
Google continues to advance its AI offerings with the launch of Gemini 3 Flash. This model combines frontier-level intelligence with exceptional speed and efficiency. Developers and enterprises now access high-performance AI without compromising on latency or cost.
Overview of Gemini 3 Flash: Key Features and Release Details
Google released Gemini 3 Flash on December 17, 2025. Researchers engineered this model to deliver Pro-grade reasoning while maintaining the low latency characteristic of the Flash series. Consequently, it replaces Gemini 2.5 Flash as the default model in the Gemini app and AI Mode in Google Search.
Gemini 3 Flash excels in diverse tasks. It handles coding, complex analysis, interactive applications, agentic workflows, and multimodal reasoning effectively. Furthermore, the model processes videos, images, and audio inputs natively. Developers leverage these capabilities for real-time assistance, data extraction, and visual question-answering.

One standout feature involves the model's adaptive thinking mechanism. It modulates computation based on query complexity, resulting in 30% fewer tokens consumed on average for routine tasks compared to Gemini 2.5 Pro. This efficiency translates directly to reduced operational costs in production environments.
Additionally, Gemini 3 Flash supports high-frequency workflows. Enterprises deploy it for near real-time interactions, such as in-game AI assistants or rapid A/B testing scenarios. Companies including JetBrains, Figma, and Bridgewater Associates already utilize the model for transformative applications.
Performance Benchmarks: How Gemini 3 Flash Stacks Up
Independent evaluations demonstrate Gemini 3 Flash's superior capabilities. Artificial Analysis benchmarks reveal that the model operates three times faster than Gemini 2.5 Pro while surpassing it in quality metrics.
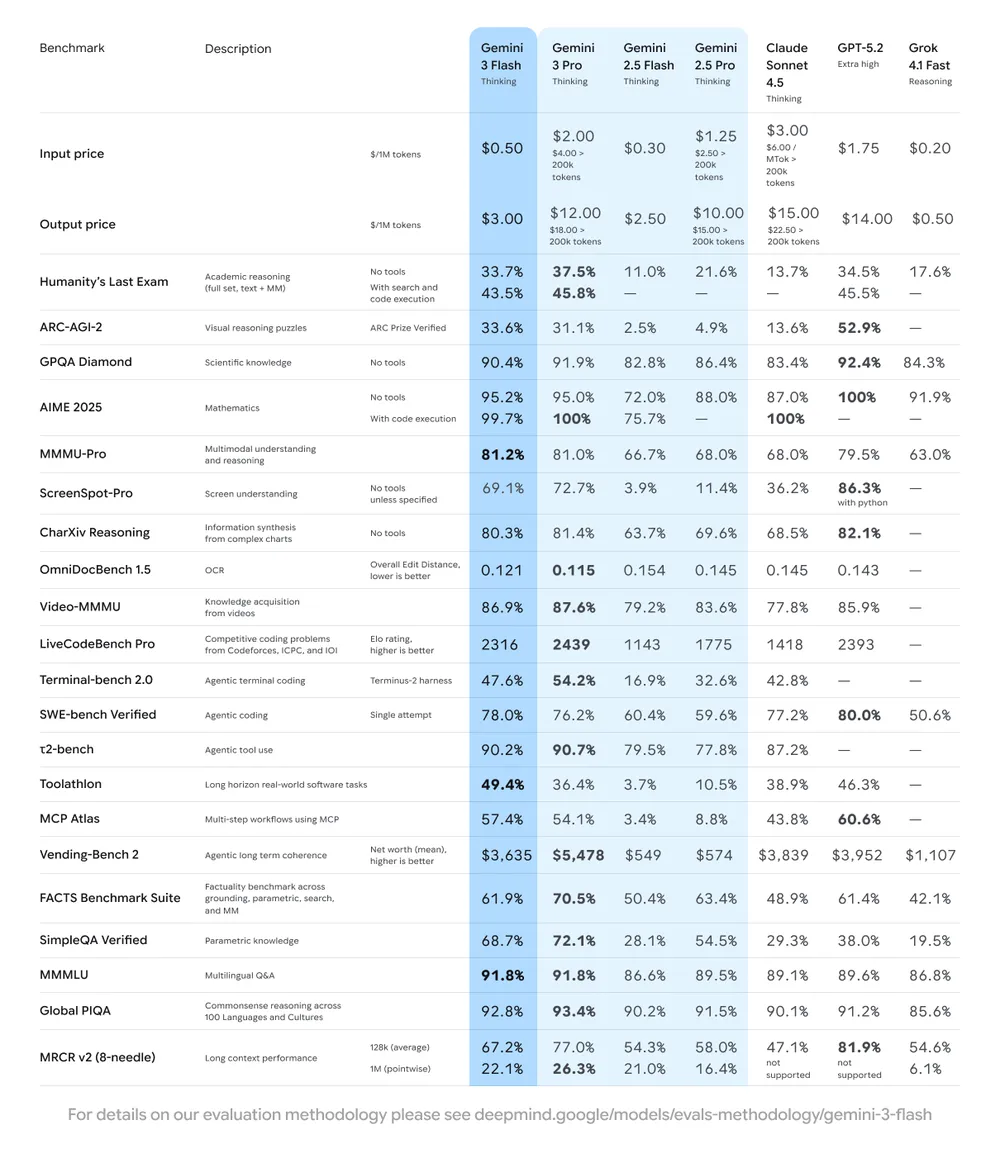
Specifically, Gemini 3 Flash achieves impressive scores across challenging evaluations:
- GPQA Diamond: 90.4% – reflecting PhD-level reasoning proficiency.
- Humanity’s Last Exam (without tools): 33.7%.
- MMMU Pro: 81.2% – state-of-the-art multimodal understanding, matching Gemini 3 Pro.
- SWE-bench Verified: 78% – leading performance in coding agent tasks.
These results position Gemini 3 Flash at the Pareto frontier for speed versus quality. Moreover, it outperforms larger models in efficiency while retaining frontier intelligence in reasoning, vision, and agentic coding.
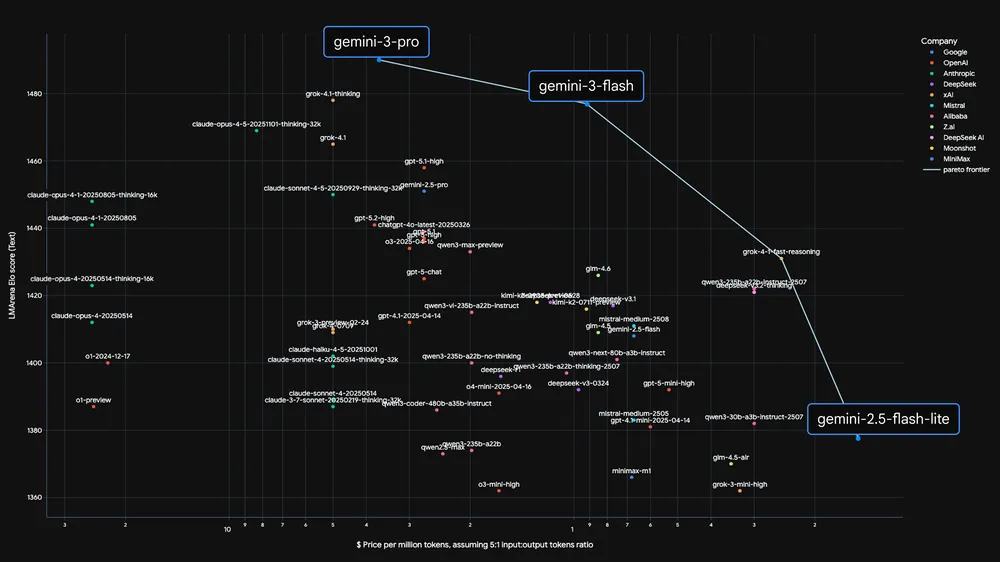
Compared to its predecessor, Gemini 2.5 Flash, the new model delivers substantial improvements across all categories. It also competes favorably with contemporary frontier models, often matching or exceeding Gemini 3 Pro in specific domains at significantly lower latency.
Multimodal Capabilities: Beyond Text Processing
Gemini 3 Flash processes multimodal inputs seamlessly. Developers feed it images, videos, and audio alongside text prompts. For instance, the model analyzes short video clips to generate actionable insights, such as personalized training plans from sports footage.
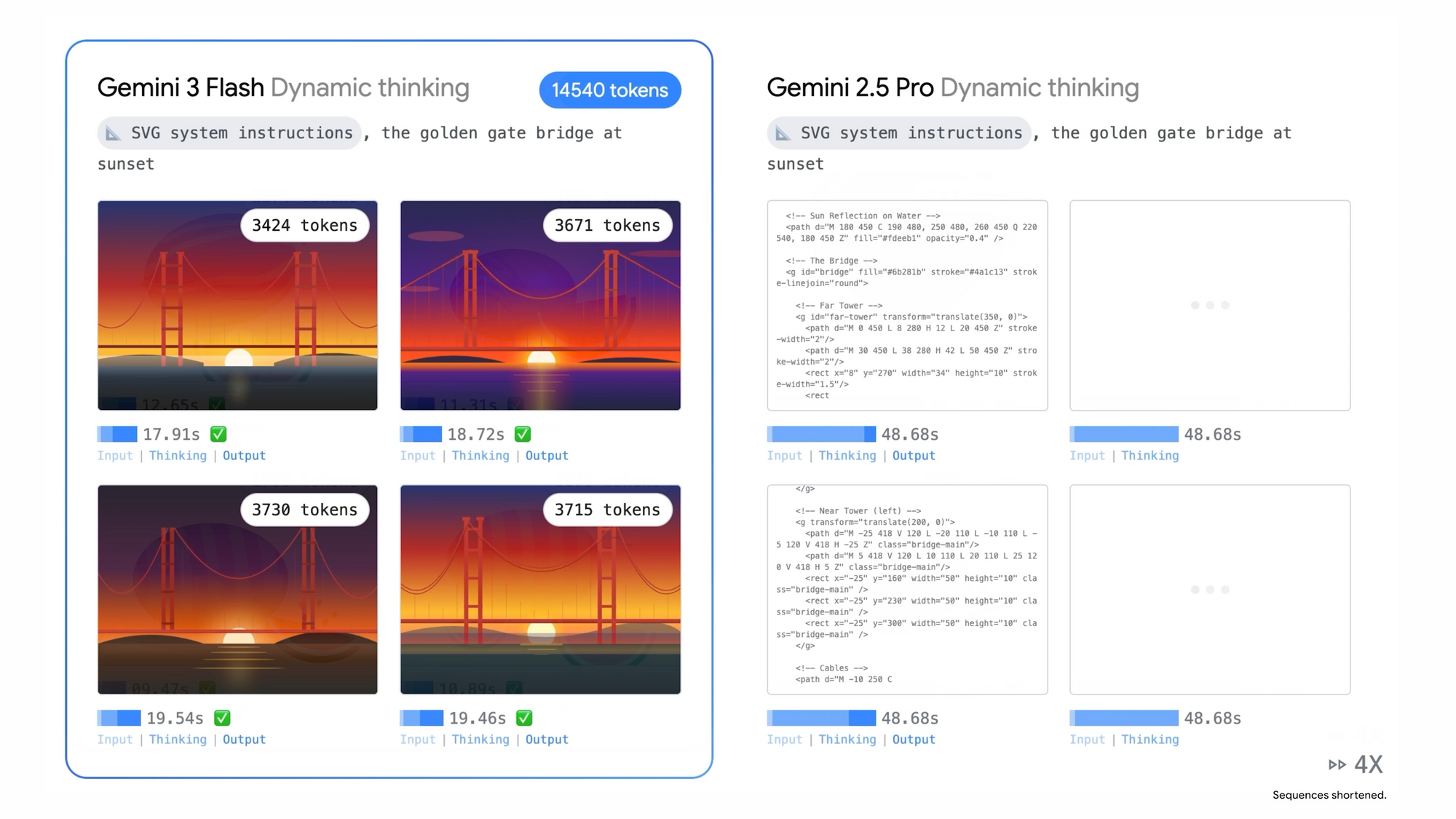
In visual tasks, Gemini 3 Flash identifies elements in sketches in near real-time. It overlays contextual UI elements on static images, transforming them into interactive prototypes. Additionally, audio processing enables the model to review recordings, detect knowledge gaps, and create tailored quizzes with explanations.
These features extend to advanced applications. Developers build systems that convert unstructured voice instructions into functional applications. The model also performs complex data extraction from visual content and supports vibe-based coding paradigms.
Overall, multimodal integration pushes Gemini 3 Flash toward practical deployments in robotics, augmented reality, and content creation pipelines.
Speed, Efficiency, and Technical Architecture
Engineers optimized Gemini 3 Flash for raw inference speed. It achieves low latency suitable for responsive applications, including games and live agents. This optimization stems from architectural refinements that prioritize throughput without sacrificing reasoning depth.
The model handles over one trillion tokens daily through the Gemini API, underscoring its scalability. Furthermore, token efficiency improvements reduce costs for everyday operations.
Developers select between "Fast" and "Thinking" modes in the Gemini app. The former prioritizes quick responses, while the latter allocates additional computation for complex problems. This flexibility ensures optimal performance across varying use cases.
Pricing Structure: Cost-Effective Access to Frontier AI
Google prices Gemini 3 Flash competitively to encourage broad adoption. The API charges $0.50 per million input tokens and $3 per million output tokens. Audio inputs cost $1 per million tokens.
Compared to Gemini 2.5 Flash ($0.30 input / $2.50 output per million), the slight increase reflects enhanced capabilities. However, overall expenses often decrease due to reduced token usage in thinking tasks.
Free access remains available through the Gemini app for global users. Developers experiment in Google AI Studio with generous rate limits. Paid tiers unlock higher quotas and enterprise features via Vertex AI.
This pricing model positions Gemini 3 Flash as a cost-efficient workhorse. It offers frontier performance at a fraction of larger models' expenses.
Availability and Developer Integrations
Gemini 3 Flash rolls out globally immediately upon release. Users access it directly in the Gemini app, where it serves as the default model.
Developers integrate via multiple platforms:
- Google AI Studio for prototyping.
- Gemini CLI and Google Antigravity for agentic development.
- Android Studio for mobile applications.
- Vertex AI and Gemini Enterprise for production deployments.
Preview access enables enterprises to evaluate the model in controlled environments. Additionally, integrations with tools like Cursor and Harvey demonstrate real-world adoption.
Integrating Gemini 3 Flash API: Practical Considerations
Developers configure API requests using standard REST endpoints. Requests include JSON payloads specifying the model ("gemini-3-flash") and content parts.
Authentication requires an API key from Google AI Studio. Moreover, multimodal requests incorporate base64-encoded media or URLs.
Effective integration demands thorough testing. Tools like Apidog prove invaluable here. Apidog provides a comprehensive platform for API design, mocking, debugging, and automated testing.
For example, developers import Gemini API specifications into Apidog. They then generate mock servers for frontend collaboration, create test suites verifying response formats, and monitor token usage. Apidog supports environment variables for switching between preview and stable endpoints seamlessly.
Furthermore, Apidog handles multimodal payloads efficiently. Users upload files directly, inspect detailed responses, and validate structured outputs. This workflow accelerates iteration cycles significantly.
In agentic applications, Apidog facilitates tool-calling validation. Developers define expected schemas and assert compliance automatically.
Use Cases: Real-World Applications of Gemini 3 Flash
Enterprises deploy Gemini 3 Flash across diverse domains. In software development, it powers intelligent code assistants that generate, refactor, and debug at scale.
Content platforms leverage multimodal features for automated moderation and enhancement. For instance, systems analyze user-uploaded media to suggest improvements or extract metadata.
Interactive applications benefit from low latency. Game developers implement dynamic NPCs that respond contextually in real-time.
Additionally, analytical workflows use the model for rapid insight generation from unstructured data. Bridgewater Associates employs similar capabilities for financial modeling.
Educational tools create personalized learning experiences. The model processes lecture recordings to identify gaps and produce remedial content.
Comparison with Previous Gemini Models
Gemini 3 Flash builds directly on the Gemini 3 series foundation. It retains complex reasoning and multimodal strengths while optimizing for speed and cost.
Relative to Gemini 2.5 Pro, it delivers three times faster inference with superior benchmark performance. Token efficiency further widens the practical advantage.
Against Gemini 2.5 Flash, the upgrade manifests in reasoning depth and multimodal accuracy. Users experience "smarts and speed" simultaneously.
Future Implications and Conclusion
Gemini 3 Flash establishes a new standard for accessible frontier AI. Its combination of performance, efficiency, and pricing democratizes advanced capabilities.
Developers now build responsive, intelligent applications without prohibitive costs. Enterprises scale AI deployments confidently.
To begin experimenting, generate an API key in Google AI Studio and test requests. Pair this with Apidog for streamlined development – download it free and accelerate your Gemini 3 Flash integrations.
This model signals continued rapid progress in AI. Subsequent iterations will likely push boundaries further, but Gemini 3 Flash already provides substantial value today.


