
Les développeurs recherchent constamment des modèles d'IA avancés pour améliorer le raisonnement, le codage et la résolution de problèmes dans leurs applications. L'API Qwen3-Max-Thinking se distingue comme une version d'aperçu qui repousse les limites dans ces domaines. Ce guide explique comment les ingénieurs accèdent et implémentent cette API efficacement. De plus, il met en évidence les outils qui simplifient le processus.
Alibaba Cloud alimente l'API Qwen3-Max-Thinking, offrant un aperçu précoce de capacités de réflexion améliorées. Publié comme un point de contrôle intermédiaire pendant l'entraînement, ce modèle atteint des performances remarquables sur des benchmarks tels que AIME 2025 et HMMT lorsqu'il est combiné avec l'utilisation d'outils et une puissance de calcul évoluée. De plus, les utilisateurs activent facilement le mode de réflexion via des paramètres comme enable_thinking=True. À mesure que l'entraînement progresse, attendez-vous à des fonctionnalités encore plus puissantes. Cet article couvre tout, de l'enregistrement à l'utilisation avancée, garantissant que vous intégrez l'API Qwen3-Max-Thinking en douceur dans vos flux de travail.
Comprendre l'API Qwen3-Max-Thinking
Les ingénieurs reconnaissent l'API Qwen3-Max-Thinking comme une évolution de la série Qwen d'Alibaba, spécifiquement conçue pour des tâches de raisonnement supérieures. Contrairement aux modèles standards, cet aperçu intègre des "budgets de réflexion" qui permettent aux utilisateurs de contrôler la profondeur du raisonnement dans des domaines comme les mathématiques, le codage et l'analyse scientifique. Alibaba a publié cette version pour présenter les progrès, même si l'entraînement se poursuit.

Le modèle de base Qwen3-Max se vante de plus d'un billion de paramètres et d'un entraînement sur 36 billions de jetons, doublant le volume de données de son prédécesseur, Qwen2.5. Il prend en charge une fenêtre de contexte massive de 262 144 jetons, avec une entrée maximale de 258 048 jetons et une sortie de 65 536 jetons. De plus, il gère plus de 100 langues, ce qui le rend polyvalent pour les applications mondiales. Cependant, la variante Qwen3-Max-Thinking ajoute des fonctionnalités d'agent, réduisant les hallucinations et permettant des processus multi-étapes via l'appel d'outils Qwen-Agent.
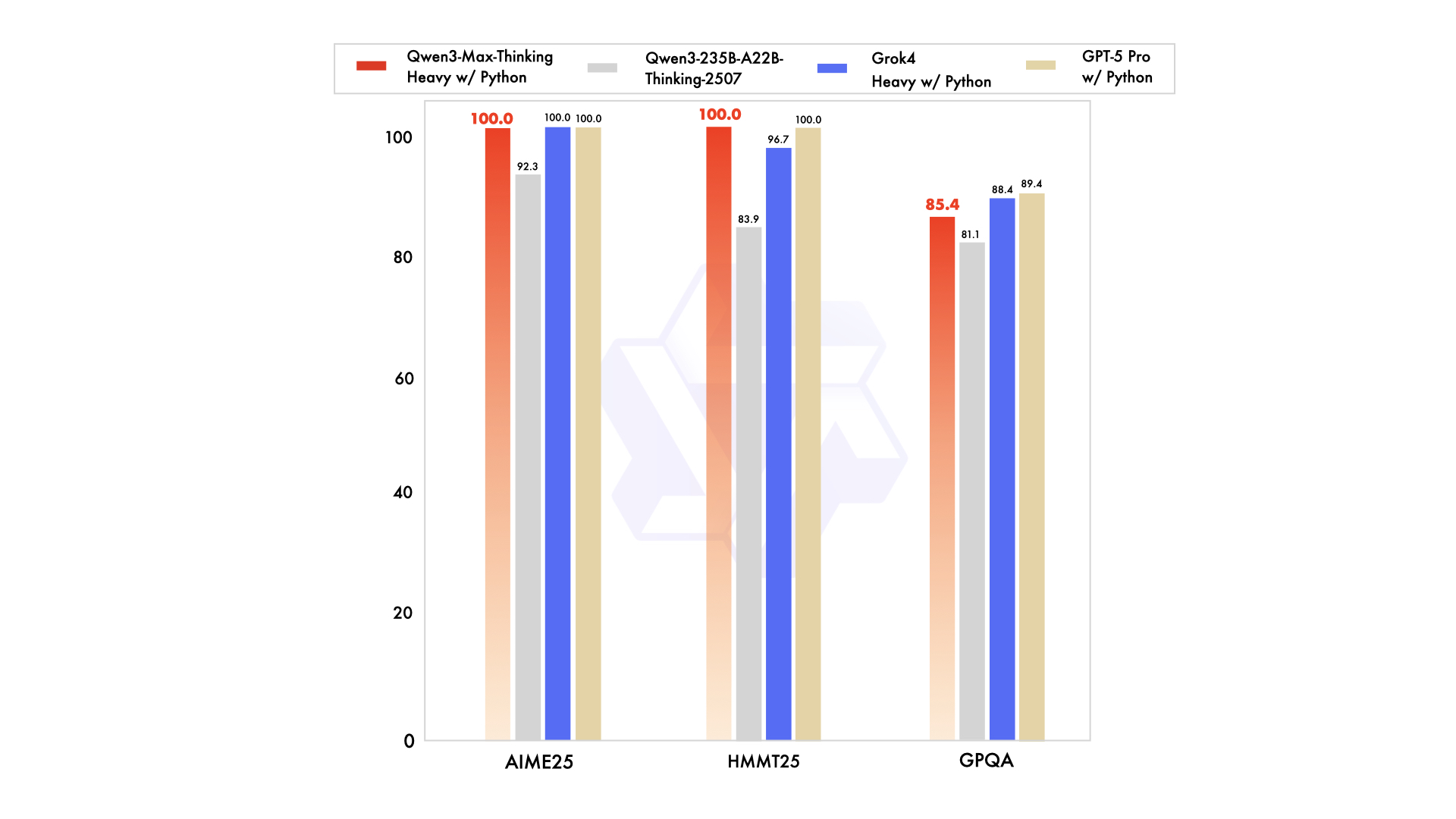
Les métriques de performance soulignent ses forces. Par exemple, il obtient un score de 74,8 sur LiveCodeBench v6 pour le codage et de 81,6 sur AIME25 pour les mathématiques. Lorsqu'il est augmenté, il atteint 100 % sur des benchmarks exigeants comme AIME 2025 et HMMT. Néanmoins, cet aperçu fonctionne initialement comme un modèle d'instruction non-réfléchissant, avec des améliorations de raisonnement activées via des drapeaux spécifiques. Les développeurs y accèdent via l'API d'Alibaba Cloud, qui maintient la compatibilité avec les standards OpenAI pour une migration facile.
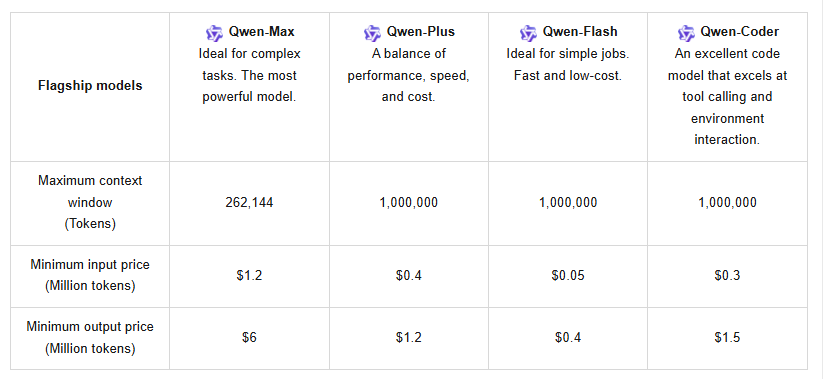
De plus, l'API prend en charge la mise en cache de contexte, ce qui optimise les requêtes répétées et réduit les coûts. La tarification suit une structure échelonnée : pour 0 à 32K jetons, l'entrée coûte 1,2 $ par million et la sortie 6 $ par million ; pour 32K à 128K, l'entrée passe à 2,4 $ et la sortie à 12 $ ; et pour 128K à 252K, l'entrée atteint 3 $ avec une sortie à 15 $. Les nouveaux utilisateurs bénéficient d'un quota gratuit d'un million de jetons, valable 90 jours, encourageant les tests initiaux.
En comparaison avec des concurrents comme Claude Opus 4 ou DeepSeek-V3.1, Qwen3-Max-Thinking excelle dans les tâches d'agent, telles que SWE-Bench Verified à 72,5. Pourtant, son statut d'aperçu signifie que certaines fonctionnalités, comme les budgets de réflexion complets, sont encore en développement. Les utilisateurs peuvent l'essayer via Qwen Chat pour des sessions interactives ou l'API pour un accès programmatique. Cette configuration positionne l'API Qwen3-Max-Thinking comme un outil clé pour le développement logiciel, l'éducation et l'automatisation d'entreprise.
Prérequis pour accéder à l'API Qwen3-Max-Thinking
Avant de poursuivre, les développeurs doivent rassembler les exigences essentielles. Tout d'abord, créez un compte Alibaba Cloud si vous n'en avez pas. Visitez le site web d'Alibaba Cloud et inscrivez-vous en utilisant une adresse e-mail ou un numéro de téléphone. Vérifiez le compte via le lien ou le code fourni pour activer l'accès complet.
Ensuite, assurez-vous de bien connaître les concepts d'API, y compris les points de terminaison RESTful et les charges utiles JSON. L'API Qwen3-Max-Thinking utilise les protocoles HTTPS, donc les connexions sécurisées sont importantes. De plus, préparez les outils de développement : Python 3.x ou des langages similaires avec des bibliothèques comme `requests` pour les appels HTTP. Pour des intégrations avancées, envisagez des frameworks tels que vLLM ou SGLang, qui prennent en charge un service efficace sur plusieurs GPU.
L'authentification nécessite une clé API d'Alibaba Cloud. Naviguez vers la console après vous être connecté et générez des clés dans la section de gestion des API. Stockez-les en toute sécurité, car elles accordent l'accès aux points de terminaison du modèle. De plus, conformez-vous aux politiques d'utilisation — évitez les appels excessifs pour éviter la limitation de débit. Le système propose les dernières versions et des versions instantanées ; sélectionnez les instantanés pour des performances stables sous de fortes charges.
Des considérations matérielles s'appliquent pour les tests locaux, bien que l'accès au cloud atténue cela. Le modèle exige une puissance de calcul significative, mais l'infrastructure d'Alibaba le gère. Enfin, téléchargez des outils de support comme Apidog pour rationaliser les tests. Apidog gère les requêtes, les environnements et les collaborations, ce qui le rend idéal pour expérimenter les paramètres de l'API Qwen3-Max-Thinking.
Avec ces éléments en place, les ingénieurs évitent les pièges courants comme les erreurs d'authentification ou l'épuisement des quotas. Cette préparation assure une transition transparente vers l'implémentation réelle.
Guide étape par étape pour obtenir et configurer l'API Qwen3-Max-Thinking
Les développeurs commencent par se connecter à la console Alibaba Cloud. Localisez la section ModelStudio, où résident les modèles Qwen. Recherchez "qwen3-max-preview" ou des identifiants similaires pour trouver la documentation et la page d'activation.
Activez ensuite le modèle. Cliquez sur le bouton d'activation pour Qwen3-Max-Thinking, en acceptant les conditions si vous y êtes invité. Cette étape donne accès aux fonctionnalités d'aperçu. De plus, échangez le quota de jetons gratuit en suivant les instructions à l'écran — les nouveaux comptes sont automatiquement éligibles.
Générez ensuite les identifiants API. Dans la zone de gestion des clés API, créez une nouvelle paire de clés. Notez l'ID de la clé d'accès et le secret ; ceux-ci authentifient les requêtes. Évitez de les partager publiquement pour maintenir la sécurité.
Configurez ensuite votre environnement de développement. Installez les bibliothèques nécessaires via pip, telles que pip install requests openai. Bien que compatible OpenAI, ajustez les points de terminaison à l'URL de base d'Alibaba, typiquement quelque chose comme "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation".
Testez un appel de base pour vérifier la configuration. Construisez une charge utile JSON avec le nom du modèle "qwen3-max-preview", l'invite d'entrée et le paramètre crucial "enable_thinking": true. Envoyez une requête POST au point de terminaison. Par exemple :
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Surveillez la réponse pour les étapes de réflexion dans la sortie. Si cela réussit, cela démontre un raisonnement actif. Cependant, gérez les erreurs comme 401 pour les clés invalides en vérifiant à nouveau les identifiants.
Passez aux configurations avancées. Intégrez l'appel d'outils en ajoutant des fonctions dans la charge utile. L'API prend en charge Qwen-Agent pour les flux de travail d'agent, permettant des exécutions multi-étapes. De plus, utilisez la mise en cache de contexte en incluant des ID de cache dans les requêtes pour réutiliser efficacement les contextes précédents.
Résolvez les problèmes rapidement. Les limites de débit déclenchent des erreurs 429 ; passez aux versions instantanées ou optimisez les requêtes. Les problèmes de réseau nécessitent des connexions stables. En suivant ces étapes, les développeurs sécurisent un accès fiable à l'API Qwen3-Max-Thinking.
Intégrer l'API Qwen3-Max-Thinking avec Apidog
Apidog simplifie les interactions API, et les développeurs l'exploitent pour l'API Qwen3-Max-Thinking. Commencez par télécharger Apidog depuis leur site officiel — c'est gratuit et s'installe rapidement sur les principales plateformes.
Importez ensuite la spécification API. Apidog prend en charge les formats OpenAPI ; téléchargez la spécification d'Alibaba pour les modèles Qwen et téléchargez-la. Cette action remplit automatiquement les points de terminaison, y compris ceux de génération de texte.
Configurez ensuite les environnements. Créez un nouvel environnement dans Apidog, en ajoutant des variables pour les clés API et les URL de base. Cette configuration permet de basculer facilement entre les tests et la production.
Testez ensuite les requêtes. Utilisez l'interface d'Apidog pour construire des appels POST. Saisissez le modèle, l'invite et le paramètre `enable_thinking`. Envoyez la requête et inspectez les réponses en temps réel, avec des fonctionnalités comme la coloration syntaxique et la journalisation des erreurs.
Enchaînez les requêtes pour des flux de travail complexes. Apidog permet de séquencer les appels, idéal pour les tâches d'agent où une réponse alimente une autre. De plus, simulez des charges élevées pour tester les performances.
Collaborez avec des équipes en utilisant les outils de partage d'Apidog. Exportez des collections pour que vos collègues puissent reproduire les configurations. De plus, surveillez l'utilisation des jetons grâce à des analyses intégrées pour rester dans les quotas.
Optimisez davantage les intégrations. Apidog gère efficacement les charges utiles volumineuses, prenant en charge la fenêtre de contexte de 262K. Déboguez les hallucinations en ajustant les budgets de réflexion une fois qu'ils sont entièrement disponibles.
Explorer les points de terminaison et les paramètres de l'API
L'API Qwen3-Max-Thinking expose plusieurs points de terminaison, principalement pour la génération de texte. Le principal, /api/v1/services/aigc/text-generation/generation, gère les tâches de complétion. Les développeurs POSTent des données JSON ici.
Les paramètres clés incluent "model", spécifiant "qwen3-max-preview". L'objet "input" contient des messages au format chat. De plus, les "parameters" dictent le comportement : définissez "enable_thinking" sur True pour le mode de raisonnement.
- D'autres options améliorent le contrôle. "max_tokens" limite la longueur de la sortie, jusqu'à 65 536. "temperature" ajuste la créativité, par défaut à 0,7. "top_p" affine l'échantillonnage.
- Pour l'utilisation d'outils, incluez un tableau "tools" avec des définitions de fonctions. L'API répond avec des appels, permettant des flux d'agent.
- La mise en cache de contexte utilise "cache_prompt" pour stocker et référencer les entrées précédentes, réduisant les coûts. Spécifiez les ID de cache dans les requêtes ultérieures.
- Les paramètres de gestion des erreurs comme "retry" gèrent les transitoires. De plus, le versionnement via "snapshot" assure la cohérence.
Comprendre ces éléments permet un réglage précis. Pour les problèmes de mathématiques, une réflexion plus approfondie permet des étapes détaillées ; pour le codage, elle génère des solutions robustes. Les développeurs expérimentent pour trouver les paramètres optimaux.
Exemples pratiques d'utilisation de l'API Qwen3-Max-Thinking
Les ingénieurs appliquent l'API dans divers scénarios. Considérez le codage : Demandez "Écrivez une fonction Python pour trier une liste." Avec la réflexion activée, elle décrit la logique avant le code.
- En mathématiques, interrogez "Résoudre l'intégrale de x^2 dx." La réponse décompose les étapes, montrant les règles d'intégration.
- Pour les tâches d'agent, définissez des outils comme la recherche web. Le modèle planifie les actions, exécute via des rappels et synthétise les résultats.
- Utilisation en entreprise : Analysez de longs documents en fournissant des contextes. La grande fenêtre traite les historiques des utilisateurs pour des recommandations.
- Éducation : Générez des explications pour des sujets complexes, en adaptant la profondeur via des paramètres.
- Santé : Soutenez les décisions éthiques avec des résultats raisonnés, bien que toujours à vérifier.
- Écriture créative : Produisez des histoires avec des intrigues logiques.
Ces exemples illustrent la polyvalence. Les développeurs les adaptent en utilisant Apidog pour les tests.
Bonnes pratiques pour une utilisation efficace
Optimisez d'abord la consommation de jetons. Rédigez des invites concises pour éviter le gaspillage. Utilisez la mise en cache pour les éléments répétitifs.
Surveillez les quotas avec diligence. Suivez l'utilisation dans la console ; mettez à niveau si nécessaire.
Sécurisez les clés avec des variables d'environnement ou des coffres-forts. Faites-les pivoter périodiquement.
Gérez les limites de débit en implémentant une temporisation exponentielle dans le code.
Testez minutieusement avec Apidog avant la production. Simulez les cas limites.
Mettez à jour vers de nouveaux instantanés dès leur publication, en vérifiant les journaux de modifications.
Combinez avec d'autres outils pour des systèmes hybrides.
Suivez ces conseils pour maximiser le potentiel de l'API Qwen3-Max-Thinking.
Conclusion
L'API Qwen3-Max-Thinking transforme les applications d'IA grâce à un raisonnement avancé. En suivant ce guide, les développeurs peuvent y accéder et l'intégrer efficacement, en tirant parti d'Apidog pour l'efficacité. À mesure que les fonctionnalités évoluent, elle reste un choix de premier ordre pour les projets innovants.