
PDFや技術マニュアルに直接質問できることを望んだことがあるなら、このガイドはあなたのためのものです。今日は、DeepSeek R1というオープンソースの推論パワーハウスと、ローカルAIモデルを実行するための軽量フレームワークであるOllamaを使用して、リトリーバル強化生成 (RAG)システムを構築します。
APIテストを強化する準備はできましたか?Apidogをチェックするのを忘れないでください!Apidogは、テストやモックサーバーの作成、管理、実行のためのワンストッププラットフォームとして機能し、ボトルネックを特定し、APIを信頼性の高いものに保ちます。
複数のツールを使いこなしたり、膨大なスクリプトを書く代わりに、ワークフローの重要な部分を自動化し、スムーズなCI/CDパイプラインを実現し、製品の機能を磨くためにより多くの時間を費やすことができます。
それがあなたの生活を簡素化するものであれば、Apidogを試してみてください!
この投稿では、DeepSeek R1(OpenAIのo1にパフォーマンスで匹敵しながらコストは95%少ないモデル)がどのようにRAGシステムを強化できるかを探ります。なぜ開発者たちがこの技術に集まっているのか、そしてあなたがどのようにして独自のRAGパイプラインを構築できるのかを解説します。
このローカルRAGシステムのコストはいくらですか?
| コンポーネント | コスト |
|---|---|
| DeepSeek R1 1.5B | 無料 |
| Ollama | 無料 |
| 16GB RAM PC | $0 |
DeepSeek R1の1.5Bモデルは、以下の理由で優れた性能を発揮します。
- フォーカスされたリトリーバル: 各回答に対して3つのドキュメントチャンクのみを使用
- 厳格なプロンプティング: “わかりません”は幻覚を防止
- ローカル実行: クラウドAPIと比較してゼロレイテンシ
必要なもの
コーディングを始める前に、ツールキットをセットアップしましょう:
1. Ollama
Ollamaを使用すると、DeepSeek R1のモデルをローカルで実行できます。
- ダウンロード: https://ollama.com/
- インストールしたら、ターミナルを開いて以下を実行します:
ollama run deepseek-r1 # 7Bモデルの場合(デフォルト)
2. DeepSeek R1モデルバリアント
DeepSeek R1は、1.5Bから671Bのパラメータサイズで提供されています。このデモでは、軽量RAGに最適な1.5Bモデルを使用します:
ollama run deepseek-r1:1.5b
プロのヒント:より大きなモデル(70Bなど)はより良い推論を提供しますが、より多くのRAMを必要とします。小さいモデルから始めて、徐々にスケールアップしましょう!

RAGパイプラインの構築:コードウォークスルー
ステップ1:ライブラリをインポート
以下のライブラリを使用します:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
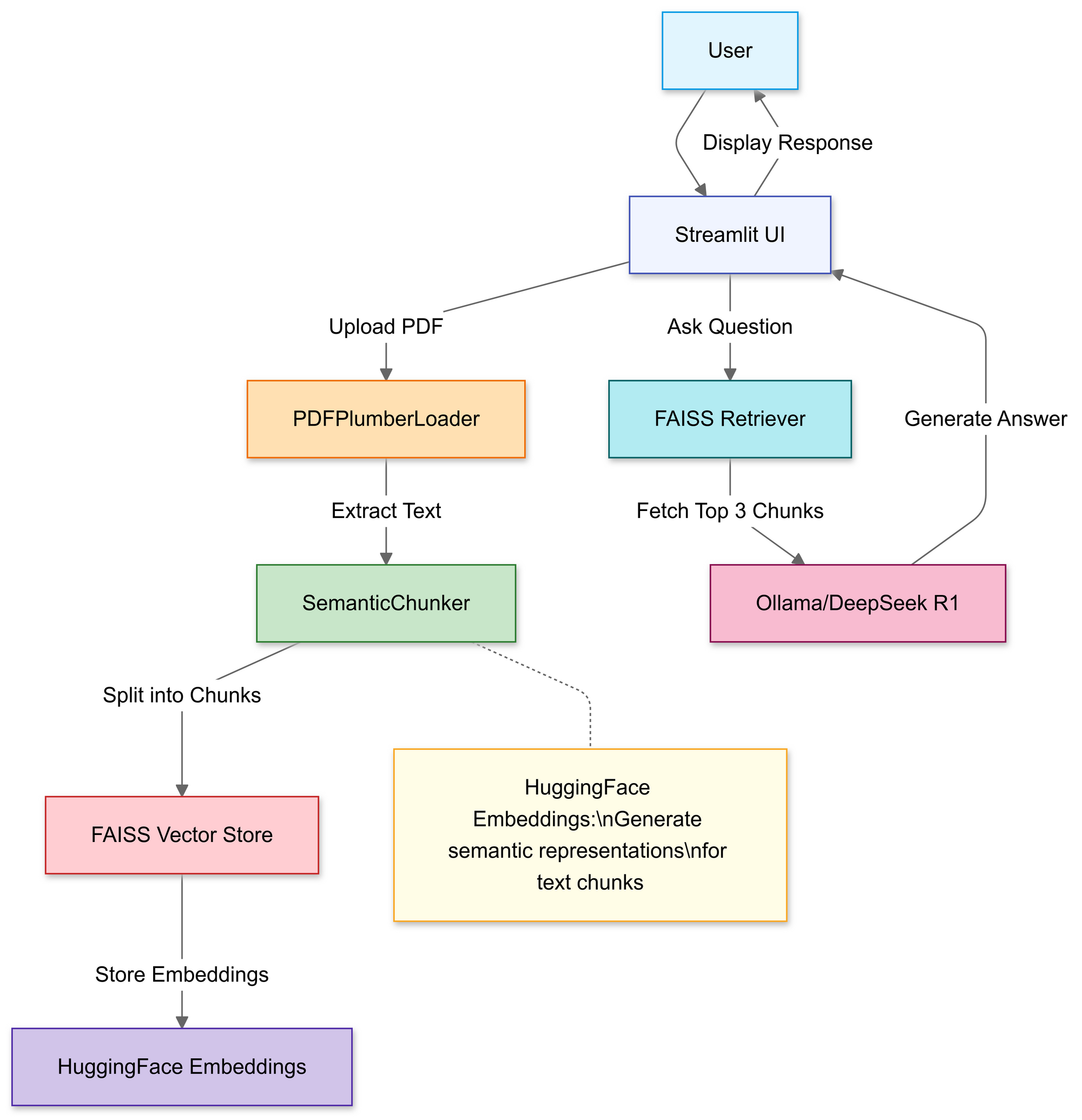
ステップ2:PDFをアップロードして処理
このセクションでは、Streamlitのファイルアップローダーを使用して、ユーザーがローカルのPDFファイルを選択できるようにします。
# Streamlitファイルアップローダー
uploaded_file = st.file_uploader("PDFファイルをアップロード", type="pdf")
if uploaded_file:
# PDFを一時保存
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# PDFテキストを読み込む
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
アップロードされると、PDFPlumberLoader関数がPDFからテキストを抽出し、パイプラインの次のステージの準備をします。このアプローチは、ファイル内容を読み取るための手間のかからない手段を提供します。
ステップ3:ドキュメントを戦略的にチャンク化
RecursiveCharacterTextSplitterを使用して、元のPDFテキストを小さなセグメント(チャンク)に分割します。良いチャンク化と悪いチャンク化の概念を説明しましょう:
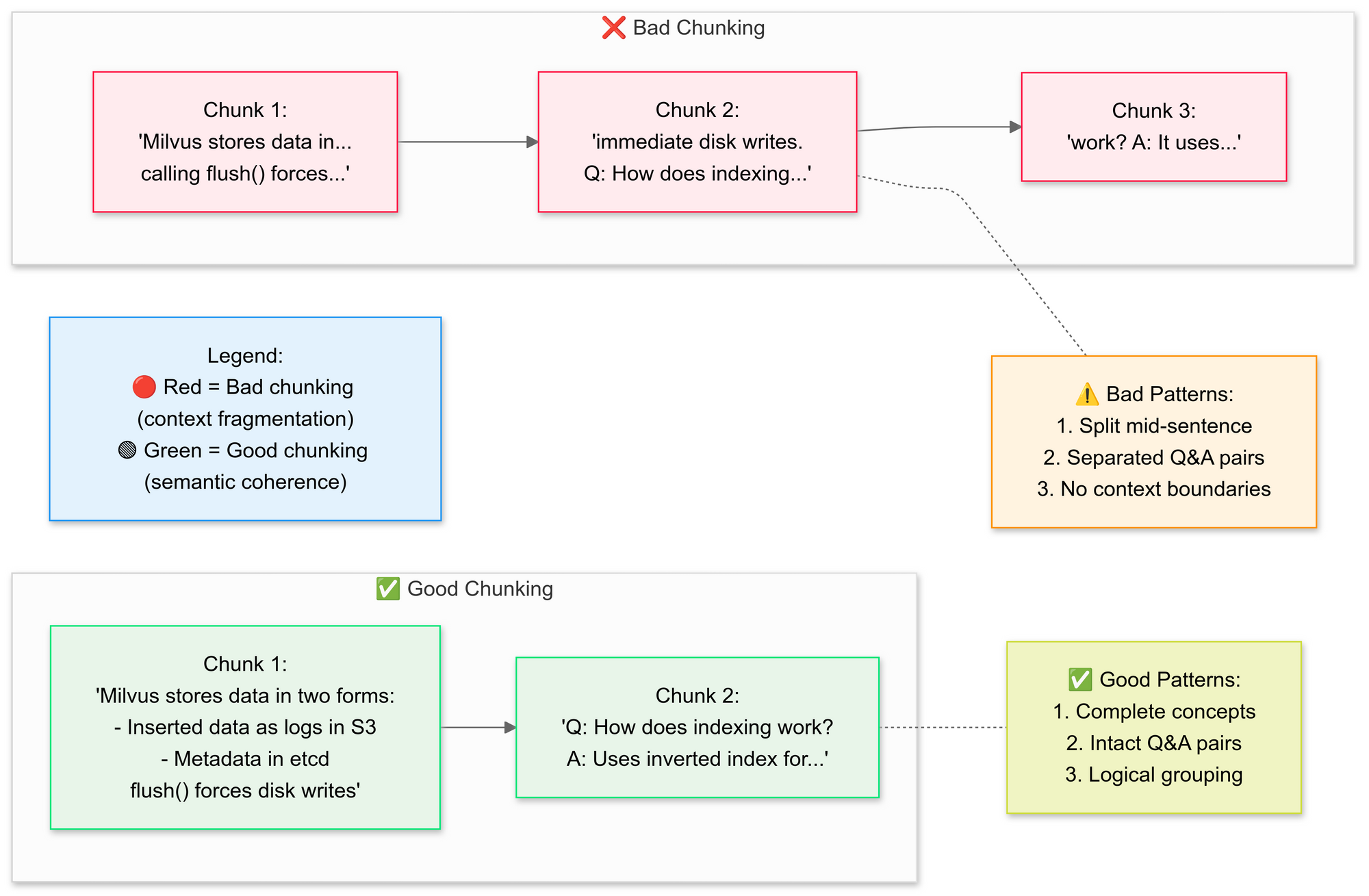
なぜセマンティックチャンク化なのか?
- 関連する文をグループ化(例:"Milvusがデータを保存する方法"がそのまま保持される)
- テーブルや図を分割しない
# テキストをセマンティックチャンクに分割
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
このステップは、コンテキストをわずかに重複させたセグメントを保存し、言語モデルが質問により正確に回答できるようにします。小さくて明確に定義されたドキュメントチャンクは、検索をより効率的かつ関連性の高いものにします。
ステップ4:検索可能な知識ベースを作成
分割後、パイプラインはセグメントのベクトル埋め込みを生成し、FAISSインデックスに保存します。
# 埋め込みを生成
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# リトリーバーを接続
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 上位3つのチャンクを取得
これにより、テキストが数値表現に変換され、クエリの実行がはるかに容易になります。その後、このインデックスに対するクエリが実行され、最もコンテキストに関連するチャンクが見つかります。
ステップ5:DeepSeek R1を設定
ここでは、Deepseek R1 1.5BをローカルLLMとして使用して、RetrievalQAチェーンをインスタンス化します。
llm = Ollama(model="deepseek-r1:1.5b") # 当社の1.5Bパラメータモデル
# プロンプトテンプレートを作成
prompt = """
1. 以下のコンテキストのみに基づいてください。
2. 不明な場合は「わかりません」と言ってください。
3. 回答は4文以内にしてください。
コンテキスト: {context}
質問: {question}
回答:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
このテンプレートは、モデルがPDFの内容に基づいて回答を行うことを強制します。FAISSインデックスに結びついたリトリーバーで言語モデルをラップすることにより、チェーンを通じて行われたクエリはPDFの内容からコンテキストを探し出し、回答をその出典資料に基づいたものにします。
ステップ6:RAGチェーンを組み立てる
次に、アップロード、チャンク化、リトリーバルのステップを結合して、首尾一貫したパイプラインにすることができます。
# チェーン1:回答を生成
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# チェーン2:ドキュメントチャンクを結合
document_prompt = PromptTemplate(
template="コンテキスト:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# 最終RAGパイプライン
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
これはRAG(リトリーバル強化生成)デザインの中核であり、大規模言語モデルに確認されたコンテキストを提供し、内部のトレーニングのみに依存させないようにします。
ステップ7:ウェブインターフェースを起動
最後に、コードはStreamlitのテキスト入力と書き込み機能を使用して、ユーザーが質問を入力し、すぐに回答を表示できるようにします。
# Streamlit UI
user_input = st.text_input("PDFに質問してください:")
if user_input:
with st.spinner("考え中..."):
response = qa(user_input)["result"]
st.write(response)
ユーザーがクエリを入力すると、チェーンは最も一致するチャンクを取得し、それを言語モデルに供給して、回答を表示します。langchainライブラリが正しくインストールされていれば、今すぐコードが機能し、「モジュールが見つかりません」エラーを引き起こさずに済みます。
質問をして提出し、即座に回答を得ましょう!
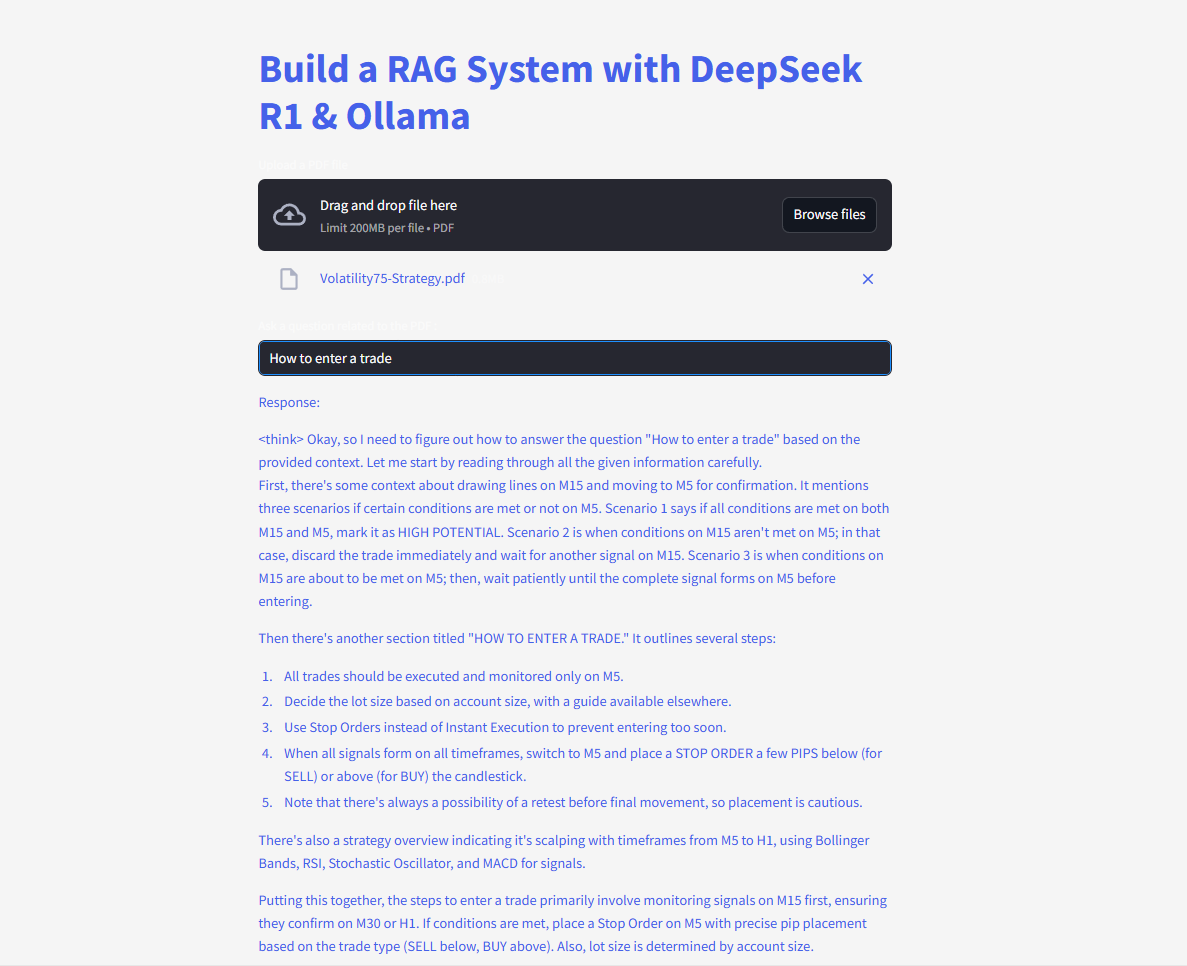
完全なコードは以下の通りです:
DeepSeekとのRAGの未来
自己検証やマルチホップ推論のような機能が開発中のDeepSeek R1は、さらに高度なRAGアプリケーションを解放する準備が整っています。質問に答えるだけでなく、自らの論理を議論するAIを想像してみてください—自律的に。


