
2025年8月、Qwenチームが最新の「Qwen3-2507」シリーズをリリースしました。8月6日に4Bモデルが最終リリースされ、8月8日には100万トークンの超長入力対応が発表されています。235Bパラメータの旗艦MoEモデルに、思考モードと指令モードの完全分離、さらに256Kの超長コンテキストウィンドウ(最大100万トークンまで拡張可能)を搭載し、ローカルAI環境に新たな可能性をもたらしています。
本記事では、LMStudioを使ってQwen3-2507をローカル環境で動かす方法を解説します。クラウドAPIも便利ですが、ローカル実行にはプライバシー保護、コスト削減、オフライン利用可能といった明確なメリットがあります。
Qwen3-2507って何がすごいの?
Qwen3-2507は2025年8月にリリースされた最新世代のLLMで、前バージョンから革命的な進化を遂げています。特に注目すべきは、Mixture-of-Experts(MoE)アーキテクチャの最適化と、思考モード・指令モードの完全分離です。
 QwenLM
QwenLMQwen3-2507の主要モデルラインナップ
今回の2507アップデートで登場したモデル(2025年8月):
| モデル名 | 総パラメータ | 活性パラメータ | モード | 特徴 |
|---|---|---|---|---|
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 指令 | 強力な指示対応・多言語能力 |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 思考 | 複雑な推論・Agent能力 |
| Qwen3-30B-A3B-Instruct-2507 | 30B | 3B | 指令 | 高効率・256Kコンテキスト |
| Qwen3-30B-A3B-Thinking-2507 | 30B | 3B | 思考 | 高効率推論モード |
| Qwen3-4B-Instruct-2507 | 4B | 4B | 指令 | 軽量・高速応答 |
| Qwen3-4B-Thinking-2507 | 4B | 4B | 思考 | 軽量推論モード |
Qwen3ファミリーの他のモデル(別途リリース済み):
- Qwen3-Coderシリーズ:コーディング専用モデル(480B-A35B、30B-A3Bなど)
- 密モデル:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-7B など
全部Apache 2.0ライセンスでオープンソース化されているのがすごいですよね!
Qwen3-2507の革新的な技術特徴
思考モード(Thinking)と指令モード(Instruct)の完全分離
- Thinking-2507:複雑な問題に対して段階的に推論を行い、Chain-of-Thoughtで深く考えた上で回答。数学的証明やコード設計など、論理的思考が必要なタスクに最適
- Instruct-2507:シンプルな質問に対して即座に回答。日常的な質問応答や翻訳、要約などの高速処理に特化
複雑なアルゴリズム設計には「Thinking」モード、簡単なコード補完には「Instruct」モードというように、タスクに応じた使い分けが可能です。
256K超長コンテキストウィンドウ(最大100万トークンまで拡張可能)
前バージョンから大幅に拡張され、2025年8月8日のアップデートで100万トークンの超長入力に対応。長文ドキュメントの解析や大規模コードベース全体の理解が可能に。実質的に小説数冊分のテキストを一度に処理できます。
多言語サポートの強化
119言語・方言をサポートし、日本語の精度もさらに向上。ローカライゼーションタスクにも対応。
Agent機能とツール連携の進化
外部ツールとの統合能力が大幅に強化され、複雑なタスクの自動化やワークフロー構築が可能に。
トレーニングデータの大規模化と品質向上
- 指示追従、論理的推論、テキスト理解、数学、科学、コーディング、ツール使用など、全般的な能力が大幅に向上
- 多言語でのロングテール知識カバレッジが大幅に拡大
- ユーザーの好みとの整合性が向上し、より有用な応答と高品質なテキスト生成を実現
Qwen3-2507のパフォーマンスと効率性
MoEアーキテクチャの驚異的な効率:
Qwen3-2507シリーズの最大の特徴は、MoE(Mixture-of-Experts)による効率化です:
- Qwen3-235B-A22B-2507:235Bの総パラメータを持ちながら、推論時には22B(約9.4%)のみを活性化。これにより、メモリ使用量を大幅に削減しながら、大規模密モデルに匹敵する性能を実現
- Qwen3-30B-A3B-2507:わずか3Bの活性パラメータで、従来の14B~32B密モデルと同等の性能。22~24GBのVRAMで動作可能
コーディングタスクでの大幅な性能向上:
Qwen3-2507シリーズは、コーディング能力も大幅に強化されています:
- 複雑なアルゴリズム実装、バグ修正、コードリファクタリングなど、実践的なコーディングタスクで優れた結果
- ツール使用能力の向上により、開発ワークフローとの統合がより容易に
補足:Qwen3-Coderシリーズについて
コーディングに特化したい場合は、別途リリースされているQwen3-Coderシリーズ(480B-A35B、30B-A3Bなど)も利用可能です。HumanEval、MBPP、LiveCodeBenchなどの主要コーディングベンチマークで最高クラスのスコアを記録しています。
推論・数学タスクでの進化:
Thinking-2507モデルは、MATH、GSM8K、AIMEなどの数学ベンチマークで前世代から大幅に向上。Chain-of-Thought推論により、複雑な問題解決能力が飛躍的に改善されました。
実用的なメリット:
- 推論コストの削減:活性パラメータが少ないため、推論速度が速く、電力消費も少ない
- ローカル実行の現実性:30B-A3Bモデルなら、一般的なゲーミングPC(RTX 4090など)でも快適に動作
- 長文処理能力:256Kコンテキストにより、大規模ドキュメントやコードベース全体の解析が可能
LMStudioでQwen3-2507を動かす方法
LMStudioは、LLMをローカルで簡単に動かせるツールで、複雑な設定なしでモデルを管理・実行できます。Qwen3-2507シリーズにも完全対応しており、コマンドラインツールとAPIサーバーも提供しているため、開発者にとって使いやすい環境が整っています。
インストールと設定
まず、LMStudioをインストールして、少なくとも一度は起動しておく必要があります。その後、コマンドラインツール「lms」をブートストラップします。
macOSやLinuxの場合:
~/.lmstudio/bin/lms bootstrap
Windowsの場合:
cmd /c %USERPROFILE%/.lmstudio/bin/lms.exe bootstrap
インストールを確認するには、新しいターミナルウィンドウを開いてlmsコマンドを実行します:
lms
以下のような出力が表示されるはずです:
lms - LM Studio CLI - v0.2.22
GitHub: https://github.com/lmstudio-ai/lmstudio-cli
Usage
lms <subcommand>
where <subcommand> can be one of:
- status - Prints the status of LM Studio
- server - Commands for managing the local server
- ls - List all downloaded models
- ps - List all loaded models
- load - Load a model
- unload - Unload a model
- create - Create a new project with scaffolding
- log - Log operations. Currently only supports streaming logs from LM Studio via `lms log stream`
- version - Prints the version of the CLI
- bootstrap - Bootstrap the CLI
For more help, try running `lms <subcommand> --help`
Qwen3-2507モデルのダウンロードと実行
LMStudioは最新のQwen3-2507シリーズをサポートしています。利用可能な主要モデルは以下の通りです:
Qwen3-2507シリーズ(2025年8月最新版):
qwen3-235b-a22b-instruct-2507(旗艦指令モデル)qwen3-235b-a22b-thinking-2507(旗艦思考モデル)qwen3-30b-a3b-instruct-2507(高効率指令モデル、VRAM 22-24GB推奨)qwen3-30b-a3b-thinking-2507(高効率思考モデル)qwen3-4b-instruct-2507(軽量指令モデル)qwen3-4b-thinking-2507(軽量思考モデル)
その他のQwen3ファミリーモデル:
qwen3-coder-30b-a3b-instruct(コーディング専用、ローカル実行に最適)qwen3:32b、qwen3:14b、qwen3:8b、qwen3:7bなど
実行例1:高効率な30B-A3B Instruct-2507モデルを使う場合
lms get qwen3-30b-a3b-instruct-2507
このコマンドでモデルがダウンロードされ、インタラクティブなチャットセッションが開始されます。チャットを終了するには Ctrl+C を押します。
注意:lms get コマンドは、モデルのダウンロードと対話型チャットを同時に行います。API経由で使用する場合は、後述の「API経由で使用する完全な手順」セクションを参照してください。
実行例2:軽量な4B Instruct-2507モデルを使う場合
lms get qwen3-4b-instruct-2507
4Bモデルは、より少ないVRAMで動作し、高速な応答が必要な場合に最適です。
実行例3:複雑な推論にThinking-2507モデルを使う場合
lms get qwen3-30b-a3b-thinking-2507
Thinking-2507モデルは、数学的証明、複雑なアルゴリズム設計、論理的推論が必要なタスクで威力を発揮します。
API経由で使用する完全な手順
API経由でQwen3-2507を使用する場合、以下の手順で進めます:
ステップ1:モデルのダウンロード(初回のみ)
まず、使用したいモデルをダウンロードします:
# 30B-A3Bモデルをダウンロード
lms get qwen3-30b-a3b-instruct-2507
このコマンドを実行すると、モデルがダウンロードされ、対話型チャットが開始されます。チャットを終了するには Ctrl+C を押します。
ダウンロード済みのモデルを確認するには:
lms ls
ステップ2:APIサーバーの起動
lms server start
ステップ3:モデルのロード
APIを使用する前に、モデルをメモリにロードする必要があります:
方法1:コマンドラインでロード
lms load qwen3-30b-a3b-instruct-2507
方法2:LMStudioのGUIでロード
LMStudioアプリケーションを開き、Developer ページでモデルをロードします。
ステップ4:ロード状態の確認
モデルが正しくロードされているか確認します:
lms ps
これで、APIリクエストを送信できる状態になりました。
使用後:サーバーの停止
lms server stop
コードからQwen3-2507を呼び出す
curlを使用する場合(Instruct-2507モデル):
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-30b-a3b-instruct-2507",
"messages": [
{ "role": "system", "content": "You are a helpful coding assistant." },
{ "role": "user", "content": "Write a Python function to calculate Fibonacci numbers." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
Thinking-2507モデルで複雑な推論を行う場合:
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-30b-a3b-thinking-2507",
"messages": [
{ "role": "system", "content": "Think step by step and show your reasoning." },
{ "role": "user", "content": "Design an efficient algorithm to find the longest palindromic substring." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
Pythonを使用する場合:
from openai import OpenAI
# ローカルサーバーに接続
client = OpenAI(base_url="http://localhost:1234/v1",
api_key="lm-studio")
# Instruct-2507モデルで高速応答
completion = client.chat.completions.create(
model="qwen3-30b-a3b-instruct-2507",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Explain the difference between async and await in JavaScript."}
],
temperature=0.7,
)
print(completion.choices[0].message)
# Thinking-2507モデルで深い推論
thinking_completion = client.chat.completions.create(
model="qwen3-30b-a3b-thinking-2507",
messages=[
{"role": "system", "content": "Think deeply and show your reasoning process."},
{"role": "user", "content": "How would you design a distributed caching system?"}
],
temperature=0.7,
)
print(thinking_completion.choices[0].message)
TypeScriptを使用する場合:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: "lm-studio", // 実際には必要ありません
baseUrl: "http://localhost:1234/v1"
});
async function main() {
// Instruct-2507モデルでコード生成
const codeCompletion = await client.chat.completions.create({
messages: [
{ role: 'system', content: 'You are an expert programmer.' },
{ role: 'user', content: 'Create a React component for a todo list with TypeScript.' }
],
model: "qwen3-30b-a3b-instruct-2507",
});
console.log(codeCompletion.choices[0].message);
// 軽量な4Bモデルで高速応答
const quickCompletion = await client.chat.completions.create({
messages: [
{ role: 'user', content: 'Explain what is a closure in JavaScript.' }
],
model: "qwen3-4b-instruct-2507",
});
console.log(quickCompletion.choices[0].message);
}
main();
ApidogでLMStudioのAPIをテストする
APIのテストにはApidogが非常に便利です。LMStudioのAPIモードと相性が良く、リクエストの送信や応答の確認が簡単に行えます。
Apidogを使ってQwen3-2507のAPIをテストする方法は以下の通りです:
- 新しいAPIリクエストを作成
- エンドポイントに
http://localhost:1234/v1/chat/completionsを設定 - リクエストを送信し、リアルタイムタイムラインで応答を監視
- JSONPath抽出機能を使って応答を自動的に解析
Instruct-2507モデルをテストする場合:
{
"model": "qwen3-30b-a3b-instruct-2507",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Explain MoE architecture in simple terms." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}
Thinking-2507モデルで複雑な推論をテストする場合:
{
"model": "qwen3-30b-a3b-thinking-2507",
"messages": [
{ "role": "system", "content": "Think step by step and show your reasoning." },
{ "role": "user", "content": "Design a scalable microservices architecture for an e-commerce platform." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}
軽量な4B-Instruct-2507モデルで高速応答をテストする場合:
{
"model": "qwen3-4b-instruct-2507",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What are the benefits of using TypeScript over JavaScript?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}
Apidogの強化されたストリーミング機能を使えば、ストリーミングメッセージが統合され、デバッグが効率的に行えます。特にThinking-2507モデルの推論プロセスを可視化する際に有用です。
トラブルシューティング
エラー:「No models loaded」
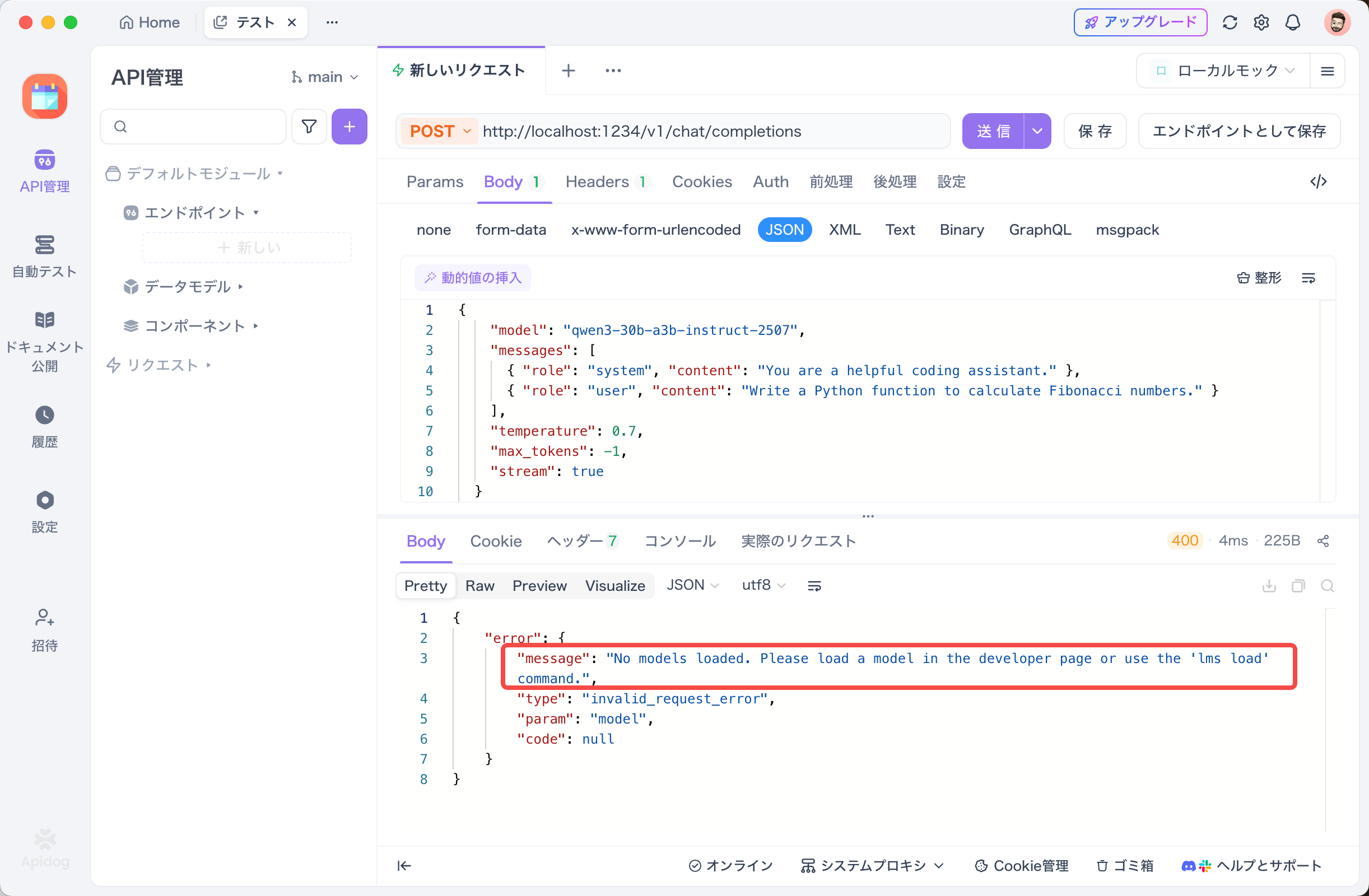
APIリクエスト時に以下のエラーが表示される場合:
{
"error": {
"message": "No models loaded. Please load a model in the developer page or use the 'lms load' command.",
"type": "invalid_request_error"
}
}
解決方法:
- まず、モデルがダウンロード済みか確認:
lms ls
2. ダウンロードされていない場合は、ダウンロード:
lms get qwen3-30b-a3b-instruct-2507
3. モデルをロード:
lms load qwen3-30b-a3b-instruct-2507
4. ロードされているか確認:
lms ps
5. LMStudioのGUIを使用している場合は、Developer ページでモデルを手動でロードしてください。
その他の注意点
- モデルのダウンロード:
lms loadを実行する前に、必ずlms getまたは LMStudio GUI でモデルをダウンロードしてください。 - VRAMの確認:30B-A3Bモデルは22~24GBのVRAMを推奨します。不足する場合は4Bモデルを試してください。
- サーバーの起動確認:
lms server startを実行後、http://localhost:1234にアクセスできることを確認してください。 - モデル名の確認:APIリクエストのモデル名は、
lms lsで表示される正確な名前を使用してください。 - ダウンロード済みモデルの確認:
lms lsコマンドで、ダウンロード済みのモデル一覧を確認できます。
まとめ
Qwen3-2507は本当に革命的なアップデートです。235Bパラメータの旗艦MoEモデルが、わずか22Bの活性パラメータで動作し、思考モードと指令モードを自在に切り替えられる。さらに256Kの超長コンテキスト(最大100万トークンまで拡張可能)により、大規模ドキュメントやコードベース全体の解析が可能になりました。2025年8月のこのアップデートは、ローカルAIの可能性を大きく広げました。
LMStudioを使えば、これらの強力なモデルを簡単にローカルで実行できるので、プライバシーを確保しながら、コスト効率よく最新のAI技術を活用できます。
個人的なおすすめモデル:
- 日常使い:Qwen3-30B-A3B-Instruct-2507 - わずか3Bの活性パラメータながら、驚くほど高性能。22~24GBのVRAMがあれば快適に動作
- 軽量・高速:Qwen3-4B-Instruct-2507 - より少ないVRAMで動作し、高速な応答が必要な場合に最適
- 複雑な推論:Qwen3-30B-A3B-Thinking-2507 - 数学的証明、複雑なアルゴリズム設計など、Chain-of-Thought推論が必要なタスクに最適
- コーディング特化:別途リリースされているQwen3-Coderシリーズも利用可能
ハードウェアとソフトウェアのエコシステムが進化し続ける中で、大規模言語モデルの力はますます民主化され、クラウドサーバーから私たちのローカルマシンへと移行しています。Qwen3-2507は、その最前線に立つモデルと言えるでしょう。
LMStudioを使えば、複雑な環境構築なしに、これらの最新モデルを数分で動かすことができます。プライバシーを重視する開発者、コストを抑えたい個人ユーザー、オフライン環境での利用を考えている方にとって、ローカルLLMは今後ますます重要な選択肢となっていくはずです。
Qwen3-2507の登場により、ローカルAI環境の可能性はさらに広がりました。思考モードと指令モードの使い分け、100万トークンの超長文処理、そして効率的なMoEアーキテクチャ。これらの機能を活用することで、これまでクラウドAPIでしか実現できなかった高度なタスクも、自分のマシンで実行できるようになります。
Apidogなら、美しいAPIドキュメントを自動生成するだけでなく、Postmanをより手頃な価格で置き換えることもできます。
オールインワンの開発体験を、ぜひお試しください。


