
ローカルマシンでLLMを実行することにはいくつかの利点があります。まず、データに対する完全なコントロールを得られ、プライバシーが保たれます。次に、高額なAPIコールや月額サブスクリプションを気にせずに実験ができます。さらに、ローカルデプロイメントは、これらのモデルがどのように動作するかを学ぶための実践的な方法を提供します。
さらに、LLMをローカルで実行することで、ネットワークのレイテンシの問題やクラウドサービスへの依存を回避できます。これは、特にコードベースと密接に統合する必要があるプロジェクトに取り組む場合、より速く構築、テスト、反復できることを意味します。
LLMの理解: 簡単な概要
私たちのおすすめを紹介する前に、LLMとは何かを簡単に説明しましょう。簡単に言えば、大型言語モデル(LLM)は、大量のテキストデータで訓練されたAIモデルです。これらのモデルは、言語の統計的パターンを学習し、提供されたプロンプトに基づいて人間のようなテキストを生成することができます。
LLMは多くの現代のAIアプリケーションの中心です。チャットボット、ライティングアシスタント、コードジェネレーター、さらには高度な対話型エージェントを支えています。しかし、これらのモデルを実行すること、特に大規模なものは、リソースを大量に消費します。だからこそ、信頼できるツールを使用してローカルでそれらを実行することが非常に重要です。
ローカルのLLMツールを使用すると、データをリモートサーバーに送信することなく、これらのモデルで実験できます。これにより、セキュリティとパフォーマンスが向上します。このチュートリアルを通じて、「LLM」というキーワードが強調され、各ツールがこれらの強力なモデルを自分のハードウェア上で活用するのにどのように役立つかを探ります。
1: Llama.cpp
Llama.cppは、ローカルでLLMを実行する際に最も人気のあるツールの1つといえるでしょう。Georgi Gerganovによって作成され、活気のあるコミュニティによって維持されているこのC/C++ライブラリは、LLaMAや他のモデルに対する推論を最小限の依存関係で実行するように設計されています。

Llama.cppが好きな理由
- 軽量で高速: Llama.cppはスピードと効率を重視して設計されています。最小限の設定で、控えめなハードウェアでも複雑なモデルを実行できます。AVXやNeonのような高度なCPU命令を活用しているため、システムのパフォーマンスを最大限に引き出すことができます。
- 多様なハードウェアサポート: x86マシン、ARMベースのデバイス、Apple Silicon Macのいずれを使用していても、Llama.cppが対応します。
- コマンドラインの柔軟性: グラフィカルインターフェイスよりもターミナルを好む方には、Llama.cppのコマンドラインツールが、シェルからモデルを読み込んで応答を生成するのを簡単にします。
- コミュニティとオープンソース: オープンソースプロジェクトとして、世界中の開発者の継続的な貢献や改善の恩恵を受けています。
始め方
- インストール: GitHubからリポジトリをクローンし、自分のマシンでコードをコンパイルします。
- モデルの設定: お好きなモデル(例えば、量子化されたLLaMAのバリエーション)をダウンロードし、提供されたコマンドラインユーティリティを使用して推論を開始します。
- カスタマイズ: コンテキストの長さ、温度、ビームサイズなどのパラメータを調整して、モデルの出力がどのように変わるかを見てみましょう。
例えば、シンプルなコマンドは次のようになります:
./main -m ./models/llama-7b.gguf -p "プログラミングに関するジョークを教えて" --temp 0.7 --top_k 100
このコマンドはモデルを読み込み、プロンプトに基づいてテキストを生成します。この設定のシンプルさは、ローカルでのLLM推論を始めようとする人にとって大きな利点です。
Llama.cppからスムーズに移行し、少し異なるアプローチをとる別の素晴らしいツールを見ていきましょう。
2: GPT4All
GPT4Allは、Nomic AIによって設計されたオープンソースのエコシステムで、LLMsへのアクセスを民主化しています。GPT4Allの最もエキサイティングな側面の1つは、消費者向けハードウェア上で実行できるように構築されているため、高価なマシンを必要とせずに実験することができる点です。
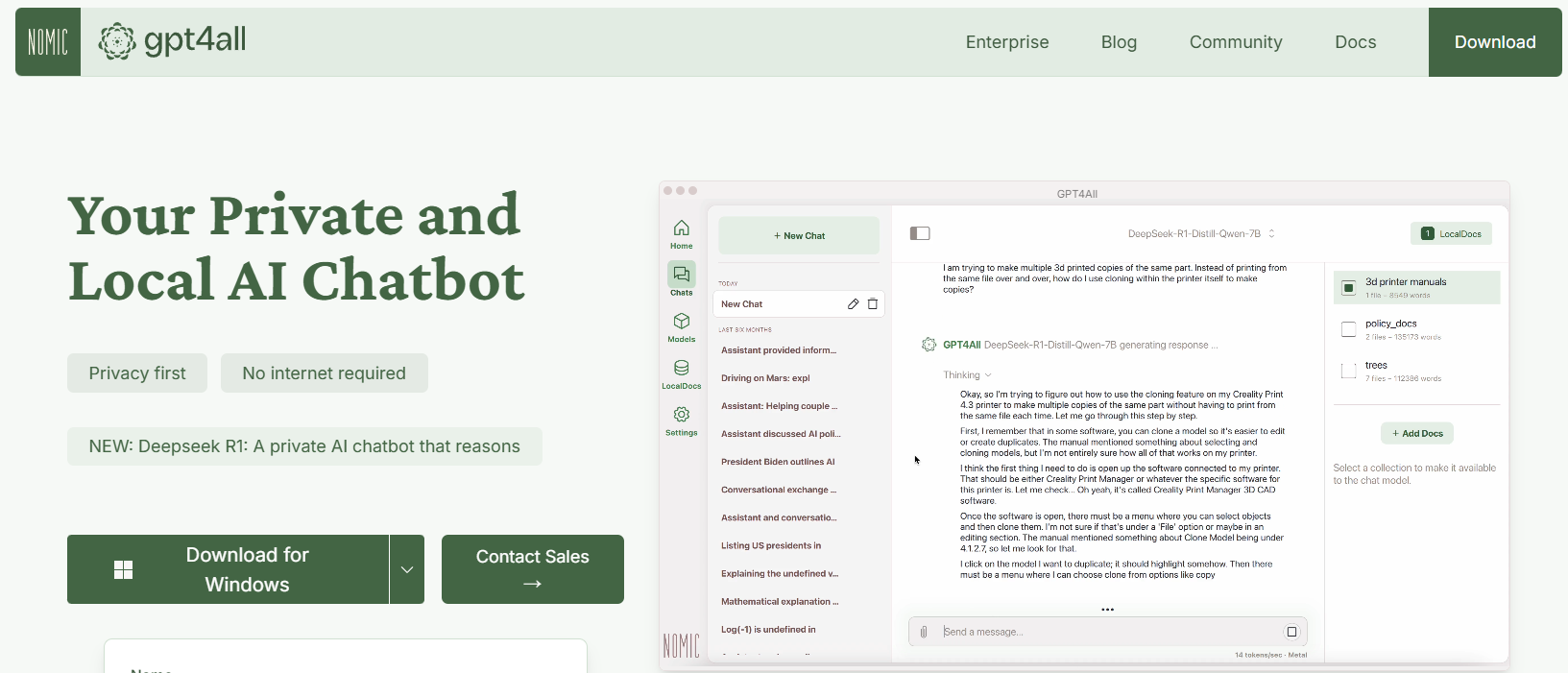
GPT4Allの主な機能
- ローカルファーストのアプローチ: GPT4Allは、完全にローカルデバイス上で実行されるように構築されています。これにより、データがマシンから出ることはなく、プライバシーと迅速な応答時間が保証されます。
- ユーザーフレンドリー: LLMが初めての方でも、GPT4Allは簡単かつ直感的なインターフェースを提供し、深い技術的知識がなくてもモデルと対話できます。
- 軽量で効率的: GPT4Allエコシステム内のモデルはパフォーマンスの最適化が施されています。ノートパソコンで実行できるため、より広範なオーディエンスにアクセス可能です。
- オープンソースとコミュニティ駆動: オープンソースの特性を持つGPT4Allは、コミュニティの貢献を招き、最新の革新に常に対応できるようにしています。
GPT4Allを始める方法
- インストール: GPT4Allのウェブサイトからダウンロードします。インストールプロセスは簡単で、Windows、macOS、Linux用の事前コンパイルされたバイナリが利用できます。
- モデルの実行: インストールが完了したら、アプリケーションを起動し、さまざまな事前調整済みモデルの中から選択します。このツールはカジュアルな実験に最適なチャットインターフェースも提供しています。
- カスタマイズ: モデルの応答の長さやクリエイティビティ設定などのパラメータを調整し、出力がどのように変わるかを見てみましょう。これにより、さまざまな条件下でLLMがどのように機能するかを理解できます。
例えば、次のようなプロンプトを入力することがあります:
人工知能に関する興味深い事実は何ですか?
そしてGPT4Allは、すべてインターネット接続なしにフレンドリーで洞察に富んだ応答を生成します。
3: LM Studio
次に、LM Studioは、特にモデル管理を簡単に行いたい方に最適なローカルでLLMを実行するための別の優れたツールです。
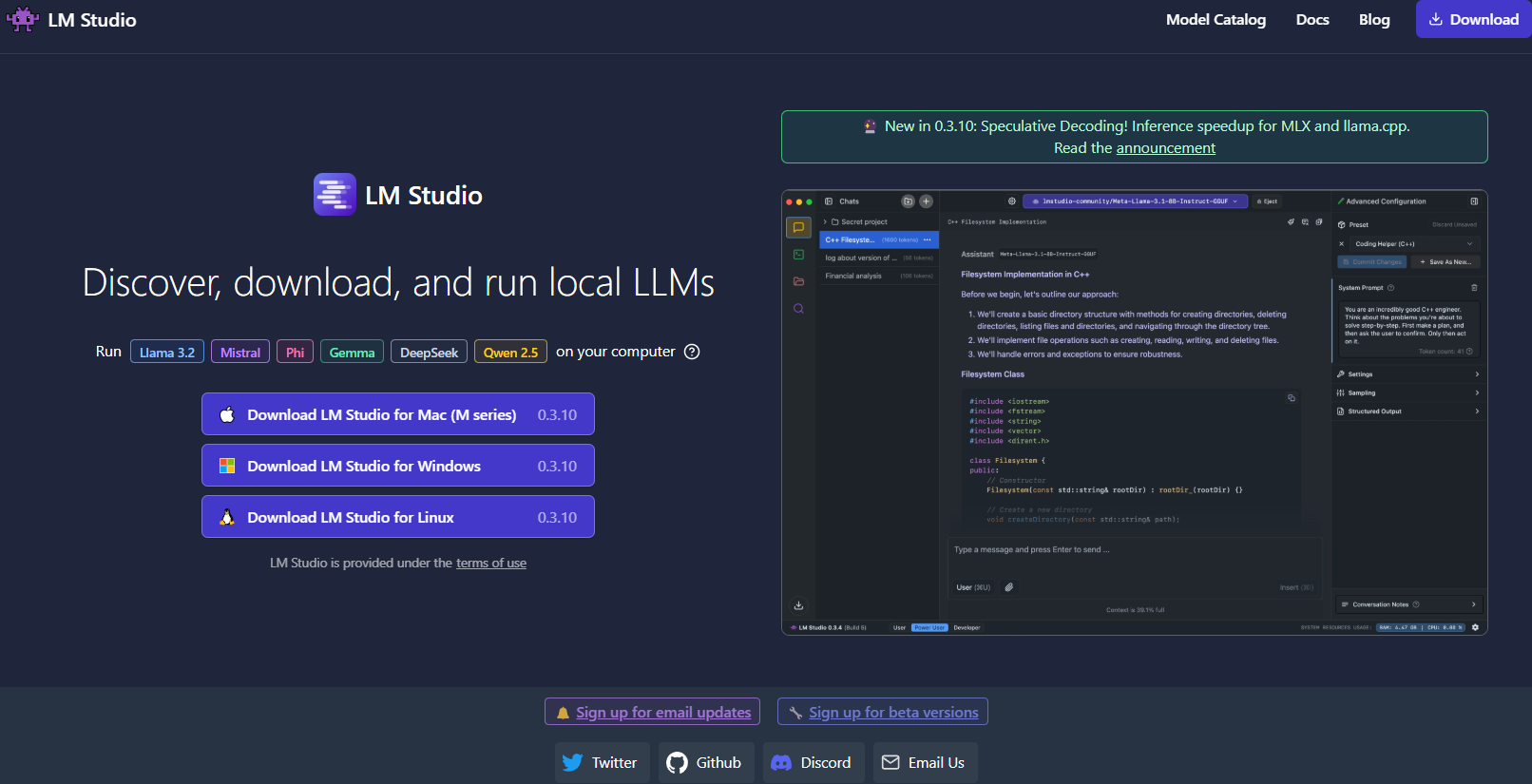
LM Studioの特長は何ですか?
- 直感的なユーザーインターフェース: LM Studioは、洗練されたユーザーフレンドリーなデスクトップアプリケーションを提供します。これは、コマンドラインだけで作業することを好まない方に最適です。
- モデル管理: LM Studioでは、さまざまなLLMを簡単にブラウズ、ダウンロード、切り替えることができます。アプリは組み込みのフィルターや検索機能を備えており、プロジェクトに最適なモデルを見つけることができます。
- カスタマイズ可能な設定: UIから温度、最大トークン数、コンテキストウィンドウなどのパラメータを直接調整できます。この即時フィードバックループは、さまざまな設定がモデルの挙動にどのように影響するかを学ぶのに最適です。
- クロスプラットフォームの互換性: LM StudioはWindows、macOS、Linuxで動作し、幅広いユーザーにアクセス可能です。
- ローカル推論サーバ: 開発者はOpenAI APIを模倣するローカルHTTPサーバも活用でき、LLM機能をアプリケーションに簡単に統合できます。
LM Studioの設定方法
- ダウンロードとインストール: LM Studioのウェブサイトを訪れ、オペレーティングシステム用のインストーラをダウンロードし、設定手順に従います。
- 起動して探索: アプリケーションを開き、利用可能なモデルのライブラリを探索し、自分のニーズに合ったモデルを選択します。
- 実験: 組み込みのチャットインターフェースを使用してモデルと対話します。また、複数のモデルを同時に実験して、パフォーマンスや品質を比較することもできます。
たとえば、創造的なライティングプロジェクトに取り組んでいる場合、LM Studioのインターフェースを使用することで、モデルを簡単に切り替え、リアルタイムで出力を微調整することができます。視覚的なフィードバックと使いやすさは、初めての方やローカルソリューションを必要としているプロフェッショナルにとって強力な選択肢です。
4: Ollama
次に紹介するのはOllamaで、シンプルさと機能性に焦点を当てた強力で使いやすいコマンドラインツールです。Ollamaは、複雑なセットアップの煩わしさを避けながらLLMを実行、作成、共有する手助けをすることを目的としています。
Ollamaを選ぶ理由
- 簡単なモデルデプロイメント: Ollamaは、モデルの重み、設定、データを「Modelfile」として知られる単一のポータブルユニットにパッケージ化します。これにより、最小限の設定で迅速にモデルをダウンロードして実行できます。
- マルチモーダル機能: テキストのみにフォーカスするツールとは異なり、Ollamaはマルチモーダル入力をサポートします。テキストと画像の両方をプロンプトとして提供することができ、ツールは両方を考慮に入れた応答を生成します。
- クロスプラットフォームの利用可能性: OllamaはmacOS、Linux、Windowsで利用可能です。異なるシステム間で作業する開発者にとって素晴らしいオプションです。
- コマンドラインの効率性: ターミナルで作業することを好む方には、Ollamaが迅速なデプロイメントと対話を実現するクリーンで効率的なコマンドラインインターフェースを提供します。
- 迅速なアップデート: コミュニティによって頻繁にアップデートされ、最新の改善や機能が常に利用可能です。
Ollamaの設定方法
1. インストール: Ollamaのウェブサイトにアクセスし、オペレーティングシステム用のインストーラをダウンロードします。インストールはターミナルでいくつかのコマンドを実行するだけなので簡単です。
2. モデルを実行: インストールが完了したら、次のようなコマンドを使用します:
ollama run llama3
このコマンドは、Llama 3モデル(または他のサポートされているモデル)を自動的にダウンロードし、推論プロセスを開始します。
3. マルチモダリティで実験: 画像をサポートするモデルを実行してみてください。たとえば、準備された画像ファイルがある場合、プロンプトにドラッグアンドドロップするか(または画像用のAPIパラメータを使用)して、モデルがどのように応答するかを確認できます。
Ollamaは、LLMをローカルに迅速にプロトタイピングまたはデプロイする際に特に魅力的です。そのシンプルさは力を犠牲にすることなく、初心者でも経験豊富な開発者でも理想的です。
5: Jan
最後に紹介するのはJanです。Janはオープンソースのローカルファーストプラットフォームで、データプライバシーとオフライン操作を重視する人々の間で徐々に人気を集めています。その哲学はシンプルです。ユーザーが強力なLLMを完全に自分のハードウェア上で実行できるようにし、隠れたデータ転送を排除します。
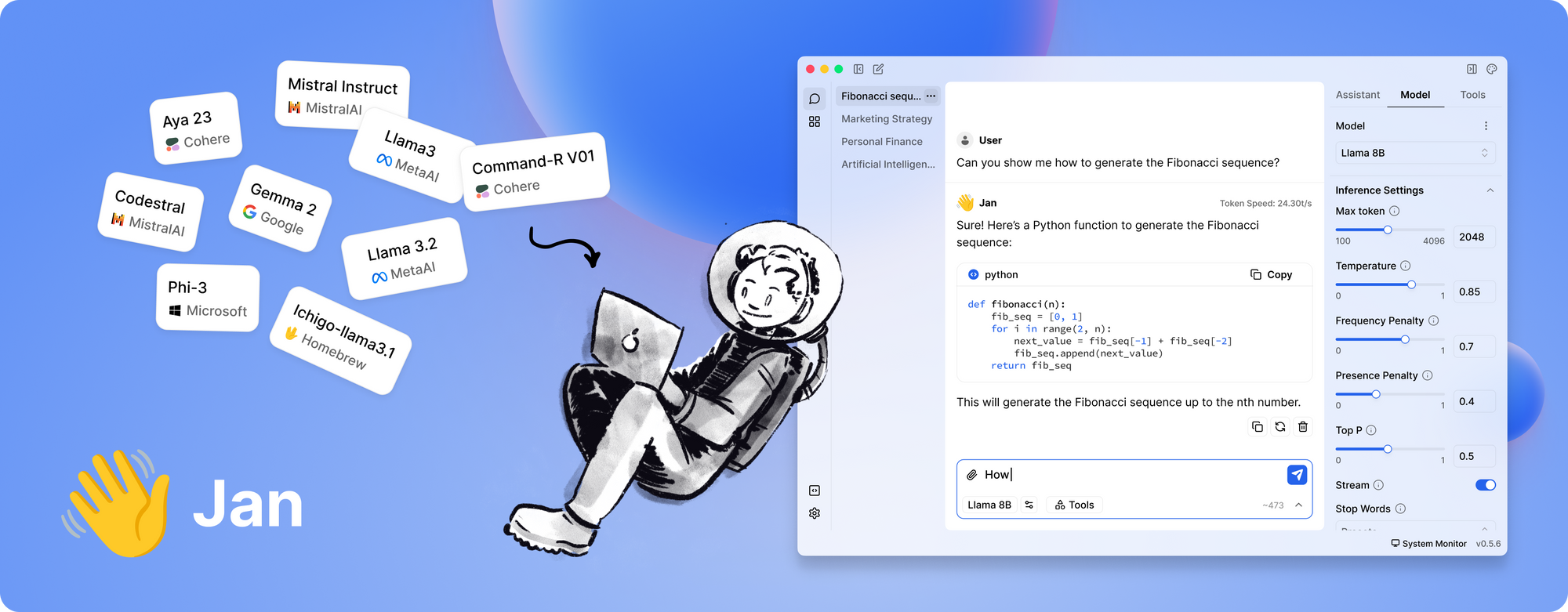
Janの特長は何ですか?
- 完全にオフライン: Janはインターネット接続なしで動作するように設計されています。これにより、すべてのインタラクションとデータがローカルに保たれ、プライバシーとセキュリティが強化されます。
- ユーザー中心で拡張可能: ツールはクリーンなインターフェースを提供し、アプリ/プラグインフレームワークをサポートしています。これにより、その機能を簡単に拡張したり、既存のツールと統合したりできます。
- 効率的なモデル実行: Janは、特定のタスク用に微調整されたさまざまなモデルを処理できるように構築されています。パフォーマンスを妥協することなく控えめなハードウェアでも実行できるよう最適化されています。
- コミュニティ主導の開発: 私たちのリストの多くのツールと同様に、Janはオープンソースで、献身的な開発者コミュニティの貢献から恩恵を受けています。
- サブスクリプション料金なし: 多くのクラウドベースのソリューションとは異なり、Janは無料で使用できます。これは、スタートアップやホビイスト、財政的制約なしにLLMを実験したい人にとって素晴らしい選択肢です。
Janを始める方法
- ダウンロードとインストール: Janの公式ウェブサイトまたはGitHubリポジトリにアクセスします。インストール手順は簡単で、迅速に使用開始できるように設計されています。
- 起動とカスタマイズ: Janを開き、さまざまなプリインストールされたモデルから選択します。必要に応じて、Hugging Faceなどの外部ソースからモデルをインポートできます。
- 実験と拡張: チャットインターフェースを使用してLLMと対話します。パラメータを調整したり、プラグインをインストールしたりして、Janがワークフローにどのように適応するかを見てみましょう。その柔軟性により、ローカルLLM体験を正確なニーズに合わせて調整できます。
Janは、本当にローカルでプライバシーを重視したLLM実行の精神を具現化しています。すべてのデータを自分のマシンに保持しながら、手間のかからないカスタマイズ可能なツールを望む人に最適です。
プロのヒント: SSEデバッグを使用したLLMレスポンスのストリーミング
LLM(大型言語モデル)を扱う場合、リアルタイムのインタラクションはユーザー体験を大いに向上させることができます。チャットボットがライブ応答を提供する場合や、データが生成されるにつれて動的に更新されるコンテンツツールの場合、ストリーミングは重要です。サーバー送信イベント(SSE)は、これに対する効率的なソリューションを提供し、サーバーがクライアントに単一のHTTP接続を介して更新をプッシュできるようにします。双方向プロトコル(WebSocketsなど)とは異なり、SSEはシンプルでわかりやすいため、リアルタイム機能に最適です。
SSEのデバッグは難しい場合があります。そこにApidogが登場します。ApidogのSSEデバッグ機能を使用すると、SSEストリームを簡単にテスト、モニタリング、トラブルシューティングできます。このセクションでは、なぜSSEがLLM APIのデバッグに重要であるのかを探り、Apidogを使用してSSE接続を設定し、テストするためのステップバイステップのチュートリアルをお届けします。
なぜSSEがLLM APIのデバッグに重要なのか
チュートリアルに入る前に、SSEがLLM APIのデバッグに適している理由を以下に示します:
- リアルタイムフィードバック: SSEは生成されたデータをストリーム形式で提供し、ユーザーが応答を自然に見ることができます。
- 低オーバーヘッド: ポーリングとは異なり、SSEは単一の永続的な接続を使用し、リソースの使用を最小限に抑えます。
- 使いやすさ: SSEはWebアプリケーションにシームレスに統合され、クライアント側の設定が最小限で済みます。
試してみる準備はできましたか? ApidogでSSEデバッグを設定しましょう。
ステップバイステップチュートリアル: ApidogでのSSEデバッグの使用
以下の手順に従って、ApidogでSSE接続を設定し、テストします。
ステップ1: Apidogで新しいAPIを作成
Apidogで新しいHTTPプロジェクトを作成してAPIリクエストをテストおよびデバッグします。SSEストリーム用にAIモデルのURLを持つAPIを追加します。この例ではDeepSeekを使用します。(プロのヒント: ApidogのAPIハブから用意されたDeepSeek APIプロジェクトをクローンしてください。)
ステップ2: リクエストを送信
APIを追加した後、送信をクリックしてリクエストを送信します。応答ヘッダーにContent-Type: text/event-streamが含まれている場合、ApidogはSSEストリームを検出し、データを解析してリアルタイムで表示します。
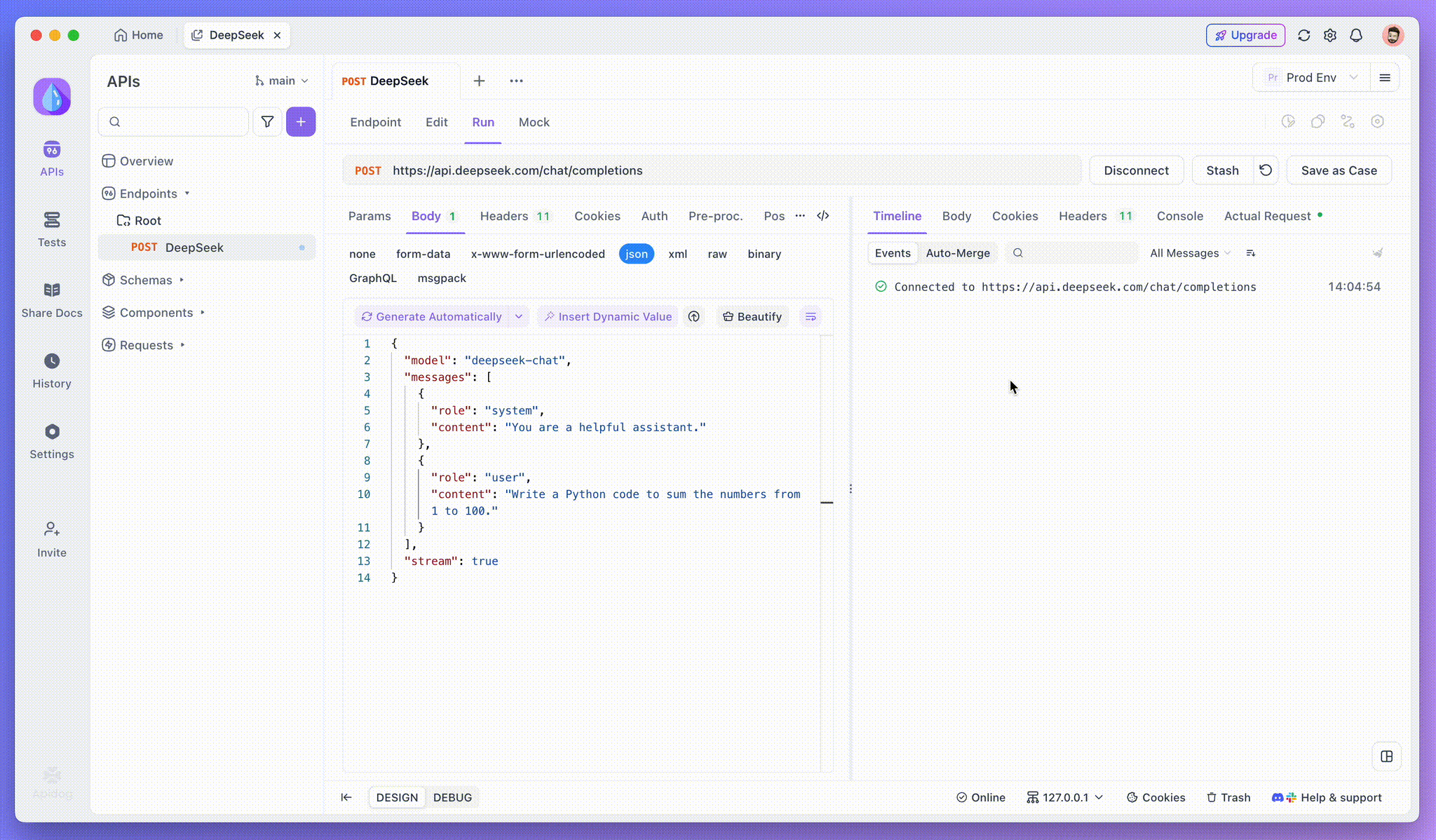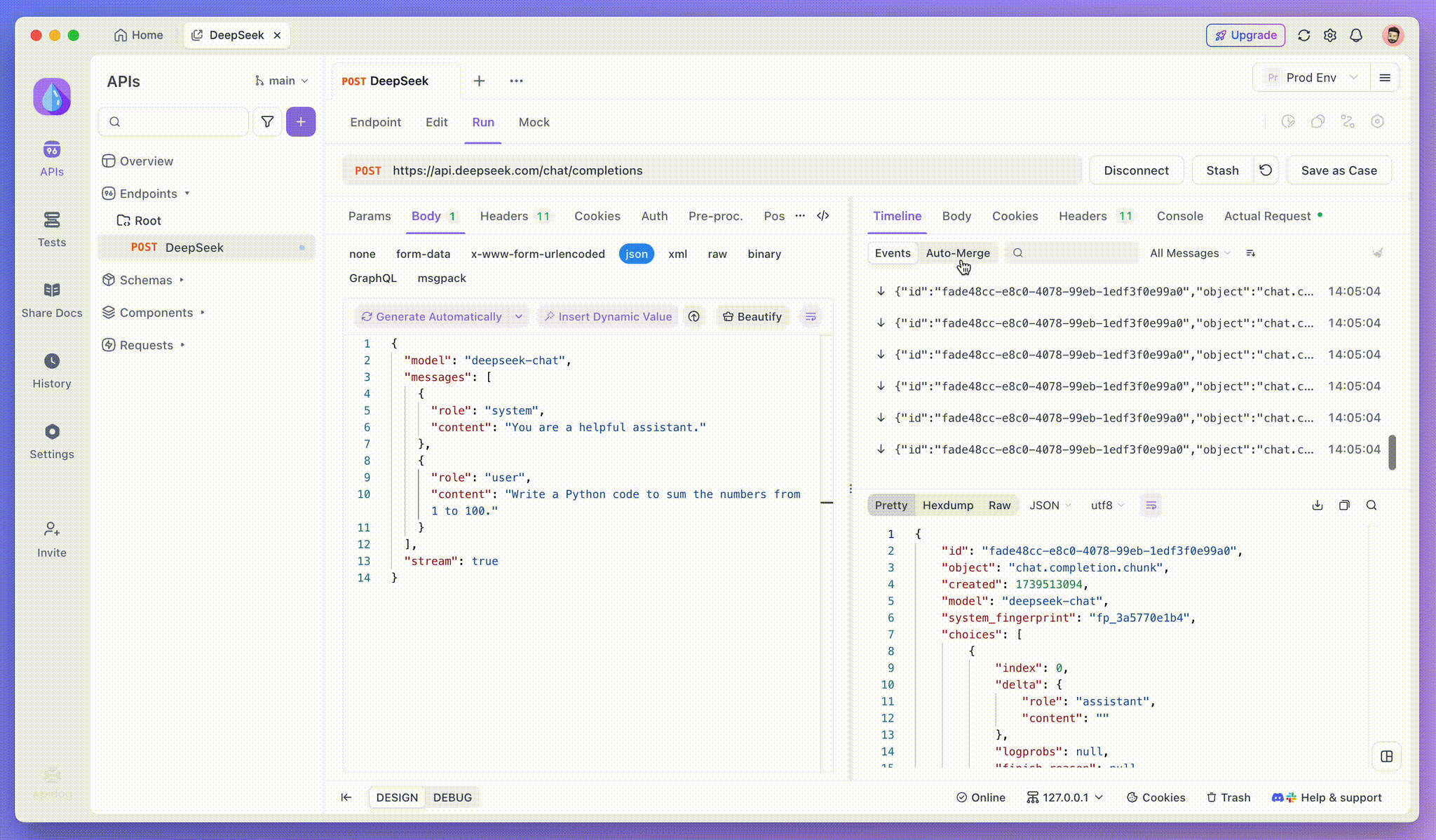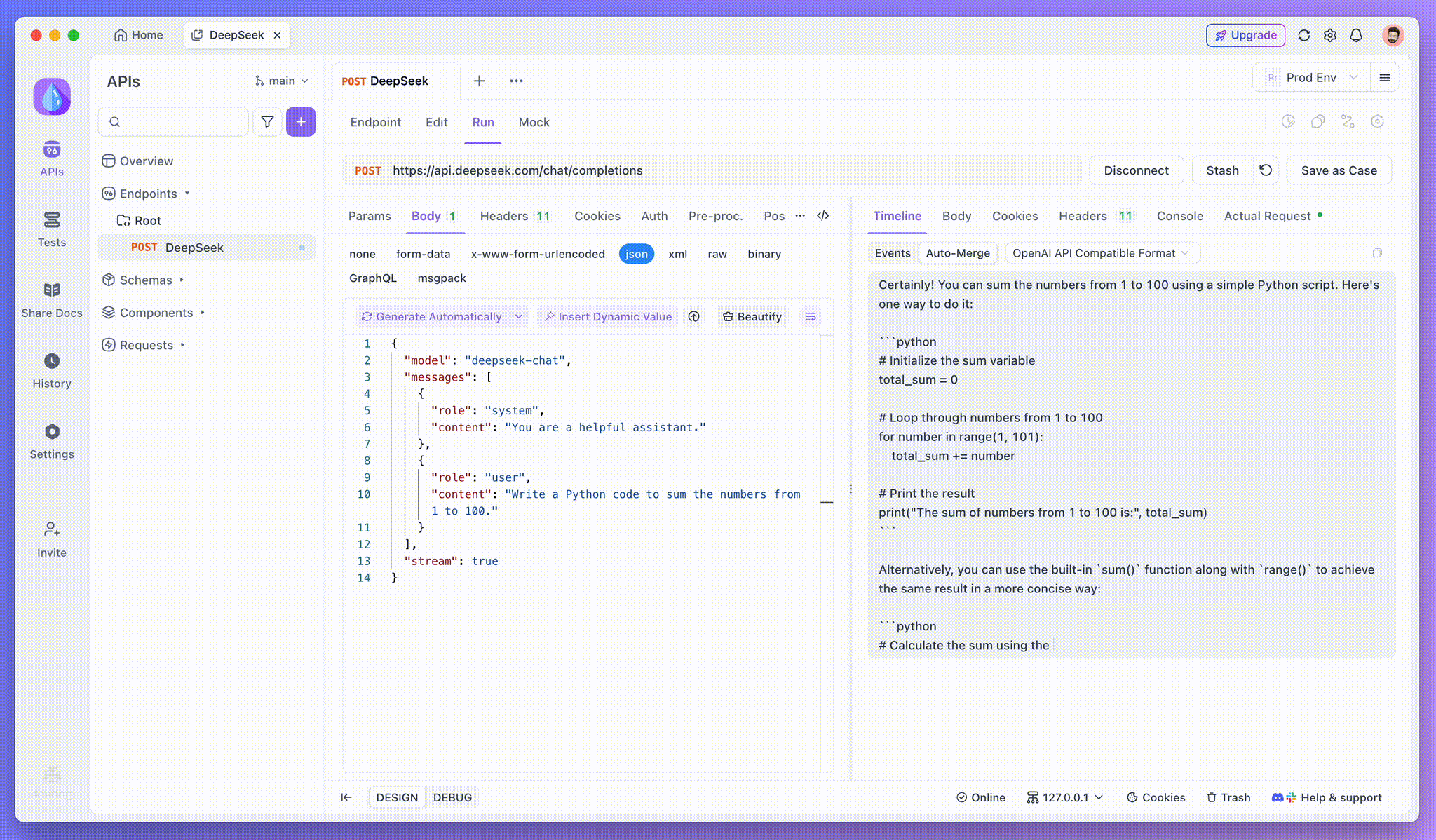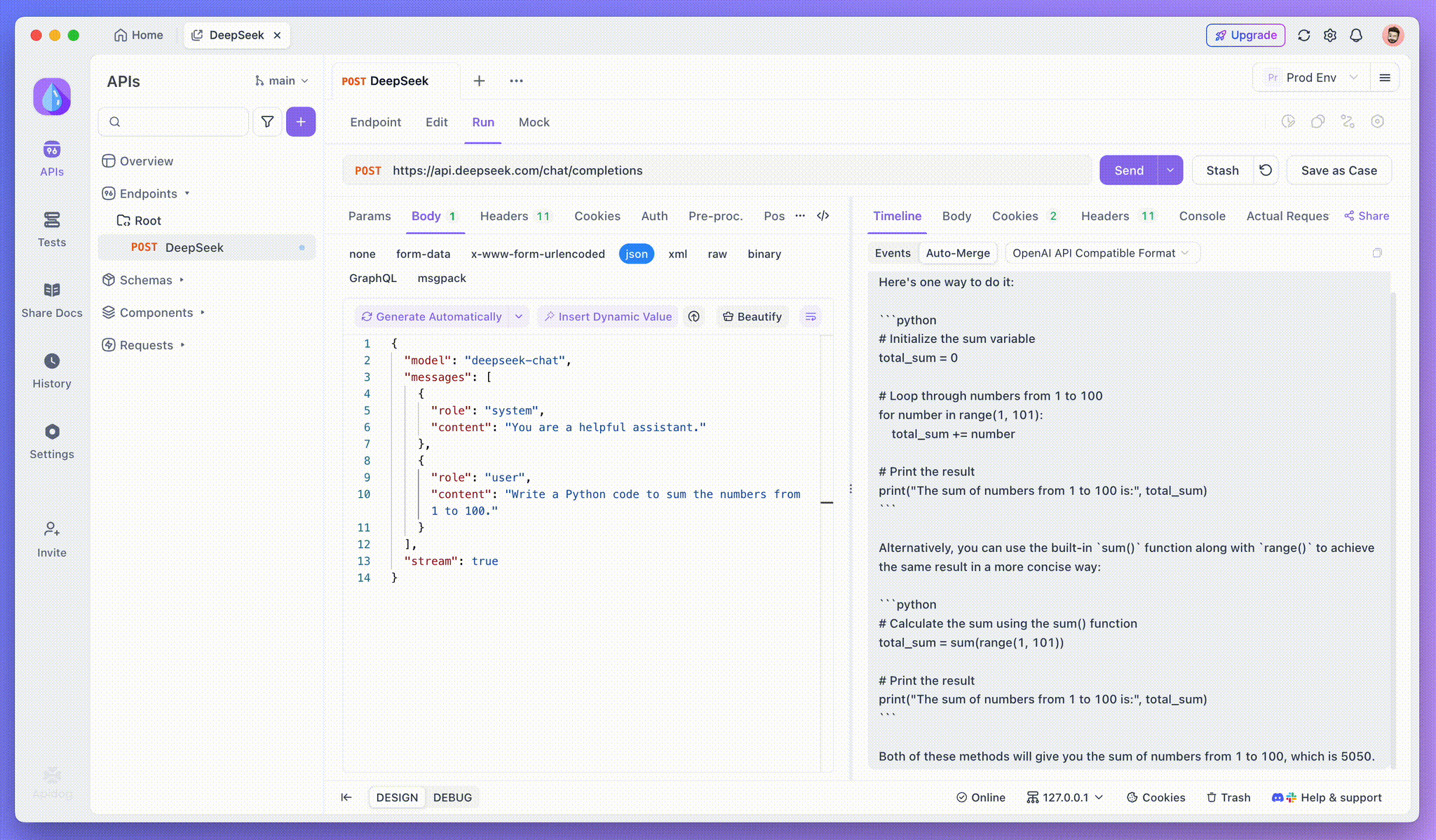
ステップ3: リアルタイムの応答を表示
Apidogのタイムラインビューは、AIモデルが応答をストリーミングする際にリアルタイムで更新され、各部分を動的に表示します。これにより、AIの思考プロセスを追跡し、出力生成についての洞察を得ることができます。
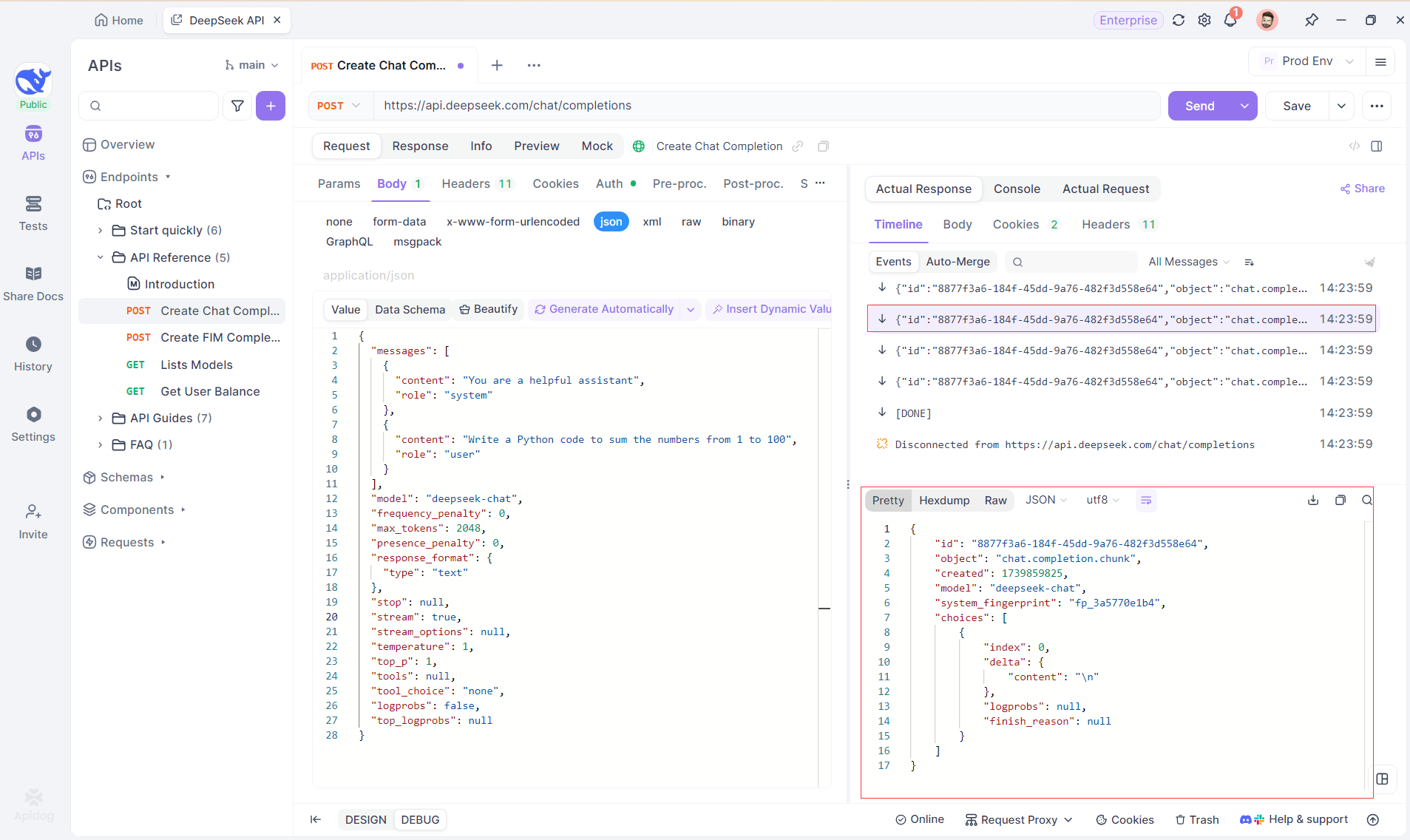
ステップ4: 完全な応答でのSSEレスポンスの表示
SSEはフラグメントにデータをストリーミングするため、追加の処理が必要です。Apidogのオートマージ機能は、OpenAI、Gemini、またはClaudeのようなモデルからの断片的なAI応答を自動的に組み合わせ、完全な出力にします。
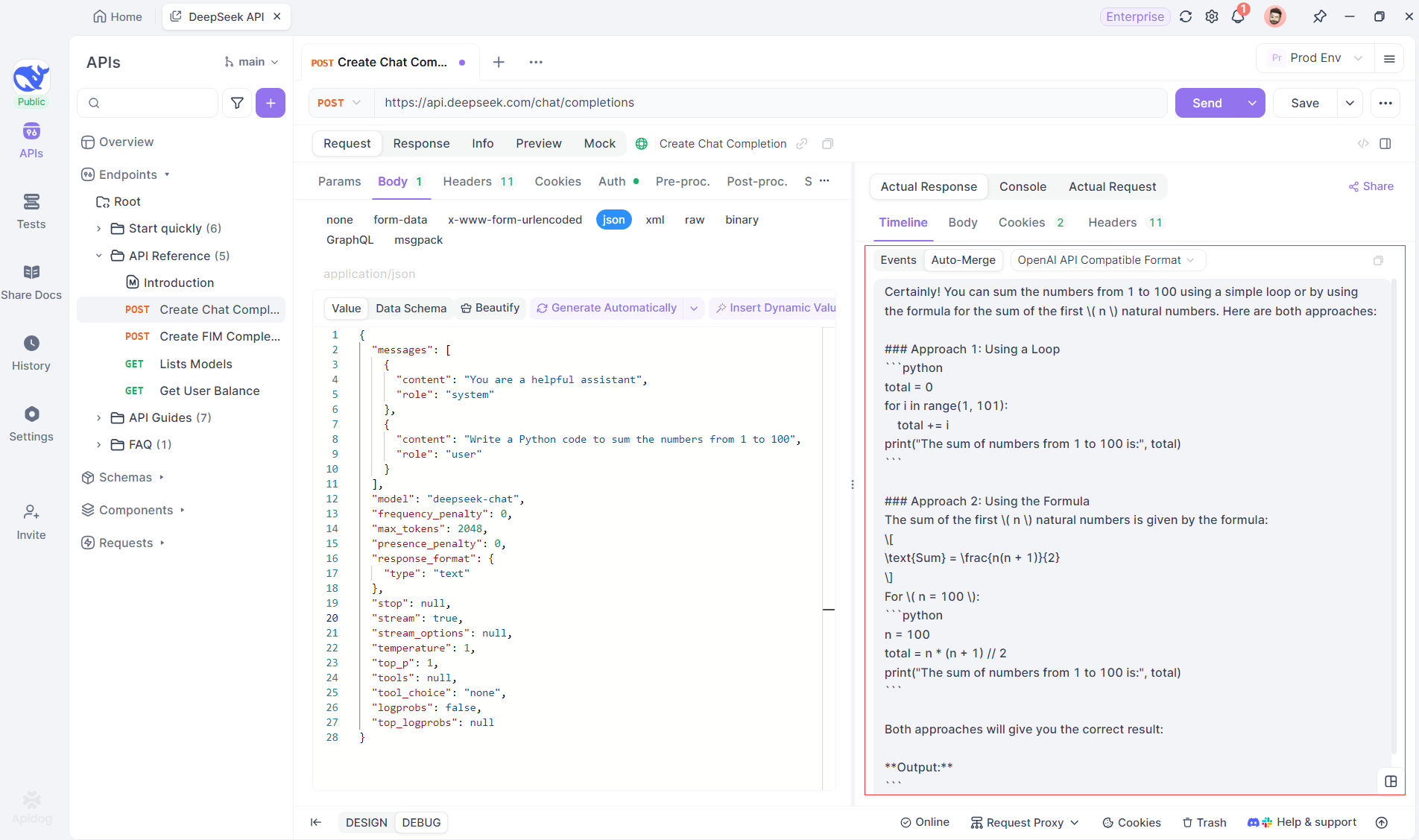
Apidogのオートマージ機能は、OpenAI、Gemini、またはClaudeのようなモデルからの断片的なAI応答を自動的に組み合わせ、手動のデータ処理を排除します。
DeepSeek R1のような推論モデルの場合、ApidogのタイムラインビューはAIの思考プロセスを視覚的にマッピングするため、デバッグや結論形成の理解が容易になります。
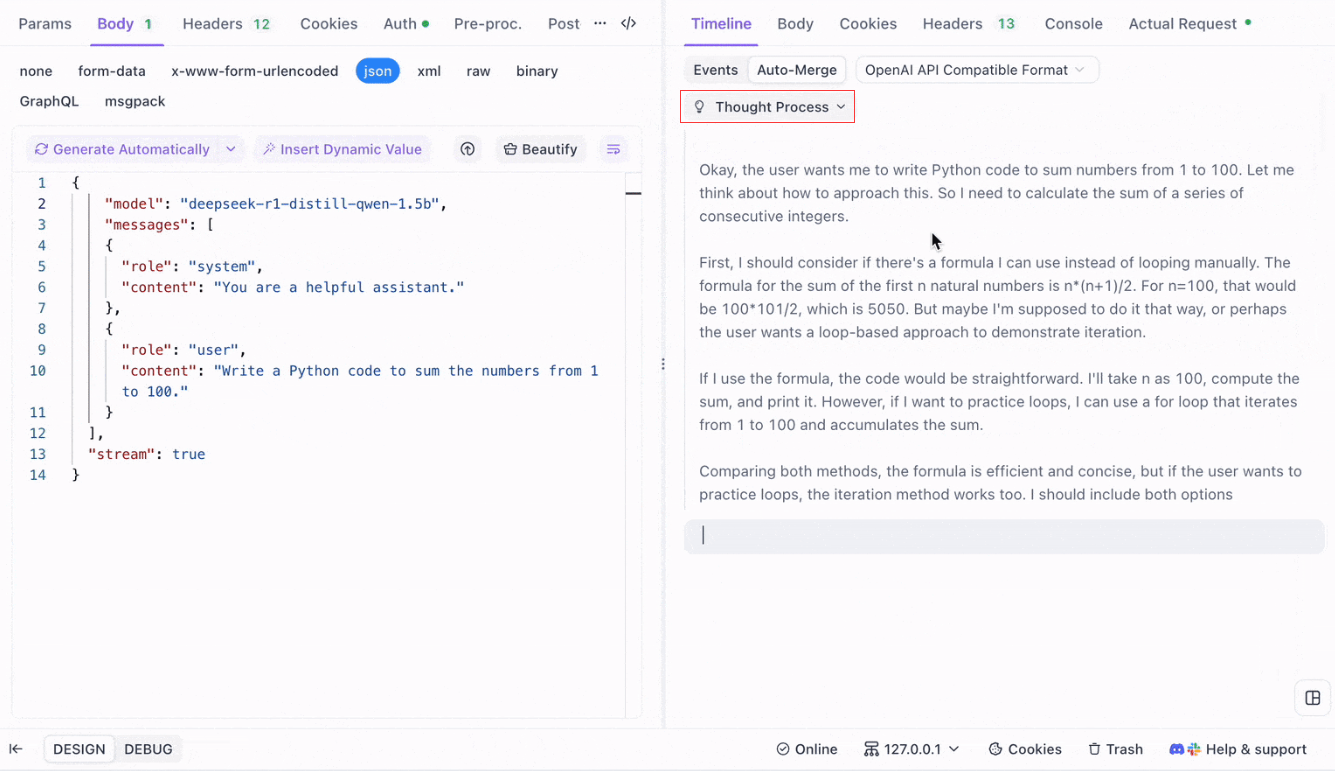
Apidogは次の形式のAI応答をシームレスに認識し、マージします:
- OpenAI APIフォーマット
- Gemini APIフォーマット
- Claude APIフォーマット
応答がこれらの形式に一致すると、Apidogは断片を自動的に結合し、手動での接続を排除し、SSEデバッグをスムーズにします。
結論と次のステップ
今日は多くのことをカバーしました!要約すると、ローカルでLLMを実行するための5つの際立ったツールは以下のとおりです:
- Llama.cpp: 軽量で高速、幅広いハードウェアサポートを備えた高度に効率的なコマンドラインツールを望む開発者に最適です。
- GPT4All: コンシューマグレードのハードウェア上で動作するローカルファーストのエコシステムで、直感的なインターフェースと強力なパフォーマンスを提供します。
- LM Studio: グラフィカルインターフェースを好む方に最適で、モデル管理が容易で広範なカスタマイズオプションを提供します。
- Ollama: マルチモーダル機能を備え、瞬時にモデルをパッケージ化するための「Modelfile」システムを備えた堅牢なコマンドラインツールです。
- Jan: プライバシーを最優先し、完全にオフラインで動作するオープンソースプラットフォームで、さまざまなLLMを統合するための拡張可能なフレームワークを提供します。
これらのツールは、パフォーマンスや使いやすさ、プライバシーなど、ユニークな利点を提供します。プロジェクトの要件に応じて、これらのソリューションの1つがあなたのニーズに最適なフィットとなるかもしれません。ローカルLLMツールの美しさは、データ漏洩、サブスクリプションコスト、ネットワークレイテンシを心配することなく探索と実験を可能にすることです。
ローカルLLMを試行することは学習プロセスであることを忘れないでください。これらのツールを自由に組み合わせ、さまざまな構成をテストし、自分のワークフローに最も合ったものを見つけてください。さらに、これらのモデルを自分のアプリケーションに統合する場合、Apidogのようなツールを使用すると、Server-sent Events(SSE)を使用してLLM APIエンドポイントを管理しテストする際に役立ちます。Apidogを無料でダウンロードして、ローカル開発体験を向上させることを忘れないでください。

次のステップ
- 実験: リストから1つのツールを選び、マシンにセットアップします。異なるモデルや設定で遊んでみて、変更が出力にどのように影響するかを理解しましょう。
- 統合: アプリケーションを開発している場合は、ローカルLLMツールをバックエンドの一部として使用します。これらのツールの多くはAPI互換性(たとえば、LM Studioのローカル推論サーバ)を提供しており、統合をスムーズにします。
- 貢献: これらのプロジェクトのほとんどはオープンソースです。バグを見つけたり、機能が不足していると感じたり、改善のアイデアがある場合は、コミュニティに貢献してみてください。あなたの意見は、これらのツールをさらに良くするのに役立ちます。
- もっと学ぶ: モデルの量子化、最適化手法、プロンプトエンジニアリングなどのトピックを読み進めてLLMの世界を探索し続けます。理解が深まれば、これらのモデルをフルポテンシャルで活用することができます。
これで、プロジェクトに最適なローカルLLMツールを選ぶためのしっかりとした基礎ができたはずです。LLM技術の風景は急速に進化しており、ローカルでモデルを実行することはプライベートでスケーラブル、高性能なAIソリューションを構築するための重要なステップです。
これらのツールを試す中で、無限の可能性があることを発見するでしょう。チャットボット、コードアシスタント、カスタムクリエイティブライティングツールなど、ローカルLLMは必要な柔軟性とパワーを提供できます。旅を楽しみ、コーディングを楽しんでください!


