Mistral AI engineers designed Magistral Small 1.2 as a 24-billion-parameter model that prioritizes reasoning efficiency. This version builds directly on Mistral Small 1.1 . Engineers applied supervised fine-tuning using traces from Magistral Medium, followed by reinforcement learning stages. Consequently, the model excels in multi-step logic without excessive computational demands.
Understanding the Magistral Model Family Evolution
Architecture Foundation and Technical Specifications
The Magistral Small 1.2 builds upon the robust foundation of Magistral 1.1, incorporating advanced reasoning capabilities through supervised fine-tuning (SFT) from Magistral Medium traces combined with reinforcement learning (RL) optimization. Building upon Magistral 1.1, with added reasoning capabilities, undergoing SFT from Magistral Medium traces and RL on top, it's a small, efficient reasoning model with 24B parameters.

Furthermore, the architectural design enables efficient deployment scenarios. Magistral Small can be deployed locally, fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized. This accessibility makes the model suitable for both enterprise and individual developer environments.
Key Technical Enhancements in Version 1.2
The transition from version 1.1 to 1.2 introduces several critical improvements that significantly impact model performance and usability. Most notably, these updates address fundamental limitations while expanding capability boundaries.
Multimodal Integration Breakthrough
Now equipped with a vision encoder, these models handle both text and images seamlessly. This integration represents a paradigm shift from purely text-based reasoning to comprehensive multimodal understanding. The vision encoder architecture enables the models to process visual information while maintaining their text reasoning capabilities.
Performance Optimization Results
15% improvements on math and coding benchmarks such as AIME 24/25 and LiveCodeBench v5/v6. These performance gains translate directly into practical applications, particularly benefiting developers working on mathematical computation, algorithm development, and complex problem-solving scenarios.

Comprehensive Feature Analysis
Advanced Reasoning Capabilities
The reasoning architecture incorporates specialized thinking tokens that structure the model's internal reasoning process. The implementation uses [THINK] and [/THINK] tokens to encapsulate reasoning content, creating transparency in the model's decision-making process while preventing confusion during prompt processing.
Moreover, the reasoning system operates through extended chains of logical inference before generating final responses. This approach enables the model to tackle complex problems that require multi-step analysis, mathematical derivations, and logical deductions.
Multilingual Support Infrastructure
The models demonstrate comprehensive language support across diverse linguistic families. The supported languages span European, Asian, Middle Eastern, and South Asian regions, including English, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Nepali, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Turkish, Ukrainian, Vietnamese, Arabic, Bengali, Chinese, and Farsi.
Additionally, this extensive multilingual capability ensures global accessibility and enables developers to create applications serving international markets without requiring separate model implementations for different languages.
Vision Processing Architecture
The vision encoder integration enables sophisticated image analysis and reasoning. The model processes visual content and combines it with textual information to generate comprehensive responses. This capability extends beyond simple image recognition to include contextual understanding, spatial reasoning, and visual problem-solving.
Performance Benchmarks and Comparative Analysis
Mathematical Reasoning Performance
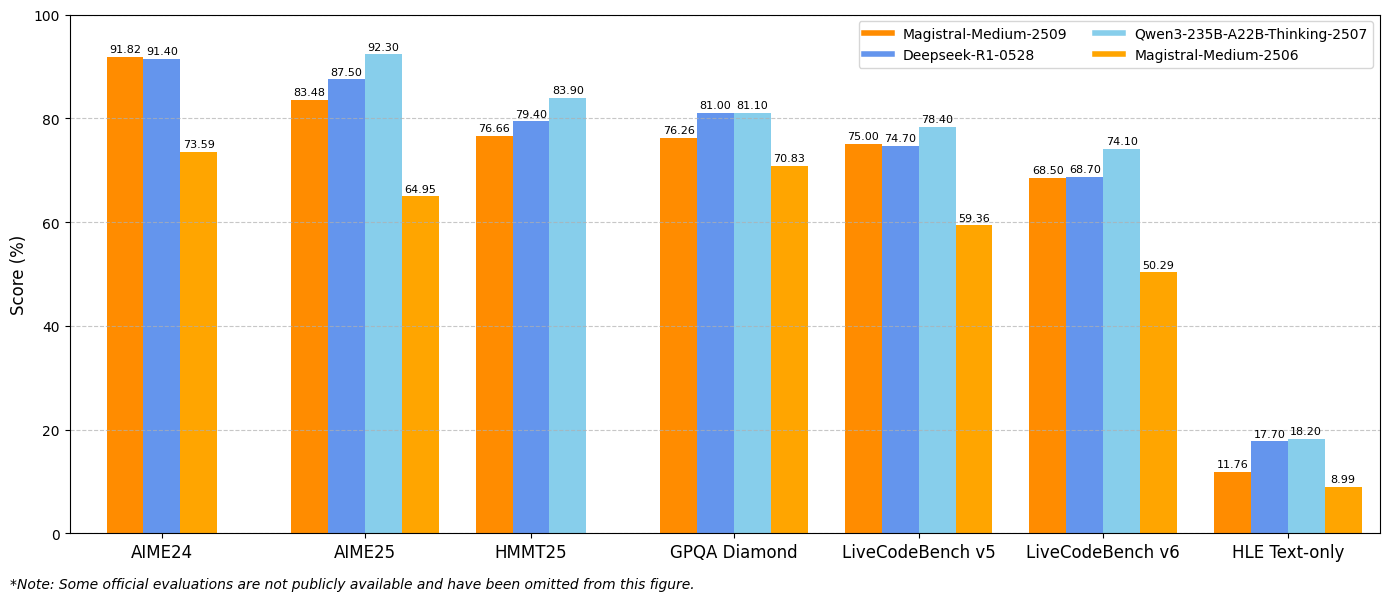
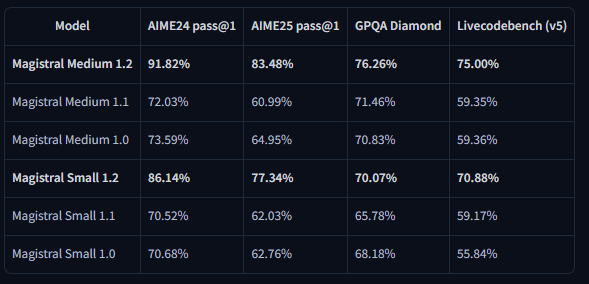
The benchmark results demonstrate substantial improvements across key evaluation metrics. Magistral Small 1.2 achieves 86.14% on AIME24 pass@1 and 77.34% on AIME25 pass@1, representing significant advances over the 1.1 version's 70.52% and 62.03% respectively.
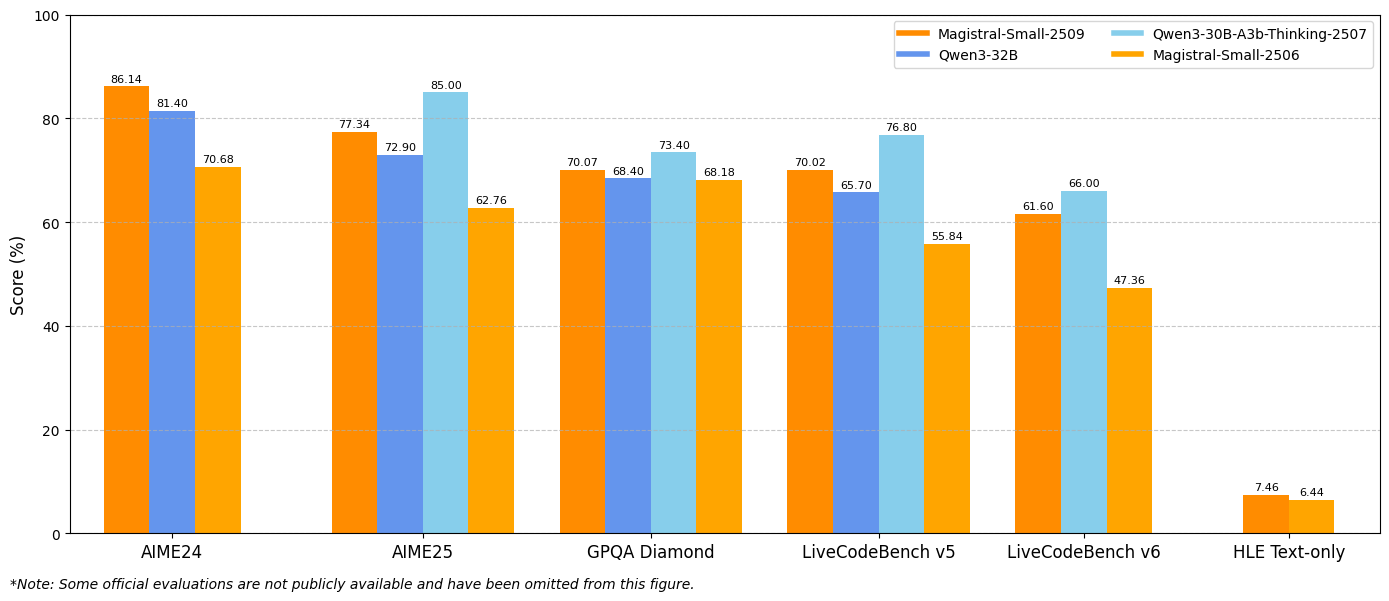
Similarly, Magistral Medium 1.2 delivers exceptional performance with 91.82% on AIME24 pass@1 and 83.48% on AIME25 pass@1, surpassing the 1.1 version's 72.03% and 60.99%. These improvements indicate enhanced mathematical reasoning capabilities that directly benefit scientific computing, engineering applications, and research environments.
Coding Performance Metrics
LiveCodeBench evaluations reveal substantial coding capability improvements. Magistral Small 1.2 scores 70.88% on LiveCodeBench v5, while Magistral Medium 1.2 achieves 75.00%. These scores represent meaningful advances in code generation, debugging, and algorithm implementation tasks.
Furthermore, the models demonstrate improved understanding of programming concepts, software architecture patterns, and debugging methodologies. This enhanced coding performance benefits software development teams, automated testing frameworks, and educational programming environments.
GPQA Diamond Results
The General Purpose Question Answering (GPQA) Diamond benchmark results showcase the models' broad knowledge application capabilities. Magistral Small 1.2 achieves 70.07%, while Magistral Medium 1.2 reaches 76.26%. These scores reflect the models' ability to handle diverse question types requiring interdisciplinary knowledge and reasoning.
Implementation and Integration Strategies
Development Environment Configuration
Implementing Magistral Small 1.2 and Magistral Medium 1.2 requires specific technical configurations to optimize performance. The recommended sampling parameters include top_p: 0.95, temperature: 0.7, and max_tokens: 131072. These settings balance creativity with consistency while supporting extended reasoning sequences.
Additionally, the models support various deployment frameworks including vLLM, Transformers, llama.cpp, and specialized quantization formats. This flexibility enables integration across different computing environments and use cases.
API Integration with Apidog
Apidog provides comprehensive tools for testing and integrating Magistral APIs into your applications. The platform supports advanced API testing scenarios, including multimodal input handling, reasoning trace analysis, and performance monitoring. Through Apidog's interface, developers can efficiently test image-text combinations, validate reasoning outputs, and optimize API call parameters.
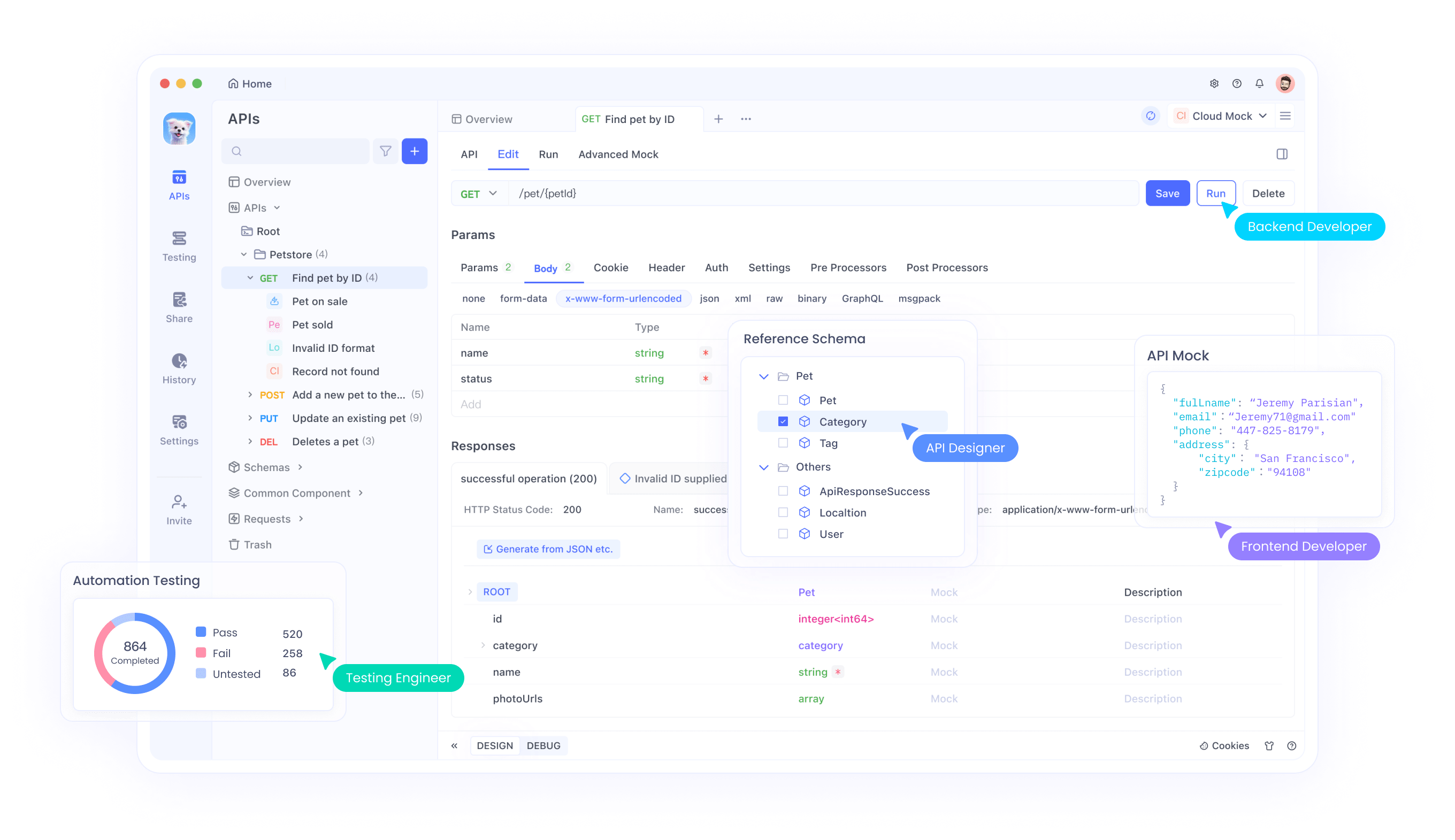
Moreover, Apidog's collaboration features enable teams to share API testing configurations, document integration patterns, and maintain consistent testing standards across development cycles. This collaborative approach accelerates development timelines while ensuring robust API implementations.
System Prompt Optimization
The models require carefully crafted system prompts to achieve optimal performance. The recommended system prompt structure includes reasoning instructions, formatting guidelines, and language specifications. The prompt should explicitly request thinking processes using the specialized tokens while maintaining consistent response formatting.
Furthermore, system prompt customization enables application-specific optimizations. Developers can modify prompts to emphasize particular reasoning patterns, adjust output formats, or incorporate domain-specific knowledge requirements.
Technical Implementation Deep-Dive
Memory and Computational Requirements
Magistral Small 1.2 operates efficiently within constrained hardware environments while maintaining high performance. The 24-billion parameter architecture enables deployment on consumer-grade hardware when properly quantized, making advanced reasoning capabilities accessible to individual developers and small teams.
Moreover, the computational efficiency improvements in version 1.2 reduce inference latency while maintaining reasoning quality. This optimization enables real-time applications and interactive systems that require immediate response generation.
Context Window and Processing Capabilities
The models support a 128,000 token context window, enabling processing of extensive documents, complex conversations, and large-scale analytical tasks. While performance may degrade beyond 40,000 tokens, the models maintain reasonable functionality across the full context range.
Additionally, the extended context capability enables comprehensive document analysis, long-form reasoning tasks, and multi-turn conversations with maintained context awareness. This capacity supports enterprise applications requiring extensive information processing.
Quantization and Optimization Techniques
The models support various quantization formats through GGUF implementations, enabling deployment across different hardware configurations. These optimizations reduce memory requirements while preserving reasoning capabilities, making the models accessible in resource-constrained environments.
Furthermore, specialized optimization techniques maintain inference speed while supporting the complex reasoning operations. These technical improvements ensure practical deployment feasibility across diverse computing environments.
Testing and Validation with Apidog
Comprehensive API Testing Strategies
Apidog provides essential tools for validating Magistral model integrations through comprehensive testing frameworks. The platform supports multimodal input testing, reasoning trace validation, and performance benchmarking. Teams can create test suites that verify both functional correctness and performance characteristics.
Apidog's automated testing capabilities enable continuous integration workflows that ensure model performance consistency across development cycles. This automation reduces manual testing overhead while maintaining quality assurance standards.
Performance Monitoring and Optimization
Through Apidog's monitoring capabilities, development teams can track API performance metrics, identify optimization opportunities, and maintain service reliability. The platform provides detailed analytics on response times, reasoning quality, and resource utilization patterns.
Furthermore, the monitoring data enables proactive optimization strategies that improve application performance and user experience. This data-driven approach ensures optimal model utilization across production environments.
Conclusion
Magistral Small 1.2 and Magistral Medium 1.2 represent significant advances in multimodal AI reasoning technology. The combination of enhanced mathematical performance, vision capabilities, and improved reasoning transparency creates powerful tools for diverse applications ranging from scientific research to software development.
The accessibility improvements through local deployment options and comprehensive API support democratize access to advanced reasoning capabilities. Organizations can now integrate sophisticated AI reasoning into their workflows without requiring extensive infrastructure investments.
Whether you're developing educational applications, conducting scientific research, or building complex software systems, Magistral Small 1.2 and Magistral Medium 1.2 provide the reasoning capabilities necessary for next-generation AI applications. Combined with robust testing and integration tools like Apidog, these models enable comprehensive development workflows that accelerate innovation while maintaining quality standards.