
急速に進化する人工知能の世界において、リアルタイムで大規模言語モデル(LLM)からの応答をストリーミングする能力は、ユーザーインタラクションを高め、全体的なアプリケーションパフォーマンスを改善するために不可欠です。これを達成するための最良の方法の一つが、サーバー送信イベント(SSE)を介することです。SSEは、サーバーとクライアントの間に一方向の通信チャネルを提供するHTTPプロトコルに基づいた堅牢な技術です。この記事では、SSEがどのように機能するか、LLMの応答をストリーミングするためにどのように使用できるか、また、Apidogのようなツールがどのようにデバッグを簡素化し、開発効率を改善できるかについて掘り下げます。
サーバー送信イベント(SSE)とは?
サーバー送信イベントは、HTTPプロトコルに基づく軽量なリアルタイム通信技術です。SSEを使用すると、サーバーはクライアントへの連続した一方向の接続を確立します。サーバーは、クライアントが新しいデータを繰り返し要求する必要なく、クライアントに更新をプッシュします。これにより、SSEはリアルタイムの更新、ライブ通知、そしてAIモデルの場合にはLLMからの継続的な応答などの動的コンテンツのストリーミングに理想的です。
SSEの美しさは、そのシンプルさと低オーバーヘッドにあります。WebSocketsとは異なり、双方向通信を可能にするWebSocketsとは異なり、SSEはサーバーがクライアントにデータを継続的にプッシュする必要がある状況に設計されています。これは、AI生成コンテンツをリアルタイムでストリーミングする際に特に便利で、クライアントはモデルが応答の各部分を生成する際にその思考過程を目の当たりにすることができます。
LLMストリーミングにおけるSSEの仕組み
LLMを使用する際、特にDeepSeek R1のような複雑なモデルでは、応答はしばしば断片的に到着します。SSEを使用すると、これらの各断片はストリーム内で個別の「イベント」として送信されます。これにより、開発者やエンドユーザーはリアルタイムで全体のプロセスを目の当たりにすることができます。サーバーが各イベントを送信する際、クライアントは即座に更新され、ユーザーは利用可能な最新情報を受け取ることができます。
AIモデル応答にSSEを使用する利点
- リアルタイムデータ配信:SSEは、生成されると同時にクライアントが更新を即座に受け取ることを可能にし、遅延がありません。
- 効率的な通信:サーバーは新しいイベントが発生したときのみデータを送信し、不必要なリクエストを削減し、システムの効率を改善します。
- 簡素化されたクライアントサイドの実装:SSEを使用すれば、クライアントは継続的なデータ更新を処理するための複雑なロジックを必要とせず、自動的に受信して表示されます。
ApidogでのSSEデバッグの設定
SSEデバッグを使用するには、Apidogを使用していることを確認し、バージョン2.6.49以上にする必要があります。Apidogは、APIを扱うためのユーザーフレンドリーなプラットフォームを提供し、DeepSeek R1のようなLLMからのリアルタイムデータストリームのSSE接続とデバッグを簡素化します。
ステップ1:Apidogで新しいAPIを作成する
まず、新しいHTTPプロジェクトを作成します。これにより、APIリクエストのテストとデバッグのためのワークスペースを設定できます。プロジェクトが設定されたら、AIモデルのURLを入力して新しいAPIを追加します。これがSSEストリームの発信元になります。この例では、DeepSeekをAIモデルとして使用します。(プロのヒント:ApidogのAPIハブで用意されているDeepSeek APIプロジェクトをクローンできます)。
ステップ2:リクエストを送信する
APIを追加したら、右上の送信をクリックしてサーバーにリクエストを送信します。サーバーのレスポンスヘッダーにContent-Type: text/event-streamが含まれている場合、Apidogは自動的にデータがSSEを介してストリーミングされていることを認識します。Apidogのインテリジェントなシステムはこの応答を解析し、応答パネルに表示します。これにより、生成されているリアルタイムのストリームを確認できます。
ステップ3:リアルタイムの応答を表示する
Apidogのタイムラインビューが魔法の場所です。AIモデルが応答をストリーミングする際、タイムラインビューは動的に更新され、応答の各断片をリアルタイムで表示します。このビューにより、AIの思考過程の進化を追跡でき、最終出力がどのように生成されるかについて貴重な洞察を得ることができます。
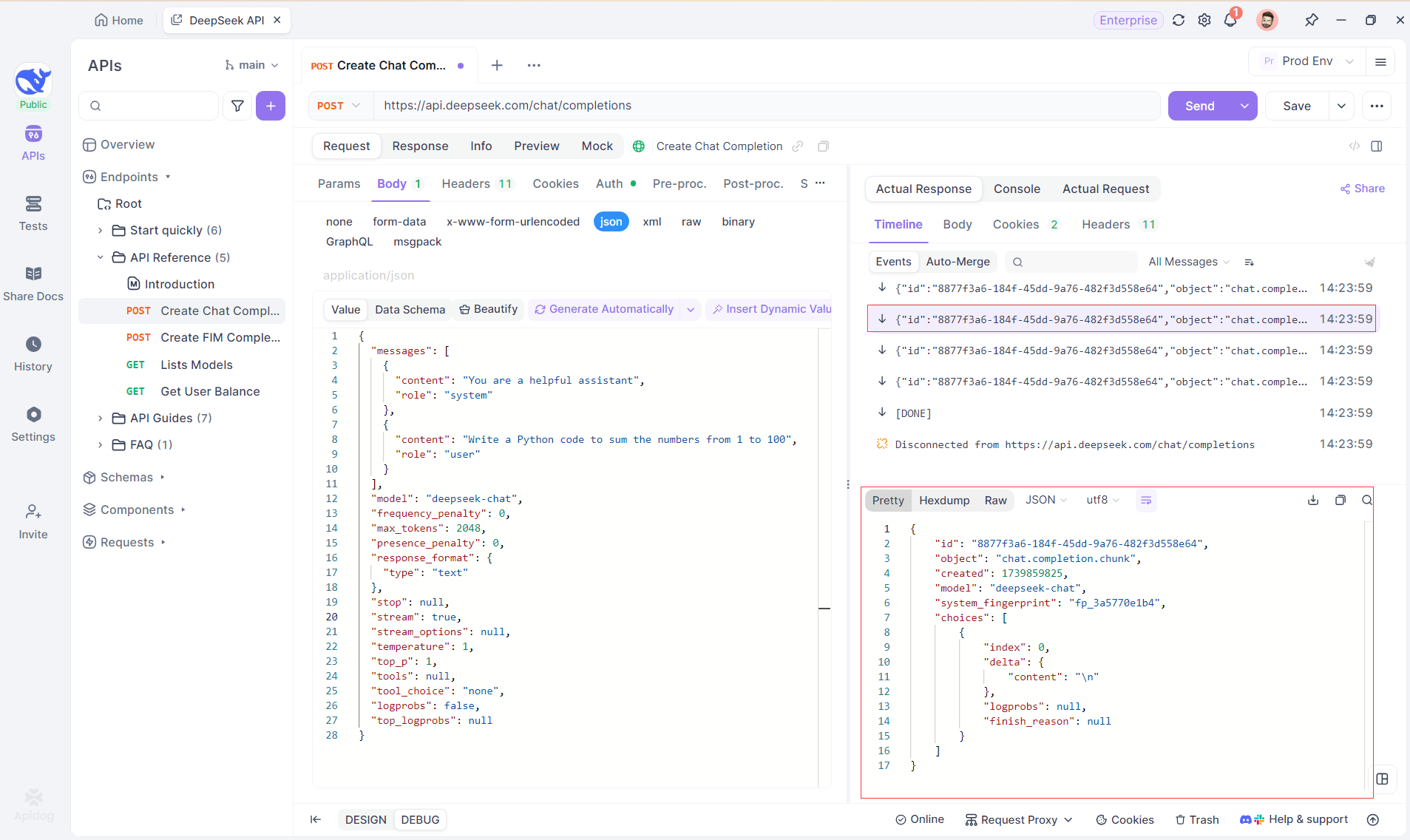
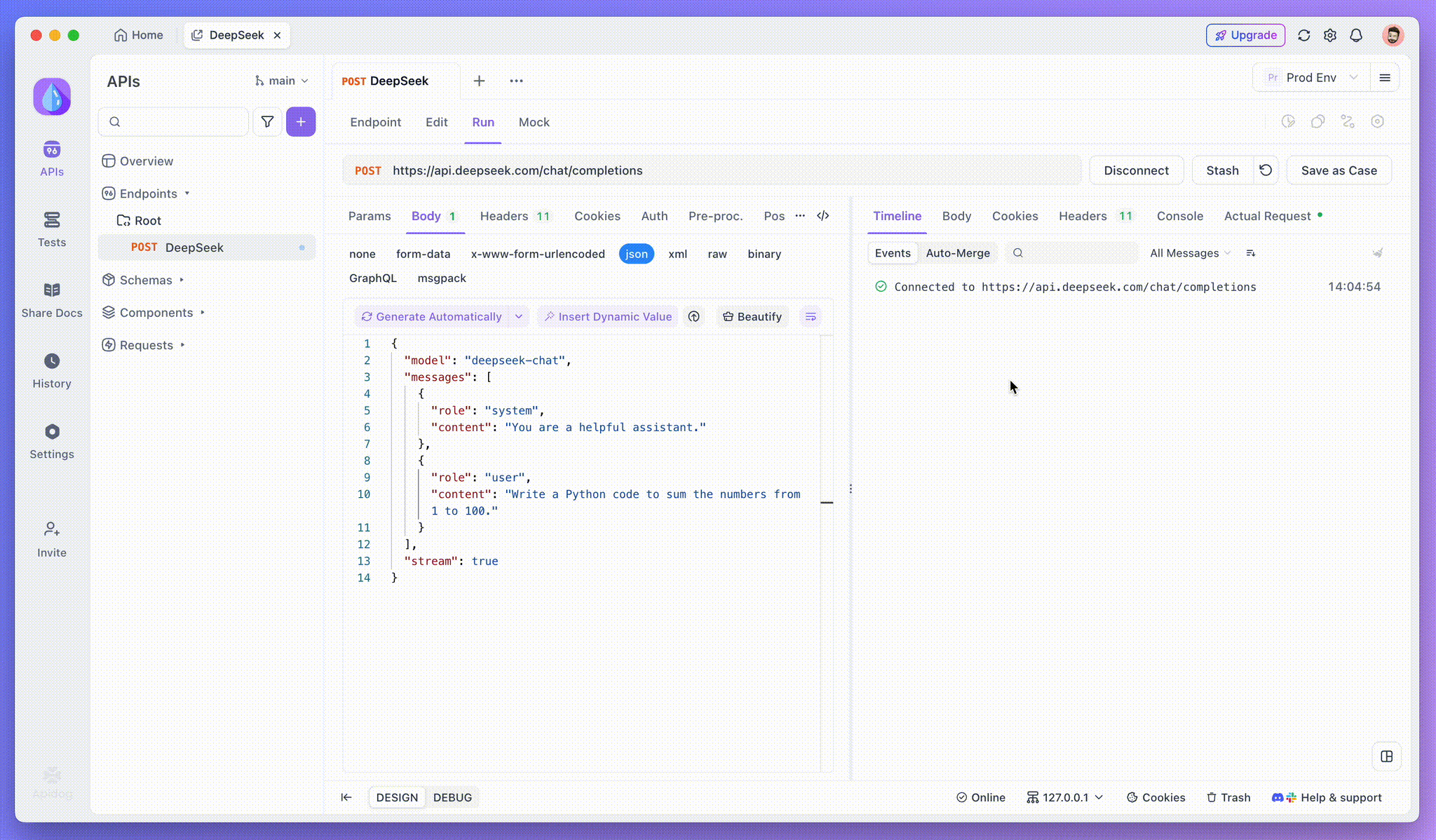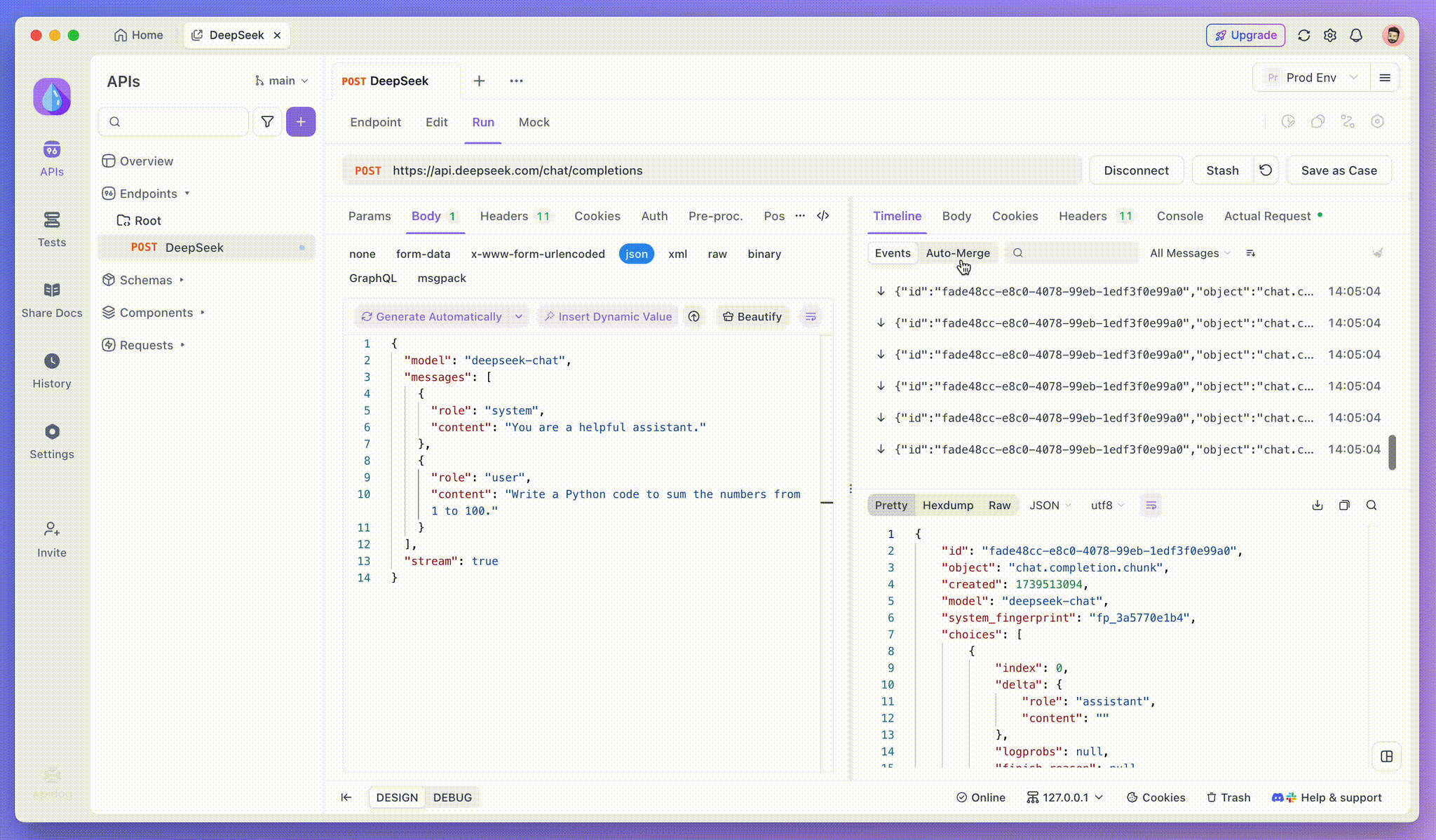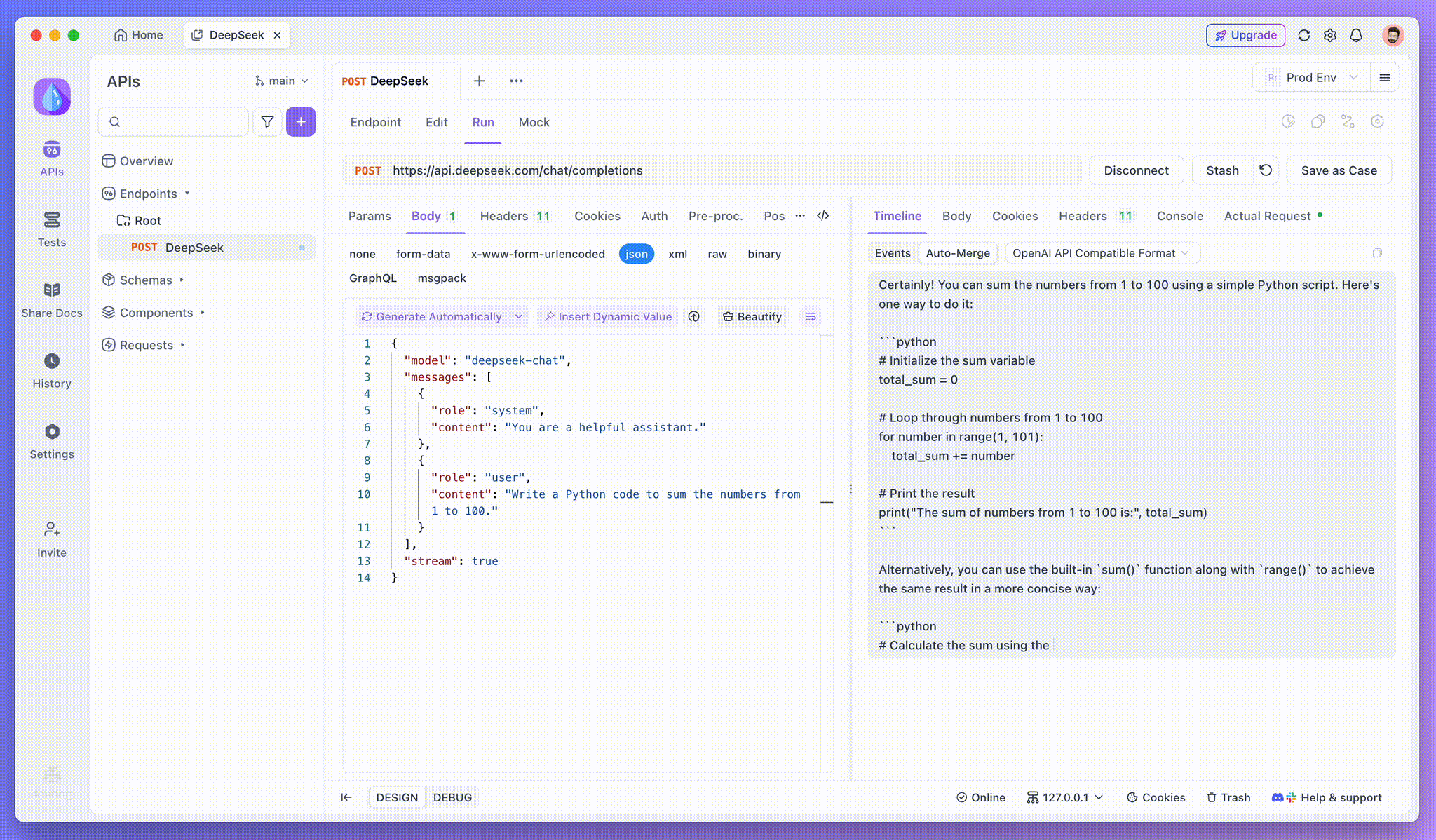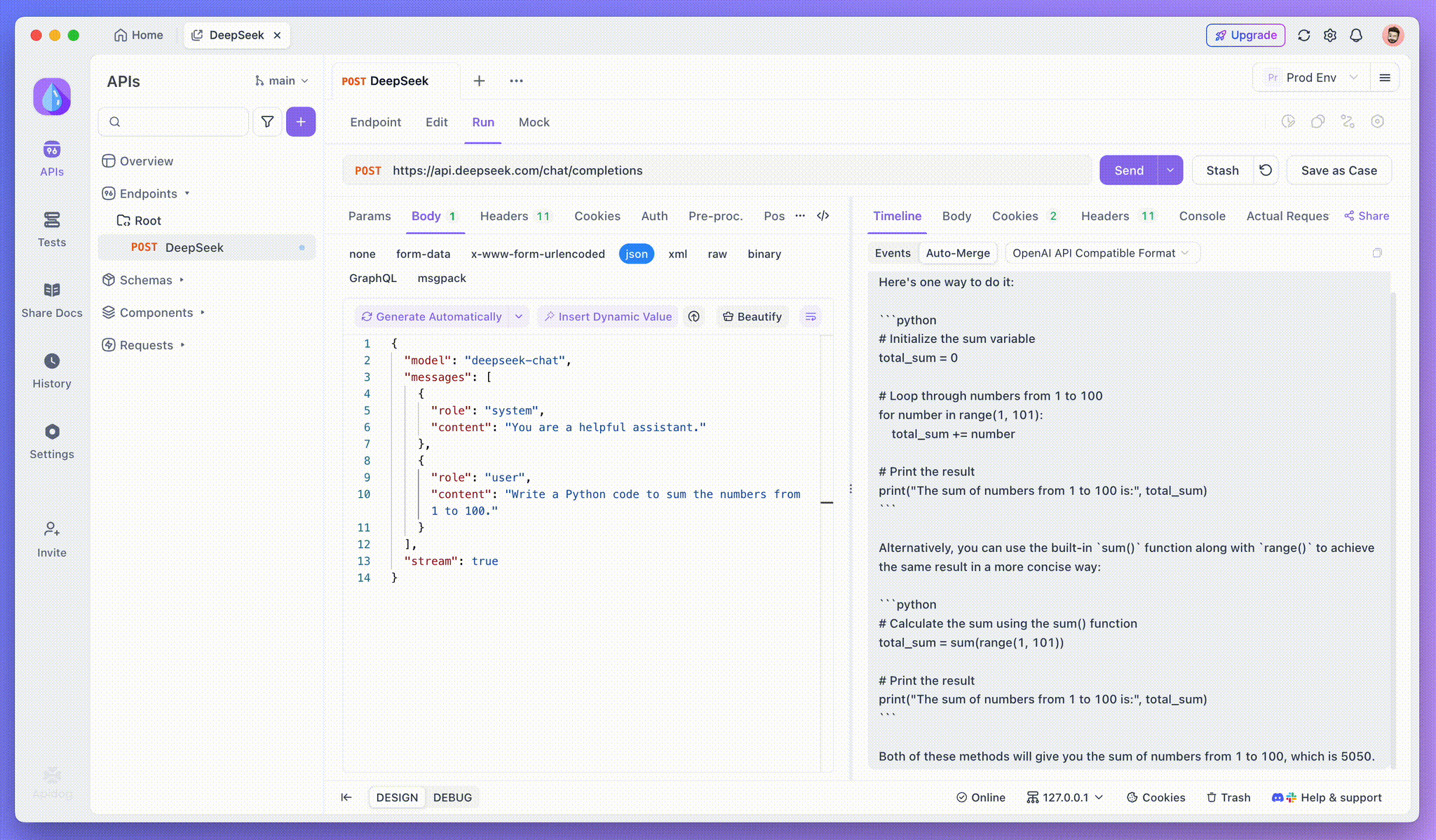
ステップ4:完全な応答内でのSSE応答を表示する
SSEはデータをストリーミングする強力な方法を提供しますが、断片的な応答を処理するためには追加の処理が必要なことがよくあります。Apidogの自動マージ機能は、この課題に対処するために設計されています。AI応答をストリーミングするとき、データはしばしば複数の断片で到着し、特にOpenAI、Gemini、またはClaudeのようなモデルではそうです。Apidogはこれらの断片を自動的に統合し、一つの完全な応答にします。
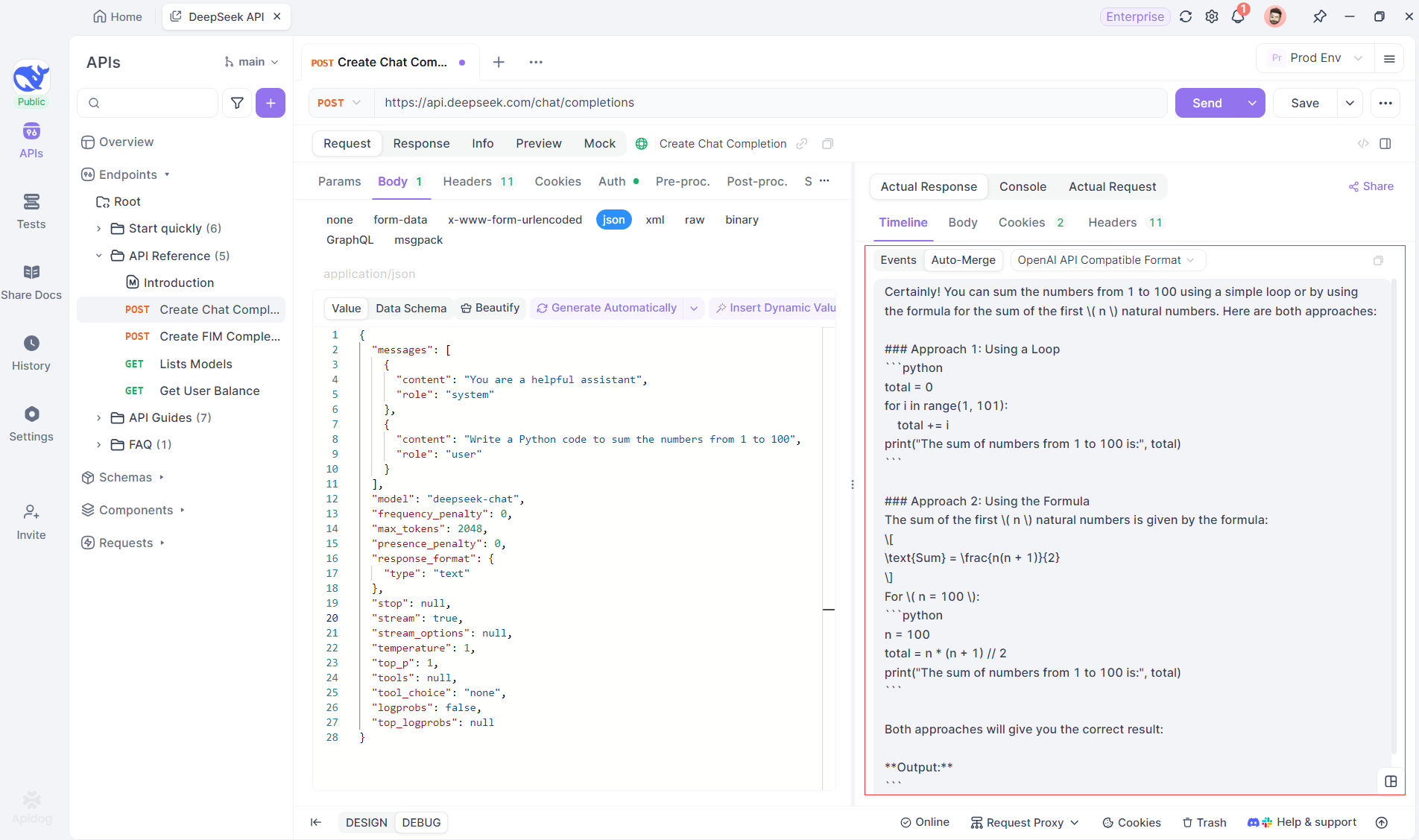
この機能により、手動でデータを処理する必要がなくなり、開発者は断片的なメッセージのマージに関わる複雑さではなく、AIの出力を分析することに集中できます。
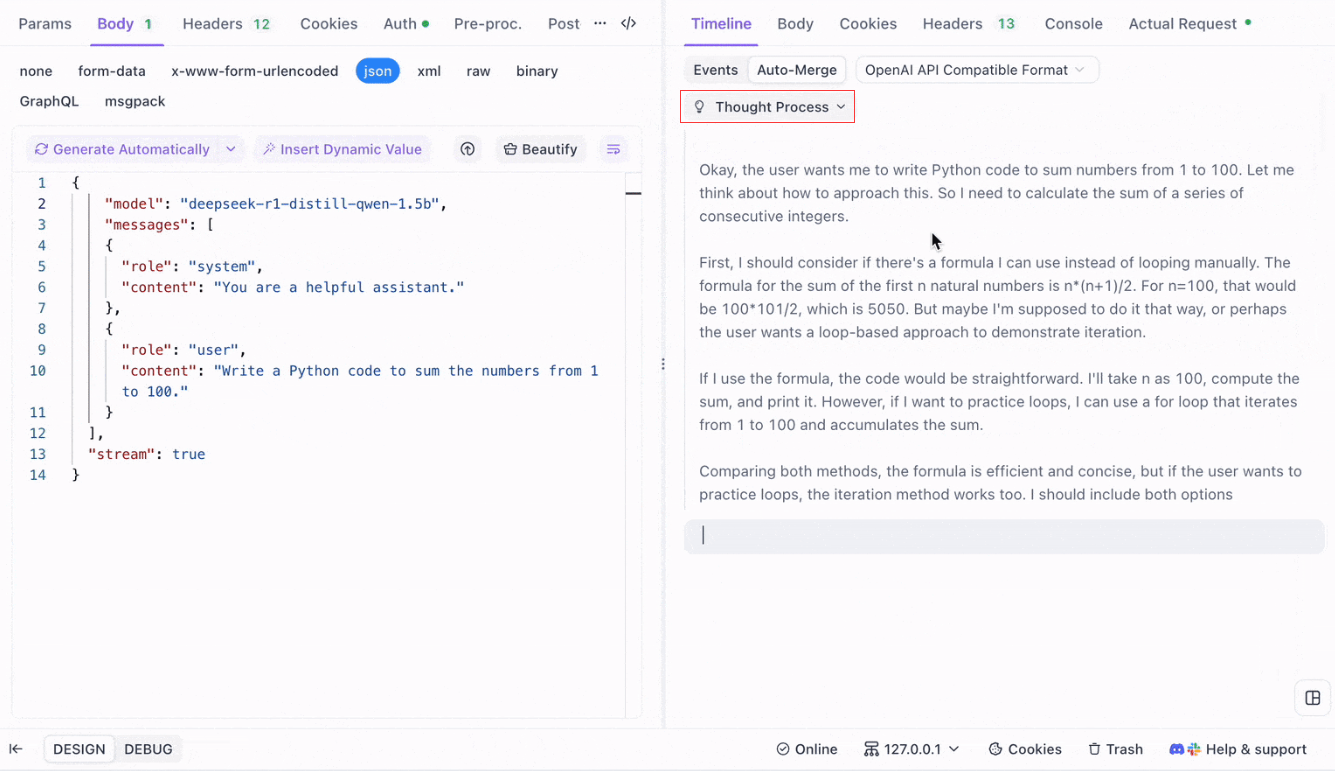
推論モデルの思考過程の視覚化:推論モデルの一つであるDeepSeek R1を使用する際の際立った機能は、Apidogがモデルの思考過程をタイムラインビューに直接表示できることです。
AIが応答を生成する際、Apidogは応答データを示すだけでなく、モデルが結論に至るまでの過程を視覚的に表現します。これにより、AIの応答の背後にある推論を理解しやすくデバッグを容易にする直感的な方法が提供されます。
自動マージのためのサポートフォーマット
Apidogは、いくつかの人気のあるAIモデルフォーマットからの応答を自動的に認識してマージできます:
- OpenAI APIフォーマット
- Gemini APIフォーマット
- Claude APIフォーマット
AIモデルからの応答がこれらのフォーマットのいずれかに一致する場合、Apidogは断片を一つの完全な応答にシームレスにマージします。これにより、開発者は断片を手動で縫い合わせる必要がなく、SSE応答のデバッグがより効率的になります。
LLMデバッグに自動マージを使用する理由
- 時間の効率:開発者は応答断片を手動でマージする退屈な作業を避けられます。
- デバッグの改善:統一された完全な応答により、AIの挙動をより明確に分析できます。
- 洞察の強化:モデルの思考過程を視覚化することで、特にDeepSeek R1のような複雑なモデルについて、理解が一層深まります。
ApidogにおけるSSEデバッグルールのカスタマイズ
場合によっては、組み込みの自動マージ機能が期待通りに機能しないことがあります。特にカスタムAIモデルや非標準フォーマットを扱う場合です。Apidogでは、JSONPath抽出ルールやポストプロセッサスクリプトを使用して応答の処理方法をカスタマイズできます。
JSONPath抽出ルールの設定
SSE応答がJSON形式であっても、OpenAI、Claude、またはGeminiのようなフォーマットのための組み込み認識ルールに準拠していない場合、必要なコンテンツを抽出するためにJSONPathを設定できます。
例えば、以下の生SSE応答を考えてみましょう:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}message.contentフィールドの内容を抽出するには、以下のようにJSONPathを設定します: $.choices[0].message.content
この設定により、次の内容が取得されます: Hi
JSONPathを使用することで、Apidogが応答を処理する方法をカスタマイズし、正しいデータを常に抽出できるようにします。
非JSON SSE用のポストプロセッサスクリプトの使用
非JSON応答の場合、Apidogはポストプロセッサスクリプトを使用してSSEストリームからデータを操作および抽出する能力を提供します。これにより、従来のJSON構造に準拠しない特定のデータフォーマットを処理するためのカスタムスクリプトを書くことができます。
サポートされていないモデルフォーマットを扱っている場合、Apidogの技術サポートに連絡してフォーマットを追加してもらうことができます。
SSEを使用したLLM応答のストリーミングに関するベストプラクティス
SSEを使用してLLM応答をストリーミングするときは、スムーズで効率的なデバッグを確保するためにいくつかのベストプラクティスを留意してください:
- 断片化を優雅に処理する:AIモデルの応答が複数の断片で到着することを常に予測し、
自動マージ機能を使用してこのプロセスを合理化します。 - 異なるAIモデルでテストする:OpenAI、Gemini、DeepSeek R1などのモデルを使用して、さまざまなフォーマットの挙動を探求し、セットアップが複数の応答タイプに対応できることを確認します。
- デバッグにタイムラインビューを使用する:Apidogのタイムラインビューを活用して、特に複雑なAIモデルに対して、応答がどのように進化するかのリアルタイムの段階的内訳を取得します。
- 非標準フォーマットにカスタマイズする:必要に応じて、JSONPathまたはポストプロセッサスクリプトを使用して非標準SSEフォーマットを処理したり、データ抽出プロセスを微調整したりします。
結論:SSEによるLLMストリーミングの強化
サーバー送信イベントは、特に大規模で複雑なLLMを扱う際に、AIモデルからのリアルタイム応答をストリーミングするための強力なメカニズムを提供します。ApidogのSSEデバッグツールを使用することで、自動マージ機能や向上した視覚化を含め、開発者は断片的な応答の処理を簡素化し、モデルの挙動に対するより深い洞察を得ることができます。OpenAIのような一般的なモデルからの応答をデバッグする場合や、カスタムAIソリューションで作業する場合でも、ApidogはSSEデータを効果的かつ洞察に満ちた方法で簡単に追跡、マージ、および分析できることを保証します。


