The open source AI landscape just witnessed another seismic shift. Z.ai, the Chinese AI company formerly known as Zhipu, has released GLM-4.5 and GLM-4.5 Air, promising to outpace DeepSeek while setting new standards for AI performance and accessibility. These models represent more than incremental improvements—they embody a fundamental rethinking of how hybrid reasoning and agentic capabilities should work in production environments.
The release comes at a crucial moment when developers increasingly demand cost-effective alternatives to proprietary models without sacrificing capability. Both GLM-4.5 and GLM-4.5 Air deliver on this promise through sophisticated architectural innovations that maximize efficiency while maintaining state-of-the-art performance across reasoning, coding, and multimodal tasks.
Understanding the GLM-4.5 Architecture Revolution
The GLM-4.5 series represents a significant departure from traditional transformer architectures. Built on a fully self-developed architecture, GLM-4.5 achieves SOTA performance in open-source models through several key innovations that distinguish it from competitors.
GLM-4.5 features 355 billion total parameters with 32 billion active parameters, while GLM-4.5-Air adopts a more compact design with 106 billion total parameters and 12 billion active parameters. This parameter configuration reflects a careful balance between computational efficiency and model capability, enabling both models to deliver impressive performance while maintaining reasonable inference costs.
The models utilize a sophisticated Mixture of Experts (MoE) architecture that activates only a subset of parameters during inference. Both leverage the Mixture of Experts design for optimal efficiency, allowing GLM-4.5 to process complex tasks using just 32 billion of its 355 billion parameters. Meanwhile, GLM-4.5 Air maintains comparable reasoning capabilities with only 12 billion active parameters from its 106 billion total parameter pool.
This architectural approach directly addresses one of the most pressing challenges in large language model deployment: the computational overhead of inference. Traditional dense models require activating all parameters for every inference operation, creating unnecessary computational burden for simpler tasks. The GLM-4.5 series solves this through intelligent parameter routing that matches computational complexity to task requirements.
Furthermore, the models support up to 128k input and 96k output context windows, providing substantial context handling capabilities that enable sophisticated long-form reasoning and comprehensive document analysis. This extended context window proves particularly valuable for agentic applications where models must maintain awareness of complex multi-step interactions.
GLM-4.5 Air Optimized Performance Characteristics
GLM-4.5 Air emerges as the efficiency champion of the series, specifically engineered for scenarios where computational resources require careful management. GLM-4.5-Air is a foundational model specifically designed for AI agent applications, built on a Mixture-of-Experts (MoE) architecture that prioritizes speed and resource optimization without compromising core capabilities.
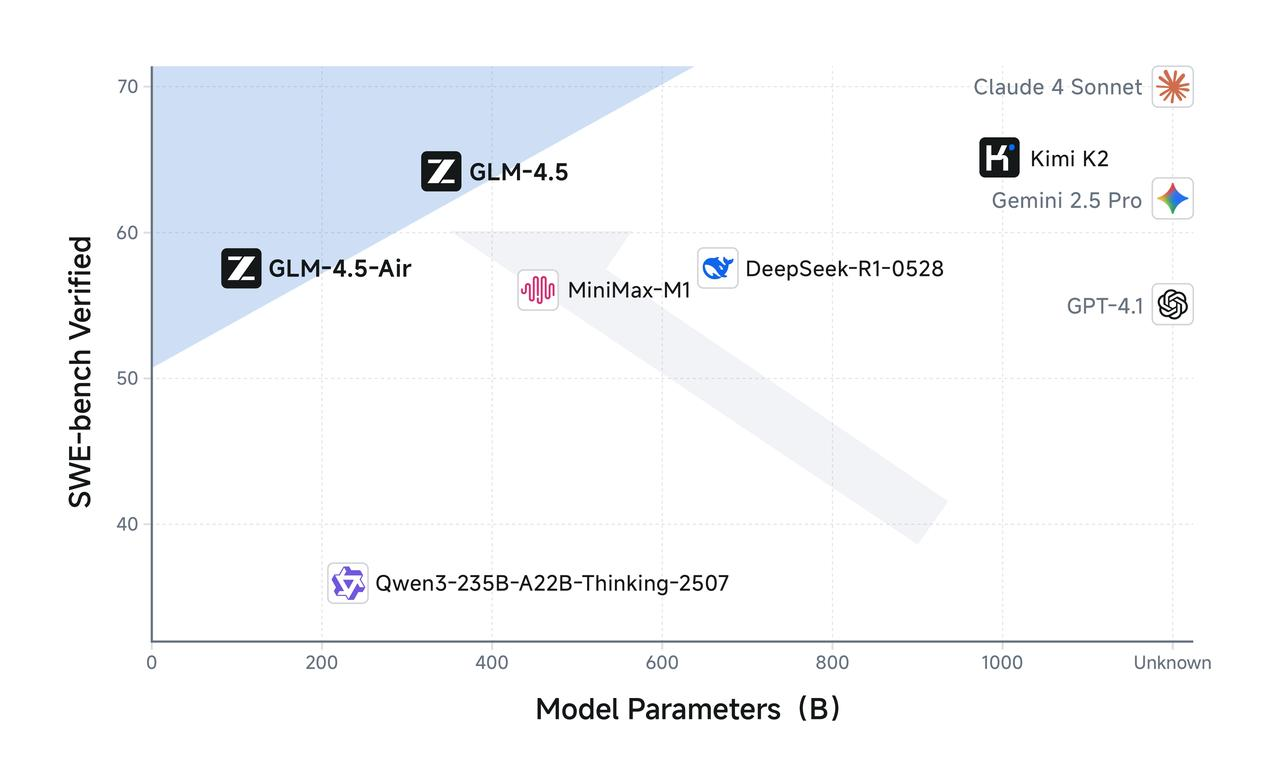
The Air variant demonstrates how thoughtful parameter reduction can maintain model quality while dramatically improving deployment feasibility. With 106 billion total parameters and 12 billion active parameters, GLM-4.5 Air achieves remarkable efficiency gains that translate directly to reduced inference costs and faster response times.
Memory requirements represent another area where GLM-4.5 Air excels. GLM-4.5-Air requires 16GB of GPU memory (INT4 quantized at ~12GB), making it accessible to organizations with moderate hardware constraints. This accessibility factor proves crucial for widespread adoption, as many development teams cannot justify the infrastructure costs associated with larger models.
The optimization extends beyond pure parameter efficiency to encompass specialized training for agent-oriented tasks. It has been extensively optimized for tool use, web browsing, software development, and front-end development, enabling seamless integration with coding agents. This specialization means GLM-4.5 Air delivers superior performance on practical development tasks compared to general-purpose models of similar size.
Response latency becomes particularly important in interactive applications where users expect near-instantaneous feedback. GLM-4.5 Air's reduced parameter count and optimized inference pipeline enable sub-second response times for most queries, making it suitable for real-time applications such as code completion, interactive debugging, and live documentation generation.
Hybrid Reasoning Implementation and Benefits
The defining characteristic of both GLM-4.5 models lies in their hybrid reasoning capabilities. Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses. This dual-mode architecture represents a fundamental innovation in how AI models handle different types of cognitive tasks.
Thinking mode activates when models encounter complex problems requiring multi-step reasoning, tool usage, or extended analysis. During thinking mode, the models generate intermediate reasoning steps that remain visible to developers but hidden from end users. This transparency enables debugging and optimization of reasoning processes while maintaining clean user interfaces.
Conversely, non-thinking mode handles straightforward queries that benefit from immediate responses without extended reasoning overhead. The model automatically determines which mode to employ based on query complexity and context, ensuring optimal resource utilization across diverse use cases.
This hybrid approach solves a persistent challenge in production AI systems: balancing response speed with reasoning quality. Traditional models either sacrifice speed for comprehensive reasoning or provide fast but potentially shallow responses. GLM-4.5's hybrid system eliminates this trade-off by matching reasoning complexity to task requirements.
Both provide thinking mode for complex tasks and non-thinking mode for immediate responses, creating a seamless user experience that adapts to varying cognitive demands. Developers can configure mode selection parameters to fine-tune the balance between speed and reasoning depth based on specific application requirements.
The thinking mode proves particularly valuable for agentic applications where models must plan multi-step actions, evaluate tool usage options, and maintain coherent reasoning across extended interactions. Meanwhile, non-thinking mode ensures responsive performance for simple queries like factual lookups or straightforward code completion tasks.
Technical Specifications and Training Details
The technical foundation underlying GLM-4.5's impressive capabilities reflects extensive engineering effort and innovative training methodologies. Trained on 15 trillion tokens, with support for up to 128k input and 96k output context windows, the models demonstrate the scale and sophistication required for state-of-the-art performance.
Training data curation represents a critical factor in model quality, particularly for specialized applications like code generation and agentic reasoning. The 15 trillion token training corpus incorporates diverse sources including code repositories, technical documentation, reasoning examples, and multimodal content that enables comprehensive understanding across domains.
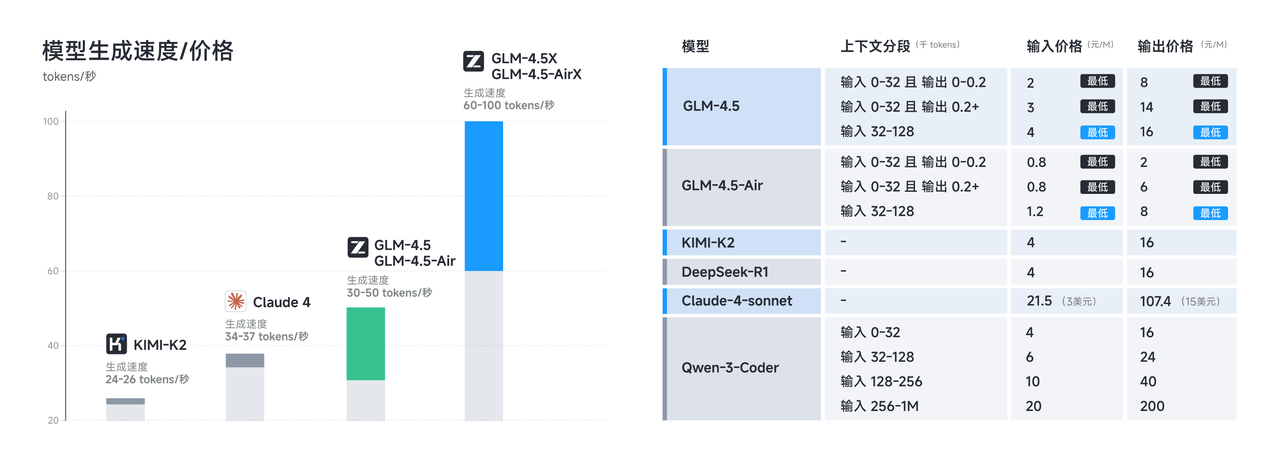
Context window capabilities distinguish GLM-4.5 from many competing models. GLM-4.5 provides 128k context length and native function calling capacity, enabling sophisticated long-form analysis and multi-turn conversations without context truncation. The 96k output context window ensures models can generate comprehensive responses without artificial length limitations.
Native function calling represents another architectural advantage that eliminates the need for external orchestration layers. Models can directly invoke external tools and APIs as part of their reasoning process, creating more efficient and reliable agentic workflows. This capability proves essential for production applications where models must interact with databases, external services, and development tools.
The training process incorporates specialized optimization for agentic tasks, ensuring models develop strong capabilities in tool usage, multi-step reasoning, and context maintenance. Unified architecture for reasoning, coding, and multimodal perception-action workflows enables seamless transitions between different task types within single interactions.
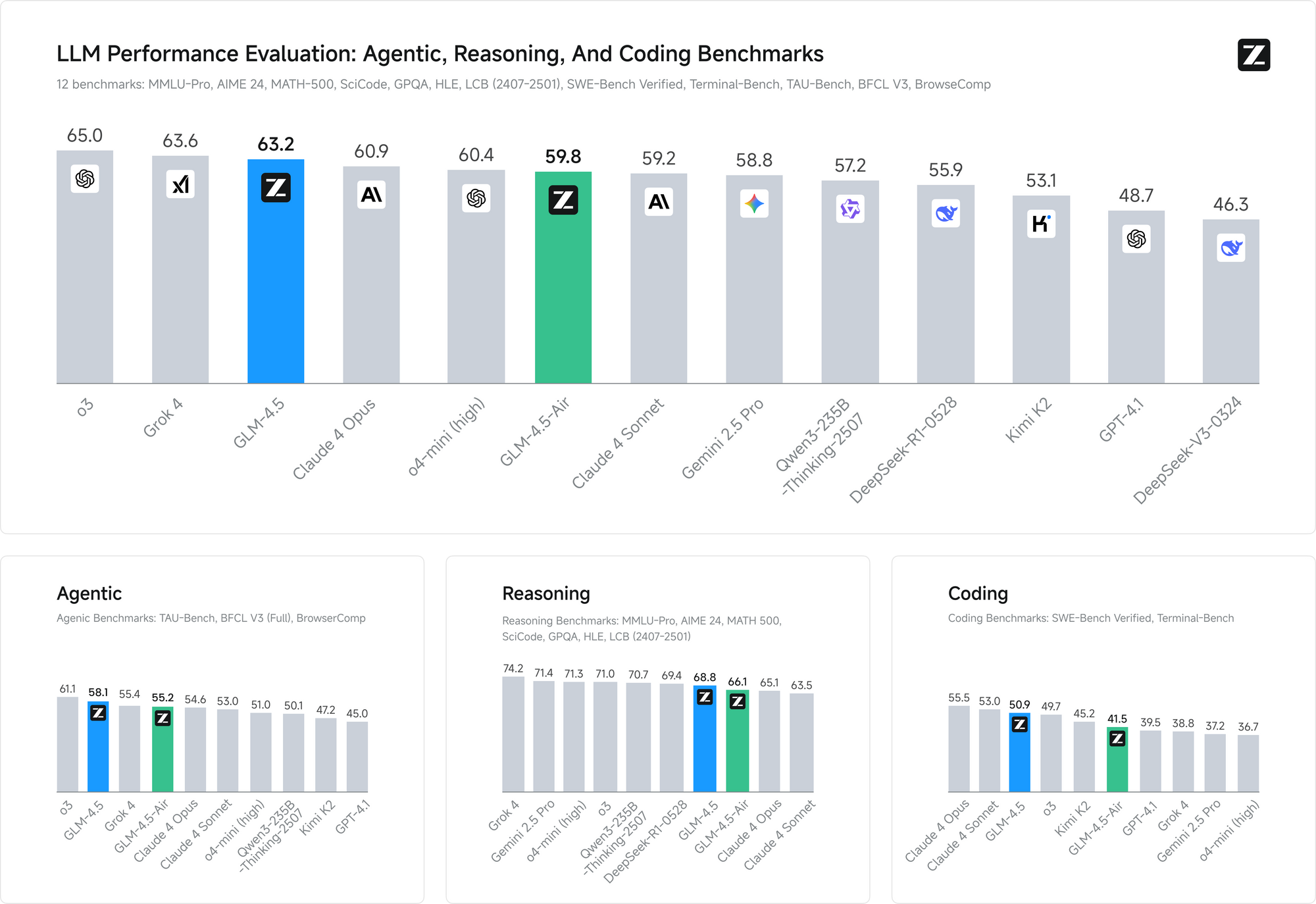
Performance benchmarks validate the effectiveness of these training approaches. On both benchmarks, GLM-4.5 matches the performance of Claude in agent ability evaluations, demonstrating competitive capability against leading proprietary models while maintaining open source accessibility.
Licensing and Commercial Deployment Advantages
Open source licensing represents one of GLM-4.5's most significant competitive advantages in the current AI landscape. The base models, hybrid (thinking/non-thinking) models, and FP8 versions are all released for unrestricted commercial use and secondary development under the MIT license, providing unprecedented freedom for commercial deployment.
This licensing approach eliminates many restrictions that limit other open source models. Organizations can modify, redistribute, and commercialize GLM-4.5 implementations without licensing fees or usage restrictions. The MIT license specifically addresses commercial concerns that often complicate enterprise AI deployments.
Multiple Access Methods and Platform Integration
GLM-4.5 and GLM-4.5 Air offer developers multiple access pathways, each optimized for different Use cases and technical requirements. Understanding these deployment options enables teams to select the most appropriate integration method for their specific applications.
Official Website and Direct API Access
The primary access method involves using Z.ai's official platform at chat.z.ai, which provides a user-friendly interface for immediate model interaction. This web-based interface enables rapid prototyping and testing without requiring technical integration work. Developers can evaluate model capabilities, test prompt engineering strategies, and validate use cases before committing to API implementations.
Direct API access through Z.ai's official endpoints provides production-grade integration capabilities with comprehensive documentation and support. The official API offers fine-grained control over model parameters, including hybrid reasoning mode selection, context window utilization, and response formatting options.
OpenRouter Integration for Simplified Access
OpenRouter provides streamlined access to GLM-4.5 models through their unified API platform at openrouter.ai/z-ai. This integration method proves particularly valuable for developers already using OpenRouter's multi-model infrastructure, as it eliminates the need for separate API key management and integration patterns.
The OpenRouter implementation handles authentication, rate limiting, and error handling automatically, reducing integration complexity for development teams. Furthermore, OpenRouter's standardized API format enables easy model switching and A/B testing between GLM-4.5 and other available models without code modifications.
Cost management becomes more transparent through OpenRouter's unified billing system, which provides detailed usage analytics and spending controls across multiple model providers. This centralized approach simplifies budget management for organizations using multiple AI models in their applications.
Hugging Face Hub for Open Source Deployment
Hugging Face Hub hosts GLM-4.5 models, providing comprehensive model cards, technical documentation, and community-driven usage examples. This platform proves essential for developers who prefer open source deployment patterns or require extensive model customization.
The Hugging Face integration enables local deployment using the Transformers library, giving organizations complete control over model hosting and data privacy. Developers can download model weights directly, implement custom inference pipelines, and optimize deployment configurations for specific hardware environments.
Self-Hosted Deployment Options
Organizations with strict data privacy requirements or specialized infrastructure needs can deploy GLM-4.5 models using self-hosted configurations. The MIT license enables unrestricted deployment across private cloud environments, on-premises infrastructure, or hybrid architectures.
Self-hosted deployment provides maximum control over model behavior, security configurations, and integration patterns. Organizations can implement custom authentication systems, specialized monitoring infrastructure, and domain-specific optimizations without external dependencies.
Container-based deployment using Docker or Kubernetes enables scalable self-hosted implementations that can adapt to varying workload demands. These deployment patterns prove particularly valuable for organizations with existing container orchestration expertise.
Integration with Development Workflows Using Apidog
Modern AI development requires sophisticated tooling to manage model integration, testing, and deployment workflows effectively across these various access methods. Apidog provides comprehensive API management capabilities that streamline GLM-4.5 integration regardless of the chosen deployment approach.
When implementing GLM-4.5 models across different platforms—whether through OpenRouter, direct API access, Hugging Face deployments, or self-hosted configurations—developers must validate performance across diverse use cases, test different parameter configurations, and ensure reliable error handling. Apidog's API testing framework enables systematic evaluation of model responses, latency characteristics, and resource utilization patterns across all these deployment methods.
The platform's documentation generation capabilities prove particularly valuable when deploying GLM-4.5 through multiple access methods simultaneously. Developers can automatically generate comprehensive API documentation that includes model configuration options, input/output schemas, and usage examples specific to GLM-4.5's hybrid reasoning capabilities across OpenRouter, direct API, and self-hosted deployments.
Collaborative features within Apidog facilitate knowledge sharing across development teams working with GLM-4.5 implementations. Team members can share test configurations, document best practices, and collaborate on integration patterns that maximize model effectiveness.
Environment management capabilities ensure consistent GLM-4.5 deployments across development, staging, and production environments, regardless of whether teams use OpenRouter's managed service, direct API integration, or self-hosted implementations. Developers can maintain separate configurations for different environments while ensuring reproducible deployment patterns.
Implementation Strategies and Best Practices
Successfully deploying GLM-4.5 models requires careful consideration of infrastructure requirements, performance optimization techniques, and integration patterns that maximize model effectiveness. Organizations should evaluate their specific use cases against model capabilities to determine optimal deployment configurations.
Hardware requirements vary significantly between GLM-4.5 and GLM-4.5 Air, enabling organizations to select variants that match their infrastructure constraints. Teams with robust GPU infrastructure can leverage the full GLM-4.5 model for maximum capability, while resource-constrained environments may find GLM-4.5 Air provides sufficient performance at reduced infrastructure costs.
Model fine-tuning represents another critical consideration for organizations with specialized requirements. The MIT license enables comprehensive model customization, allowing teams to adapt GLM-4.5 for domain-specific applications. However, fine-tuning requires careful dataset curation and training expertise to achieve optimal results.
Hybrid mode configuration requires thoughtful parameter tuning to balance response speed with reasoning quality. Applications with strict latency requirements may prefer more aggressive non-thinking mode defaults, while applications prioritizing reasoning quality may benefit from lower thinking mode thresholds.
API integration patterns should leverage GLM-4.5's native function calling capabilities to create efficient agentic workflows. Rather than implementing external orchestration layers, developers can rely on the model's built-in tool usage capabilities to reduce system complexity and improve reliability.
Security Considerations and Risk Management
Deploying open source models like GLM-4.5 introduces security considerations that organizations must address through comprehensive risk management strategies. The availability of model weights enables thorough security auditing but also requires careful handling to prevent unauthorized access or misuse.
Model inference security requires protecting against adversarial inputs that might compromise model behavior or extract sensitive information from training data. Organizations should implement input validation, output filtering, and anomaly detection systems to identify potentially problematic interactions.
Deployment infrastructure security becomes critical when hosting GLM-4.5 models in production environments. Standard security practices including network isolation, access controls, and encryption apply to AI model deployments just as they do to traditional applications.
Data privacy considerations require careful attention to information flows between applications and GLM-4.5 models. Organizations must ensure that sensitive data inputs receive appropriate protection and that model outputs don't inadvertently expose confidential information.
Supply chain security extends to model provenance and integrity verification. Organizations should validate model checksums, verify download sources, and implement controls that ensure deployed models match intended configurations.
The open source nature of GLM-4.5 enables comprehensive security auditing that provides advantages over proprietary models where security properties remain opaque. Organizations can analyze model architecture, training data characteristics, and potential vulnerabilities through direct examination rather than relying on vendor security assertions.
Conclusion
GLM-4.5 and GLM-4.5 Air represent significant advances in open source AI capabilities, delivering competitive performance while maintaining the accessibility and flexibility that define successful open source projects. Z.ai has released its next-generation base model GLM-4.5, achieving SOTA performance in open-source models through architectural innovations that address real-world deployment challenges.
The hybrid reasoning architecture demonstrates how thoughtful design can eliminate traditional trade-offs between response speed and reasoning quality. This innovation provides a template for future model development that prioritizes practical utility over pure benchmarking performance.
Cost efficiency advantages make GLM-4.5 accessible to organizations that previously found advanced AI capabilities prohibitively expensive. The combination of reduced inference costs and permissive licensing creates opportunities for AI deployment across diverse industries and organization sizes.