve a lógica antes do código.
- Em matemática, consulte "Resolva a integral de x^2 dx." A resposta detalha as etapas, mostrando as regras de integração.
- Para tarefas de agente, defina ferramentas como pesquisa na web. O modelo planeja ações, executa via callbacks e sintetiza resultados.
- Uso empresarial: Analise documentos longos alimentando contextos. A grande janela processa históricos de usuários para recomendações.
- Educação: Gere explicações para tópicos complexos, adaptando a profundidade via parâmetros.
- Saúde: Apoie decisões éticas com resultados fundamentados, embora sempre verifique.
- Escrita criativa: Produza histórias com enredos lógicos.
Esses exemplos ilustram a versatilidade. Os desenvolvedores os escalam usando o Apidog para testes.
Melhores Práticas para Uso Eficiente
Otimize o consumo de tokens primeiro. Crie prompts concisos para evitar desperdício. Use cache para elementos repetitivos.
- Monitore as cotas diligentemente. Acompanhe o uso no console; faça upgrade se necessário.
- Proteja as chaves com variáveis de ambiente ou cofres. Gire-as periodicamente.
- Lide com limites de taxa implementando um backoff exponencial no código.
- Teste completamente com o Apidog antes da produção. Simule casos extremos.
- Atualize para novos snapshots assim que lançados, verificando os changelogs.
- Combine com outras ferramentas para sistemas híbridos.
Siga estas práticas para maximizar o potencial da API Qwen3-Max-Thinking.
Conclusão
A API Qwen3-Max-Thinking transforma aplicações de IA com raciocínio avançado. Seguindo este guia, os desenvolvedores acessam e a integram de forma eficaz, aproveitando o Apidog para eficiência. À medida que os recursos evoluem, ela permanece uma escolha superior para projetos inovadores.