
Today is another great day for the open-source AI community, in particular, thrives on these moments, eagerly deconstructing, testing, and building upon the new state-of-the-art. In July 2025, Alibaba's Qwen team triggered one such event with the launch of its Qwen3 series, a powerful new family of models poised to redefine performance benchmarks. At the heart of this release lies a fascinating and highly specialized variant: Qwen3-235B-A22B-Thinking-2507.
This model is not just another incremental update; it represents a deliberate and strategic step towards creating AI systems with profound reasoning capabilities. Its name alone is a declaration of intent, signaling a focus on logic, planning, and multi-step problem-solving. This article offers a deep dive into the architecture, purpose, and potential impact of Qwen3-Thinking, examining its place within the broader Qwen3 ecosystem and what it signifies for the future of AI development.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!
The Qwen3 Family: A Multi-Faceted Assault on the State-of-the-Art
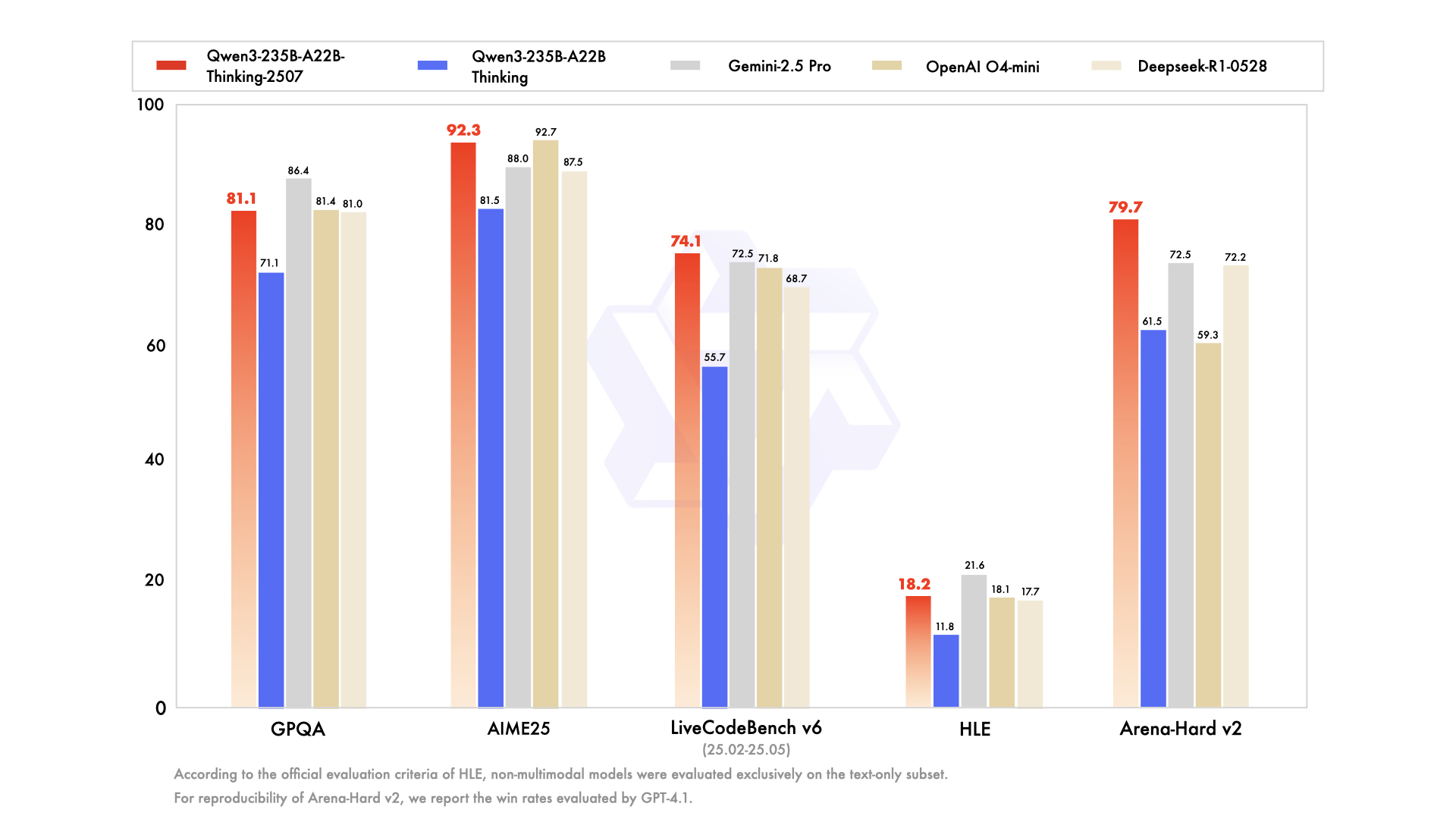
To understand the Thinking model, one must first appreciate the context of its birth. It did not arrive in isolation but as part of a comprehensive and strategically diverse Qwen3 model family. The Qwen series has already cultivated a massive following, with a history of downloads numbering in the hundreds of millions and fostering a vibrant community that has created over 100,000 derivative models on platforms like Hugging Face.
The Qwen3 series includes several key variants, each tailored for different domains:
- Qwen3-Instruct: A general-purpose instruction-following model designed for a wide array of conversational and task-oriented applications. The
Qwen3-235B-A22B-Instruct-2507variant, for example, is noted for its enhanced alignment with user preferences in open-ended tasks and broad knowledge coverage. - Qwen3-Coder: A series of models explicitly designed for agentic coding. The most powerful of these, a massive 480-billion parameter model, sets a new standard for open-source code generation and software development automation. It even comes with a command-line tool, Qwen Code, to better harness its agentic abilities.
- Qwen3-Thinking: The focus of our analysis, specialized for complex cognitive tasks that go beyond simple instruction-following or code generation.
This family approach demonstrates a sophisticated strategy: instead of a single, monolithic model trying to be a jack-of-all-trades, Alibaba is providing a suite of specialized tools, allowing developers to choose the right foundation for their specific needs.
Let's Talk About the Thinking Part of Qwen3-235B-A22B-Thinking-2507
The model's name, Qwen3-235B-A22B-Thinking-2507, is dense with information that reveals its underlying architecture and design philosophy. Let's break it down piece by piece.
Qwen3: This signifies that the model belongs to the third generation of the Qwen series, building upon the knowledge and advancements of its predecessors.235B-A22B(Mixture of Experts - MoE): This is the most crucial architectural detail. The model is not a dense 235-billion parameter network, where every parameter is used for every single calculation. Instead, it employs a Mixture-of-Experts (MoE) architecture.Thinking: This suffix denotes the model's specialization, fine-tuned on data rewarding logical deduction and step-by-step analysis.2507: This is a versioning tag, likely standing for July 2025, indicating the model's release or training completion date.
The MoE architecture is the key to this model's combination of power and efficiency. It can be thought of as a large team of specialized "experts"—smaller neural networks—managed by a "gating network" or "router." For any given input token, the router dynamically selects a small subset of the most relevant experts to process the information.
In the case of Qwen3-235B-A22B, the specifics are:
- Total Parameters (
235B): This represents the vast repository of knowledge distributed across all the available experts. The model contains a total of 128 distinct experts. - Active Parameters (
A22B): For any single inference pass, the gating network selects 8 experts to activate. The combined size of these active experts is approximately 22 billion parameters.
The benefits of this approach are immense. It allows the model to possess the vast knowledge, nuance, and capabilities of a 235B-parameter model while having the computational cost and inference speed closer to a much smaller 22B-parameter dense model. This makes deploying and running such a large model more feasible without sacrificing its depth of knowledge.
Technical Specifications and Performance Profile
Beyond the high-level architecture, the model's detailed specifications paint a clearer picture of its capabilities.
- Model Architecture: Mixture-of-Experts (MoE)
- Total Parameters: ~235 Billion
- Active Parameters: ~22 Billion per token
- Number of Experts: 128
- Experts Activated per Token: 8
- Context Length: The model supports a 128,000-token context window. This is a massive improvement that allows it to process and reason over extremely long documents, entire codebases, or lengthy conversational histories without losing track of crucial information from the beginning of the input.
- Tokenizer: It utilizes a custom Byte Pair Encoding (BPE) tokenizer with a vocabulary of over 150,000 tokens. This large vocabulary size is indicative of its strong multilingual training, allowing it to efficiently encode text from a wide range of languages, including English, Chinese, German, Spanish, and many others, as well as programming languages.
- Training Data: While the exact composition of the training corpus is proprietary, a
Thinkingmodel is certainly trained on a specialized mix of data designed to foster reasoning. This dataset would go far beyond standard web text and would likely include: - Academic and Scientific Papers: Large volumes of text from sources like arXiv, PubMed, and other research repositories to absorb complex scientific and mathematical reasoning.
- Logical and Mathematical Datasets: Datasets like GSM8K (Grade School Math) and the MATH dataset, which contain word problems requiring step-by-step solutions.
- Programming and Code Problems: Datasets like HumanEval and MBPP, which test logical reasoning through code generation.
- Philosophical and Legal Texts: Documents that require understanding dense, abstract, and highly structured logical arguments.
- Chain-of-Thought (CoT) Data: Synthetically generated or human-curated examples where the model is explicitly shown how to "think step-by-step" to arrive at an answer.
This curated data mix is what separates the Thinking model from its Instruct sibling. It is not just trained to be helpful; it is trained to be rigorous.
The Power of "Thinking": A Focus on Complex Cognition
The promise of the Qwen3-Thinking model lies in its ability to tackle problems that have historically been major challenges for large language models. These are tasks where simple pattern matching or information retrieval is insufficient. The "Thinking" specialization suggests proficiency in areas such as:
- Multi-Step Reasoning: Solving problems that require breaking down a query into a sequence of logical steps. For example, calculating the financial implications of a business decision based on multiple market variables or planning the trajectory of a projectile given a set of physical constraints.
- Logical Deduction: Analyzing a set of premises and drawing a valid conclusion. This could involve solving a logic grid puzzle, identifying logical fallacies in a piece of text, or determining the consequences of a set of rules in a legal or contractual context.
- Strategic Planning: Devising a sequence of actions to achieve a goal. This has applications in complex game-playing (like chess or Go), business strategy simulations, supply chain optimization, and automated project management.
- Causal Inference: Attempting to identify cause-and-effect relationships within a complex system described in text, a cornerstone of scientific and analytical reasoning that models often struggle with.
- Abstract Reasoning: Understanding and manipulating abstract concepts and analogies. This is essential for creative problem-solving and true human-level intelligence, moving beyond concrete facts to the relationships between them.
The model is designed to excel on benchmarks that specifically measure these advanced cognitive abilities, such as MMLU (Massive Multitask Language Understanding) for general knowledge and problem-solving, and the aforementioned GSM8K and MATH for mathematical reasoning.
Accessibility, Quantization, and Community Engagement
A model's power is only meaningful if it can be accessed and utilized. Staying true to its open-source commitment, Alibaba has made the Qwen3 family, including the Thinking variant, widely available on platforms like Hugging Face and ModelScope.
Recognizing the significant computational resources required to run a model of this scale, quantized versions are also available. The Qwen3-235B-A22B-Thinking-2507-FP8 model is a prime example. FP8 (8-bit floating point) is a cutting-edge quantization technique that dramatically reduces the model's memory footprint and increases inference speed.
Let's break down the impact:
- A 235B parameter model in standard 16-bit precision (BF16/FP16) would require over 470 GB of VRAM, a prohibitive amount for all but the largest enterprise-grade server clusters.
- The FP8 quantized version, however, reduces this requirement to under 250 GB. While still substantial, this brings the model into the realm of possibility for research institutions, startups, and even individuals with multi-GPU workstations equipped with high-end consumer or prosumer hardware.
This makes advanced reasoning accessible to a much broader audience. For enterprise users who prefer managed services, the models are also being integrated into Alibaba's cloud platforms. API access through Model Studio and integration into Alibaba's flagship AI assistant, Quark, ensures that the technology can be leveraged at any scale.
Conclusion: A New Tool for a New Class of Problems
The release of Qwen3-235B-A22B-Thinking-2507 is more than just another point on the ever-climbing graph of AI model performance. It is a statement about the future direction of AI development: a shift from monolithic, general-purpose models towards a diverse ecosystem of powerful, specialized tools. By employing an efficient Mixture-of-Experts architecture, Alibaba has delivered a model with the vast knowledge of a 235-billion parameter network and the relative computational friendliness of a 22-billion parameter one.
By explicitly fine-tuning this model for "Thinking," the Qwen team provides the world with a tool dedicated to cracking the toughest analytical and reasoning challenges. It has the potential to accelerate scientific discovery by helping researchers analyze complex data, empower businesses to make better strategic decisions, and serve as a foundational layer for a new generation of intelligent applications that can plan, deduce, and reason with unprecedented sophistication. As the open-source community begins to fully explore its depths, Qwen3-Thinking is set to become a critical building block in the ongoing quest for more capable and truly intelligent AI.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!


