
Are you looking to reduce token costs and improve data clarity in your Large Language Model (LLM) workflows? As AI agents and LLM-based applications expand, the structure and efficiency of data serialization become crucial. Enter TOON (Token-Oriented Object Notation), a cutting-edge format designed to optimize structured data for LLM input while keeping it readable and schema-aware.
In this article, we’ll break down what TOON is, how it compares to JSON, YAML, and minified JSON, and where it fits best in modern AI and API workflows.
💡 Want an API testing tool that creates beautiful API documentation? Need an all-in-one platform for developer collaboration and maximum productivity? Apidog covers your needs and replaces Postman at a more affordable price!
What Is TOON (Token-Oriented Object Notation)?
TOON is a human-readable, schema-aware serialization format engineered specifically for LLMs. While it preserves the same core data model as JSON—objects, arrays, and primitives—it introduces a compact syntax that sharply reduces token usage when sending data to LLMs.
Key Features of TOON:
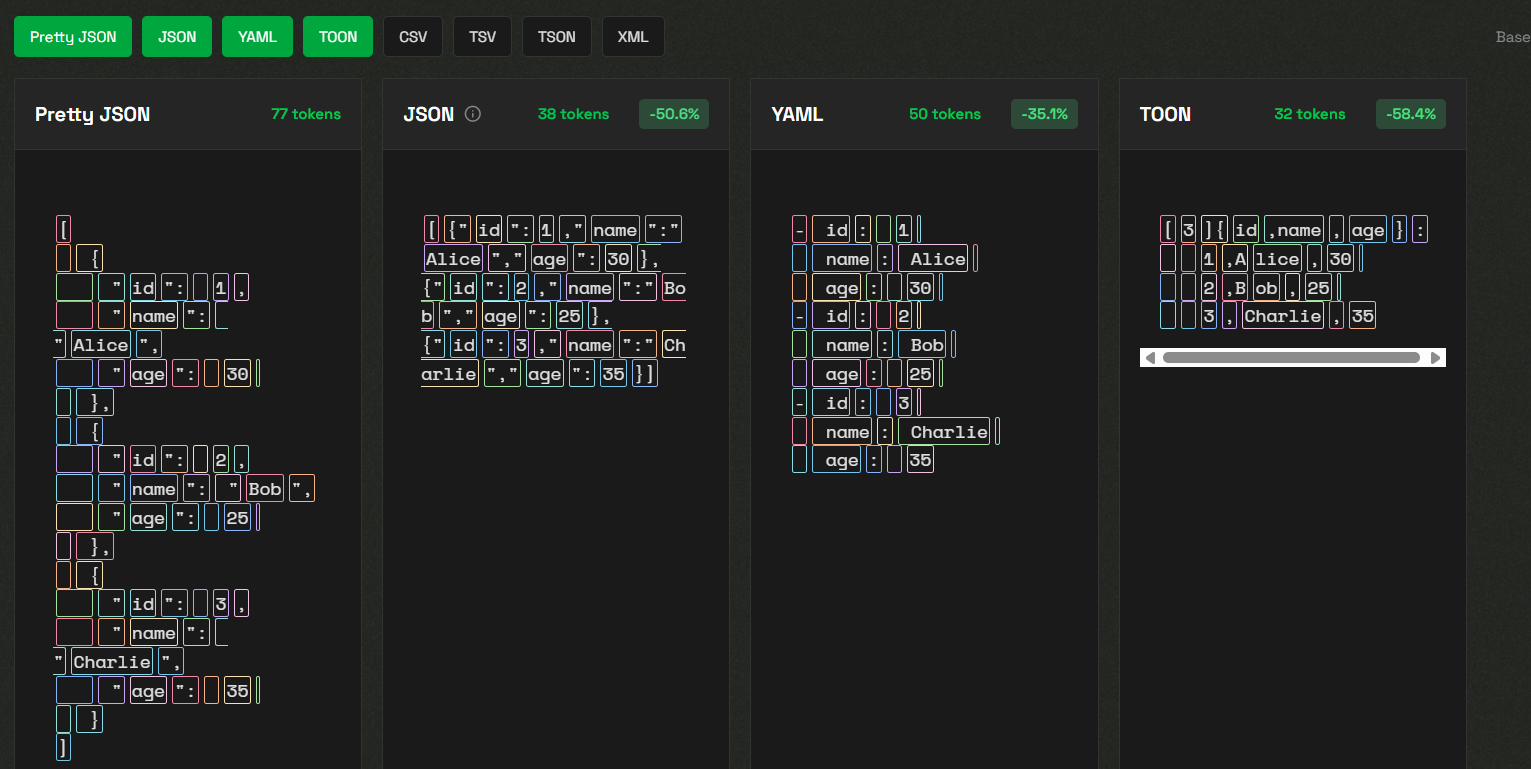
- Token Efficiency: Delivers 30–60% fewer tokens than pretty-printed JSON for uniform arrays.
- Schema Awareness: Declares array lengths (e.g., users[3]) and field headers ({id,name}) to help LLMs interpret structure with high accuracy.
- Minimal Syntax: Reduces punctuation (fewer braces, brackets, quotes), drawing inspiration from YAML and CSV.
Example: TOON Tabular Syntax for Uniform Arrays
When serializing multiple similar objects, TOON uses a compact, table-like format:
[3]{id,name,age}:
1,Alice,30
2,Bob,25
3,Charlie,35
This format explicitly communicates the schema and the number of records, making it both efficient and easy for LLMs to parse.
In practice, you maintain your backend data in JSON and convert it to TOON only when sending to the LLM, reverting back to JSON for API or database use.
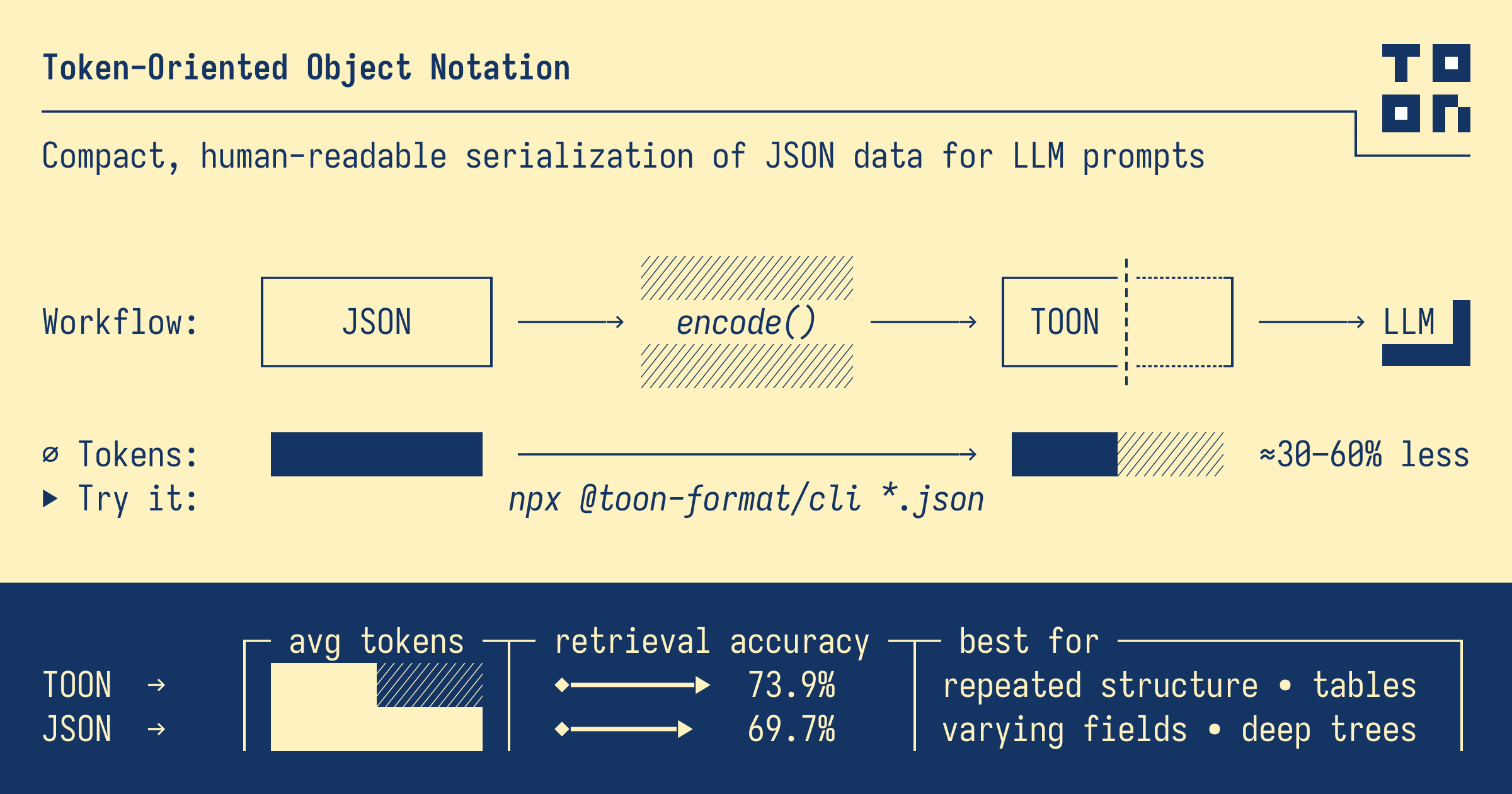
TOON vs JSON, YAML, and Minified JSON: A Practical Comparison
Understanding the strengths and weaknesses of each serialization format is key for API developers and AI-focused teams.
JSON
- Ubiquity: Supported everywhere—APIs, libraries, databases.
- Drawback: Verbose due to structural characters (quotes, braces, brackets), which inflate token counts in LLM prompts.
- Schema Limitation: Lacks explicit array lengths or field headers, so LLMs may struggle to reconstruct or validate structure.
[
{"id": 1, "name": "Alice", "age": 30},
{"id": 2, "name": "Bob", "age": 25},
{"id": 3, "name": "Charlie", "age": 35}
]
Minified (Compressed) JSON
- Compactness: Removes whitespace and newlines, slightly reducing size.
- Token Cost: Still includes all punctuation, keeping token usage relatively high.
- Structure: No explicit schema markers, making LLM parsing more error-prone.
[{"id":1,"name":"Alice","age":30},{"id":2,"name":"Bob","age":25},{"id":3,"name":"Charlie","age":35}]
YAML
- Readability: Uses indentation, making hierarchical data easier for humans.
- Less Verbose: Saves some tokens compared to JSON.
- Ambiguity: Lacks explicit array lengths or field headers unless manually added, risking structure misinterpretation by LLMs.
- id: 1
name: Alice
age: 30
- id: 2
name: Bob
age: 25
- id: 3
name: Charlie
age: 35
TOON
- Token Savings: Dramatically reduces tokens for uniform, tabular data.
- Schema Clarity: Array lengths and field headers are explicit.
- Readability: Familiar to anyone using CSV, YAML, or tabular data formats.
- Best Use Case: Uniform, flat, or tabular data—where TOON’s table notation shines.
- Limitations: For deeply nested or highly irregular data, JSON may be more practical.
[3]{id,name,age}:
1,Alice,30
2,Bob,25
3,Charlie,35
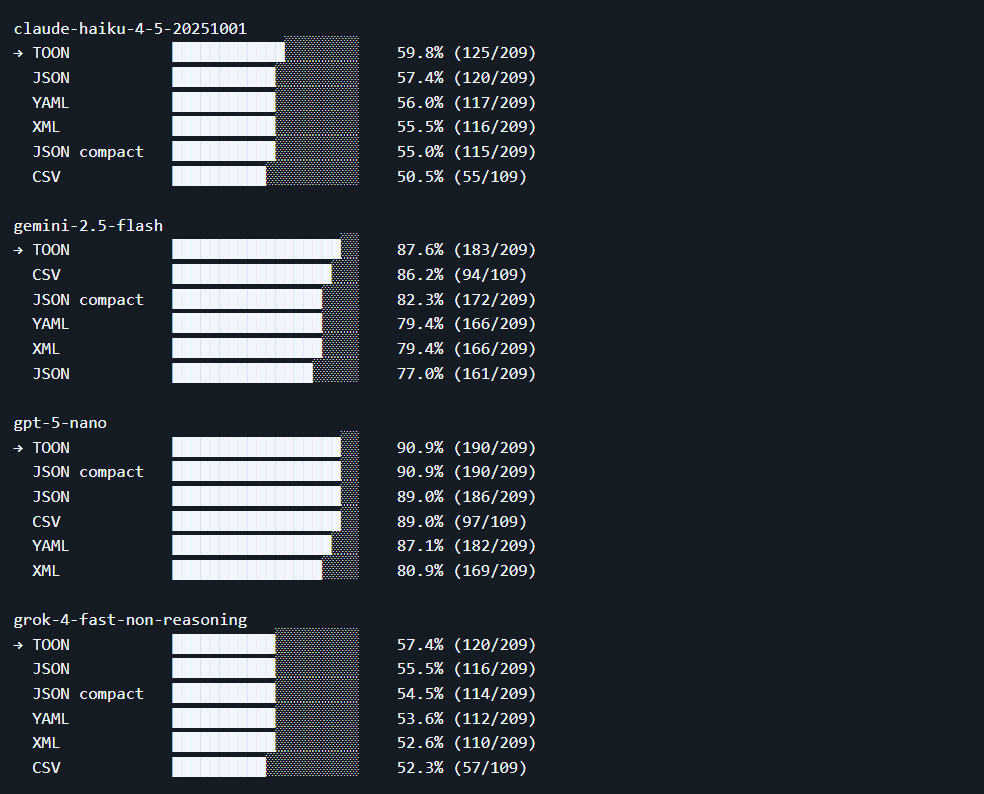
TOON accuracy across 4 LLMs on 209 data retrieval questions according to toon-format/GitHub
Why API & LLM Developers Should Consider TOON
Key Benefits
- Cost Efficiency: LLM APIs often price by token. TOON’s compact syntax can cut input costs significantly.
- Maximized Context Window: Smaller serialized data means more space for instructions, examples, or user queries.
- Reliability: Explicit structure reduces hallucinations and parsing errors in LLMs.
- Seamless Integration: Keep using JSON for APIs and databases—convert to TOON only for LLM interactions.
- Consistent Agent Workflows: For AI agents making tool calls or multi-step decisions, TOON preserves structural clarity at each step.
Example Workflow
- Backend Data: Your server or API outputs JSON as usual.
- Data Conversion: Before sending to the LLM, convert the JSON payload to TOON (with tools like ToonParse).
- LLM Processing: LLM receives the compact, schema-aware data, reducing cost and boosting reliability.
- Post-Processing: Convert TOON output back to JSON for downstream API or storage needs.
When TOON Isn’t the Best Fit
TOON isn’t a universal replacement for JSON or YAML. Consider these scenarios:
- Deeply Nested or Irregular Data: JSON is more flexible and sometimes more compact for complex hierarchies.
- Ecosystem Expectations: Many APIs, databases, and tools expect JSON. TOON is best as an internal translation layer.
- LLM Familiarity: Most LLMs are trained on JSON, not TOON. For best results, provide clear examples and use prompt engineering when introducing TOON.
- Tooling Maturity: While TOON has SDKs (TypeScript, Python, more), its ecosystem is still growing compared to JSON.
Frequently Asked Questions (FAQ)
Q1. What does TOON stand for?
A: Token-Oriented Object Notation—a format optimized to encode structured data into fewer tokens for LLM input.
Q2. Can TOON represent all JSON data?
A: Yes. TOON is lossless relative to JSON; it supports the same data types and nesting.
Q3. How much token saving does TOON deliver?
A: Benchmarks show 30–60% fewer tokens versus pretty-printed JSON for uniform arrays, while preserving high accuracy for structured retrieval.
Q4. Will LLMs understand TOON by default?
A: Many LLMs can parse TOON if prompted with examples. However, some prompt tuning may be needed for models not pre-trained on TOON.
Q5. Is TOON suitable for API endpoints or storage?
A: Not directly. TOON is ideal for LLM input. For APIs and storage, JSON or other standards remain best. Use TOON as a translation layer within your LLM pipeline.
Verdict: Should You Use TOON Instead of JSON for LLMs?
TOON is a powerful complement—not a wholesale replacement—for JSON in LLM and AI agent workflows.
-
Use TOON when:
- You need to minimize token usage (cost-sensitive, large context windows).
- Your data is uniform, tabular, or flat.
- Clarity and schema validation for LLMs are priorities.
-
Stick with JSON when:
- You require maximum compatibility and interoperability.
- Your data is deeply nested or highly variable in structure.
For teams building robust LLM pipelines, TOON can be a game-changer—especially when combined with the right API testing and documentation tools. Platforms like Apidog streamline API workflows, making it easy to integrate new serialization formats and optimize your LLM-driven processes.
Conclusion
TOON is a thoughtful evolution in data serialization for LLMs and AI agents, offering minimal syntax, explicit schemas, and significant token savings. For developers and teams handling large, structured payloads in LLM workflows, TOON delivers real efficiency and clarity.
Evaluate your data patterns and consider integrating TOON where it makes sense. Continue leveraging JSON or YAML where interoperability or deep nesting are key. And for a unified platform that supports seamless API testing, documentation, and team collaboration, explore Apidog.
💡 Want an API testing tool that builds beautiful API documentation? Need streamlined teamwork with maximum productivity? Apidog has you covered and replaces Postman at a better price!


