
ようこそ!最先端のAIツールを活用してウェブスクレイピングやコンテンツ分析を行う方法をずっと考えていたなら、ここがその正しい場所です。今日は、OpenAI SWARM、Streamlit、およびマルチエージェントシステムを組み合わせたエキサイティングなプロジェクトに深く dive して、ウェブスクレイピングをより賢くし、コンテンツ分析をより洞察に満ちたものにする方法を探ります。また、ApidogがAPIテストを簡素化し、あなたのAPIニーズに対してより手頃な選択肢となる方法も探っていきます。
さあ、完全な機能を持つウェブスクレイピングとコンテンツ分析システムの構築を始めましょう!
1. OpenAI SWARMとは?
OpenAI SWARMは、ウェブスクレイピングやコンテンツ分析を含むさまざまなタスクを自動化するためのAIとマルチエージェントシステムを活用する新たなアプローチです。SWARMは、複数のエージェントが独立して作業するか、特定のタスクで協力して共通の目標を達成することに焦点を当てています。

SWARMの仕組み
複数のウェブサイトからデータを収集したいと想像してみてください。単一のスクレイパーボットを使用することも可能ですが、ボトルネックやエラー、さらにはウェブサイトによってブロックされるリスクがあります。しかし、SWARMを使用すると、タスクの異なる側面に取り組むために複数のエージェントを展開できます。一部のエージェントはデータの抽出に焦点を当て、他のエージェントはデータのクリーンアップ、さらには分析用にデータを変換することに集中します。これらのエージェントは互いに通信し、タスクを効率的に処理します。
OpenAIの強力な言語モデルとSWARMの手法を組み合わせることで、人間の問題解決を模倣するスマートで適応型のシステムを構築できます。このチュートリアルでは、より賢いウェブスクレイピングとデータ処理のためにSWARM技術を使用します。
2. マルチエージェントシステムの紹介
マルチエージェントシステム(MAS)は、複雑な問題を解決するために共有された環境で相互作用する自律エージェントの集まりです。エージェントは並行してタスクを実行できるため、さまざまなソースからデータを収集しなければならない状況や、異なる処理段階が必要な場合にMASが理想的です。
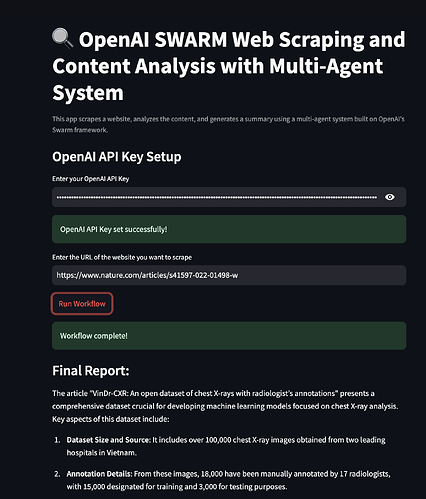
ウェブスクレイピングの文脈では、マルチエージェントシステムには次のようなエージェントが含まれる可能性があります:
- データ抽出:関連データを収集するために異なるウェブページをクロールします。
- コンテンツパース:分析のためにデータをクリーンアップして整理します。
- データ分析:収集されたデータから洞察を得るためにアルゴリズムを適用します。
- 報告:ユーザーフレンドリーな形式で結果を提示します。
ウェブスクレイピングにマルチエージェントシステムを使用する理由は?
マルチエージェントシステムは障害に対して頑健であり、非同期に動作することができます。つまり、1つのエージェントが失敗したり問題に直面しても、他のエージェントは業務を続けることができます。したがって、SWARMアプローチはウェブスクレイピングプロジェクトにおいてより高い効率、スケーラビリティ、およびフォールトトレランスを保証します。
3. Streamlit: 概要
Streamlitは、データ分析、機械学習、及び自動化プロジェクトのためにカスタムウェブアプリケーションを簡単に作成し共有できる人気のオープンソースのPythonライブラリです。インタラクティブなUIを作成するためのフレームワークを提供し、フロントエンドの経験がなくても大丈夫です。
なぜStreamlitなのか?
- 使いやすさ:Pythonコードを書くだけで、Streamlitがそれをユーザーフレンドリーなウェブインターフェースに変換します。
- 迅速なプロトタイピング:新しいアイデアの迅速なテストと展開が可能です。
- AIモデルとの統合:機械学習ライブラリやAPIとシームレスに統合されます。
- カスタマイズ:さまざまなユースケースに対応した洗練されたアプリを構築するための柔軟性があります。
私たちのプロジェクトでは、Streamlitを使用してウェブスクレイピングの結果を可視化し、コンテンツ分析のメトリックを表示し、マルチエージェントシステムを制御するためのインタラクティブなインターフェースを作成します。
4. なぜApidogがゲームチェンジャーなのか
Apidogは、従来のAPI開発およびテストツールに代わる堅牢なソリューションです。設計からテスト、展開に至るまで、APIライフサイクル全体をサポートし、1つの統合プラットフォーム内で完結します。

Apidogの主な機能:
- ユーザーフレンドリーなインターフェース:使いやすいドラッグ&ドロップのAPI設計。
- 自動テスト:追加のスクリプトを書くことなく、包括的なAPIテストを実行します。
- 組み込み文書化:詳細なAPI文書を自動的に生成します。
- 手頃な価格プラン:競合他社と比較して、もっと手頃なオプションを提供します。
Apidogは、API統合とテストが不可欠なプロジェクトに最適で、コスト効率的かつ包括的なソリューションです。
Apidogを無料でダウンロードして、これらの利点を実際に体験してください。
5. 開発環境の設定
コードに入る前に、環境が整っていることを確認しましょう。必要なものは:
- Python 3.7+
- Streamlit:
pip install streamlitでインストール - ウェブスクレイピング用BeautifulSoup:
pip install beautifulsoup4でインストール - Requests:
pip install requestsでインストール - Apidog:APIテスト用に、Apidogの公式ウェブサイトからダウンロードできます。
上記のすべてがインストールされていることを確認してください。では、環境を設定しましょう。
6. ウェブスクレイピング用のマルチエージェントシステムの構築
OpenAI SWARMとPythonライブラリを使用して、ウェブスクレイピングのためのマルチエージェントシステムを構築しましょう。ここでの目標は、さまざまなウェブサイトからデータをクロール、解析、分析するタスクを実行する複数のエージェントを作成することです。
ステップ1: エージェントの定義
異なるタスクのためにエージェントを作成します:
- クロールエージェント:ウェブページから生のHTMLを収集します。
- パーサーエージェント:意味のある情報を抽出します。
- アナライザーエージェント:データを処理して洞察を得ます。
以下は、Pythonで簡単なCrawlerAgentを定義する方法です:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"{self.url}からコンテンツを取得できませんでした")
except Exception as e:
print(f"エラー: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
ステップ2: パーサーエージェントの追加
ParserAgentが生のHTMLをクリーンアップして構造化します:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # 例: すべての段落を抽出
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
ステップ3: アナライザーエージェントの追加
このエージェントは、コンテンツを分析するために自然言語処理(NLP)技術を適用します。
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # 例: 最も一般的な上位10単語
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. SWARMとStreamlitによるコンテンツ分析
エージェントが連携して機能し始めたので、Streamlitを使用して結果を可視化しましょう。
ステップ1: Streamlitアプリの作成
Streamlitをインポートして基本的なアプリ構造を設定することから始めます:
import streamlit as st
st.title("マルチエージェントシステムを用いたウェブスクレイピングとコンテンツ分析")
st.write("より賢いデータ抽出のためのOpenAI SWARMとStreamlitの使用。")
ステップ2: エージェントの統合
ユーザーがURLを入力し、スクレイピングと分析の結果を表示できるように、Streamlitアプリにエージェントを統合します。
url = st.text_input("スクレイピングするURLを入力してください:")
if st.button("スクレイピングして分析"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("最も一般的な上位10単語")
st.write(analysis_result)
else:
st.error("コンテンツの取得に失敗しました。別のURLを試してください。")
else:
st.warning("有効なURLを入力してください。")
ステップ3: アプリの展開
以下のコマンドを使用してアプリを展開できます:
streamlit run your_script_name.py

8. Apidogを使用したAPIのテスト
次に、ApidogがウェブスクレイピングアプリにおけるAPIのテストにどのように役立つかを見てみましょう。

ステップ1: Apidogの設定
Apidogの公式ウェブサイトからApidogをダウンロードしてインストールします。インストールガイドに従って環境を設定してください。
ステップ2: APIリクエストの作成
Apidog内で直接APIリクエストを作成してテストできます。GET、POST、PUT、DELETEなど、さまざまなリクエストタイプをサポートしており、ウェブスクレイピングのあらゆるシナリオに対応できます。

ステップ3: APIテストの自動化
Apidogを使用すると、テストスクリプトを自動化して、外部サービスに接続するときのマルチエージェントシステムの応答を検証できます。これにより、あなたのシステムは時間の経過とともに堅牢で一貫したものとなります。

9. Streamlitアプリケーションの展開
アプリケーションが完成したら、一般公開のために展開します。Streamlitは、そのStreamlit Sharingサービスを使用してこれを簡単にします。
- GitHubにコードをホストします。
- Streamlit Sharingに移動し、GitHubリポジトリを接続します。
- ワンクリックでアプリを展開します。
10. 結論
おめでとうございます!OpenAI SWARM、Streamlit、およびマルチエージェントシステムを使用して強力なウェブスクレイピングとコンテンツ分析システムを構築する方法を学びました。SWARM手法がどのようにスクレイピングをより賢くし、コンテンツ分析をより正確にするかを探りました。Apidogを統合することで、APIテストと検証の洞察も得られ、システムの信頼性を確保できました。
さあ、Apidogを無料でダウンロードして、強力なAPIテスト機能を活用してプロジェクトをさらに強化しましょう。Apidogは、他のソリューションと比較して手頃で効率的な選択肢として際立っており、開発者にシームレスな体験を提供します。
このチュートリアルを通じて、複雑なデータ収集と分析タスクにより効果的に取り組む準備が整いました。頑張って、コーディングを楽しんでください!


