
Qwen, the open foundation model initiative from Alibaba, consistently pushes the boundaries of artificial intelligence through rapid iterations and releases. Developers and researchers eagerly anticipate each update, as Qwen models often set new standards in performance and versatility. Recently, Qwen dropped three innovative models: Qwen-Image-Edit-2509, Qwen3-TTS-Flash, and Qwen3-Omni. These releases enhance capabilities in image editing, text-to-speech synthesis, and omni-modal processing, respectively.
Furthermore, these models arrive at a pivotal moment in AI development, where multimodal integration becomes essential for practical applications. Qwen-Image-Edit-2509 addresses the demand for precise visual manipulations, while Qwen3-TTS-Flash tackles latency issues in voice generation. Meanwhile, Introducing Qwen3-Omni unifies diverse inputs into a cohesive framework. Together, they demonstrate Qwen's commitment to accessible, high-performance AI. However, understanding their technical underpinnings requires a closer examination. This article dissects each model, highlighting features, architectures, benchmarks, and potential impacts.
Qwen-Image-Edit-2509: Elevating Image Editing Precision
Qwen-Image-Edit-2509 represents a significant advancement in AI-driven image manipulation. Engineers at Qwen rebuilt this model to cater to creators, designers, and developers who require granular control over visual content. Unlike previous iterations, this version supports multi-image editing, enabling users to combine elements such as a person with a product or a scene effortlessly. Consequently, it eliminates common artifacts like mismatched blends, producing coherent outputs.

The model excels in single-image consistency. It preserves facial identities across poses, styles, and filters, which proves invaluable for applications in advertising and personalization. For product images, Qwen-Image-Edit-2509 maintains object integrity, ensuring that edits do not distort key attributes. Additionally, it handles text elements comprehensively, allowing modifications to content, fonts, colors, and even textures. This versatility stems from integrated ControlNet mechanisms, which incorporate depth maps, edge detection, and keypoints for precise guidance.
Technically, Qwen-Image-Edit-2509 builds upon the foundational Qwen-Image architecture but incorporates advanced training techniques. Developers trained it using image concatenation methods to facilitate multi-image inputs. For example, combining "person + person" or "person + scene" leverages concatenated data streams, enhancing the model's ability to fuse disparate visuals. Furthermore, the architecture integrates diffusion-based processes, where noise is progressively removed to generate refined images. This approach, common in stable diffusion variants, allows for conditional generation based on user prompts.
In terms of benchmarks, Qwen-Image-Edit-2509 demonstrates superior performance in consistency metrics. Internal evaluations show it outperforming competitors in face preservation, with similarity scores exceeding 95% across diverse edits. Product consistency benchmarks reveal minimal distortion, making it ideal for e-commerce. However, quantitative data from external sources remains limited due to its recent release. Nevertheless, user demonstrations on platforms like Hugging Face highlight its edge over models like Stable Diffusion XL in multi-element blending.
Applications abound for Qwen-Image-Edit-2509. Marketers utilize it to create customized ads by editing product placements seamlessly. Designers employ it for rapid prototyping, altering scenes without manual retouching. Moreover, in gaming, it facilitates dynamic asset generation. One illustrative example involves transforming a person's outfit: an input image of a woman in casual attire, combined with a black dress reference, yields a output where the dress fits naturally, preserving posture and lighting. This capability, as shown in visual demos, underscores its practical utility.


Transitioning to implementation, developers access Qwen-Image-Edit-2509 via GitHub repositories and Hugging Face spaces. Installation typically involves cloning the repo and setting up dependencies like PyTorch. A basic usage script might look like this:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Such code enables quick iterations. However, users must consider computational requirements, as inference demands GPU acceleration for optimal speed.
Despite its strengths, Qwen-Image-Edit-2509 faces challenges. High-resolution edits can consume significant memory, and complex prompts occasionally lead to inconsistencies. Nonetheless, ongoing community contributions via open-source channels mitigate these issues. Overall, this model redefines image editing by combining precision with accessibility.
Qwen3-TTS-Flash: Accelerating Text-to-Speech Synthesis
Qwen3-TTS-Flash emerges as a powerhouse in text-to-speech (TTS) technology, prioritizing speed and naturalness. Qwen engineers designed it to deliver human-like voices with minimal latency, addressing bottlenecks in real-time applications. Specifically, it achieves a first-packet latency of just 97ms in single-threaded environments, enabling fluid interactions in chatbots and virtual assistants.
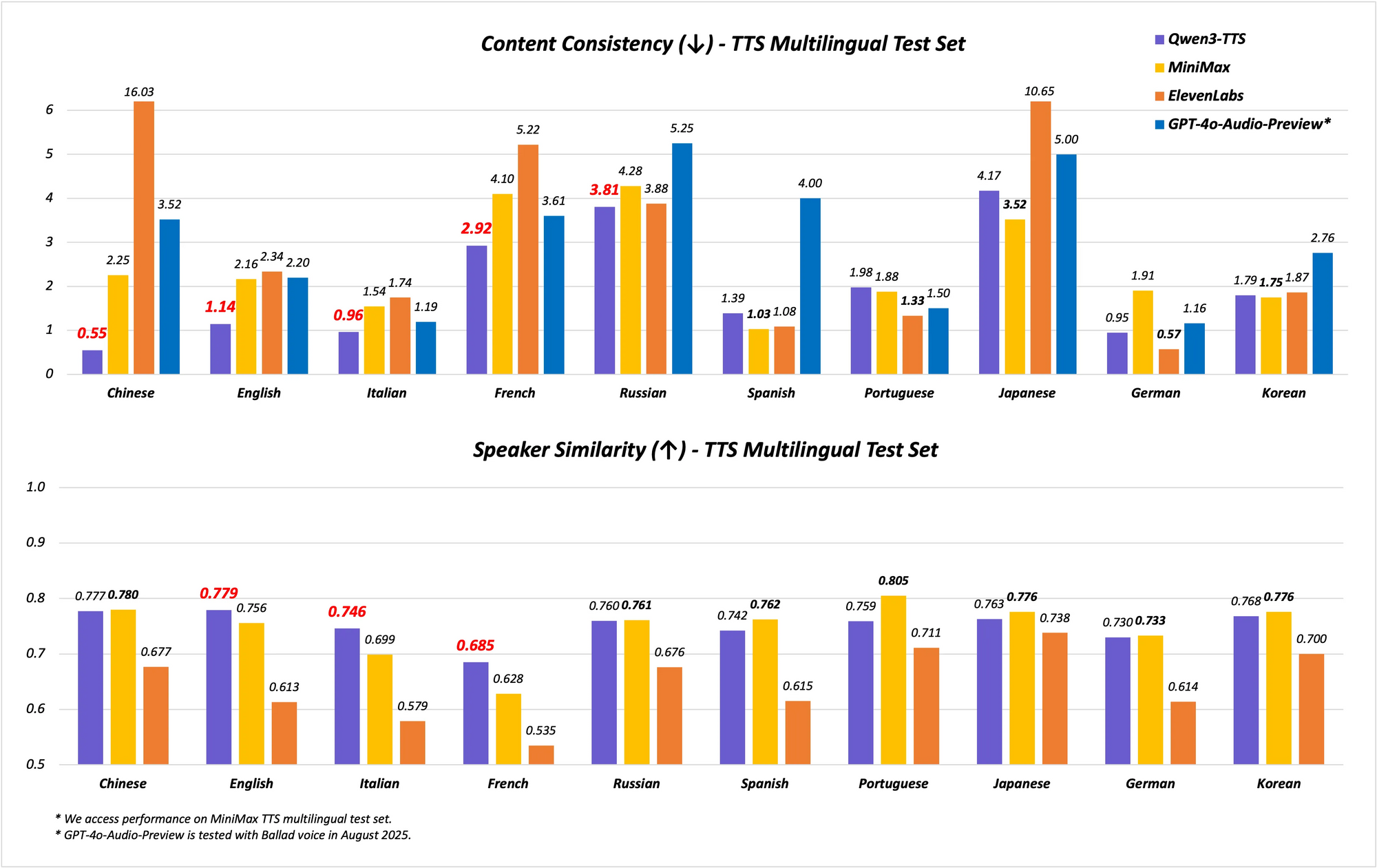
The model supports multilingual and multi-dialect capabilities, covering 10 languages with 17 expressive voices. It excels in Chinese and English stability, achieving state-of-the-art (SOTA) performance on benchmarks like the Seed-TTS-Eval test set. Here, it surpasses models such as SeedTTS, MiniMax, and GPT-4o-Audio-Preview in stability metrics. Furthermore, in multilingual evaluations on the MiniMax TTS test set, Qwen3-TTS-Flash records the lowest Word Error Rate (WER) for Chinese, English, Italian, and French.
Dialect support sets Qwen3-TTS-Flash apart. It handles nine Chinese dialects, including Cantonese, Hokkien, Sichuanese, Beijing, Nanjing, Tianjin, and Shaanxi. This feature allows for culturally nuanced speech, essential in diverse markets. Additionally, the model adapts tones automatically, drawing from large-scale training data to match input sentiment. Robust text handling further enhances reliability, as it extracts key information from complex formats like dates, numbers, and acronyms.
Architecturally, Qwen3-TTS-Flash employs a transformer-based encoder-decoder framework, optimized for low-latency inference. It uses multi-codebook representations for richer voice modeling, improving expressiveness. Training involved vast datasets encompassing 119 languages for text and 19 for speech understanding, though output focuses on 10 languages. This setup enables cross-lingual generation, where inputs in one language produce outputs in another seamlessly.

Benchmarks illustrate its prowess. On stability tests, Qwen3-TTS-Flash scores higher in timbre similarity and naturalness compared to ElevenLabs and GPT-4o. For instance:
| Benchmark | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Chinese Stability | SOTA | Lower | Lower |
| English WER | Lowest | Higher | Higher |
| Multilingual Timbre Similarity | SOTA | Lower | Lower |
These results stem from rigorous evaluations, positioning it as a leader in TTS.
In demonstrations, Qwen3-TTS-Flash generates expressive speech, such as describing a "honey lavender latte" with enthusiasm or handling dialogues in dialects. Video transcripts reveal its ability to process mixed-language inputs, like "I'm really happy today. I know that girl from China," delivered in accented voices. Applications include interactive voice response (IVR) systems, gaming NPCs, and content creation, where low latency doubles efficiency.
Implementation requires accessing the model via APIs or Hugging Face demos. A sample Python invocation:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
This simplicity accelerates development. However, dialect accuracy may vary with rare inputs, necessitating fine-tuning.
Qwen3-TTS-Flash transforms TTS by balancing speed, quality, and diversity, making it indispensable for modern AI systems.
Introducing Qwen3-Omni: The Unified Multimodal Powerhouse
Introducing Qwen3-Omni marks a milestone in multimodal AI, as Qwen integrates text, image, audio, and video into a single end-to-end model. This native unification avoids modality trade-offs, enabling deeper cross-modal reasoning. The model processes 119 languages for text, 19 for speech input, and 10 for speech output, with a remarkable 211ms latency for responses.
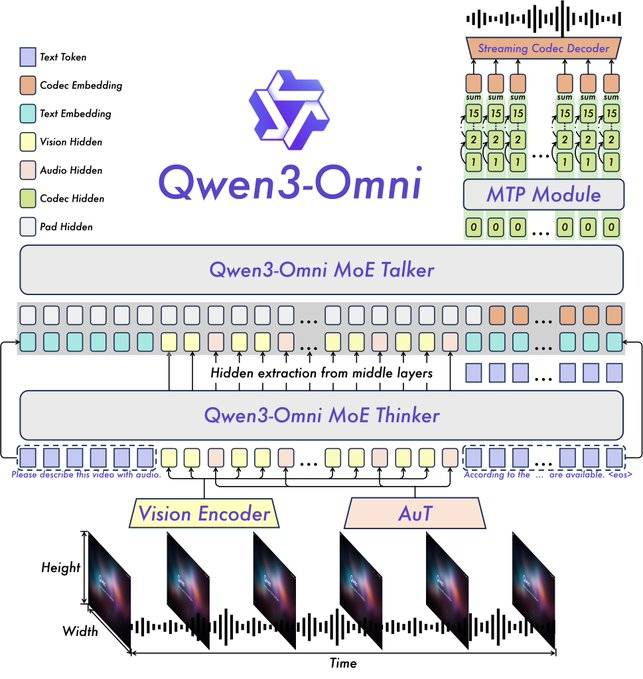
Key features include SOTA performance on 22 out of 36 audio and audio-visual benchmarks, customizable system prompts, built-in tool calling, and an open-source captioner model with low hallucination rates. Qwen open-sourced variants like Qwen3-Omni-30B-A3B-Instruct for instruction-following and Qwen3-Omni-30B-A3B-Thinking for enhanced reasoning.
The architecture builds on the Thinker-Talker framework from Qwen2.5-Omni, with upgrades such as replacing the Whisper audio encoder with an Audio Transformer (AuT) for better representation. Multi-codebook speech handling enriches voice output, while extended context supports over 30 minutes of audio. This allows full-modality reasoning, where video inputs inform audio responses.
Benchmarks confirm its dominance. It achieves overall SOTA on 32 benchmarks, excelling in audio understanding and generation. For example, in audio-visual tasks, it outperforms models like GPT-4o in latency and accuracy. A comparison table:
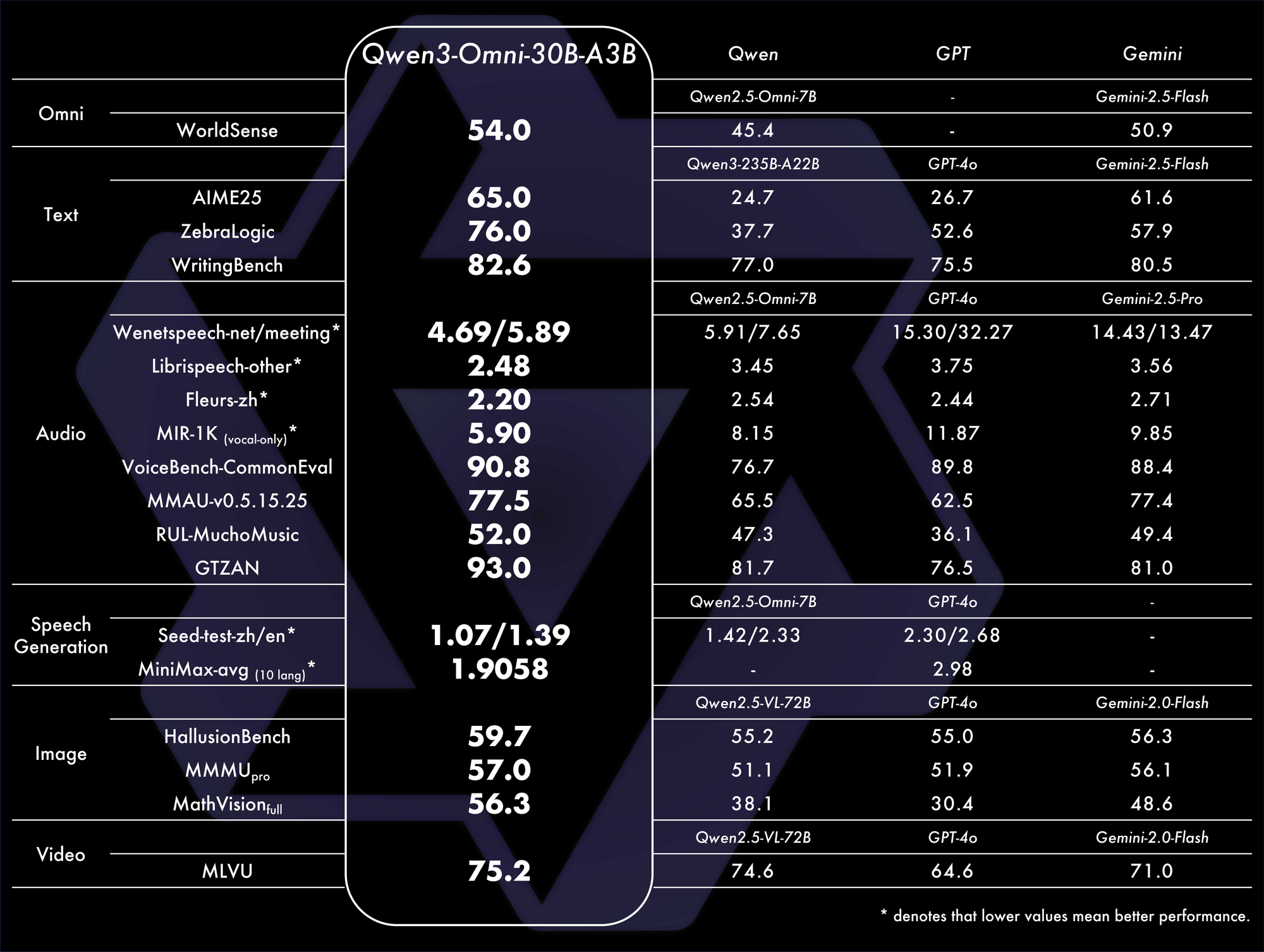
These metrics highlight its efficiency in real-world scenarios.
Applications span voice chat, video analysis, and multimodal agents. For instance, it analyzes a video clip and generates spoken summaries, ideal for accessibility tools. Demos on Qwen Chat showcase voice and video interactions, where users query images or audios verbally.
From GitHub, the README describes it as capable of real-time speech generation from diverse inputs. Setup involves:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
This modular approach facilitates customization. Challenges include high computational demands for video processing, but optimizations like quantization help.
Introducing Qwen3-Omni consolidates modalities, fostering innovative AI ecosystems.
Synergies Among Qwen's New Models and Future Implications
Qwen-Image-Edit-2509, Qwen3-TTS-Flash, and Qwen3-Omni complement each other, enabling end-to-end workflows. For example, edit an image with Qwen-Image-Edit-2509, describe it via Qwen3-Omni, and vocalize the output with Qwen3-TTS-Flash. This integration amplifies utility in content creation and automation.
Moreover, their open-source nature invites community enhancements. Developers using Apidog can test APIs efficiently, ensuring robust integrations.
However, ethical considerations arise, such as misuse in deepfakes. Qwen mitigates this through safeguards.
In conclusion, Qwen's drops redefine AI landscapes. By advancing technical frontiers, they empower users to achieve more. As adoption grows, these models will drive the next wave of innovation.


