
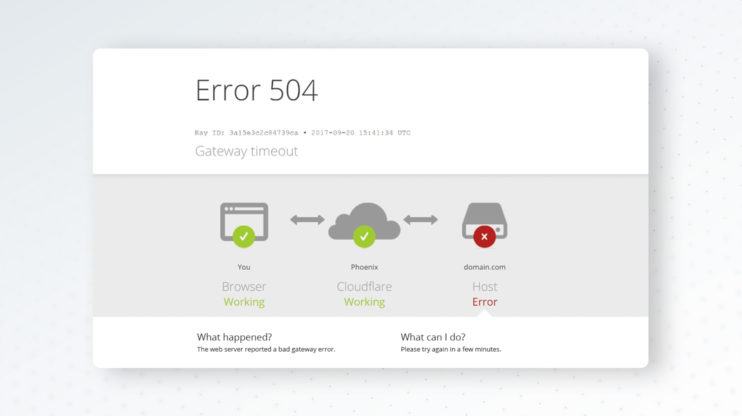
You're browsing a website, and instead of the page loading, you're staring at a message that says "504 Gateway Timeout." The spinner has been spinning for what feels like an eternity. You hit refresh, but the same error appears. The website isn't technically "down," but something in its infrastructure has given up waiting for a response.
This frustrating experience is caused by one of the most common server-side errors on the modern web: the 504 Gateway Timeout status code.
Unlike client errors like 404 Not Found, which are usually the user's "fault," or server errors like 500 Internal Server Error, which happen inside the application, the 504 is a communication breakdown between servers. It's the digital equivalent of a middleman throwing their hands up and saying, "I've been waiting too long for the person you actually want to talk to, and I'm giving up."
But what exactly is HTTP Status Code 504: Gateway Timeout, and why does it happen? More importantly, how can you fix it or prevent it from showing up in your app, API, or website?
If you're a developer, system administrator, or just a curious web user, understanding what causes a 504 error and how to fix it is incredibly valuable.
We’ll cover all of that in detail from what this code means, to common causes, to practical fixes.
Now, let's explore what happens behind the scenes when you encounter a 504 Gateway Timeout.
The Modern Web Architecture: It's Never Just One Server
To understand 504, we need to understand how modern websites and applications are built. Very few applications run on a single server anymore. Most use a multi-tier architecture that looks something like this:
- User's Browser: Makes the initial request.
- Load Balancer / Reverse Proxy: Distributes traffic to multiple backend servers (e.g., NGINX, HAProxy, AWS ALB).
- Web/Application Servers: Run the actual application code (e.g., Node.js, Python/Django, PHP).
- Backend Services / APIs: Handle specific tasks like authentication, payments, or data processing (often microservices).
- Database / Cache: Store and retrieve data.
The 504 error typically occurs between steps 2 and 3, or between steps 3 and 4. The "gateway" in "Gateway Timeout" refers to the server acting as an intermediary the load balancer or reverse proxy.
What Does HTTP 504 Gateway Timeout Actually Mean?
The 504 Gateway Timeout status code indicates that a server acting as a gateway or proxy did not receive a timely response from an upstream server it needed to access in order to complete the request.
In simpler terms: "I (the gateway) asked another server for help, but that server took too long to answer me, so I'm giving up and telling you there's a problem."
A typical 504 response is quite minimal:
HTTP/1.1 504 Gateway TimeoutContent-Type: text/htmlContent-Length: 125
<html><head><title>504 Gateway Timeout</title></head><body><center><h1>504 Gateway Timeout</h1></center></body></html>
Unlike some other errors, there's usually no custom body because the gateway itself is often a simple piece of infrastructure that doesn't know how to generate fancy error pages.
Think of it like this:
You ask your friend to check if a restaurant is open. Your friend calls the restaurant, but no one picks up. After waiting a while, your friend tells you:
“Sorry, they didn’t answer I got a timeout.”
That’s exactly what happens with a 504 Gateway Timeout.
The gateway (usually a reverse proxy like NGINX or a load balancer) tries to connect to an upstream server (like your web app or database). If that upstream server takes too long to respond, the gateway throws a 504 and aborts the request.
The Chain of Responsibility: How a 504 Happens
Let's walk through a concrete example using a common e-commerce architecture.
1. The Request: A user searches for a product. Their browser sends a request to https://shop.example.com/search?q=laptop.
2. The Load Balancer's Role: The request first hits a load balancer (the gateway). The load balancer's job is to forward this request to one of several available application servers. The load balancer has a timeout setting of, say, 30 seconds.
3. The Application Server's Task: The application server receives the request. To fulfill it, it needs to call two other services:
- It calls the Search Service to get product results.
- It calls the User Profile Service to get personalized recommendations.
4. The Problem: The User Profile Service is experiencing high load or a database deadlock. It gets stuck and doesn't respond.
5. The Timeout: The application server waits... 25 seconds... 28 seconds... 29 seconds... The load balancer, still waiting for a response from the application server, hits its 30-second timeout limit.
6. The 504 Response: The load balancer gives up. It can't return the search results because it never received them from the application server. So it returns a 504 Gateway Timeout to the user's browser.
The crucial insight here is that the application server might still be working, trying to get a response from the User Profile Service. But the load balancer has already called off the request from its perspective.
When to Expect a 504
504s are most common in scenarios where:
- Your application relies on multiple downstream services or microservices.
- The upstream service is temporarily unavailable due to maintenance or high load.
- A third-party API or database is slow or unresponsive.
- Network paths experience transient latency or packet loss.
Because 504 is usually temporary, retry strategies and circuit breakers often come into play as part of a robust resilience plan.
When a 504 Might Be Acceptable
There are legitimate cases where a gateway timeout is expected or acceptable:
- Maintenance windows where upstream services are intentionally slowed or offline.
- Temporary spikes in traffic that upstream services can’t absorb immediately.
- Intermittent dependency issues that are being rolled back or mitigated.
In these cases, transparent communication and well-designed retry policies help minimize user impact.
Real-Life Example of a 504 Gateway Timeout
Imagine you’re building an e-commerce website. Your checkout process calls multiple APIs payment, inventory, shipping, and user authentication.
Now, if the payment API suddenly slows down or becomes unavailable, your server (which acts as a gateway) waits for a response. If it doesn’t get one within the timeout limit (say, 30 seconds), it throws:
504 Gateway Timeout
To users, it looks like your website is broken. But technically, the problem lies in the communication chain between services.
504 vs. Other 5xx Errors: Knowing the Difference
It's easy to mix up server errors, but each tells a different story about what went wrong.
504 Gateway Timeout vs. 502 Bad Gateway:
504means "The upstream server took too long to respond." (Timeout issue)502means "The upstream server sent me back something invalid or garbage." (The response was malformed, or the connection was refused entirely).
504 Gateway Timeout vs. 500 Internal Server Error:
504occurs at the infrastructure level between servers.500occurs at the application level inside your code (e.g., an unhandled exception in your Python or JavaScript code).
504 Gateway Timeout vs. 408 Request Timeout:
504is a server-side timeout: a gateway timed out waiting for another server.408is a client-side timeout: a server timed out waiting for the client to send the complete request.
Common Causes of 504 Gateway Timeout
Understanding the causes is the first step toward prevention and resolution.
1. Overloaded Backend Servers
This is the most common cause. Your application servers might be under heavy load, causing them to respond slowly or not at all. This could be due to:
- A traffic spike
- Inefficient database queries
- Insufficient server resources (CPU, RAM)
2. Network Issues
Connectivity problems between your gateway and your backend servers can cause timeouts.
- Network congestion
- Firewall rules blocking traffic
- DNS resolution problems
3. Resource-Intensive Operations
Some operations naturally take a long time:
- Generating complex reports
- Processing large file uploads
- Running machine learning inference
If these operations exceed your gateway's timeout threshold, they'll cause 504 errors.
4. Service Dependencies
If your application depends on external APIs or microservices that are slow or down, your application server will wait for them, potentially triggering the gateway timeout.
5. Misconfigured Timeouts
Sometimes the timeouts are simply set too low. A gateway might have a 10-second timeout, but a legitimate complex operation might take 15 seconds.
Testing and Debugging APIs with Apidog
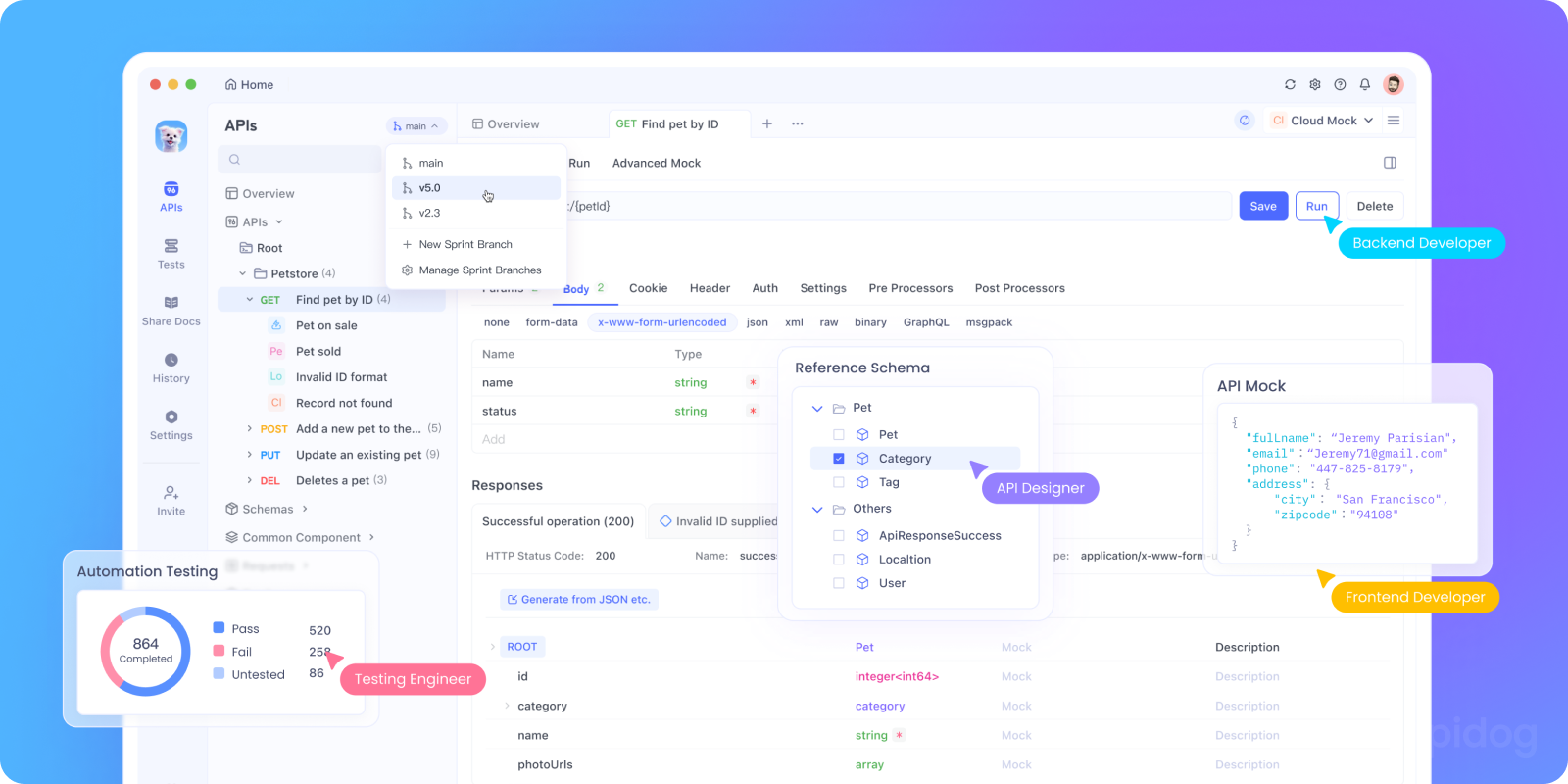
Identifying the root cause of intermittent 504 errors can be like finding a needle in a haystack. When debugging 504s, developers often struggle with visibility figuring out which server, service, or request is to blame. Apidog provides several features that make this much easier.
With Apidog, you can:
- Performance Testing: Use Apidog to send multiple concurrent requests to your API and measure response times. This can help you identify if certain endpoints are slow under load, which could lead to 504s.
- Set Up Monitoring: Create automated monitors in Apidog that periodically check your endpoints. If a request takes longer than a threshold you set (e.g., 25 seconds when your gateway timeout is 30), Apidog can alert you before users start seeing 504s.
- Test Service Dependencies: If your API calls other services, use Apidog to test those dependencies independently. This helps you isolate whether the problem is in your application or in a downstream service.
- Simulate Slow Responses: Use Apidog's mock servers to simulate slow backend responses. This lets you test how your gateway and application handle timeouts without actually overloading your production system.
- Document Timeout Expectations: Use Apidog's documentation features to note which endpoints are expected to be long-running, helping your team set appropriate timeout values in the infrastructure.
And yes, you can download Apidog for free. It's not just another Postman alternative it’s a full ecosystem for API design, testing, and performance monitoring.
Troubleshooting and Fixing 504 Errors
Immediate Steps:
- Check Server Resources: Look at CPU, memory, and disk I/O on your application servers.
- Review Logs: Check your application and gateway logs for errors around the time the 504s occurred.
- Verify External Dependencies: Ensure any third-party APIs or services your application uses are healthy.
Long-Term Solutions:
- Optimize Application Performance: Identify and fix slow database queries, optimize code, and implement caching.
- Adjust Timeout Settings: Increase timeout values on your gateway if you have legitimate long-running operations.
- Implement Circuit Breakers: Use patterns that stop calling a failing service after multiple failures, preventing cascading timeouts.
- Scale Your Infrastructure: Add more application servers or upgrade to more powerful instances.
- Implement Asynchronous Processing: For long-running tasks, use a job queue (like Redis Queue or AWS SQS) and return immediately with a
202 Accepted, then notify the user when the task is complete.
Best Practices To Prevent 504 Errors Long-Term
Let’s wrap up the technical part with some preventive strategies that’ll save you headaches down the road.
1. Use Caching Wherever Possible
Caching responses (at the app, CDN, or proxy level) reduces backend load and response time.
2. Optimize Database Queries
Poorly optimized SQL queries often cause backend bottlenecks tune indexes and avoid large joins.
3. Monitor API Health
Use tools like Apidog, Datadog, or Pingdom to monitor API uptime and performance continuously.
4. Implement Circuit Breakers
Add a circuit breaker pattern in your API to temporarily halt requests to failing services.
5. Scale Automatically
Use auto-scaling in cloud environments like AWS or Azure to handle sudden traffic surges.
6. Log Everything
Centralized logging helps you detect slow endpoints before they become full-blown outages.
The Human Side: Communication During Outages
Transparent communication during gateway timeouts matters. Inform users when a service is experiencing delays, offer an expected recovery time if possible, and provide status updates. A well-managed incident response plan reduces user frustration and builds trust.
Architectural Patterns to Mitigate Gateways
- Service mesh with timeout policies: Centralize timeout configurations and failure handling.
- Timeouts per hop: Configure appropriate timeouts at each hop in the request chain to prevent long waits.
- Backpressure and queueing: Buffer requests during congestion to smooth spikes.
- Canary deployments: Roll out changes gradually to reduce the risk of widespread upstream delays.
- Redundant upstreams: Provide alternative services to reduce single points of failure.
These patterns help you contain the impact of upstream delays and keep user experience intact.
Conclusion: The Price of Distributed Systems
The HTTP 504 Gateway Timeout status code is a natural consequence of the modern, distributed web architecture. While frustrating for users, it serves an important purpose: preventing requests from hanging indefinitely and ensuring the overall system remains responsive.
Understanding that a 504 is fundamentally a communication problem between servers not necessarily an application bug is the key to effective troubleshooting. By monitoring performance, optimizing slow operations, and properly configuring your infrastructure, you can minimize these errors and provide a better experience for your users.
The next time you see a 504 error, you'll know it's a story of a patient gateway server that eventually had to give up waiting. And when you're building the systems that need to avoid these timeouts, a tool like Apidog can be your best ally in identifying performance bottlenecks and ensuring your APIs respond in a timely manner.


