The Qwen team at Alibaba Cloud has released two powerful additions to their large language model (LLM) lineup: Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507. These models bring significant advancements in reasoning, instruction following, and long-context understanding, with native support for a 256K token context length. Designed for developers, researchers, and AI enthusiasts, these models offer robust capabilities for tasks ranging from coding to complex problem-solving. Additionally, tools like Apidog, a free API management platform, can streamline testing and integration of these models into your applications.
Understanding the Qwen3-4B Models
The Qwen3 series represents the latest evolution in Alibaba Cloud’s large language model family, succeeding the Qwen2.5 series. Specifically, Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507 are tailored for distinct use cases: the former excels in general-purpose dialogue and instruction following, while the latter is optimized for complex reasoning tasks. Both models support a native context length of 262,144 tokens, enabling them to process extensive datasets, long documents, or multi-turn conversations with ease. Moreover, their compatibility with frameworks like Hugging Face Transformers and deployment tools like Apidog makes them accessible for both local and cloud-based applications.
Qwen3-4B-Instruct-2507: Optimized for Efficiency
The Qwen3-4B-Instruct-2507 model operates in non-thinking mode, focusing on efficient, high-quality responses for general-purpose tasks. This model has been fine-tuned to enhance instruction following, logical reasoning, text comprehension, and multilingual capabilities. Notably, it does not generate <think></think> blocks, making it ideal for scenarios where quick, direct answers are preferred over step-by-step reasoning.
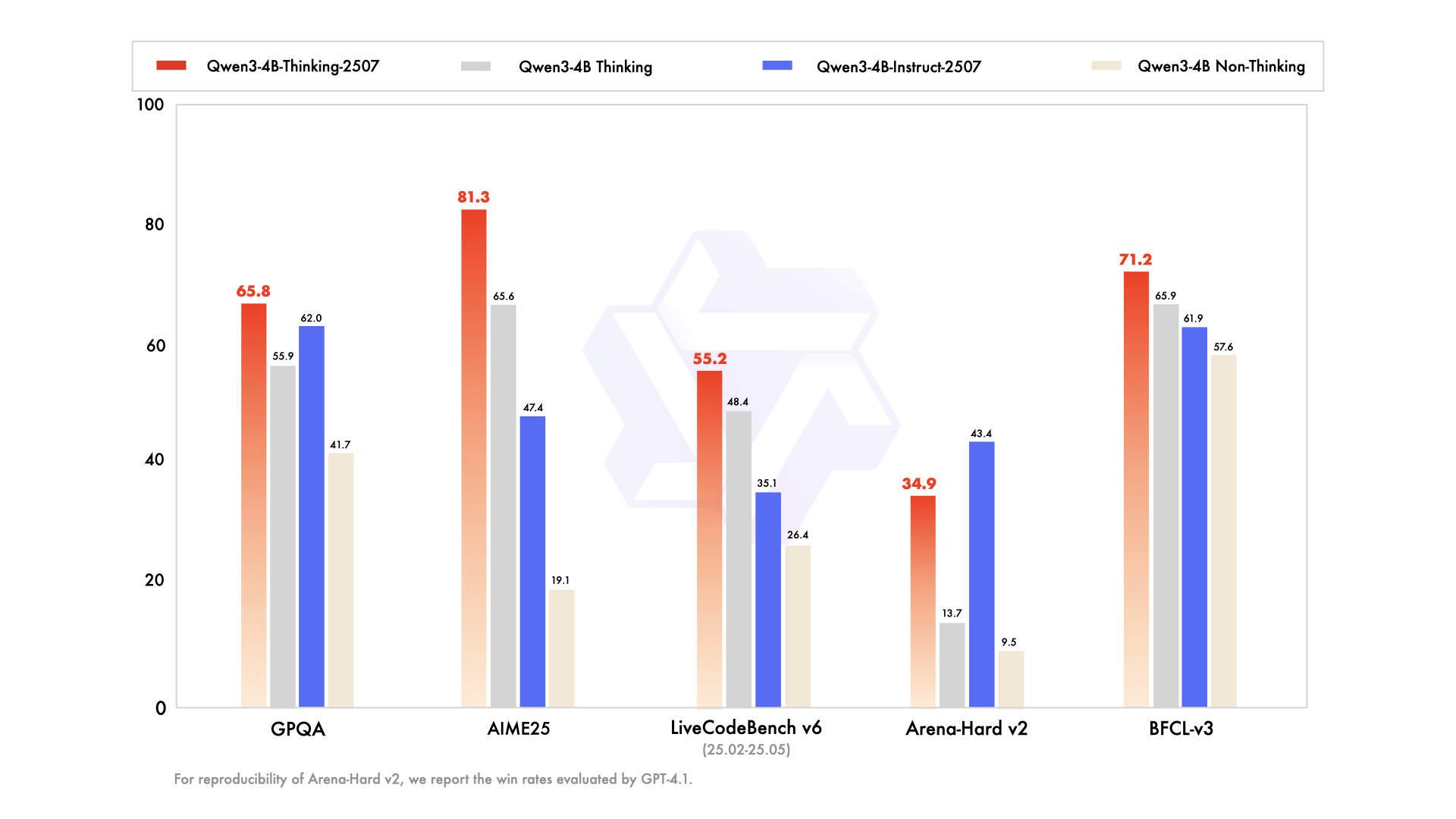
Key enhancements include:
- Improved General Capabilities: The model demonstrates superior performance in mathematics, science, coding, and tool usage, making it versatile for technical applications.
- Multilingual Support: It covers over 100 languages and dialects, ensuring robust performance in global applications.
- Long-Context Understanding: With a 256K token context length, it handles extended inputs, such as legal documents or lengthy codebases, without truncation.
- Alignment with User Preferences: The model delivers more natural and engaging responses, excelling in creative writing and multi-turn dialogues.
For developers integrating this model into APIs, Apidog provides a user-friendly interface to test and manage API endpoints, ensuring seamless deployment. This efficiency makes Qwen3-4B-Instruct-2507 a go-to choice for applications requiring rapid, accurate responses.
Qwen3-4B-Thinking-2507: Built for Deep Reasoning
In contrast, Qwen3-4B-Thinking-2507 is designed for tasks demanding intensive reasoning, such as logical problem-solving, mathematics, and academic benchmarks. This model operates exclusively in thinking mode, automatically incorporating chain-of-thought (CoT) processes to break down complex problems. Its output may include a closing </think> tag without an opening <think> tag, as the default chat template embeds thinking behavior.
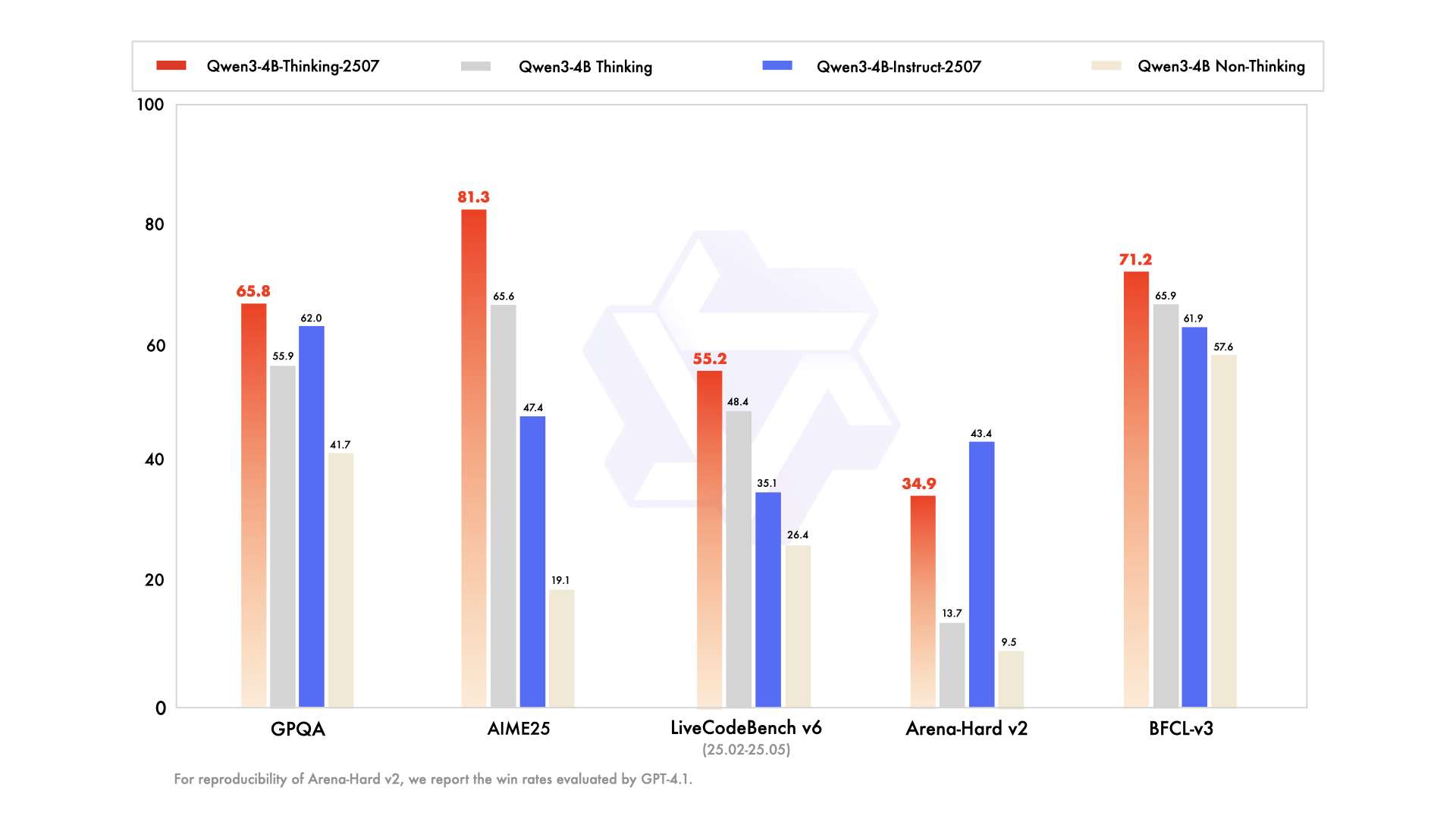
Key enhancements include:
- Advanced Reasoning Capabilities: The model achieves state-of-the-art results among open-source thinking models, particularly in STEM fields and coding.
- Increased Thinking Depth: It excels in tasks requiring human-expert-level reasoning, with an extended thinking length for thorough analysis.
- 256K Context Length: Like its Instruct counterpart, it supports massive context windows, ideal for processing large datasets or intricate queries.
- Tool Integration: The model leverages tools like Qwen-Agent for streamlined agentic workflows, enhancing its utility in automated systems.
For developers working with reasoning-intensive applications, Apidog can facilitate API testing, ensuring that the model’s outputs align with expected results. This model is particularly suited for research environments and complex problem-solving scenarios.
Technical Specifications and Architecture
Both Qwen3-4B models are part of the Qwen3 family, which includes dense and mixture-of-experts (MoE) architectures. The 4B designation refers to their 4 billion parameters, striking a balance between computational efficiency and performance. Consequently, these models are accessible on consumer-grade hardware, unlike larger models like Qwen3-235B-A22B, which require substantial resources.
Architecture Highlights
- Dense Model Design: Unlike MoE models, Qwen3-4B models use a dense architecture, ensuring consistent performance across tasks without the need for selective parameter activation.
- YaRN for Context Extension: The models leverage YaRN to extend their context length from 32,768 to 262,144 tokens, enabling long-context processing without significant performance degradation.
- Training Pipeline: The Qwen team employed a four-stage training process, including long chain-of-thought cold start, reasoning-based reinforcement learning, thinking mode fusion, and general reinforcement learning. This approach enhances both reasoning and dialogue capabilities.
- Quantization Support: Both models support FP8 quantization, reducing memory requirements while maintaining accuracy. For example, Qwen3-4B-Thinking-2507-FP8 is available for resource-constrained environments.
Hardware Requirements
To run these models efficiently, consider the following:
- GPU Memory: A minimum of 8GB VRAM is recommended for FP8-quantized models, while bfloat16 models may require 16GB or more.
- RAM: For optimal performance, 16GB of unified memory (VRAM + RAM) is sufficient for most tasks.
- Inference Frameworks: Both models are compatible with Hugging Face Transformers (version ≥4.51.0), vLLM (≥0.8.5), and SGLang (≥0.4.6.post1). Local tools like Ollama and LMStudio also support Qwen3.
For developers deploying these models, Apidog simplifies the process by providing tools to monitor and test API performance, ensuring efficient integration with inference frameworks.
Integration with Hugging Face and ModelScope
The Qwen3-4B models are available on both Hugging Face and ModelScope, offering flexibility for developers. Below, we provide a code snippet to demonstrate how to use Qwen3-4B-Instruct-2507 with Hugging Face Transformers.


from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)For Qwen3-4B-Thinking-2507, additional parsing is required to handle thinking content:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)These snippets demonstrate the ease of integrating Qwen models into Python workflows. For API-based deployments, Apidog can help test these endpoints, ensuring reliable performance.
Performance Optimization and Best Practices
To maximize the performance of Qwen3-4B models, consider the following recommendations:
- Sampling Parameters: For Qwen3-4B-Instruct-2507, use
temperature=0.7,top_p=0.8,top_k=20, andmin_p=0. For Qwen3-4B-Thinking-2507, usetemperature=0.6,top_p=0.95,top_k=20, andmin_p=0. Avoid greedy decoding to prevent performance degradation. - Context Length Management: If encountering out-of-memory issues, reduce the context length to 32,768 tokens. However, for reasoning tasks, maintain a context length above 131,072 tokens.
- Presence Penalty: Set
presence_penaltybetween 0 and 2 to reduce repetitions, but avoid high values to prevent language mixing. - Inference Frameworks: Use vLLM or SGLang for high-throughput inference, and leverage Apidog to monitor API performance.
Comparing Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507
While both models share the same 4 billion parameter architecture, their design philosophies differ:
- Qwen3-4B-Instruct-2507: Prioritizes speed and efficiency, making it suitable for chatbots, customer support, and general-purpose applications.
- Qwen3-4B-Thinking-2507: Focuses on deep reasoning, ideal for academic research, complex problem-solving, and tasks requiring chain-of-thought processes.
Developers can switch between modes using /think and /no_think prompts, allowing flexibility based on task requirements. Apidog can assist in testing these mode switches in API-driven applications.
Community and Ecosystem Support
The Qwen3-4B models benefit from a robust ecosystem, with support from Hugging Face, ModelScope, and tools like Ollama, LMStudio, and llama.cpp. The open-source nature of these models, licensed under Apache 2.0, encourages community contributions and fine-tuning. For instance, Unsloth provides tools for 2x faster fine-tuning with 70% less VRAM, making these models accessible to a broader audience.
Conclusion
The Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507 models mark a significant leap in Alibaba Cloud’s Qwen series, offering unmatched capabilities in instruction following, reasoning, and long-context processing. With a 256K token context length, multilingual support, and compatibility with tools like Apidog, these models empower developers to build intelligent, scalable applications. Whether you’re generating code, solving equations, or creating multilingual chatbots, these models deliver exceptional performance. Start exploring their potential today, and use Apidog to streamline your API integrations for a seamless development experience.